【目标跟踪】|数据集汇总

测试使用的数据集
OTB在它的第一个[9]和第二个[12]版本中分别收集了51个和100个移动对象,而ALOV++[21]提供了一个更大的超过300个视频的池。VOT[4]、[5]、[8]是自2013年以来每年与ICCV和ECCV研讨会一起举办的年度视觉对象跟踪挑战赛。之后还提出了其他几个旨在解决具体问题的数据集。它们包括大规模人员和刚性目标跟踪数据集NUS_PRO[17]、长期空中跟踪数据集UAV123/UAV20L[15]、彩色跟踪数据集TColor-128[16]、长期跟踪数据集OxUvA[13]、热跟踪数据集PTB-TIR[22]和VOT-TIR[5]、RGBD跟踪数据集PTB[18]和高帧率跟踪数据集NFS[14]。这些数据集在推动跟踪方法的发展方面发挥了重要作用。然而,这些数据集规模较小,仅提供测试数据,不适合基于深度学习的跟踪方法的统一训练和评估。
OTB
OTB50[4]和OTB100[5]提供51和98个视频序列,每个帧使用11个不同的属性和垂直边界框进行注释。
VOT
TC128
NFS
提供了一组100个高帧率(120FPS)的视频,试图专注于快速运动。外观变化
UAV123
收集从无人机捕获或由飞行模拟器生成的123个视频和20个长视频的另一个特定应用集合。
包含训练集的跟踪数据集
TrackingNet
VOT15[9]是从OTB100[5]和ALOV300[17]等现有数据集中采样的,导致序列重叠(例如篮球、汽车、歌手等)。即使冗余得到了控制,人们在选择训练视频序列时也需要小心,因为在测试视频上训练深度跟踪器是不公平的。
TrackingNet,这是一个为训练深度跟踪器而设计的大规模目标跟踪数据集。
TrackingNet总共汇集了30643个视频片段,平均时长为16.6s。从140小时的可视内容中提取的所有14,431,266帧都使用单个垂直边界框进行注释。
从YouTube-BoingBox[42]中选择了30,132个训练视频,并构建了一个新的511个测试视频集,其分布与训练集相似。
YT-BB以每秒1fps的速度提供粗略注释。为了增加注释密度,我们混合使用最先进的跟踪器来填充缺失的注释。我们声称,任何跟踪器在1秒的小时间间隔内都是可靠的。因此,我们使用DCF跟踪器使用向前和向后传递之间的加权平均值对30,132个视频进行了密集标注

标注规则
边界框可能包含大量背景。例如,不管人物的姿势如何,Person类始终包含手臂和腿部。我们认为,跟踪器应该能够处理可变形的物体,并理解它正在跟踪的是什么。同样,动物的尾巴也总是包括在内。此外,目标的边界框根据其在帧中的可见性进行调整。估计目标的遮挡部分的位置是不确定的,因此应该避免。例如,目标类刀具的手柄可以用手隐藏。在这种情况下,仅对刀片进行注释。
