深度学习(莫烦 神经网络 lecture 3) Keras
神经网络 & Keras
目录
- 神经网络 & Keras
- 目录
- 1、Keras简介
- 1.1 科普: 人工神经网络 VS 生物神经网络
- 1.2 什么是神经网络 (Neural Network)
- 1.3 神经网络 梯度下降
- 1.4 科普: 神经网络的黑盒不黑
- 1.5 Why Keras?
- 1.6 兼容 backend
- 2、如何搭建各种神经网络
- 2.1 Regressor回归
- 2.2 Classifier 分类
- 2.3 什么是卷积神经网络 CNN
- 2.4 CNN 卷积神经网络
- 2.5 什么是循环神经网络 RNN
- 2.6 什么是 LSTM 循环神经网络
- 2.7 RNN Classifier
- 2.8 RNN Regressor
- 2.9什么是自编码(Autoencoder)
- 2.10 Autoencoder 自编码
- 1、Keras简介
1、Keras简介
1.1 科普: 人工神经网络 VS 生物神经网络
9百亿神经细胞组成了我们复杂的神经网络系统, 这个数量甚至可以和宇宙中的星球数相比较

1.2 什么是神经网络 (Neural Network)
是存在于计算机里的神经系统
1.3 神经网络 梯度下降
optimization
牛顿法 (Newton’s method), 最小二乘法(Least Squares method), 梯度下降法 (Gradient Descent) 等等
梯度下降
全局 and 局部最优
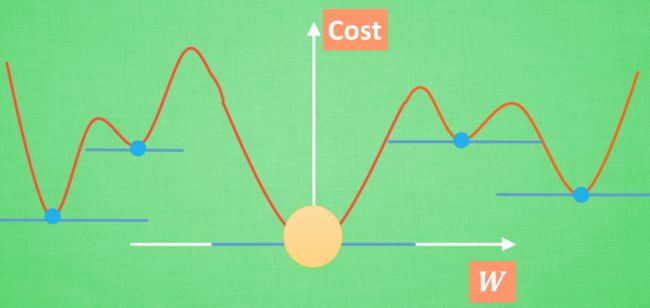
神经网络能让你的局部最优足够优秀
1.4 科普: 神经网络的黑盒不黑
将神经网络第一层加工后的宝宝叫做代表特征(feature representation)
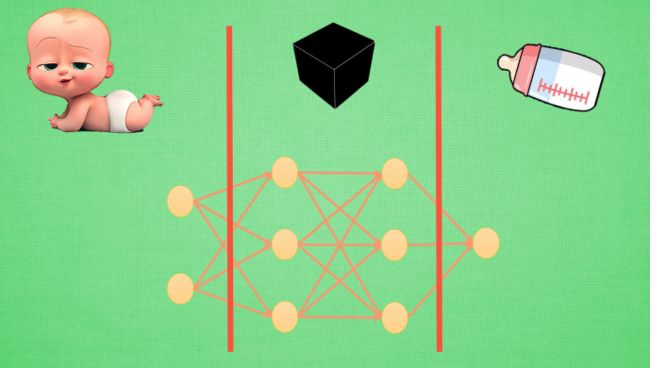
与其说黑盒是在加工处理, 还不如说是在将一种代表特征转换成另一种代表特征, 一次次特征之间的转换

1.5 Why Keras?
如果说 Tensorflow 或者 Theano 是神经网络方面的巨人. 那 Keras 就是站在巨人肩膀上的人.
Keras 是一个兼容 Theano 和 Tensorflow 的神经网络高级包, 用他来组件一个神经网络更加快速, 几条语句就搞定了.
而且广泛的兼容性能使 Keras 在 Windows 和 MacOS 或者 Linux 上运行无阻碍.
