【Python】机器学习笔记11-核密度估计(Kernel Density Estimation)
本文的参考资料:《Python数据科学手册》;
本文的源代上传到了Gitee上;
本文用到的包:
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
from cartopy.mpl.geoaxes import GeoAxesSubplot
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.datasets import fetch_species_distributions, load_digits
from sklearn.model_selection import GridSearchCV, LeaveOneOut, train_test_split
from sklearn.neighbors import KernelDensity
sns.set()
plt.rc('font', family='SimHei')
plt.rc('axes', unicode_minus=False)
核密度估计(Kernel Density Estimation)
密度评估器是一种利用D维数据集生成D维概率分布估计的算法,GMM使用不同的高斯分布的加权汇总来表示概率分布估计。
核密度估计算法将高斯混合理念扩展到了逻辑极限,它通过对每一个点生成高斯分布的混合成分,获得本实质上是无参数的密度评估器(书本原话)。
核密度估计的自由参数是核类型和核带宽,前者指定每个点核密度分布的形状,后者指定每个点核的大小。
上边是书上讲的话,下面是我的理解:
核密度估计本质上是从有限的样本中尽可能地估算概率密度函数,类似于让直方图的区间趋向无穷小后得到的图形,当然由于样本数量是有限的不能直接实现这样的操作。
核密度估计示例
核密度估计在sklearn中由KernelDensity类实现,kernel参数指定需要用到的核函数,来适应不同的需求;
以下代码生成一组高斯分布的随机数据,分别绘制其直方图与KDE图,查看效果;
x_train = np.hstack((np.random.normal(2, 1.66, 200), np.random.normal(8, 2.33, 200))) # 两个高斯分布组合到一起
model = KernelDensity(bandwidth=1.0, kernel='gaussian')
model.fit(x_train[:, np.newaxis])
x_range = np.linspace(x_train.min() - 1, x_train.max() + 1, 500)
x_log_prob = model.score_samples(x_range[:, np.newaxis]) # 这个东西返回概率的对数
x_prob = np.exp(x_log_prob)
plt.figure(figsize=(10, 10))
r = plt.hist(
x=x_train,
bins=50,
density=True,
histtype='stepfilled',
color='red',
alpha=0.5,
label='直方图',
)
plt.fill_between(
x=x_range,
y1=x_prob,
y2=0,
color='green',
alpha=0.5,
label='KDE',
)
plt.plot(x_range, x_prob, color='gray')
plt.vlines(x=2, ymin=0, ymax=r[0].max() + 0.01, color='k', linestyle='--', alpha=0.7) # 分布中心
plt.vlines(x=8, ymin=0, ymax=r[0].max() + 0.01, color='k', linestyle='--', alpha=0.7) # 分布中心
plt.ylim(0, r[0].max() + 0.011)
plt.legend(loc='upper right')
plt.title('同一组数据的直方图与KDE图')

使用交叉检验确定带宽
在使用核密度估计时,如果带宽设置过小,会出现过拟合的现象,如果带宽设置过大,会出现欠拟合的现象,因此需要确定好最佳的带宽;
sklearn中的KernelDensity类支持使用GridSearchCV来寻找最佳参数,以下是一个示例:
x_train = np.hstack((np.random.normal(2, 1.66, 200), np.random.normal(8, 2.33, 200)))
grid = GridSearchCV(
estimator=KernelDensity(kernel='gaussian'),
param_grid={'bandwidth': 10 ** np.linspace(-1, 1, 100)},
cv=LeaveOneOut(),
)
grid.fit(x_train[:, np.newaxis])
print(f'最佳带宽:{grid.best_params_["bandwidth"]}')
输出结果:
最佳带宽:0.7742636826811272
在球形空间中使用KDE
从sklearn中加载物种分布数据(fetch_species_distributions函数),返回的数据中包含了森林小稻鼠和褐喉树懒在南美中的分布数据;
我们将用KDE从这些分布数据中计算这两个物种的分布密度,并显示在地图上(还真是在球面上的数据);
由于书本介绍的Basemap已经停止维护了,所以这里我是用了cartopy这个库来显示地图(费了不少力气);