属性
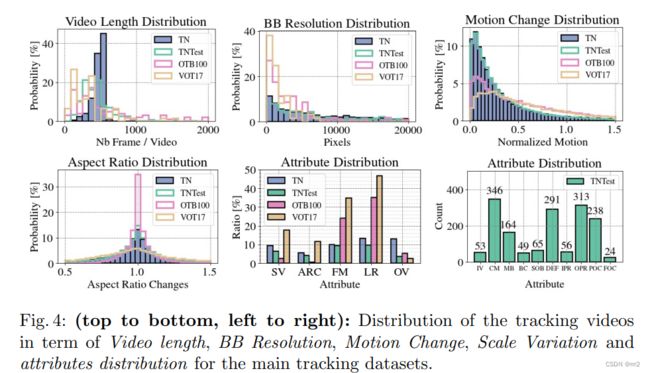
视频帧时长。bbox的像素数量和分布。运动改变
纵横比改变的分布 (OTB100的纵横比改变很小)
SV ARC FM LR OV
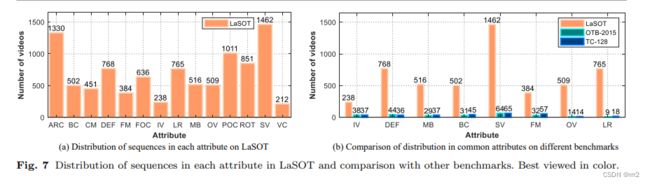
LaSOT
圆圈大小为总帧数

它是一个long-term tracking ,这个数据集有1400个视频序列,每个视频平均有2512帧,最短的视频也有1000帧,最长的包含11397帧。分为70个类别(真的很多了,一般只要二十左右,那会有更多的吗?答案是肯定的,GOT-10k),每个类别由二十个视频序列组成。
每个视频序列包含不同的挑战,这些类别是从ImageNet的1000类中挑选出来的。那每一帧是怎么标注的呢?是人工标注,很小心的密集标注。更重要的是,它考虑了视觉外观和自然语言的联系,不仅标注了bbox而且增加了丰富的自然语言描述,旨在鼓励对于跟踪,结合视觉和自然语言特征的探索。这里提供1400个句子描述。
那这些视频是怎么来的呢?从YouTube搜索的,5000中挑选了1400,但是这1400个视频也不能直接使用,因为有大量的无关内容,例如对于运动者的介绍,所以得过滤掉这些不相关的内容。
它只有227G,比TrackingNet小很多。

14种属性

类别均匀性

把LaSOT分为训练和测试子集。根据80/20分,也就是对于每一个类别,我们挑选16个视频作为训练,4个作为测试。最后有1120个训练视频,280个测试视频。
ref
https://www.elecfans.com/d/996309.html
GOT-10K
论文翻译
https://blog.csdn.net/MJ17709005513/article/details/120853748
GOT-10K数据集由中国科学院自动化研究所CASIA的智能系统与工程研究中心发布并维护,是具有国际权威的通用单目标跟踪算法评测数据集。
其中训练集由10000个视频序列组成,全部取材于现实世界里移动的物体,包含563个目标类别与87种运动模式。物体的边界框全部是手动标记,总计超过150万个。
测试集由180个视频序列组成,包含84类移动物体和32种运动模式,且训练视频与测试视频之间所有的对象不重叠。
GOT-10k首次引入了跟踪器评估的One-shot协议,其中训练类和测试类是零重叠的。该协议避免了评价结果对熟悉对象的偏向,促进了跟踪器开发的泛化。
