实体关系抽取学习笔记
1 关系抽取概述
1.1 简介
信息抽取旨在从大规模非结构或半结构的自然语言文本中抽取结构化信息。关系抽取是其中的重要子任务之一,主要目的是从文本中识别实体并抽取实体之间的语义关系。
关系抽取对于很多NLP的应用,如信息提取、问答系统、阅读理解等有非常重要的作用。
常见的关系抽取结果可以用SPO结构的三元组来表示,即 (Subject, Predication, Object),如:中国的首都是北京 ==> (中国, 首都, 北京)
1.2 任务、方法
根据是否有确定的关系集合,可以分成以下两种任务:
- 限定关系抽取:事先确定好所有需要抽取的关系集合
- 开放式关系抽取:需要抽取的关系集合是不确定的,而且抽取语料所属的领域也可能是不确定的
关系抽取可以用基于模板、有监督、半监督、无监督的方式实现:
- 基于模板(pattern):通过人工设计模板的方式,对文本进行匹配。
- 有监督学习:监督学习的关系集合通常是确定的,高质量监督数据下的监督学习模型的准确率会比较高。然而,缺点是需要大量的人力成本和时间成本来对数据进行标注,且其难以扩展新的关系类别。
- 半监督学习:利用少量的标注信息作为种子模版,从非结构化数据中抽取大量新的实例来构成新的训练数据。主要方法包括Bootstraping和远程监督学习。
- 无监督学习:利用语料中存在的大量冗余信息做聚类,在聚类结果的基础上给定关系,但由于聚类方法本身就存在难以描述关系和低频实例召回率低的问题,因此无监督学习一般难以得很好的抽取效果。
对于有监督的关系抽取任务,通常也将其分为两大类
- Pipline:将实体抽取与关系抽取分为两个独立的过程,关系抽取依赖实体抽取的结果
- Joint Model:实体抽取与关系抽取同时进行
1.3 难点
实体对的关系中,存在关系重叠和复杂关系问题。

-
a:正常关系问题
-
b:关系重叠问题,一对多。如"张学友演唱过《吻别》《在你身边》"中,存在2种关系:"张学友-歌手-吻别"和"张学友-歌手-在你身边"
-
c:关系重新问题,一对实体存在多种关系。如"周杰伦作曲并演唱《七里香》"中,存在2种关系:"周杰伦-歌手-七里香"和"周杰伦-作曲-七里香"
-
d:复杂关系问题,由实体重叠导致。如《叶圣陶散文选集》中,叶圣陶-作品-叶圣陶散文选集;
-
e:复杂关系问题,关系交叉导致。如"张学友、周杰伦分别演唱过《吻别》《七里香》","张学友-歌手-吻别"和"周杰伦-歌手-七里香"
1.4 常用数据集
有监督学习:ACE2004、ACE2005、SemEval-2010 Task 8、TACRED
远监督学习:NYT-Freebase
1.5 效果测评
对于有监督的关系抽取方法,一般采用精确率(precision)、召回率 (recall)和F1值进行测评。
对于无监督的关系抽取方法,一般使用![]() 、V-measure、ARI进行测评。
、V-measure、ARI进行测评。
2 基于模板(pattern)方法
2.1 优点、缺点
优点是:
- 精确率比较高(high-precision)
- 可以为特定领域定制(tailor)
- 在小规模数据集上容易实现,构建简单
缺点是:
- 召回率比较低(low-recall)