书本代码用到了一个在如今的sklearn中已经被废弃的函数construct_grids,我从网上找到了它的源码,凑合用一下;
def construct_grids(batch): # 这个函数在现在版本的sklearn中被废弃了,从网上找到了以前的源码
"""Construct the map grid from the batch object
Parameters
----------
batch : Batch object
The object returned by :func:`fetch_species_distributions`
Returns
-------
(xgrid, ygrid) : 1-D arrays
The grid corresponding to the values in batch.coverages
"""
# x,y coordinates for corner cells
xmin = batch.x_left_lower_corner + batch.grid_size
xmax = xmin + (batch.Nx * batch.grid_size)
ymin = batch.y_left_lower_corner + batch.grid_size
ymax = ymin + (batch.Ny * batch.grid_size)
# x coordinates of the grid cells
xgrid = np.arange(xmin, xmax, batch.grid_size)
# y coordinates of the grid cells
ygrid = np.arange(ymin, ymax, batch.grid_size)
return xgrid, ygrid
species_data = fetch_species_distributions()
species_names = ['褐喉树懒', '森林小稻鼠']
lat_and_lon = np.vstack((
species_data.train['dd lat'],
species_data.train['dd long'],
)).T
species_train = np.array([
d.decode('ascii').startswith('micro') # 这样写的话,森林小稻鼠(microryzomys minutus)就是1,褐喉树懒(bradypus variegatus)就是0
for d in species_data.train['species']
], dtype=np.int)
fig = plt.figure(figsize=(20, 10)) # type: plt.Figure
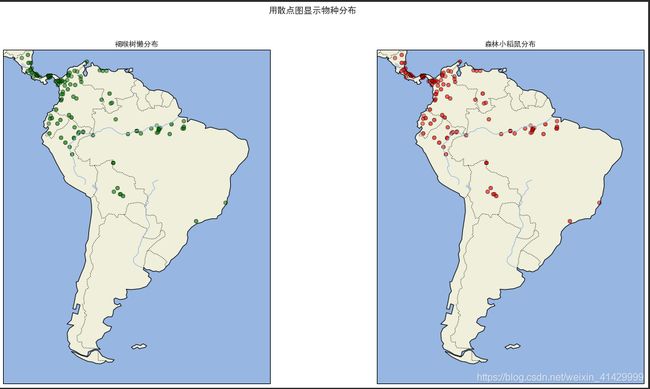
fig.suptitle('用散点图显示物种分布')
for i in range(2):
ax = fig.add_subplot(1, 2, i + 1, projection=ccrs.PlateCarree()) # type: GeoAxesSubplot
ax.set_extent([-30, -90, 15, -60], crs=ccrs.PlateCarree()) # 南美洲的经纬度
ax.add_feature(cfeature.LAND)
ax.add_feature(cfeature.OCEAN)
ax.add_feature(cfeature.COASTLINE)
ax.add_feature(cfeature.BORDERS, linestyle=':')
ax.add_feature(cfeature.LAKES, alpha=0.5)
ax.add_feature(cfeature.RIVERS)
ax.scatter(
x=lat_and_lon[:, 1][species_train==0], y=lat_and_lon[:, 0][species_train==0],
c='green' if i == 0 else 'red', cmap='rainbow', edgecolor='k', alpha=0.1
)
ax.set_title(f'{species_names[i]}分布')
x_grid, y_grid = construct_grids(species_data)
X, Y = np.meshgrid(x_grid[::5], y_grid[::5][::-1])
land_reference = species_data.coverages[6][::5, ::5]
land_mask = (land_reference > -9999).ravel() # -9999代表的区域是海洋
xy = np.vstack((Y.ravel(), X.ravel())).T
xy = np.radians(xy[land_mask])
fig = plt.figure(figsize=(20, 10)) # type: plt.Figure
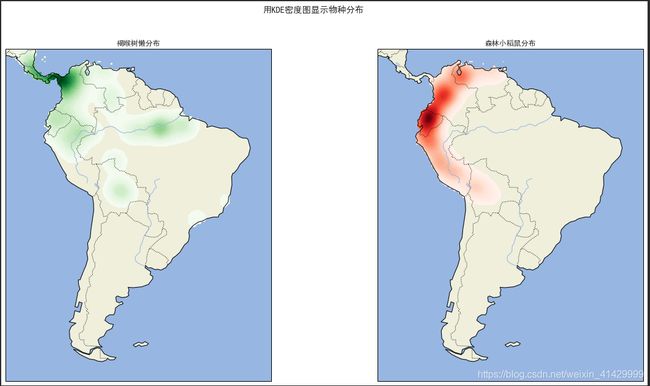
fig.suptitle('用KDE密度图显示物种分布')
for i in range(2):
ax = fig.add_subplot(1, 2, i + 1, projection=ccrs.PlateCarree()) # type: GeoAxesSubplot
ax.set_extent([-30, -90, 15, -60], crs=ccrs.PlateCarree()) # 南美洲的经纬度
ax.add_feature(cfeature.LAND)
ax.add_feature(cfeature.OCEAN)