LaSOT[20]和TrackingNet[19]这两个数据集都提供了统一的大型训练和测试数据,但它们的手动定义的对象类(分别为21个和70个类)可能不足以代表不同的真实世界移动对象。此外,在这两个数据集中,训练对象类和测试对象类完全重叠且分布紧密,导致评估结果偏向于熟悉的对象类,在这些对象类上的性能很难推广到大范围的不可见对象。
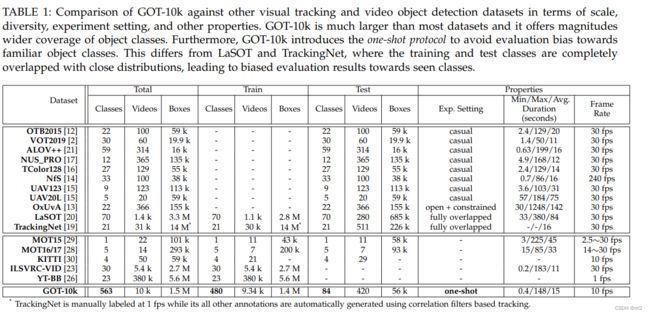
首次引入了跟踪器评估的单次协议,其中训练集和测试集之间的类是零重叠的。该协议避免了对熟悉对象的评价偏差,促进了跟踪器开发的通用性。

有更广泛的不同对象类的覆盖范围。
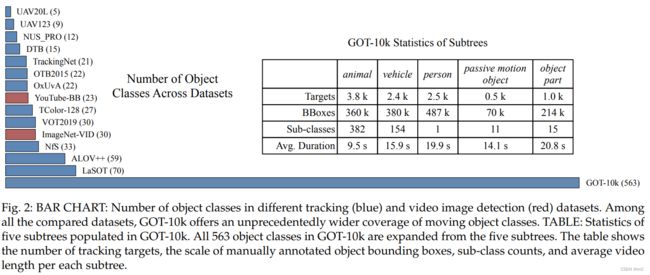
在验证阶段,许多类别的视频由于场景和动作单一、对象不完整、动作非常缓慢或轨迹碎片化而经常被过滤掉。经过几轮验证,我们的数据集的视频自然呈现出跨类分布的不均衡。
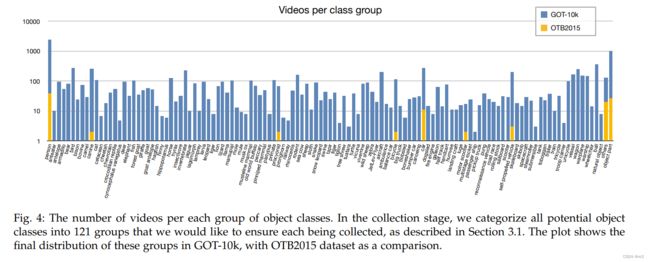
我们将GOT-10k数据集分为统一的训练,验证和测试集,以实现跟踪方法的公平比较。与许多其他机器学习应用[24],[26]不同,通用对象跟踪数据集的分割并不简单(即通过随机采样一部分数据)。一方面,我们期望评估结果反映不同方法在各种对象和场景中的泛化能力。为此,必须在培训和测试视频之间建立明确的领域差距。另一方面,我们不需要数千个视频来评估跟踪算法。此外,跟踪器的评估非常耗时,因此保持测试集相对紧凑是有利的。
测试集设置
视频数量的影响。我们将测试视频的数量从5个调整到1000个,步长为5。图6a显示,随着视频数量的增加,排名的标准差明显减小,这表明评估的稳定性有所提高。考虑到稳定性和效率的权衡,我们在基准测试中将视频数量设置为420
目标类别的影响
我们将视频编号固定为420,并将采样对象类别从5更改为115,结果如图6b所示。我们观察到随着对象类的增加,方法等级的标准差有明显的下降趋势,验证了测试集多样性对排行榜稳定性的重要性。我们在测试数据中包括84个对象类
运动类别的影响
在视频数量固定为420个的情况下,我们将动作类的数量从5个调整到40个。图6c显示了运动类别对排名稳定性的影响。稳定性通常随着测试集中包含更多运动类别而提高。我们的测试集中包括31个运动类
重复时间的影响\
许多跟踪基准要求跟踪器在其数据集上运行多次.重复时间从1增加到30。我们发现,在我们的大型测试集上评估时,增加重复时间对评估稳定性的贡献可以忽略不计(约为0.1)。考虑到许多跟踪器的随机性,我们将重复次数设置为3次,这对于稳定的评估是足够的。
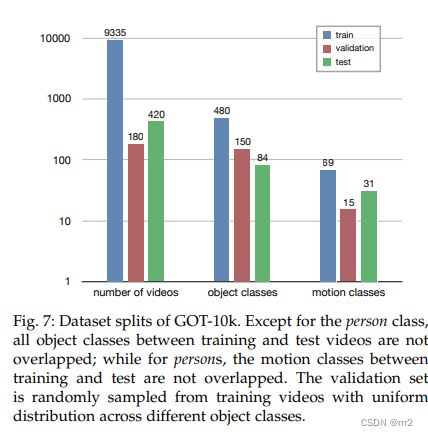