1.6 兼容 backend
我们来介绍 Keras 的两个 Backend,也就是Keras基于什么东西来做运算。Keras 可以基于两个Backend,一个是 Theano,一个是 Tensorflow。
如果我们选择Theano作为Keras的Backend, 那么Keras就用 Theano 在底层搭建你需要的神经网络;同样,如果选择 Tensorflow 的话呢,Keras 就使用 Tensorflow 在底层搭建神经网络。
import keras
Using Theano Backend
可以修改 Backend
2、如何搭建各种神经网络
2.1 Regressor回归
神经网络可以用来模拟回归问题 (regression),例如给下面一组数据,用一条线来对数据进行拟合,并可以预测新输入 x 的输出值。
"""1、导入模块、创建数据"""
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
# create some data
X = np.linspace(-1, 1, 200)
np.random.shuffle(X) # randomize the data
Y = 0.5 * X + 2 + np.random.normal(0, 0.05, (200, ))
# plot data
plt.scatter(X, Y)
plt.show()
X_train, Y_train = X[:160], Y[:160] # first 160 data points
X_test, Y_test = X[160:], Y[160:] # last 40 data points
"""2、建立模型"""
# build a neural network from the 1st layer to the last layer
model = Sequential()
model.add(Dense(units=1, input_dim=1))
# choose loss function and optimizing method
model.compile(loss='mse', optimizer='sgd')
"""3、训练、评估"""
# training
print('Training -----------')
for step in range(301):
cost = model.train_on_batch(X_train, Y_train)
if step % 100 == 0:
print('train cost: ', cost)
# test
print('\nTesting ------------')
cost = model.evaluate(X_test, Y_test, batch_size=40)
print('test cost:', cost)
"""4、预测新样本"""
W, b = model.layers[0].get_weights()
print('Weights=', W, '\nbiases=', b)
# plotting the prediction
Y_pred = model.predict(X_test)
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred)
plt.show()

2.2 分类问题
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.optimizers import RMSprop
"""1、数据预处理
x变成0-1之间,y进行one-hot编码
"""
# download the mnist to the path '~/.keras/datasets/' if it is the first time to be called
# X shape (60,000 28x28), y shape (10,000, )
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# data pre-processing
X_train = X_train.reshape(X_train.shape[0], -1) / 255. # normalize
X_test = X_test.reshape(X_test.shape[0], -1) / 255. # normalize
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
"""2、建立模型
直接在模型里面加入多个层
"""
# Another way to build your neural net
model = Sequential([
Dense(32, input_dim=784),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
"""3、定义优化器、编译模型、训练"""
# Another way to define your optimizer
rmsprop = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
# We add metrics to get more results you want to see
model.compile(optimizer=rmsprop,
loss='categorical_crossentropy',
metrics=['accuracy'])
print('Training ------------')
# Another way to train the model
model.fit(X_train, y_train, epochs=2, batch_size=32)
"""4、评估模型"""
print('\nTesting ------------')
# Evaluate the model with the metrics we defined earlier
loss, accuracy = model.evaluate(X_test, y_test)
print('test loss: ', loss)
print('test accuracy: ', accuracy)
Using TensorFlow backend.
Training ------------
Epoch 1/2
60000/60000 [==============================] - 5s 84us/step - loss: 0.3434 - acc: 0.9046
Epoch 2/2
60000/60000 [==============================] - 4s 67us/step - loss: 0.1948 - acc: 0.9437
Testing ------------
10000/10000 [==============================] - 0s 35us/step
test loss: 0.174235421626
test accuracy: 0.9505
在回归网络中用到的是 model.add 一层一层添加神经层,今天的方法是直接在模型的里面加多个神经层。好比一个水管,一段一段的,数据是从上面一段掉到下面一段,再掉到下面一段。
优化器,可以是默认的,也可以是我们在上一步定义的。 损失函数,分类和回归问题的不一样,用的是交叉熵。 metrics,里面可以放入需要计算的 cost,accuracy,score 等。
2.3 什么是卷积神经网络 CNN
卷积
也就是说神经网络不再是对每个像素的输入信息做处理了,而是图片上每一小块像素区域进行处理, 这种做法加强了图片信息的连续性. 使得神经网络能看到图形, 而非一个点. 这种做法同时也加深了神经网络对图片的理解
池化
是一个筛选过滤的过程, 能将 layer 中有用的信息筛选出来, 给下一个层分析. 同时也减轻了神经网络的计算负担
2.4 CNN 卷积神经网络
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Activation, Convolution2D, MaxPooling2D, Flatten
from keras.optimizers import Adam
# download the mnist to the path '~/.keras/datasets/' if it is the first time to be called
# X shape (60,000 28x28), y shape (10,000, )
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# data pre-processing
X_train = X_train.reshape(-1, 1,28, 28)/255.
X_test = X_test.reshape(-1, 1,28, 28)/255.