- 特定领域的模板需要专家构建,难以考虑周全所有可能的模板,费时费力
- 需要为每条关系定义模板
- 难以维护
- 可移植性差
2.2 基于触发词/字符串
我们以“任职于”关系为例,我们可以编写以下规则:
- X是Y的员工
- X在Y工作
通过正则表达式,我们就可以抽取句子中的关系。
另外,借助于NER标签,我们可以使用同一条规则,匹配多种关系,比如以下规则:
- X是Y的Z
假如X是PERSON,Y是ORGANIZATION,Z是POSITION,这条规则可以匹配“任职于”关系,比如:小明是A公司的经理。
假如X、Y是PERSON,Z是CHARACTER,这条规则可以匹配“配偶”关系,比如:小明是小红的老公。
2.3 基于依存句法
通常可以以动词为起点构建规则,对节点上的词性和边上的依存关系进行限定。
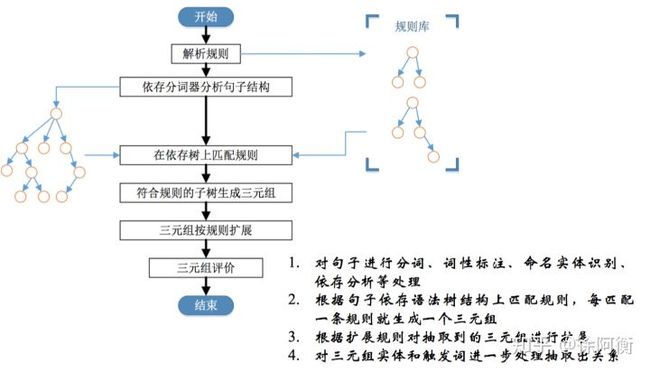
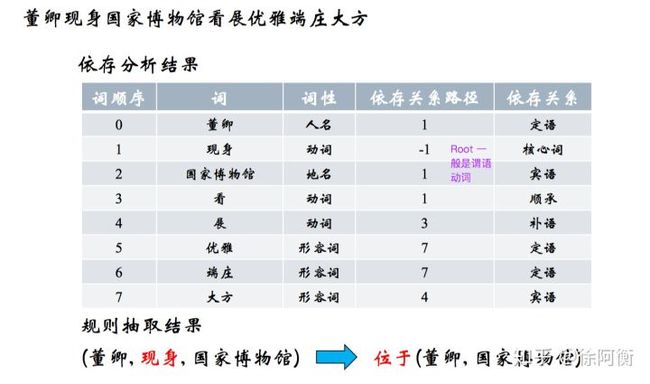
2.4 基于统计模板
统计模板无须人工构建,主要基于搜索引擎进行统计模板抽取。具体来说,将已知实体对作为查询语句,抓取搜索引擎返回的前n个结果文档并保留包含该实体对的句子集合,从句子集合保留置信度较高的模板用于关系分类。
3 有监督学习方法
3.1 优点、缺点
优点是:
- 当实际数据和训练数据比较相似时,准确率会比较高
缺点是:
- 需要大量标注数据,费时费力
- 无法识别新的关系
3.2 Pipline和Joint Model(联合抽取)对比
Pipeline方法指先抽取实体、再抽取关系。Pipeline方法易于实现,两个抽取模型的灵活性高,实体模型和关系模型可以使用独立的数据集,并不需要同时标注实体和关系的数据集。但是存在以下缺点:
- 误差积累:实体抽取的错误会影响下一步关系抽取的性能。
- 实体冗余:由于先对抽取的实体进行两两配对,然后再进行关系分类,没有关系的候选实体对所带来的冗余信息,会提升错误率、增加计算复杂度。
- 交互缺失:忽略了这两个任务之间的内在联系和依赖关系。
相比于Pipeline方法,Joint Model方法能获得更好的性能。
3.3 方法分类
基于有监督学习的方法,主要可以分为基于特征、核函数、深度学习三种。基于特征的方法需要基于传统特征,并人工定义使用的特征集合。核函数基于传统特征,自动在高维空间进行计算,不需要人工定义。基于深度学习的方法不需要利用额外的特征,使用神经网络自动提取特征。
3.4 Pipline方法
3.4.1论文笔记
================================================================================================
ACL 2014:Relation Classification via Convolutional Deep Neural Network
================================================================================================
概述
在深度学习兴起之前,关系抽取的传统方法依赖于特征工程,而这些特征通常由预先准备的NLP系统得到,这容易在构造特征的过程中造成误差累积,阻碍系统性能。本论文属于早期使用深度卷积网络模型解决关系抽取任务的经典论文。
