第四次作业--猫狗挑战赛
ouc软件工程第四次作业-猫狗大战挑战赛
文章目录
- ouc软件工程第四次作业-猫狗大战挑战赛
-
- 一、谷歌 Colab 上完成猫狗大战VGG模型的迁移
-
-
- 1.1准备工作
- 1.2数据集下载
- 1.3.数据处理
- 1.4.创建 VGG Mode
- 1.5.修改最后一层,冻结前面层的参数
- 1.6 训练并测试全连接层
- 1.7.可视化模型预测结果
-
- 二、迁移学习——AI研习社猫狗挑战赛
-
- 2.1数据下载并解压:
- 2.2.创建损失函数和优化器时,使用Adam优化器:
- 2.3.对比赛的数据集进行测试:
- 2.4.测试结果:
- 2.5.改进的地方:
- 三、作业总结
一、谷歌 Colab 上完成猫狗大战VGG模型的迁移
1.1准备工作
这一部分是导入相应的包并判断是否存在GPU设备。

1.2数据集下载
这一部分是下载相关猫和狗的数据,训练集包含1800张图(猫的图片900张,狗的图片900张),测试集包含2000张图片。

1.3.数据处理
在使用CNN处理图像时,需要对图片进行预处理。图片将被整理成
![]()
的大小,同时还将进行归一化处理。datasets 用做加载图像数据,它可以以多线程(multi-thread)的形式从硬盘中读取数据,使用 mini-batch (将所有数据分批,然后按顺序处理图片) 的形式,在网络训练中向 GPU 输送。

查看数据的相关属性,训练集的类别分别为“cats”和“dogs”,标签为0代表猫,1代表狗。第三行输出了前五张图片的路径和类别,也可以查看训练集和测试集中图片的数量。

对数据进行初始化,train 数据一共有1800张图,每个batch是64张,valid 数据一共有2000张图,每个batch是5张。数据加载器结合了数据集和取样器,并且可以提供多个线程处理数据集。对测试集进行了遍历,共有400个batch,把第一个 batch 保存到 inputs_try, labels_try,可得第一个batch中的图片全为猫且大小为3x224x224。

显示 labels_try 的5张图片,即valid里第一个batch的5张图片:


1.4.创建 VGG Mode
使用预训练好的 VGG 模型。同时,为了展示 VGG 模型对本数据的预测结果,还下载了 ImageNet 1000 个类的 JSON 文件。

在这部分代码中,对输入的5个图片利用VGG模型进行预测,同时,使用softmax对结果进行处理,随后展示了识别结果。可以看到,识别结果是比较非常准确的。


1.5.修改最后一层,冻结前面层的参数
我们的目标是使用预训练好的模型,因此,需要把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。



1.6 训练并测试全连接层
包括三个步骤:
(1)创建损失函数和优化器;
其中损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签. 它不会为我们计算对数概率,适合最后一层是 log_softmax() 的网络.
(2)训练模型;
(3)测试模型。
先创建损失函数和优化器,并定义训练模型和使用训练模型进行训练


运行结果如图:
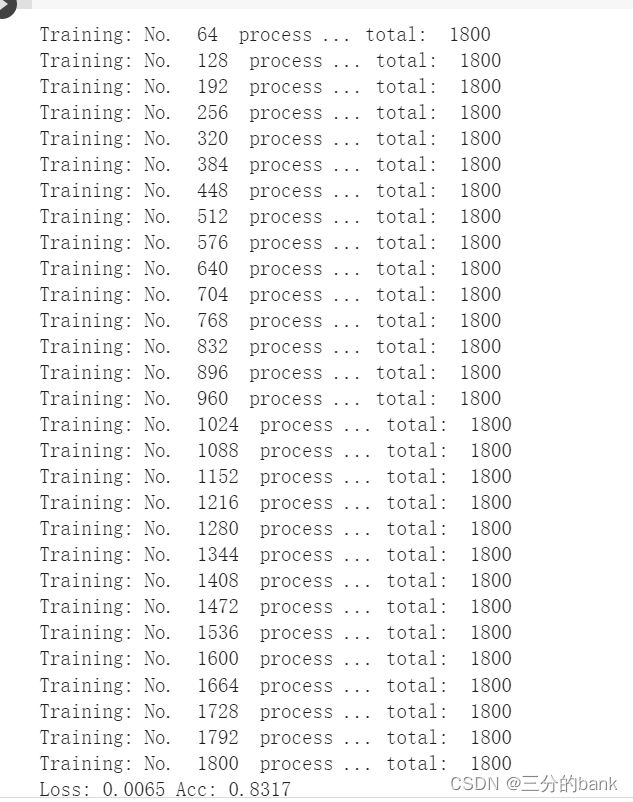
训练模型结果, Loss 0.0065, Acc 0.8317
测试模型

运行结果如图:

