【深度学习与计算机视觉】12、迁移学习
文章目录
-
-
- 一、迁移学习简介
- 二、为什么要使用迁移学习
- 三、迁移学习的实现
- 四、迁移学习系统介绍
- (一)原始数据有标签,目标数据有标签
-
- 1、模型微调(model fine-tune)[也叫再优化]
-
- (1)保守训练 Conservative Training
- (2)层迁移 Layer Transfer
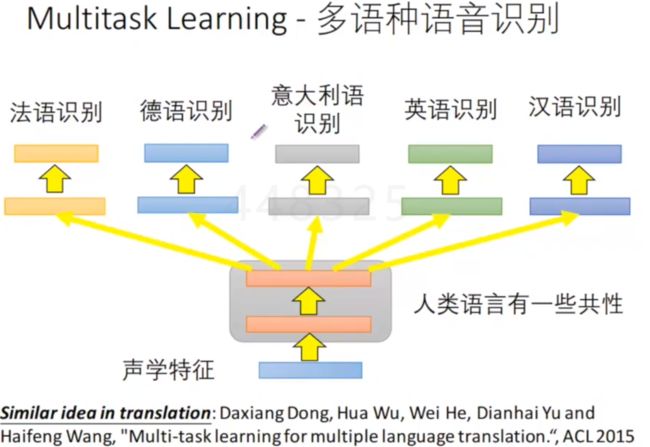
- 2、多任务的学习——应用在语音识别
- 二、原始数据有标签,目标数据无标签
-
一、迁移学习简介
迁移学习(transfer learning)通俗来说就是找到已有知识和新知识之间的相似性,由于直接对目标开始从头学习的成本太高,硬件要求和时间周期要求也很高,所以我们转而利用相关知识来辅助尽快的学习新知识。
迁移学习的核心就是找到目标和已有知识之间的相似性,进而对新知识进行学习。
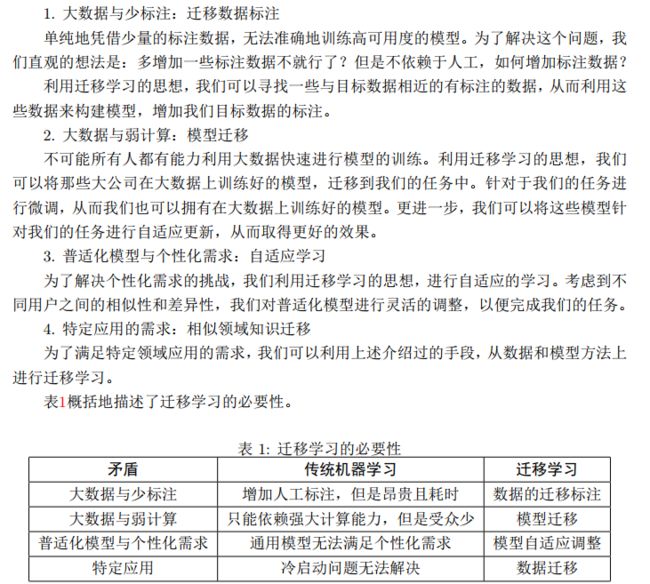
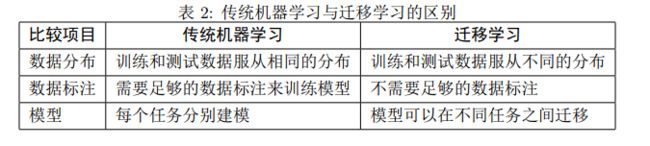
在迁移学习中,我们已有的知识叫做源域(source domain),要学习的新知识叫目标域(target domain)。迁移学习研究如何把源域的知识迁移到目标域上。特别地,在机器学习领域中,迁移学习研究如何将已有模型应用到新的不同的、但是有一定关联的领域中。传统机器学习在应对数据的分布、维度,以及模型的输出变化等任务时,模型不够灵活、结果不够好,而迁移学习放松了这些假设。在数据分布、特征维度以及模型输出变化条件下,有机地利用源域中的知识来对目标域更好地建模。另外,在有标定数据缺乏的情况下,迁移学习可以很好地利用相关领域有标定的数据完成数据的标定。
理论上,任何领域之间都可以做迁移学习。但是,如果源域和目标域之间相似度不够,迁移结果并不会理想,出现所谓的负迁移情况。比如,一个人会骑自行车,就可以类比学电动车;但是如果类比着学开汽车,那就有点天方夜谭了。如何找到相似度尽可能高的源域和目标域,是整个迁移过程最重要的前提。