本文指出,词汇级和句子级的特征对于关系分类非常重要,提出利用卷积神经网络提取词汇级和句子级特征进行关系分类。同时,本文提出使用位置特征(PF),编码每个词到目标名词对的相对距离。
首先,通过查找词嵌入,将所有单词符号转换为向量。然后,根据给定的名词提取词汇级特征。同时,使用卷积方法学习句子级特征。将这两个层次的特征拼接起来,形成最终提取的特征向量。最后,将特征输入softmax分类器,预测两个标记名词之间的关系。
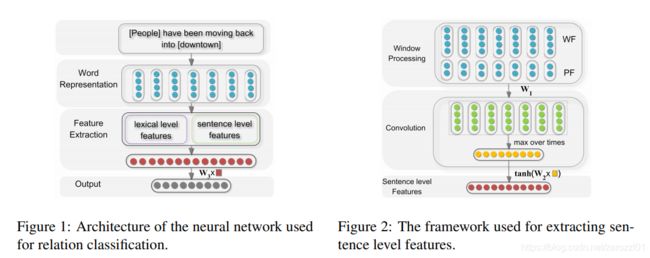
模型架构
模型输入是一个带有两个标记名词的句子。模型主要包含三个部分:Word Representation、Feature Extraction、Output。
1)Word Representation
把句子中的每个词转换成词向量(word embedding)。
2)Feature Extraction
分为词汇级特征和句子级特征。
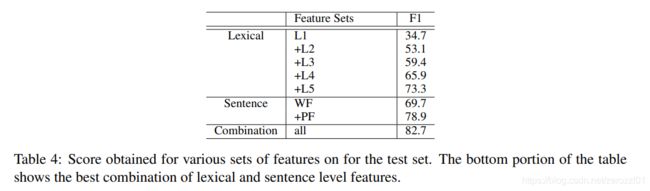
词汇级特征
包括实体对e1和e2的词向量,e1和e2的左右两边词的词嵌入向量,以及一个WordNet上位词向量。WordNet上位词特征指的是e1和e2同属于哪一个上位名次,如“狗”和“猫”的上位词可以是“动物”或者“宠物”,具体需要参考的 WordNet 词典是怎样构建的。直接将上述的5个向量直接拼接构成词汇级别的特征向量l。
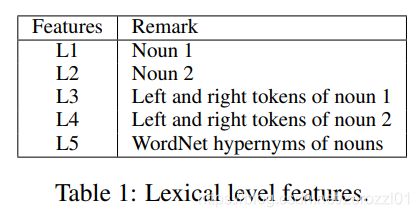
句子级特征
Word Features:把每个词表示成该词的词向量以及其上下文中每个词的词向量的组合。假设上下文窗口选择3,则{x0,x1, · · · ,x6}转换为{[xs, x0, x1],[x0, x1, x2],· · · ,[x5, x6, xe]}。
Position Features:PF是当前词到e1和e2的相对距离的组合。在本模型中,相对距离也被映射到一个向量,然后得到当前词到e1和e2的相对距离向量d1和d2,且PF = [d1, d2]。
结合WF和PF,每个词表示为[WF, PF],然后对输入进行卷积运算。卷积完成后,进行max-pooling池化,最后经过tanh进行非线性变换,得到句子级别的特征向量g。
3)Output
把词汇级别特征l和句子级别特征g进行拼接,得到最后的特征表示f=[l,g],然后对f输入到最后的全连接层,得到最终输出![]() ,然后将其送入分类器进行分类。
,然后将其送入分类器进行分类。
实验结果
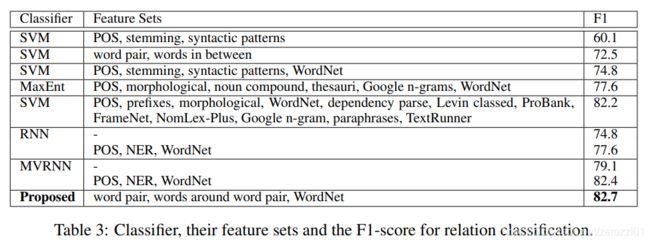
特征分析
================================================================================================
ACL 2016:Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