ax.add_feature(cfeature.COASTLINE)
ax.add_feature(cfeature.BORDERS, linestyle=':')
ax.add_feature(cfeature.LAKES, alpha=0.5)
ax.add_feature(cfeature.RIVERS)
kde = KernelDensity(bandwidth=0.03, metric='haversine') # 一个球形空间的KDE
kde.fit(np.radians(lat_and_lon[species_train == i]))
Z = np.full(land_mask.shape[0], -9999)
Z[land_mask] = np.exp(kde.score_samples(xy))
Z = Z.reshape(X.shape)
ax.contourf(
X, Y, Z,
levels=np.linspace(0, Z.max(), 50),
cmap='Greens' if i == 0 else 'Reds',
)
ax.set_title(f'{species_names[i]}分布')
fig.savefig('GIS.png')
结果:
案例:不是很朴素的贝叶斯
朴素贝叶斯分类为每一个类创建了一个简单的生成模型,并用这些模型构建了一个快速的分类器。在朴素贝叶斯分类中,生成模型是与坐标轴平行的某种分布(高斯分布、多项式分布、etc)。
如果利用KDE这样的核密度估计算法,我们就可以去掉“朴素”的成分,使用更成熟的生成模型描述每一个类。虽然它还是贝叶斯分类,但是它不再NAIVE!
步骤如下:
- 通过标签将训练数据分割成为若干个集合
- 为每一个集合你和一个KDE模型来获得其生成模型,获得 P ( x ∣ y ) P(x|y) P(x∣y)
- 根据没一个集合中的样本数量,计算先验概率 P ( y ) P(y) P(y)
- 对于每一个未知数据,计算 P ( x ∣ y ) P ( y ) P(x|y)P(y) P(x∣y)P(y),并将其分配给概率最大的标签
(好神奇)
使用网格搜索找到最佳参数后,这个自定义的KDE贝叶斯分类器对于sklearn手写数字的分类准确率可以达到96.7%,如果只是使用高斯朴素贝叶斯进行分类的话准确率只有85%(之前做过);
当然,我们的模型还存在改进空间,比如可以允许每一类的KDE带宽各不相同;
class KDEClassifier(BaseEstimator, ClassifierMixin):
"""
bandwidth: 用于KDE模型的带宽
kernel: 用于KDE模型的核函数名称
"""
def __init__(self, bandwidth=1.0, kernel='gaussian'):
self.bandwidth = bandwidth
self.kernel = kernel
self.classes_ = None
self.models_ = None
self.logpriors_ = None
def fit(self, X, y):
self.classes_ = np.sort(np.unique(y)) # 找到所有的类
training_sets = [X[y == yi] for yi in self.classes_]
# 为每一个类训练一个KDE,从样本中计算每一个类在D维空间中出现的概率密度
self.models_ = [KernelDensity(bandwidth=self.bandwidth, kernel=self.kernel).fit(Xi) for Xi in training_sets]
self.logpriors_ = [np.log(Xi.shape[0] / X.shape[0]) for Xi in training_sets] # 根据样本数量计算每一个类的先验概率
return self
def predict_proba(self, X):
logprobs = np.array([
m.score_samples(X) for m in self.models_ # 计算输入样本作为每一个类在其所在位置出现的概率
]).T
result = np.exp(logprobs + self.logpriors_) # 概率的对数相加,等于概率相乘,乘以每一个类的先验概率
return result / result.sum(axis=1, keepdims=True)
def predict(self, X):
return self.classes_[np.argmax(self.predict_proba(X), axis=1)] # 找概率最大的那一个类
digits = load_digits()
bandwidths = 10 ** np.linspace(0, 2, 100)
grid = GridSearchCV(estimator=KDEClassifier(), param_grid={'bandwidth': bandwidths}, cv=5)
grid.fit(digits.data, digits.target)
#%%
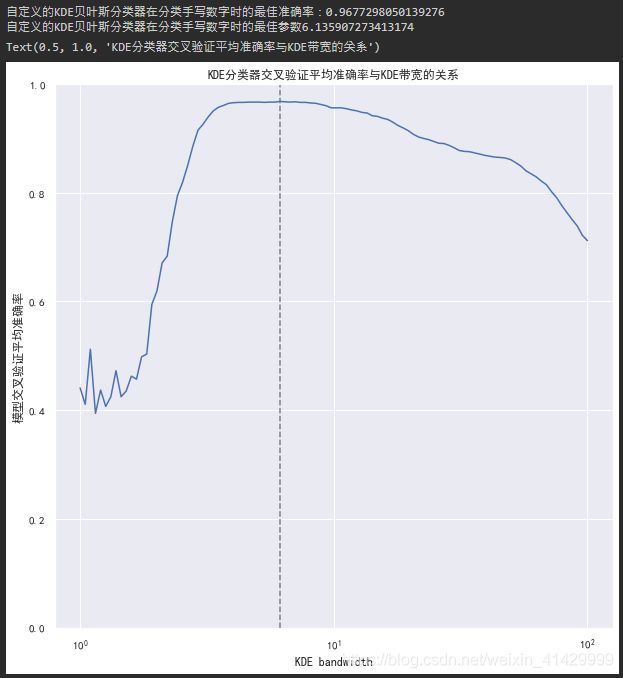
print(f'自定义的KDE贝叶斯分类器在分类手写数字时的最佳准确率:{grid.best_score_}')
print(f'自定义的KDE贝叶斯分类器在分类手写数字时的最佳参数{grid.best_params_["bandwidth"]}')
plt.figure(figsize=(10, 10))
plt.semilogx(bandwidths, grid.cv_results_['mean_test_score'])