二、为什么要使用迁移学习
三、迁移学习的实现
深度学习中,最强大的理念之一就是,有时候可以从一个任务中学到知识,并将这些知识应用到另一个独立的任务中去。
例如你已经训练好了一个神经网络,可以识别出猫这样的对象,然后使用这些学到的知识来更好的阅读x射线扫描图,这就是所谓的迁移学习。
假设已经训练好了一个图像识别神经网络,要用该网络去进行另外的工作的话,可以将最后一层输出层替换掉,将最后一层的连接权重也删除,然后随机为最后一层重新赋予随机权重,然后在新数据集上训练。
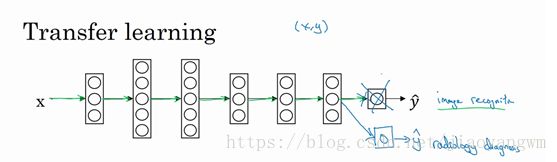
1、两种训练方法:
-
如果新数据集很小,那么只需要重新训练最后一层的权重,也就是 w L , b L w^L,b^L wL,bL,并保持其他参数不变
-
如果新数据将较大,可以重新训练网络中的所有参数。
2、迁移学习的预训练和微调:
预训练模型:已经训练好的优秀的模型,和你需要解决的问题有一定的相似性,比如VGG、GoogLeNet等。
- ImageNet的目标是将所有的图像正确的划分到1000类目录下,这1000个分类基本上都来源于我们的日常生活,比如说猫猫狗狗的种类,各种家庭用品,日常通勤工具等等。在迁移学习中,这些预训练的网络对于ImageNet数据集外的图片也表现出了很好的泛化性能。既然预训练模型已经训练得很好,我们就不会在短时间内去修改过多的权重,在迁移学习中用到它的时候,往往只是进行微调(fine tune)。
微调:使用已经训练好的模型对目标数据进行训练的时候,不会修改过多的参数,只是进行很少的参数调整。
微调模型有下列三种方法:
-
特征提取:将预训练模型当做特征提取装置来使用,具体做法是将输出层去掉,然后将剩下的网络当做一个固定的特征提取机,从而应用到新的数据集中。
-
采用预训练模型的结构:还可以采用预训练模型的结构,但是先将所有的权重随机初始化,然后依据自己的数据集进行训练
-
训练特定层,冻结其他层:将模型起始的一些曾的权重保持不变,重新训练后面的层,得到新的权重,在这个过程中,可以多次进行尝试,从而能够依据结果找到冻结层和重新训练的层之间的最佳搭配。