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
"""1、建立模型 conv-pool-conv-pool-fc-fc"""
# Another way to build your CNN
model = Sequential()
# Conv layer 1 output shape (32, 28, 28)
model.add(Convolution2D(
batch_input_shape=(None, 1, 28, 28),
filters=32,
kernel_size=5,
strides=1,
padding='same', # Padding method
data_format='channels_first',
))
model.add(Activation('relu'))
# Pooling layer 1 (max pooling) output shape (32, 14, 14)
model.add(MaxPooling2D(
pool_size=2,
strides=2,
padding='same', # Padding method
data_format='channels_first',
))
# Conv layer 2 output shape (64, 14, 14)
model.add(Convolution2D(64, 5, strides=1, padding='same', data_format='channels_first'))
model.add(Activation('relu'))
# Pooling layer 2 (max pooling) output shape (64, 7, 7)
model.add(MaxPooling2D(2, 2, 'same', data_format='channels_first'))
# Fully connected layer 1 input shape (64 * 7 * 7) = (3136), output shape (1024)
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation('relu'))
# Fully connected layer 2 to shape (10) for 10 classes
model.add(Dense(10))
model.add(Activation('softmax'))
"""2、定义优化器、编译模型、训练"""
# Another way to define your optimizer
adam = Adam(lr=1e-4)
# We add metrics to get more results you want to see
model.compile(optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy'])
print('Training ------------')
# Another way to train the model
model.fit(X_train, y_train, epochs=1, batch_size=64,)
"""3、评估"""
print('\nTesting ------------')
# Evaluate the model with the metrics we defined earlier
loss, accuracy = model.evaluate(X_test, y_test)
print('\ntest loss: ', loss)
print('\ntest accuracy: ', accuracy)
Using TensorFlow backend.
Training ------------
Epoch 1/1
60000/60000 [==============================] - 557s 9ms/step - loss: 0.2698 - acc: 0.9265
Testing ------------
10000/10000 [==============================] - 44s 4ms/step
test loss: 0.0994714692663
test accuracy: 0.9691
2.5 什么是循环神经网络 RNN
今天我们会来聊聊在语言分析, 序列化数据中穿梭自如的循环神经网络 RNN(Recurrent Neural Network)
只想着斯蒂芬乔布斯这个名字 , 请你再把他逆序念出来. 斯布乔(*#&, 有点难吧. 这就说明, 对于预测, 顺序排列是多么重要. 我们可以预测下一个按照一定顺序排列的字, 但是打乱顺序, 我们就没办法分析自己到底在说什么了.
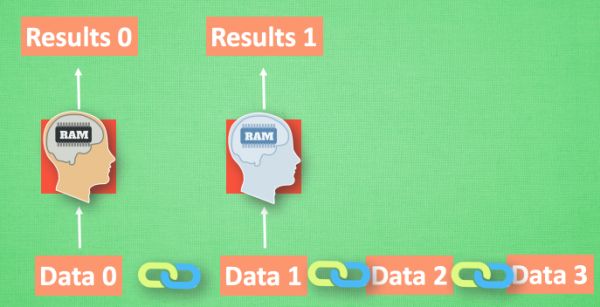
(1)序列数据

我们想象现在有一组序列数据 data 0,1,2,3. 在当预测 result0 的时候,我们基于的是 data0, 同样在预测其他数据的时候, 我们也都只单单基于单个的数据.* 每次使用的神经网络都是同一个 NN. *不过这些数据是有关联 顺序的 , 就像在厨房做菜, 酱料 A要比酱料 B 早放, 不然就串味了. 所以普通的神经网络结构并不能让 NN 了解这些数据之间的关联.
(2)处理序列数据的神经网络
那我们如何让数据间的关联也被 NN 加以分析呢? 想想我们人类是怎么分析各种事物的关联吧, 最基本的方式,就是记住之前发生的事情. 那我们让神经网络也具备这种记住之前发生的事的能力.
再分析 Data0 的时候, 我们把分析结果存入记忆. 然后当分析 data1的时候, NN会产生新的记忆, 但是新记忆和老记忆是没有联系的. 我们就简单的把老记忆调用过来, 一起分析. 如果继续分析更多的有序数据 , RNN就会把之前的记忆都累积起来, 一起分析.