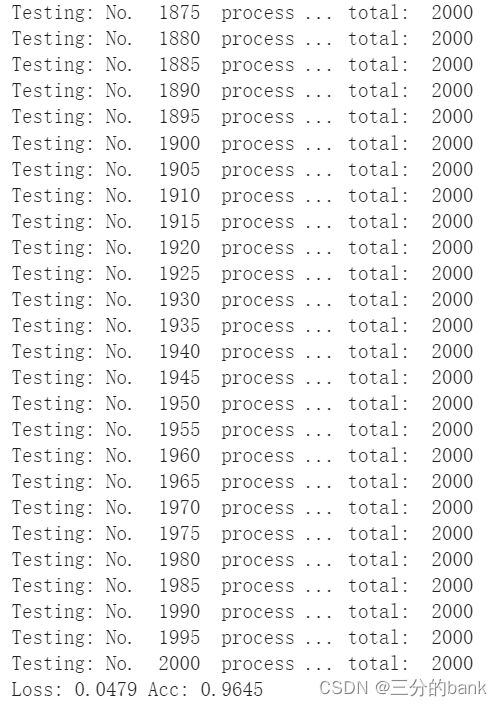
测试模型结果,Loss: 0.0479 , Acc: 0.9645
1.7.可视化模型预测结果
主观分析就是把预测的结果和相对应的测试图像输出出来看看,一般有四种方式:
· 随机查看一些预测正确的图片
· 随机查看一些预测错误的图片
· 预测正确,同时具有较大的probability的图片
· 预测错误,同时具有较大的probability的图片
· 最不确定的图片,比如说预测概率接近0.5的图片
代码:
运行结果:

二、迁移学习——AI研习社猫狗挑战赛
2.1数据下载并解压:
! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip
! unzip dogscats.zip
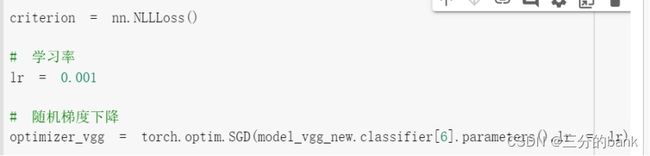
2.2.创建损失函数和优化器时,使用Adam优化器:
criterion = nn.NLLLoss()
\# 学习率
lr = 0.001
\# 随机梯度下降
optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr)
2.3.对比赛的数据集进行测试:
```css
```css
dsets = datasets.ImageFolder('/content/cat_dog', vgg_format)
result = {} #用于存放结果
#加载测试集
loader_test = torch.utils.data.DataLoader(dsets, batch_size=1, shuffle=False, num_workers=0)
def test(model,dataloader,size):
model.eval()
cnt = 0
predictions = np.zeros(size)
for inputs,_ in dataloader:
inputs = inputs.to(device)
outputs = model(inputs)
_,preds = torch.max(outputs.data,1)
#提取图片名称作为key从而进行分割
key = dsets.imgs[cnt][0].split("/")[-1].split('.')[0]
result[key] = preds[0]
cnt += 1
test(model_vgg_new,loader_test,size=2000)
#将结果写成表格
with open("/content/test.csv",'a+') as f:
for key in range(2000):
f.write("{},{}\n".format(key,result[str(key)]))
2.4.测试结果:

2.5.改进的地方:
将SGD优化器改为使用Adam优化器,相比于SGD优化器,Adam优化器的速度更快,在这里优化效果比SGD效果更好。
训练模型batch_size调为128,也可以使训练的结果更好。
三、作业总结
1、图形处理器 GPU:,又称显示核心、视觉处理器、显示芯片。是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。GPU使显卡减少了对CPU的依赖,并进行部分原本CPU的工作,尤其是在3D图形处理时GPU所采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。
2、在此平台上,
!wget + 下载地址,可以从该网址上直接下载到实验上,
!unzip 可以解压缩
3、sledge hammer 是在 ImageNet 上预训练好的 VGG 模型,在这个数据集中,有大量猫和狗的图片,不修改网络,此模型也可以非常准确的识别猫和狗。
4、冻结前面层的参数,修改最后一层, 学习了VGG模型,此网络由卷积层(发现图像中局部的 pattern)、全连接层(全局上建立特征的关联)、池化(给图像降维以提高特征的 invariance)
5、用可视化模型预测结果 即主观分析的方式:随机查看一些预测正确、错误的图片,预测正确、错误,同时具有较大的probability的图片、 最不确定的图片,比如说预测概率接近0.5的图片。
确的识别猫和狗。
4、冻结前面层的参数,修改最后一层, 学习了VGG模型,此网络由卷积层(发现图像中局部的 pattern)、全连接层(全局上建立特征的关联)、池化(给图像降维以提高特征的 invariance)
5、用可视化模型预测结果 即主观分析的方式:随机查看一些预测正确、错误的图片,预测正确、错误,同时具有较大的probability的图片、 最不确定的图片,比如说预测概率接近0.5的图片。
6、在这个实验中,我们学习到了如何在工程问题中使用深度学习,首先准备待解决问题的数据,然后下载预训练好的网络,接着用准备好的数据来 fine-tune 预训练好的网络。可以在今后的实验中,按照该步骤使用深度学习解决问题。