3、微调模型不同方法的应用场景:
- 数据集小,目标数据和预训练模型的数据相似度高:
该情况不用重新训练模型,只需要将输出层改成符合问题情景下的输出结构即可,使用预处理模型作为模式提取器。
比如说我们使用在ImageNet上训练的模型来辨认一组新照片中的小猫小狗。在这里,需要被辨认的图片与ImageNet库中的图片类似,但是我们的输出结果中只需要两项——猫或者狗。在这个例子中,我们需要做的就是把dense layer和最终softmax layer的输出从1000个类别改为2个类别。
- 数据集小,数据相似度不高:
该情况下我们可以冻结预训练模型中的前k个层中的权重,然后重新训练后面的n-k个层,当然最后一层也需要根据相应的输出格式来进行修改。
因为数据的相似度不高,重新训练的过程就非常关键,而新数据将的大小不足,则是通过冻结预训练模型的前k层进行弥补。
为什么冻结前k层:前几层的网络捕获的是边缘、轮廓等普遍的特征,这些特征和很多问题都是相关的,所以可以保持前面的权重不变,让网络在学习的过程中重点关注后面的特有的特征,从而对后面的网络进行参数的学习。
- 数据集大,数据相似度不高
该情况我们有一个很大的数据集,所以神经网络的训练过程会比较有效率,然鹅实际数据和预训练模型的训练数据之间有很大的差异,采用预训练模型不会是一种很高效的方法。
因此最好的方法还是通过将预训练模型中的权重全部初始化后的新数据集的基础上重头开始训练。
- 数据集大,数据相似度高
该情况是最理想的情况,采用预训练模型会变得很高效,最好的运用方式是保持模型原有的结构和初始权重不变,随后在新数据集的基础上重新训练。
4、为什么迁移学习会有好的效果:
从类似于ImageNet的庞大的图像库中学习到了很多结构信息、图像的形状信息等等,这些东西很有用且有较好的鲁棒性,训练好的参数代表提取不同特征的模板,所以训练好的模型相当于可以提取不同种类特征的特征提取器,我们只需要将新样本输入,就可以获得有效的特征。
四、迁移学习系统介绍
当前的任务和已有模型可能有某种关联,如果自己训练网络的话,训练过程很漫长,并且数据集不够大,利用已有的模型可以快速收敛到较好的效果。