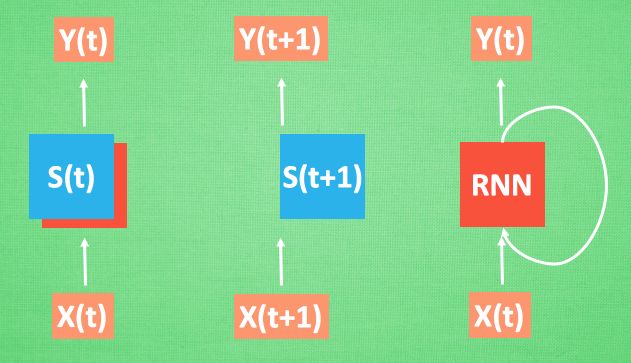
我们再重复一遍刚才的流程, 不过这次是以加入一些数学方面的东西. 每次 RNN 运算完之后都会产生一个对于当前状态的描述 , state. 我们用简写 S( t) 代替, 然后这个 RNN开始分析 x(t+1) , 他会根据 x(t+1)产生s(t+1), 不过此时 y(t+1) 是由 s(t) 和 s(t+1) 共同创造的. 所以我们通常看到的 RNN 也可以表达成这种样子.
(3)RNN的用途
RNN 的形式不单单这有这样一种, 他的结构形式很自由. 如果用于分类问题, 比如说一个人说了一句话, 这句话带的感情色彩是积极的还是消极的. 那我们就可以用只有最后一个时间点输出判断结果的RNN.
又或者这是图片描述 RNN, 我们只需要一个 X 来代替输入的图片, 然后生成对图片描述的一段话.
或者是语言翻译的 RNN, 给出一段英文, 然后再翻译成中文.
有了这些不同形式的 RNN, RNN 就变得强大了. 有很多有趣的 RNN 应用. 比如之前提到的, 让 RNN 描述照片. 让 RNN 写学术论文, 让 RNN 写程序脚本, 让 RNN 作曲. 我们一般人甚至都不能分辨这到底是不是机器写出来的.
2.6 什么是 LSTM 循环神经网络
今天我们会来聊聊在普通RNN的弊端和为了解决这个弊端而提出的 LSTM 技术. LSTM 是 long-short term memory 的简称, 中文叫做 长短期记忆. 是当下最流行的 RNN 形式之一
(1)RNN的弊端

之前我们说过, RNN 是在有顺序的数据上进行学习的. 为了记住这些数据, RNN 会像人一样产生对先前发生事件的记忆. 不过一般形式的 RNN 就像一个老爷爷, 有时候比较健忘. 为什么会这样呢?(在时间上梯度消失)

想像现在有这样一个 RNN, 他的输入值是一句话: ‘我今天要做红烧排骨, 首先要准备排骨, 然后…., 最后美味的一道菜就出锅了’, shua ~ 说着说着就流口水了. 现在请 RNN 来分析, 我今天做的到底是什么菜呢. RNN可能会给出“辣子鸡”这个答案. 由于判断失误, RNN就要开始学习 这个长序列 X 和 ‘红烧排骨’ 的关系 , 而RNN需要的关键信息 ”红烧排骨”却出现在句子开头,
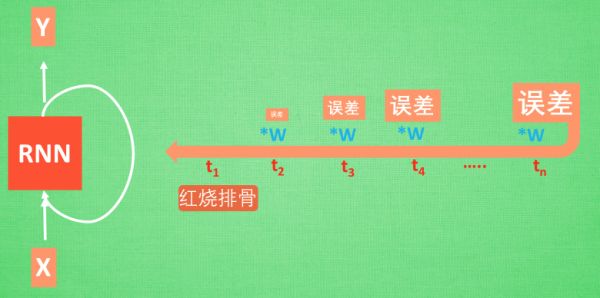
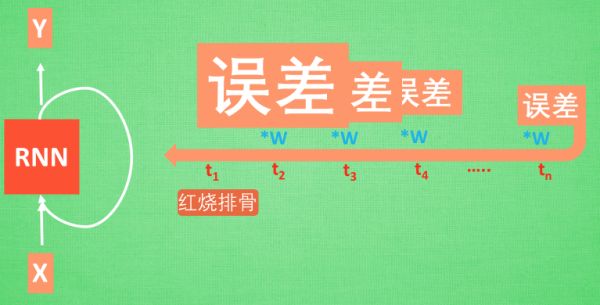
再来看看 RNN是怎样学习的吧. 红烧排骨这个信息原的记忆要经过长途跋涉才能抵达最后一个时间点. 然后我们得到误差, 而且在 反向传递 得到的误差的时候, 他在每一步都会 乘以一个自己的参数 W.
