【数据挖掘】k-means算法原理与实现
1、监督学习与无监督学习
根据训练数据是否拥有标记信息,学习任务可大致分为两大类:“监督学习”和“无监督学习”,分类和回归是前者的代表,而聚类则是后者的代表。
2、什么是k-means聚类算法?
该算法预先将数据分为k组,随机选取k个对象作为聚类中心,是一种迭代求解的聚类分析方法。
3、k-means算法实现代码(cv可用)
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
'''
无监督学习,即只有数据,无明确答案,即训练集没有标签。对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇
'''
'''
算法思想:
1.选择适当的k
2.初始化k个质心u
3.计算每个样本到质心的距离
4.按最小距离聚类,将数据集D分配到子数据集中
5.迭代以下步骤以至收敛:
1、重新计算质心,求均值
2、重新计算每个样本到每个质心的距离(遍历样本,扫描质心,两个for循环嵌套)
3、按最小样本聚类,将数据集D重新分配到子数据集中
4、如果迭代收敛或符合停止条件(达到最大迭代次数或所有样本分类不再变化),则输出聚类结果。
'''
#计算欧拉距离,这里求两点之间的欧氏距离
'''
欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义,指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。
在二维和三维空间中的欧氏距离就是两点之间的实际距离。
欧拉距离公式:d(x,y)*d(x,y)=(x1-y1)*(x1-y1)+(x2-y2)*(x2-y2)+···+(xn-yn)*(xn-yn)
'''
#kmeans算法的优缺点
'''
缺点:
1、需要预先给定K值,很多情况下K值的估计是非常困难的;
2、K-Means算法对初始选取的质心点是敏感的,不同的随机种子点得到的聚类结果完全不同 ,对结果影响很大;
3、对异常点数据敏感;
优化:
1、初始聚类中心
'''
#计算数据集到质心的距离
def calcDis(dataSet, centroids, k):
clalist = []
for data in dataSet:
diff = np.tile(data, (k,1)) - centroids#相减 (np.tile(a,(2,1))就是把a先沿x轴复制1倍,即没有复制,仍然是 [0,1,2]。 再把结果沿y方向复制2倍得到array([[0,1,2],[0,1,2]]))
squaredDiff = diff ** 2 #平方
squaredDist = np.sum(squaredDiff, axis=1)#和 (axis=1表示行)
distance = squaredDist ** 0.5 #对于开根号
clalist.append(distance)#不断计算点到质心的距离,并在集合clalist中添加数据
clalist = np.array(clalist) #返回一个每个点到质点的距离len(dateSet)*k的数组
return clalist
#计算质心
def classify(dataSet, centroids, k):
clalist = calcDis(dataSet, centroids, k)
#分组并计算新的质心
minDistIndices = np.argmin(clalist, axis=1)#axis=1 表示求出每行的最小值的下标
newCentroids = pd.DataFrame(dataSet).groupby(minDistIndices).mean()#DataFramte(dataSet)对DataSet分组,groupby(min)按照min进行统计分类,mean()对分类结果求均值
newCentroids = newCentroids.values
#计算变化量
changed = newCentroids - centroids
return changed, newCentroids
def kmeans(dataSet, k):
#随机选取数据集中的质心
centroids = random.sample(dataSet, k)
#调用classify算法计算数据集合中各点到达质心的距离
changed, newCentroids = classify(dataSet, centroids, k)
#np.any()是或操作更新质心,直到变化量全部为0
while np.any(changed != 0):
changed, newCentroids = classify(dataSet, newCentroids, k)
centroids = sorted(newCentroids.tolist())#tolist()将矩阵转换成列表 sorted()排序
#根据质心计算每个集群
cluster = []
clalist = calcDis(dataSet, centroids, k)#调用欧拉距离函数
minDistIndices = np.argmin(clalist, axis=1)
for i in range(k):
cluster.append([])
for i, j in enumerate(minDistIndices):#enymerate()可同时遍历索引和遍历元素
cluster[j].append(dataSet[i])
return centroids, cluster
#创建数据集
def createDataSet():
return [[1, 1], [1, 2], [2, 1], [6, 4], [6, 3], [5, 4],[1,3],[6,6],[5.4,1.8],[10.1,5.9],[1.2,1.2],[3.8,4],[2.3,3.3],[3,2],[1.3,1.3],[1.5,2],[3.2,3],[3.2,1],[2.7,1],[3.4,1.6],[2.7,1],[4.3,3.2],[6.3,7.1],[9.2,6.3],[8.3,5.2],[5.3,4.1],[8.4,9.3]]
if __name__ == '__main__':
dataset = createDataSet()
#采用min-max标准化方法对数据进行归一化处理
for p in range(len(dataset)):
dataset[p][0] = (dataset[p][0]-1)/10.1-1
dataset[p][1] = (dataset[p][1]-1)/9.3-1
#centroids表示质心 cluster表示集群
centroids, cluster = kmeans(dataset, 2)
print('质心为:%s' % centroids)
print('集群为:%s' % cluster)
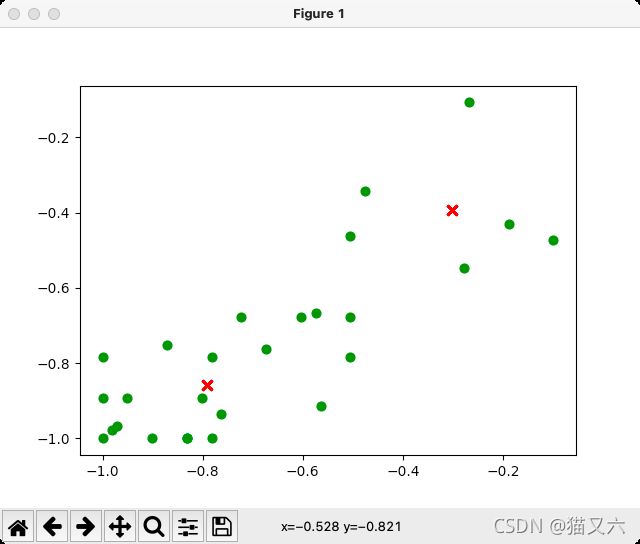
#绘制散点图
for i in range(len(dataset)):
plt.scatter(dataset[i][0], dataset[i][1], marker='o', color='green', s=40, label='原始点')
for j in range(len(centroids)):
plt.scatter(centroids[j][0], centroids[j][1], marker='x', color='red', s=50, label='质心')
plt.show()4、k-means聚类算法代码运行结果
各位朋友,文章若有任何问题,多多指教!