前提:保证原本的任务和当前任务有联系
为什么需要迁移学习:
深度学习需要大量的数据,来学到本质的规律,迁移学习将在一个领域中已经学习到的能力拿来处理另外一个领域的问题。
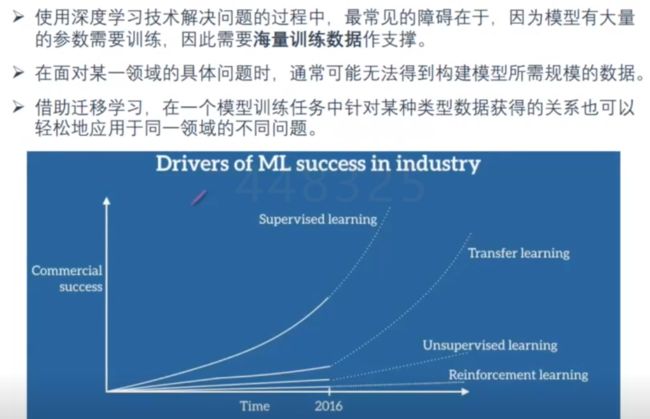
工业界的有监督学习用的最多,也最有效,无监督学习做一个辅助作用,迁移学习是由很大的的发展空间。
(一)原始数据有标签,目标数据有标签
1、模型微调(model fine-tune)[也叫再优化]

无法利用自己的小样本数据集去训练,肯定会过拟合,所以借用已有的模型在我们的数据集上做一个调优,但也可能会出现过拟合,因为已有的ImageNet网络能力太强了,新的数据效果没有那么好。
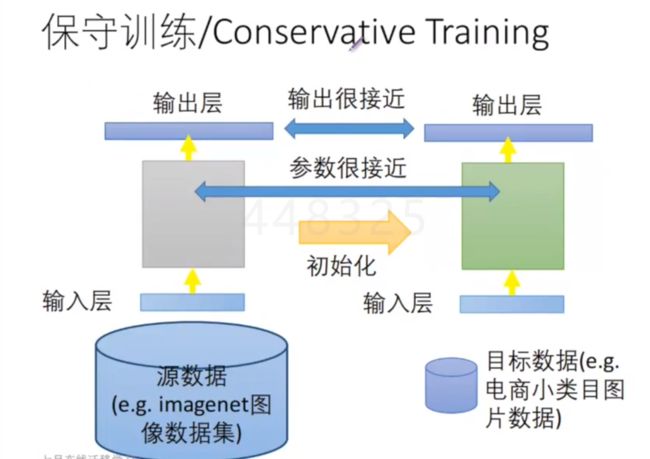
(1)保守训练 Conservative Training
原本大的数据集训练得到的GoogLeNet,能力很强大,如果放任它去学习我们小样本数据集,肯定会过拟合,给了参数太大的自由空间,模型功能太强大,但是已经过拟合了。
**如何去控制过拟合:**因为原本的模型是泛化能力很好的模型,所以新的模型可以允许参数在原来的基础上做微小的变动,也就是两个数据集上得到的模型参数很接近,可以将正则化模型变为 ∑ ∣ ∣ w i ′ − w i ∣ ∣ \sum ||w_i'-w_i|| ∑∣∣wi′−wi∣∣,也就是将“新参数-原参数”的差作为正则项,约束参数在原始基础上的变化。
(2)层迁移 Layer Transfer
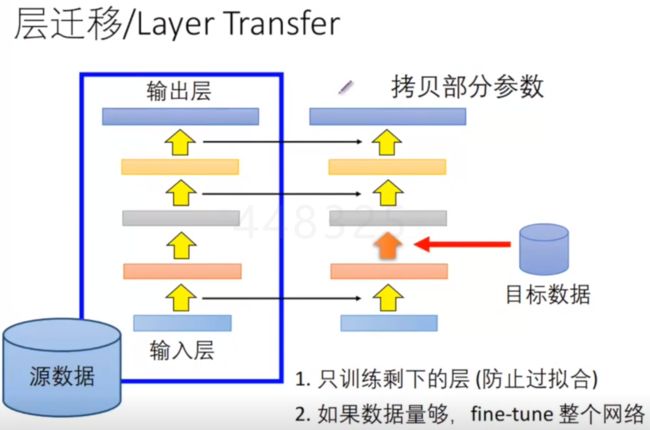
如果数据量很小:固定前面几层,将其学习率调为0,只训练剩下的后面的层,可以调整的参数变少了,学习受到了限制,会避免过拟合。
数据量足够大:可以将前面的学习率调的小一些,不是直接置为0,可以置为0.001等,训练整个网络,但是还是不要给太大的自由度。
如果选择固定那些层:
- 图像:固定开始的层
图像是从底层开始学的,前面的层通常提取的是底层特征,比如边缘等,最后的层是底层特征的组合,所以我们将之前的层固定住,对后面的有分类作用的层进行优化。