GOT-10k数据集的最后拆分如图7所示。测试集包含420个视频、84类运动对象和31种运动形式,在这样的设置下可以观察到相当稳定的排名。除了Person类,训练和测试视频之间的所有目标类都是不重叠的;而对于Person,训练集和测试集之间的运动类不重叠。我们将每个类别的最大视频数量限制在8个(仅占测试集大小的1.9%),以避免较大规模的类别主导评估结果。
验证集是通过从训练子集中随机抽样180个视频来选择的,并且在不同的目标类上具有均匀的概率。
对于每个随机跟踪器,我们运行3次实验,并对分数进行平均,以确保评估的可重复性。
————————————————
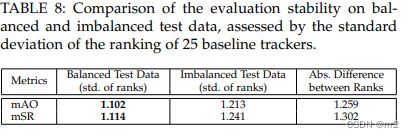
我们选择广泛使用的平均重叠度(AO)和成功率(SR)作为我们的指标。AO表示所有基本事实和估计边界框之间重叠的平均值,而SR测量重叠超过阈值(例如,0.5)的成功跟踪帧的百分比。AO最近被证明等同于OTB[9]、[12]、NFS[14]、UAV[15]、TrackingNet[19]和LaSOT[20]数据集中使用的曲线下面积(AUC)度量。此外,用于VOT挑战总体排名的预期平均重叠(EAO)度量近似于较大视频池的AO。SR指标也用于OTB2015[12]和OxUvA[13]数据集中。它清楚地指示了在一定精度下跟踪或丢失了多少帧,这是许多应用程序所关注的。
现有的跟踪基准直接通过对序列分数进行平均来获得最终性能,完全忽略了评估中潜在的类别不平衡(即,序列越多,权重越高),我们提出了类别平衡度量方法,这与已有的跟踪基准不同的是,它完全忽略了评估中潜在的类别不平衡(即,序列越多,权重越高)。以AO为例,类别平衡度量MAO(平均重叠)的计算公式为:
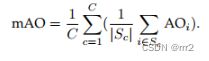
其中C是类别数量,Sc表示属于第C类的序列的子集,而|Sc|是子集尺度。在公式中,首先(在括号中)计算类别的AO,然后求平均值以获得最终分数,对不同的类别一视同仁。同样的原理也适用于SR,其中mSR是通过将SRs在不同类别中平均。我们使用两个重叠阈值0.5和更严格的0.75来计算mSR。
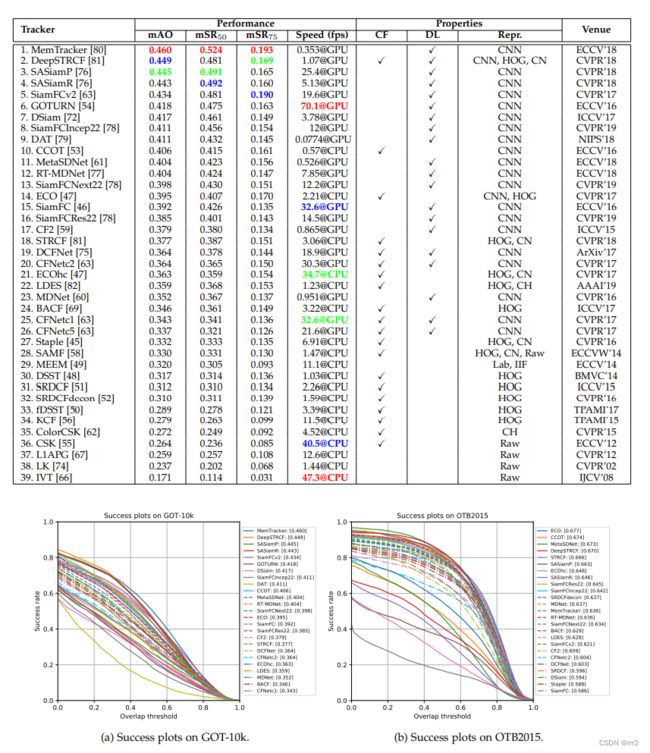
请注意,在GOT-10k上评估的跟踪速度通常低于他们在OTB和VOT上报告的结果。这是因为GOT-10k中视频和对象的分辨率远远高于OTB和VOT数据集(3∼9倍)。虽然这些高分辨率视频由于在更大的图像处理(例如,裁剪、调整大小和填充)上花费了更多的计算成本而降低了几乎所有跟踪器的速度,
但那些将搜索区域下采样到固定大小的方法(例如,大多数siamese跟踪器,如SiamFC、SASiamP和CFNet)受到的影响较小;
而那些搜索区域大小与对象的分辨率成比例的方法(例如,一些基于相关滤波器的方法,如CSK、KCF和DSST)在我们的视频上运行的速度要慢得多。