plt.vlines(x=grid.best_params_['bandwidth'], ymin=0, ymax=1, color='gray', linestyle='--')
plt.xlabel('KDE bandwidth')
plt.ylabel('模型交叉验证平均准确率')
plt.ylim(0, 1)
plt.title('KDE分类器交叉验证平均准确率与KDE带宽的关系')
完整代码(Jupyter Notebook)
#%% md
# 核密度估计
密度评估器是一种利用D维数据集生成D维概率分布估计的算法,GMM使用不同的高斯分布的加权汇总来表示概率分布估计。
核密度估计算法将高斯混合理念扩展到了逻辑极限,它通过对每一个点生成高斯分布的混合成分,获得本实质上是无参数的密度评估器。
核密度估计的自由参数是核类型和核带宽,前者指定每个点核密度分布的形状,后者指定每个点核的大小。
上边是书上讲的话,下面是我的理解:<br>
核密度估计本质上是从有限的样本中尽可能地估算概率密度函数,类似于让直方图的区间趋向无穷小后得到的图形,当然由于样本数量是有限的无法实现这样的操作。
## 核密度估计示例
以下代码生成一组高斯分布的随机数据,分别绘制其直方图与KDE图,查看效果;
#%%
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
from cartopy.mpl.geoaxes import GeoAxesSubplot
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.datasets import fetch_species_distributions, load_digits
from sklearn.model_selection import GridSearchCV, LeaveOneOut, train_test_split
from sklearn.neighbors import KernelDensity
sns.set()
plt.rc('font', family='SimHei')
plt.rc('axes', unicode_minus=False)
#%%
x_train = np.hstack((np.random.normal(2, 1.66, 200), np.random.normal(8, 2.33, 200)))
model = KernelDensity(bandwidth=1.0, kernel='gaussian')
model.fit(x_train[:, np.newaxis])
x_range = np.linspace(x_train.min() - 1, x_train.max() + 1, 500)
x_log_prob = model.score_samples(x_range[:, np.newaxis]) # 这个东西返回概率的对数
x_prob = np.exp(x_log_prob)
print(x_range.shape)
print(x_log_prob.shape)
plt.figure(figsize=(10, 10))
r = plt.hist(
x=x_train,
bins=50,
density=True,
histtype='stepfilled',
color='red',
alpha=0.5,
label='直方图',
)
plt.fill_between(
x=x_range,
y1=x_prob,
y2=0,
color='green',
alpha=0.5,
label='KDE',
)
plt.plot(x_range, x_prob, color='gray')
plt.vlines(x=2, ymin=0, ymax=r[0].max() + 0.01, color='k', linestyle='--', alpha=0.7)
plt.vlines(x=8, ymin=0, ymax=r[0].max() + 0.01, color='k', linestyle='--', alpha=0.7)
plt.ylim(0, r[0].max() + 0.011)
plt.legend(loc='upper right')
plt.title('同一组数据的直方图与KDE图')
#%% md
## 使用交叉检验确定带宽
在使用核密度估计时,如果带宽设置过小,会出现过拟合的现象,如果带宽设置过大,会出现欠拟合的现象,因此需要确定好最佳的带宽;
sklearn中的KernelDensity类支持使用GridSearchCV来寻找最佳参数;
#%%
x_train = np.hstack((np.random.normal(2, 1.66, 200), np.random.normal(8, 2.33, 200)))
grid = GridSearchCV(
estimator=KernelDensity(kernel='gaussian'),
param_grid={'bandwidth': 10 ** np.linspace(-1, 1, 100)},
cv=LeaveOneOut(),
)
grid.fit(x_train[:, np.newaxis])
print(f'最佳带宽:{grid.best_params_["bandwidth"]}')
#%% md
## 在球形空间中使用KDE
从sklearn中加载物种分布数据(fetch_species_distributions),返回的数据中包含了森林小稻鼠和褐喉树懒在南美中的分布数据;
我们将用KDE从这些分布数据中计算这两个物种的分布密度,并显示在地图上;
由于书本介绍的Basemap已经停止维护了,所以这里我是用了cartopy这个库来显示地图;