- 语音:通常是最后一些层
每个人都有不同的发声方式,根据语音识别得到文本,通过前面的层对不同人的发声做一个抽象,说话的内容都是由基本单元组成的,但是每个人发出的基本单元是不同的,通过音素来组成最后的话的过程是一样的。
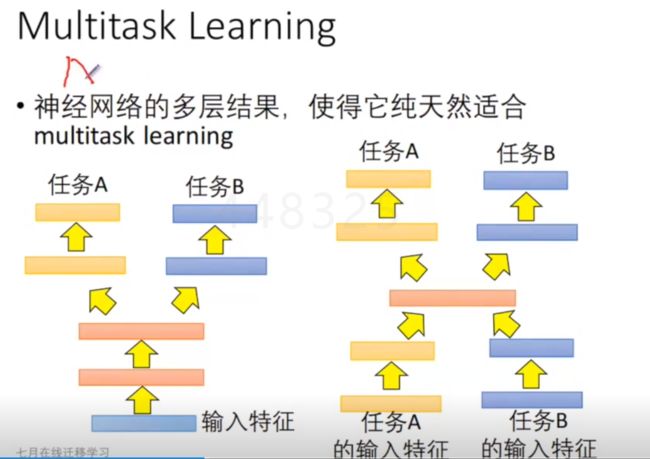
2、多任务的学习——应用在语音识别
(1)在做迁移学习的时候,保证在原来的任务上效果不会太差,但是肯定不是用同一个网络,所以会造出来一个组合网络,共用前面的几个层的参数,前面几层是捕捉两个任务的共性。
(2)前面的层抽取不同的卡通/真实图像的特征,两个数据形态是由一定差距的,中间的一层是共用的
不同的语种的人类语言的共性学习出来,后面的阶段再区分不同语种的文本表达。
二、原始数据有标签,目标数据无标签
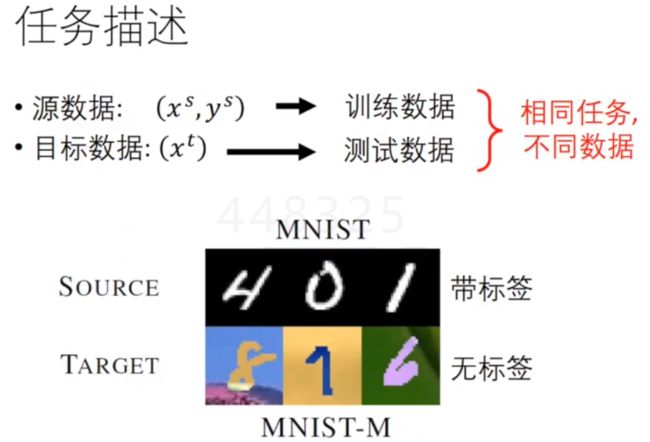
源数据黑白分明很干净,目标数据是彩色且有干扰背景的无标签的。
可视化之后,不同的数字被投影到不同的区域,也就是映射为不同的特征了,前面的绿色是特征抽取的过程,MNIST-M被分类后都集中在一块,分类效果很差。
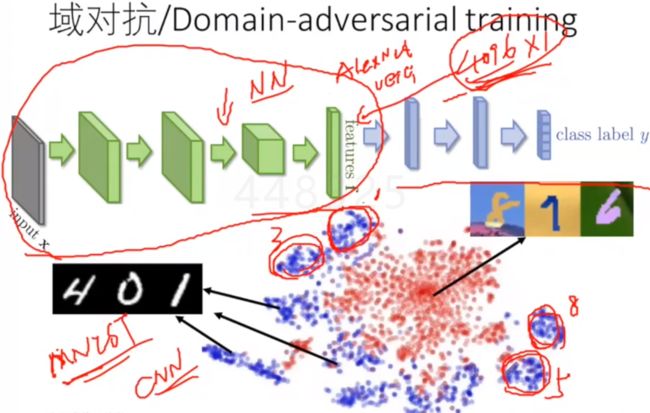
1、域对抗
域对抗:两个数据集是两个不同的类,域对抗做的事情不是区分1,2,3,而是区分这个数据来源于MNIST还是MNIST-M,也就是这个通用的方法将域的信息去掉了,不关心其来源于那个域,只要判断它是1,2,3即可。
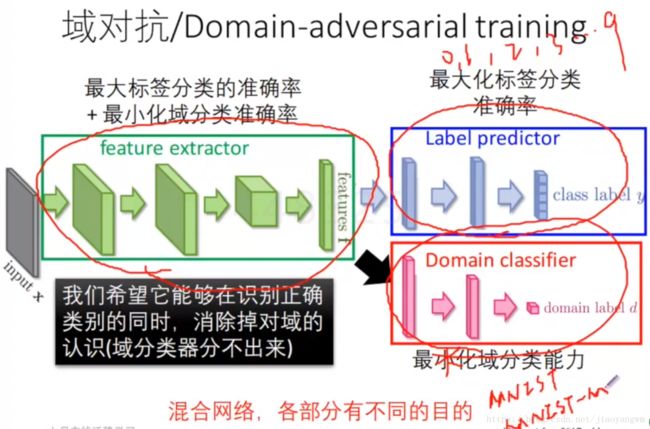
左边的绿色区域抽特征,同时要满足:
-
可以抽取到不同类别数字的特征
-
区别不出来来源于哪个domain
上面的分支训练的时候只用MNIST,因为它有标签,
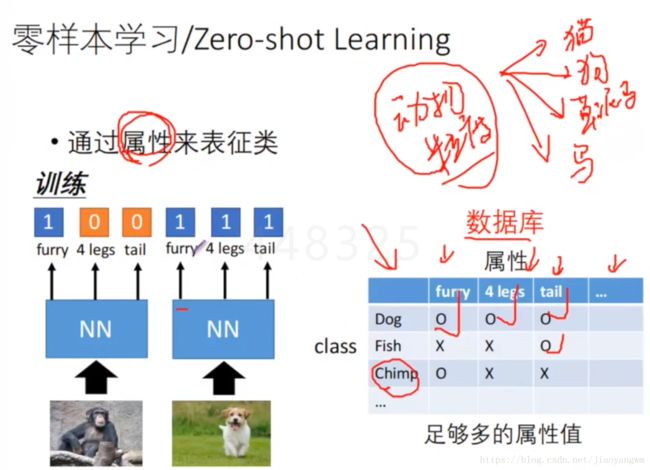
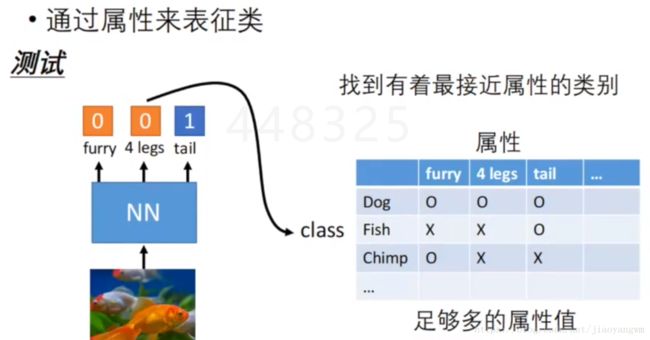
2、零样本学习:
通过属性来表征类,所以现在不直接用来识别猫、狗、兔子,而是通过它们的属性,再查找属性表来表征它们可能属于某个类。