如果这个 W 是一个小于1 的数, 比如0.9. 这个0.9 不断乘以误差, 误差传到初始时间点也会是一个接近于零的数, 所以对于初始时刻, 误差相当于就消失了. 我们把这个问题叫做梯度消失或者梯度弥散 Gradient vanishing.
反之如果 W 是一个大于1 的数, 比如1.1 不断累乘, 则到最后变成了无穷大的数, RNN被这无穷大的数撑死了, 这种情况我们叫做剃度爆炸, Gradient exploding.
这就是普通 RNN 没有办法回忆起久远记忆的原因
(2)LSTM
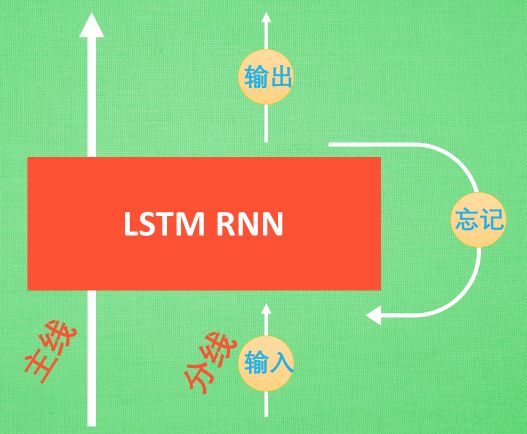
LSTM 就是为了解决这个问题而诞生的. LSTM 和普通 RNN 相比, 多出了三个控制器. (输入控制, 输出控制, 忘记控制). 现在, LSTM RNN 内部的情况是这样.
他多了一个 控制全局的记忆, 我们用粗线代替. 为了方便理解, 我们把粗线想象成电影或游戏当中的 主线剧情. 而原本的 RNN 体系就是 分线剧情. 三个控制器都是在原始的 RNN 体系上, 我们先看 输入方面 , 如果此时的分线剧情对于剧终结果十分重要, 输入控制就会将这个分线剧情按重要程度 写入主线剧情 进行分析. 再看 忘记方面, 如果此时的分线剧情更改了我们对之前剧情的想法, 那么忘记控制就会将之前的某些主线剧情忘记, 按比例替换成现在的新剧情. 所以 主线剧情的更新就取决于输入 和忘记 控制. 最后的输出方面, 输出控制会基于目前的主线剧情和分线剧情判断要输出的到底是什么.
基于这些控制机制, LSTM 就像延缓记忆衰退的良药, 可以带来更好的结果.
2.7 RNN Classifier
这次我们用循环神经网络(RNN, Recurrent Neural Networks)进行分类(classification),采用MNIST数据集,主要用到SimpleRNN层。
- MNIST里面的图像分辨率是28×28,为了使用RNN,我们将图像理解为序列化数据。 每一行作为一个输入单元,所以输入数据大小INPUT_SIZE = 28; 先是第1行输入,再是第2行,第3行,第4行,…,第28行输入, 这就是一张图片也就是一个序列,所以步长TIME_STEPS = 28。
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import SimpleRNN, Activation, Dense
from keras.optimizers import Adam
TIME_STEPS = 28 # same as the height of the image
INPUT_SIZE = 28 # same as the width of the image
BATCH_SIZE = 50
BATCH_INDEX = 0
OUTPUT_SIZE = 10
CELL_SIZE = 50
LR = 0.001
# download the mnist to the path '~/.keras/datasets/' if it is the first time to be called
# X shape (60,000 28x28), y shape (10,000, )
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# data pre-processing
X_train = X_train.reshape(-1, 28, 28) / 255. # normalize
X_test = X_test.reshape(-1, 28, 28) / 255. # normalize
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
"""1、建立模型"""
# build RNN model
model = Sequential()