书本代码用到了一个在如今的sklearn中已经被废弃的函数construct_grids,我从网上找到了它的源码,凑合用一下;
#%%
def construct_grids(batch): # 这个函数在现在版本的sklearn中被废弃了,从网上找到了以前的源码
"""Construct the map grid from the batch object
Parameters
----------
batch : Batch object
The object returned by :func:`fetch_species_distributions`
Returns
-------
(xgrid, ygrid) : 1-D arrays
The grid corresponding to the values in batch.coverages
"""
# x,y coordinates for corner cells
xmin = batch.x_left_lower_corner + batch.grid_size
xmax = xmin + (batch.Nx * batch.grid_size)
ymin = batch.y_left_lower_corner + batch.grid_size
ymax = ymin + (batch.Ny * batch.grid_size)
# x coordinates of the grid cells
xgrid = np.arange(xmin, xmax, batch.grid_size)
# y coordinates of the grid cells
ygrid = np.arange(ymin, ymax, batch.grid_size)
return xgrid, ygrid
species_data = fetch_species_distributions()
species_names = ['褐喉树懒', '森林小稻鼠']
lat_and_lon = np.vstack((
species_data.train['dd lat'],
species_data.train['dd long'],
)).T
species_train = np.array([
d.decode('ascii').startswith('micro') # 这样写的话,森林小稻鼠(microryzomys minutus)就是1,褐喉树懒(bradypus variegatus)就是0
for d in species_data.train['species']
], dtype=np.int)
fig = plt.figure(figsize=(20, 10)) # type: plt.Figure
fig.suptitle('用散点图显示物种分布')
for i in range(2):
ax = fig.add_subplot(1, 2, i + 1, projection=ccrs.PlateCarree()) # type: GeoAxesSubplot
ax.set_extent([-30, -90, 15, -60], crs=ccrs.PlateCarree()) # 南美洲的经纬度
ax.add_feature(cfeature.LAND)
ax.add_feature(cfeature.OCEAN)
ax.add_feature(cfeature.COASTLINE)
ax.add_feature(cfeature.BORDERS, linestyle=':')
ax.add_feature(cfeature.LAKES, alpha=0.5)
ax.add_feature(cfeature.RIVERS)
ax.scatter(
x=lat_and_lon[:, 1][species_train==0], y=lat_and_lon[:, 0][species_train==0],
c='green' if i == 0 else 'red', cmap='rainbow', edgecolor='k', alpha=0.1
)
ax.set_title(f'{species_names[i]}分布')
x_grid, y_grid = construct_grids(species_data)
X, Y = np.meshgrid(x_grid[::5], y_grid[::5][::-1])
land_reference = species_data.coverages[6][::5, ::5]
land_mask = (land_reference > -9999).ravel()
xy = np.vstack((Y.ravel(), X.ravel())).T
xy = np.radians(xy[land_mask])
fig = plt.figure(figsize=(20, 10)) # type: plt.Figure
fig.suptitle('用KDE密度图显示物种分布')
for i in range(2):
ax = fig.add_subplot(1, 2, i + 1, projection=ccrs.PlateCarree()) # type: GeoAxesSubplot
ax.set_extent([-30, -90, 15, -60], crs=ccrs.PlateCarree()) # 南美洲的经纬度
ax.add_feature(cfeature.LAND)
ax.add_feature(cfeature.OCEAN)
ax.add_feature(cfeature.COASTLINE)
ax.add_feature(cfeature.BORDERS, linestyle=':')