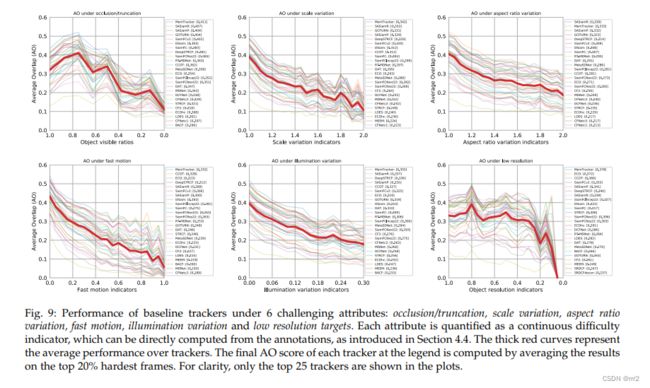
六种属性的性能比较
虽然总体性能反映了跟踪器的总体质量,但它不能根据不同的属性来区分它们,从而反映出每种方法的优缺点。在本节中,我们将从不同挑战的角度分析跟踪器的性能。
遮挡/截断
可见比v,则遮挡截断比为(1-v)
尺度变化
选择间隔五帧的两个目标尺度放大比例
![]()
T=5
长宽比变化
同尺度变化定义
![]()
照明变化
每一帧中的照明变化程度可以通过平均颜色ui=||ci−ci−1||的变化来测量,其中ci是帧i处的平均对象颜色(其中rgb通道归一化为[0, 1])。
快速运动
我们在第i帧测量相对于其大小的对象运动速度为:
![]()
其中pi表示对象中心位置,
低分辨率目标
尺寸较小的目标可能会影响跟踪性能,因为可以从中提取不太细粒度的特征。我们通过将目标的大小与数据集中目标大小的中位数进行比较来测量目标的分辨率。形式上,该指示符被定义为si/sMedium
sMedium是我们的测试数据中所有帧上目标大小的中位数。我们在评估中只考虑具有si≤sMedium的帧。
当获得所有的帧难度指标时,我们将它们的值分成几个离散的区间,并计算每个区间内的帧子集的AO分数。这场演出非常精彩。每个挑战性属性的难度增加如图9所示。从该图中,我们观察到当难度增加时,对于快速运动、纵横比变化、比例变化和照明变化的属性的跟踪性能明显下降。这表明在快速的目标状态(位置、比例和方向)和外观(姿势和照明条件)变化下的跟踪对于当前的跟踪器来说仍然是具有挑战性的。我们还发现,当目标的可见率变低(即低于0.5时)时,跟踪性能迅速下降,这表明当目标的特征被截断或受到外部干扰的影响时,很难进行鲁棒跟踪。对于属性目标分辨率,我们观察到,当目标的分辨率相对较高(即,高于0.3)时,AO分数变化不大;但当其分辨率变得非常低(即,低于0.3)时,AO分数迅速下降。这表明很难跟踪低分辨率或非常小的运动对象。一般来说,对于所有6个具有挑战性的属性,难度的增加会导致几乎所有基线跟踪器的性能显著下降。
对象和运动影响
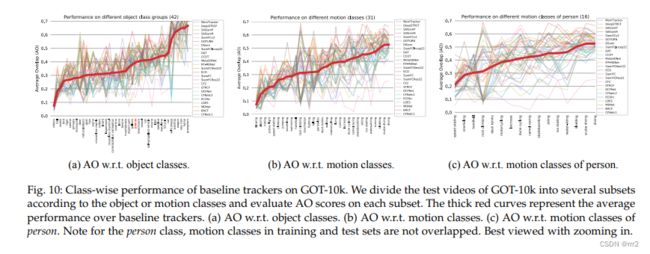
对象类分为42个组,并评估每个类组上所有基线跟踪器的AO分数。结果如图10(a)所示,在图10(a)中,根据在相应子集上评估的平均AO分数对类进行排序。虽然基线算法的性能在不同的对象类之间差别很大,但我们仍然可以看到不同对象类之间总体难度的差异。
一般来说,小的(如球、鸟和幼虫)、薄的(如蛇、鱼和蜥蜴)和快速移动的(如鸟、犬、灵长类和啮齿动物)物体通常比大的或慢的物体(如叉角羚、海牛、马车和军舰)更难跟踪。