# RNN cell
model.add(SimpleRNN(
# for batch_input_shape, if using tensorflow as the backend, we have to put None for the batch_size.
# Otherwise, model.evaluate() will get error.
batch_input_shape=(None, TIME_STEPS, INPUT_SIZE), # Or: input_dim=INPUT_SIZE, input_length=TIME_STEPS,
output_dim=CELL_SIZE,
unroll=True,
))
# output layer
model.add(Dense(OUTPUT_SIZE))
model.add(Activation('softmax'))
"""2、编译模型、训练"""
# optimizer
adam = Adam(LR)
model.compile(optimizer=adam,
loss='categorical_crossentropy',
metrics=['accuracy'])
# training
for step in range(4001):
# data shape = (batch_num, steps, inputs/outputs)
X_batch = X_train[BATCH_INDEX: BATCH_INDEX+BATCH_SIZE, :, :]
Y_batch = y_train[BATCH_INDEX: BATCH_INDEX+BATCH_SIZE, :]
cost = model.train_on_batch(X_batch, Y_batch)
BATCH_INDEX += BATCH_SIZE
BATCH_INDEX = 0 if BATCH_INDEX >= X_train.shape[0] else BATCH_INDEX
if step % 500 == 0:
cost, accuracy = model.evaluate(X_test, y_test, batch_size=y_test.shape[0], verbose=False)
print('test cost: ', cost, 'test accuracy: ', accuracy)
test cost: 2.40573239326 test accuracy: 0.0390999987721
test cost: 0.608026027679 test accuracy: 0.817900002003
test cost: 0.450786024332 test accuracy: 0.864799976349
test cost: 0.341593921185 test accuracy: 0.899800002575
test cost: 0.343054682016 test accuracy: 0.898400008678
test cost: 0.27272310853 test accuracy: 0.92040002346
test cost: 0.299111783504 test accuracy: 0.908800005913
test cost: 0.228507757187 test accuracy: 0.932900011539
test cost: 0.243453606963 test accuracy: 0.927900016308
有兴趣的话可以修改BATCH_SIZE和CELL_SIZE的值,试试这两个参数对训练时间和精度的影响。
2.8 RNN Regressor
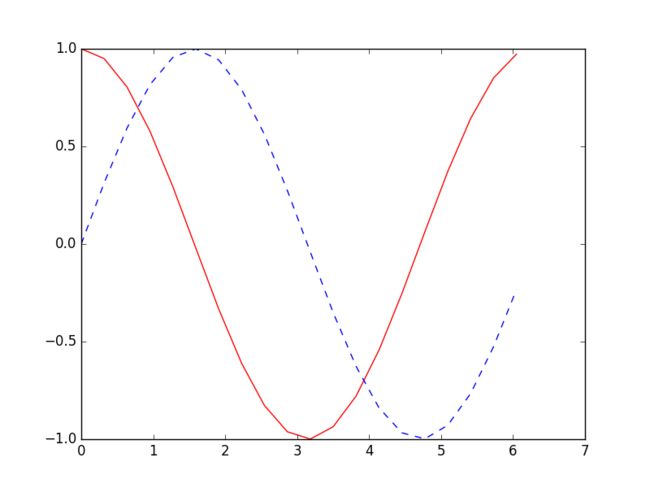
(1)生成序列
这次我们使用RNN来求解回归(Regression)问题. 首先生成序列sin(x),对应输出数据为cos(x),设置序列步长为20,每次训练的BATCH_SIZE为50.
(2)搭建模型
然后添加LSTM RNN层,输入为训练数据,输出数据大小由CELL_SIZE定义。因为每一个输入都对应一个输出,所以return_sequences=True。 每一个点的当前输出都受前面所有输出的影响,BATCH之间的参数也需要记忆,故stateful=True
model.add(LSTM(
batch_input_shape=(BATCH_SIZE, TIME_STEPS, INPUT_SIZE), # Or: input_dim=INPUT_SIZE, input_length=TIME_STEPS,
output_dim=CELL_SIZE,
return_sequences=True, # True: output at all steps. False: output as last step.