ax.add_feature(cfeature.LAKES, alpha=0.5)
ax.add_feature(cfeature.RIVERS)
kde = KernelDensity(bandwidth=0.03, metric='haversine') # 一个球形空间的KDE
kde.fit(np.radians(lat_and_lon[species_train == i]))
Z = np.full(land_mask.shape[0], -9999)
Z[land_mask] = np.exp(kde.score_samples(xy))
Z = Z.reshape(X.shape)
ax.contourf(
X, Y, Z,
levels=np.linspace(0, Z.max(), 50),
cmap='Greens' if i == 0 else 'Reds',
)
ax.set_title(f'{species_names[i]}分布')
fig.savefig('GIS.png')
#%% md
## 案例:不是很朴素的贝叶斯
朴素贝叶斯分类为每一个类创建了一个简单的生成模型,并用这些模型构建了一个快速的分类器。在朴素贝叶斯分类中,生成模型是与坐标轴平行的某种分布(高斯分布、多项式分布、etc)。
如果利用KDE这样的核密度估计算法,我们就可以去掉“朴素”的成分,使用更成熟的生成模型描述每一个类。虽然它还是贝叶斯分类,但是它不再NAIVE!
步骤如下:
- 通过标签将训练数据分割成为若干个集合
- 为每一个集合你和一个KDE模型来获得其生成模型,获得$P(x|y)$
- 根据没一个集合中的样本数量,计算先验概率$P(y)$
- 对于每一个未知数据,计算$P(x|y)P(y)$,并将其分配给概率最大的标签
(好神奇)
最后,这个自定义的KDE贝叶斯分类器对于sklearn手写数字的分类准确率可以达到96%,如果只是使用高斯朴素贝叶斯进行分类的话准确率只有85%(之前做过);
当然,我们的模型还存在改进空间,比如可以允许每一类的KDE带宽各不相同;
#%%
class KDEClassifier(BaseEstimator, ClassifierMixin):
"""
bandwidth: 用于KDE模型的带宽
kernel: 用于KDE模型的核函数名称
"""
def __init__(self, bandwidth=1.0, kernel='gaussian'):
self.bandwidth = bandwidth
self.kernel = kernel
self.classes_ = None
self.models_ = None
self.logpriors_ = None
def fit(self, X, y):
self.classes_ = np.sort(np.unique(y)) # 找到所有的类
training_sets = [X[y == yi] for yi in self.classes_]
# 为每一个类训练一个KDE,从样本中计算每一个类在D维空间中出现的概率密度
self.models_ = [KernelDensity(bandwidth=self.bandwidth, kernel=self.kernel).fit(Xi) for Xi in training_sets]
self.logpriors_ = [np.log(Xi.shape[0] / X.shape[0]) for Xi in training_sets] # 根据样本数量计算每一个类的先验概率
return self
def predict_proba(self, X):
logprobs = np.array([
m.score_samples(X) for m in self.models_ # 计算输入样本作为每一个类在其所在位置出现的概率
]).T
result = np.exp(logprobs + self.logpriors_) # 概率的对数相加,等于概率相乘,乘以每一个类的先验概率
return result / result.sum(axis=1, keepdims=True)
def predict(self, X):
return self.classes_[np.argmax(self.predict_proba(X), axis=1)] # 找概率最大的那一个类
digits = load_digits()
bandwidths = 10 ** np.linspace(0, 2, 100)
grid = GridSearchCV(estimator=KDEClassifier(), param_grid={'bandwidth': bandwidths}, cv=5)
grid.fit(digits.data, digits.target)
#%%
print(f'自定义的KDE贝叶斯分类器在分类手写数字时的最佳准确率:{grid.best_score_}')
print(f'自定义的KDE贝叶斯分类器在分类手写数字时的最佳参数{grid.best_params_["bandwidth"]}')
plt.figure(figsize=(10, 10))
plt.semilogx(bandwidths, grid.cv_results_['mean_test_score'])
plt.vlines(x=grid.best_params_['bandwidth'], ymin=0, ymax=1, color='gray', linestyle='--')
plt.xlabel('KDE bandwidth')
plt.ylabel('模型交叉验证平均准确率')
plt.ylim(0, 1)
plt.title('KDE分类器交叉验证平均准确率与KDE带宽的关系')