此外,与相对刚性的对象(例如,各种车辆)相比,具有大变形的对象(例如,蛇、灵长类动物、鳄鱼爬行动物和蜥蜴)通常导致较低的跟踪性能。
运动类别。我们在标记了不同运动类别的测试视频子集上评估基线跟踪器。排序结果如图10(b)所示。从图中我们可以观察到不同动作类的整体难度有显著差异。
一般来说,快速和戏剧性的动作(如吹气、打球、击打、速度滑冰和跳跃)通常比温和的动作(如跳水、水肺潜水和转身)更难跟踪。
另一个影响因素可能与潜在的背景杂波有关。对于一些较容易的动作类,如潜水、潜水、雪橇、滑冰和滑雪,背景可能通常很简单,颜色和纹理都很单调;
而对于一些较难的动作类,如吹、玩、攀登、游泳和手球,周围的环境通常很复杂,可能会有潜在的干扰和背景杂乱,这给跟踪带来了进一步的挑战。
人的运动类别。Person类包含一组丰富的运动形式,每种形式都代表跟踪的各种挑战的组合。它也是许多工业应用的核心问题。因此,我们从人的不同运动类别出发,分别分析了人的跟踪性能。结果如图10©所示。
一般来说,动作剧烈的运动类别(如速度滑冰、手球、甲板网球和曲棍球)、潜在的背景杂乱(如手球、攀岩和摩托车)和潜在的大变形(如攀岩)通常更难跟踪,算法可能会漂移到干扰或遮挡;
而背景可能更干净的运动类(如跳水、雪橇和滑雪)通常更容易跟踪。
训练数据的影响
MemTracker和SiamFCv2建立在随机初始化的5层AlexNet[71]之上,它们允许所有参数都是可训练的。因此,在较小规模的训练数据上,它们容易过度拟合;而在较大的训练数据上,它们有更大的改进空间。相比之下,MDNet和GOTURN是从ImageNet预先训练的权重初始化的,它们在训练期间固定早期层。因此,这两种方法可以用少量的训练数据提供良好的性能,但它们可能很难从更大的训练数据中进一步受益。
这些方法对数据规模的依赖程度不同,部分原因可能是它们的可训练模型大小不同。
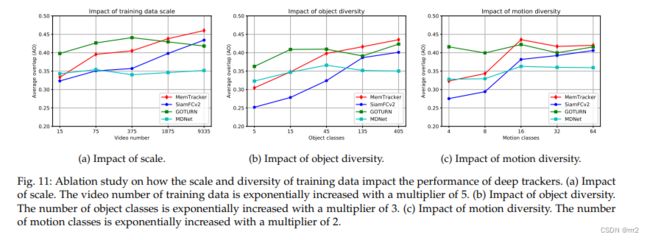
训练数据中对象多样性对MemTracker和SiamFCv2两种跟踪器泛化性能的重要性。相比之下,MDNet的性能受训练数据中对象多样性的影响较小。
MemTracker和SiamFCv2的性能随着运动类别的增加而显著提高。 SiamFCv2 MemTracker是完全从头开始训练的,它们对训练数据的多样性有更高的依赖性。此外,MemTracker从大量的视频数据中学习动态记忆的建模,这可能是MemTracker比其他跟踪器对训练数据中的运动多样性具有更高的依赖性的原因。
关于平衡与不平衡数据的训练。
我们认为这是因为深度跟踪器的泛化能力受到数据多样性的几个方面的影响,如目标和运动类的多样性、场景和挑战性属性的多样性,单独的目标类分布对深度跟踪器性能的影响可能是有限的。