stateful=True, # True: the final state of batch1 is feed into the initial state of batch2
))
最后添加输出层,LSTM层的每一步都有输出,使用TimeDistributed函数。
model.add(TimeDistributed(Dense(OUTPUT_SIZE)))
- 1
import numpy as np
np.random.seed(1337) # for reproducibility
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import LSTM, TimeDistributed, Dense
from keras.optimizers import Adam
BATCH_START = 0
TIME_STEPS = 20
BATCH_SIZE = 50
INPUT_SIZE = 1
OUTPUT_SIZE = 1
CELL_SIZE = 20
LR = 0.006
"""1、生成序列"""
def get_batch():
global BATCH_START, TIME_STEPS
# xs shape (50batch, 20steps)
xs = np.arange(BATCH_START, BATCH_START+TIME_STEPS*BATCH_SIZE).reshape((BATCH_SIZE, TIME_STEPS)) / (10*np.pi)
seq = np.sin(xs)
res = np.cos(xs)
BATCH_START += TIME_STEPS
# plt.plot(xs[0, :], res[0, :], 'r', xs[0, :], seq[0, :], 'b--')
# plt.show()
return [seq[:, :, np.newaxis], res[:, :, np.newaxis], xs]
"""建立 LSTM模型"""
model = Sequential()
# build a LSTM RNN
model.add(LSTM(
batch_input_shape=(BATCH_SIZE, TIME_STEPS, INPUT_SIZE), # Or: input_dim=INPUT_SIZE, input_length=TIME_STEPS,
output_dim=CELL_SIZE,
return_sequences=True, # True: output at all steps. False: output as last step.
stateful=True, # True: the final state of batch1 is feed into the initial state of batch2
))
# add output layer
model.add(TimeDistributed(Dense(OUTPUT_SIZE)))
adam = Adam(LR)
model.compile(optimizer=adam,
loss='mse',)
print('Training ------------')
for step in range(501):
# data shape = (batch_num, steps, inputs/outputs)
X_batch, Y_batch, xs = get_batch()
cost = model.train_on_batch(X_batch, Y_batch)
pred = model.predict(X_batch, BATCH_SIZE)
plt.plot(xs[0, :], Y_batch[0].flatten(), 'r', xs[0, :], pred.flatten()[:TIME_STEPS], 'b--')
plt.ylim((-1.2, 1.2))
plt.draw()
plt.pause(0.1)
if step % 10 == 0:
print('train cost: ', cost)

train cost: 0.0412582

2.9什么是自编码(Autoencoder)
今天我们会来聊聊用神经网络如何进行非监督形式的学习. 也就是 autoencoder, 自编码.
有一个神经网络, 它在做的事情是 接收一张图片, 然后 给它打码, 最后 再从打码后的图片中还原. 太抽象啦? 行, 我们再具体点.

假设刚刚那个神经网络是这样, 对应上刚刚的图片, 可以看出图片其实是经过了压缩,再解压的这一道工序. 当压缩的时候, 原有的图片质量被缩减, 解压时用信息量小却包含了所有关键信息的文件恢复出原本的图片. 为什么要这样做呢?

原来有时神经网络要接受大量的输入信息, 比如输入信息是高清图片时, 输入信息量可能达到上千万, 让神经网络直接从上千万个信息源中学习是一件很吃力的工作. 所以, 何不压缩一下, 提取出原图片中的最具代表性的信息, 缩减输入信息量, 再把缩减过后的信息放进神经网络学习. 这样学习起来就简单轻松了.
所以, 自编码就能在这时发挥作用. 通过将原数据白色的X 压缩, 解压 成黑色的X, 然后通过对比黑白 X ,求出预测误差, 进行反向传递, 逐步提升自编码的准确性. 训练好的自编码中间这一部分就是能总结原数据的精髓. 可以看出, 从头到尾, 我们只用到了输入数据 X, 并没有用到 X 对应的数据标签, 所以也可以说自编码是一种非监督学习. 到了真正使用自编码的时候. 通常只会用到自编码前半部分.
(1)编码器encoder
这 部分也叫作 encoder 编码器. 编码器能得到原数据的精髓, 然后我们只需要再创建一个小的神经网络学习这个精髓的数据,不仅减少了神经网络的负担, 而且同样能达到很好的效果.
如果你了解 PCA 主成分分析, 再提取主要特征时, 自编码和它一样,甚至超越了 PCA. 换句话说, 自编码 可以像 PCA 一样 给特征属性降维.
(2)解码器 Decoder
至于解码器 Decoder, 我们也能那它来做点事情. 我们知道, 解码器在训练的时候是要将精髓信息解压成原始信息, 那么这就提供了一个解压器的作用, 甚至我们可以认为是一个生成器 (类似于GAN). 那做这件事的一种特殊自编码叫做 variational autoencoders, 你能在这里找到他的具体说明.
2.10 Autoencoder 自编码
自编码,简单来说就是把输入数据进行一个压缩和解压缩的过程。 原来有很多 Feature,压缩成几个来代表原来的数据,解压之后恢复成原来的维度,再和原数据进行比较。
它是一种非监督算法,只需要输入数据,解压缩之后的结果与原数据本身进行比较。
今天要做的事情是把 datasets.mnist 数据的 28×28=784 维的数据,压缩成 2 维的数据,然后在一个二维空间中可视化出分类的效果。
(1)建立模型
encoding_dim,要压缩成的维度

import numpy as np
np.random.seed(1337) # for reproducibility
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Dense, Input
import matplotlib.pyplot as plt
# download the mnist to the path '~/.keras/datasets/' if it is the first time to be called
# X shape (60,000 28x28), y shape (10,000, )
(x_train, _), (x_test, y_test) = mnist.load_data()
# data pre-processing
x_train = x_train.astype('float32') / 255. - 0.5 # minmax_normalized
x_test = x_test.astype('float32') / 255. - 0.5 # minmax_normalized
x_train = x_train.reshape((x_train.shape[0], -1))
x_test = x_test.reshape((x_test.shape[0], -1))
print(x_train.shape)
print(x_test.shape)
# in order to plot in a 2D figure
encoding_dim = 2
# this is our input placeholder
input_img = Input(shape=(784,))
# encoder layers
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(10, activation='relu')(encoded)
encoder_output = Dense(encoding_dim)(encoded)
# decoder layers
decoded = Dense(10, activation='relu')(encoder_output)
decoded = Dense(64, activation='relu')(decoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='tanh')(decoded)
# construct the autoencoder model
autoencoder = Model(input=input_img, output=decoded)
# construct the encoder model for plotting
encoder = Model(input=input_img, output=encoder_output)
# compile autoencoder
autoencoder.compile(optimizer='adam', loss='mse')
# training
autoencoder.fit(x_train, x_train,
epochs=20,
batch_size=256,
shuffle=True)
# plotting
encoded_imgs = encoder.predict(x_test)
plt.scatter(encoded_imgs[:, 0], encoded_imgs[:, 1], c=y_test)
plt.colorbar()
plt.show()
最后看到可视化的结果,自编码模型可以把这几个数字给区分开来,我们可以用自编码这个过程来作为一个特征压缩的方法,和PCA的功能一样,效果要比它好一些,因为它是非线性的结构。
Epoch 1/20
60000/60000 [==============================] - 5s 86us/step - loss: 0.0683
Epoch 2/20
60000/60000 [==============================] - 5s 78us/step - loss: 0.0565
Epoch 3/20
60000/60000 [==============================] - 5s 76us/step - loss: 0.0515
Epoch 4/20
60000/60000 [==============================] - 5s 88us/step - loss: 0.0478
Epoch 5/20
60000/60000 [==============================] - 4s 71us/step - loss: 0.0459
Epoch 6/20
60000/60000 [==============================] - 4s 66us/step - loss: 0.0445
Epoch 7/20
60000/60000 [==============================] - 4s 65us/step - loss: 0.0435
Epoch 8/20
60000/60000 [==============================] - 4s 66us/step - loss: 0.0427
Epoch 9/20
60000/60000 [==============================] - 4s 66us/step - loss: 0.0421
Epoch 10/20
60000/60000 [==============================] - 4s 71us/step - loss: 0.0416
Epoch 11/20
60000/60000 [==============================] - 4s 73us/step - loss: 0.0412
Epoch 12/20
60000/60000 [==============================] - 5s 78us/step - loss: 0.0410
Epoch 13/20
60000/60000 [==============================] - 5s 77us/step - loss: 0.0406
Epoch 14/20
60000/60000 [==============================] - 5s 81us/step - loss: 0.0403
Epoch 15/20
60000/60000 [==============================] - 4s 66us/step - loss: 0.0401
Epoch 16/20
60000/60000 [==============================] - 4s 66us/step - loss: 0.0398
Epoch 17/20
60000/60000 [==============================] - 5s 79us/step - loss: 0.0395
Epoch 18/20
60000/60000 [==============================] - 4s 70us/step - loss: 0.0393
Epoch 19/20
60000/60000 [==============================] - 4s 70us/step - loss: 0.0392
Epoch 20/20
60000/60000 [==============================] - 4s 74us/step - loss: 0.0391