================================================================================================
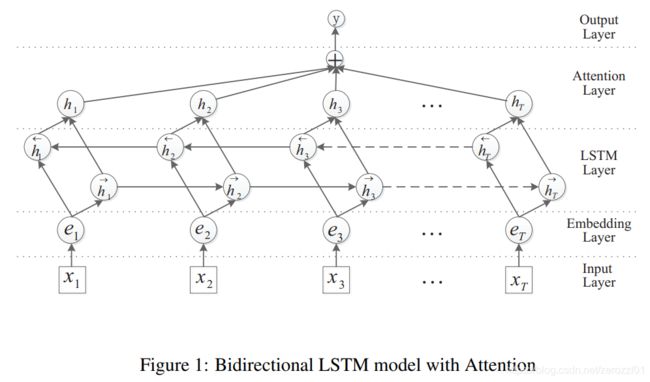
概述
本文指出,之前的研究还是会依赖WordNet、NER等外部特征。本文在仅使用词向量的情况下,基于BiLSTM和注意力机制,得到了SOTA的效果。
模型架构
模型包含以下五部分:Input layer、Embedding layer、LSTM layer、Attention layer、Output layer
1)Input layer
在输入到模型前,需要对句子进行简单处理。本模型提出使用〈e1〉、〈/e1〉、〈e2〉、〈/e2〉四个位置标签,对句子进行简单的预处理,处理结果如下:〈e1〉 Flowers 〈/e1〉 are carried into the 〈e2〉 chapel 〈/e2〉。
2)Embedding layer
把输入句子中的单词转换成词向量:S = {x1,x2,. . . ,xT } 转换为embs = {e1,e2,. . . ,eT }。
3)LSTM layer
使用LSTM的其中一种常见变形,对输入进行特征提取,计算公式如下:
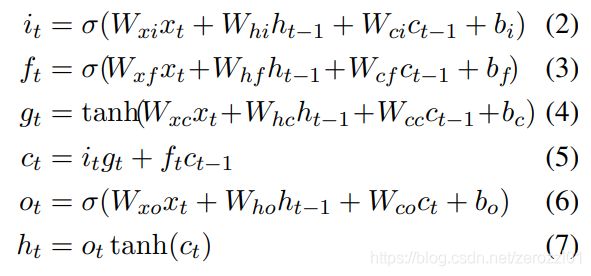
这里使用双向LSTM,得到两个方向的LSTM编码结果后,进行简单的相加,得到最后的特征表示: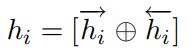 。
。
4)Attention layer
对LSTM编码后的结果计算注意力计算,得到最终的表示,计算过程如下:
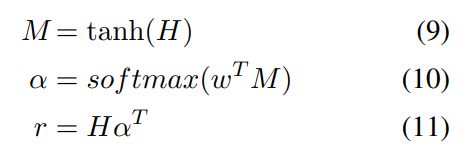
其中w是需要学习的向量参数。最后对r进行激活,得到最终表示: 。
。
5)Output layer
最后把注意力层的结果输入到全连接层,并进行softmax运算,得到最终的输出。

使用交叉熵作为损失函数,同时加入了 L2 正则化项:

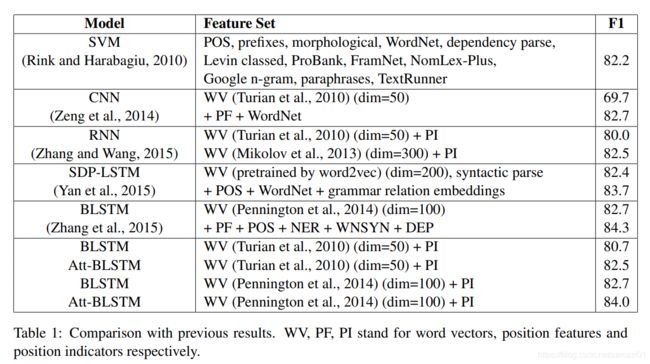
实验结果
================================================================================================
ACL 2016:Relation Classification via Multi-Level Attention CNNs
================================================================================================
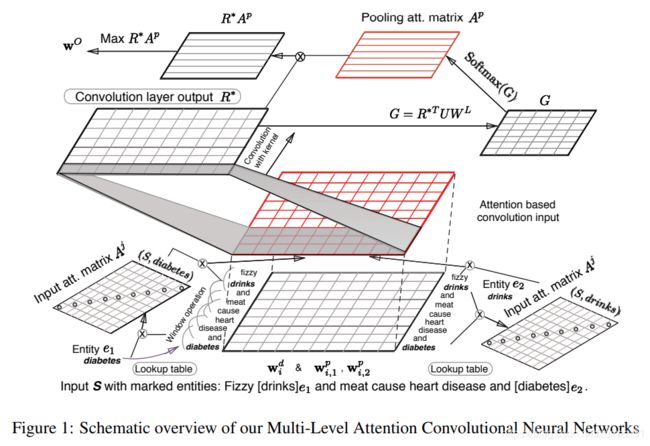
概述
本文提出使用多层注意力机制进行关系抽取。
模型基于CNN架构,依赖于一种新颖的多层注意力机制,以捕获针对实体的注意力(针对输入层的目标实体的主要注意力)和针对关系的池化注意力(针对目标关系的次要注意力)。
同时提出一种新的损失函数,pair-wise margin-based objective function。
模型架构
首先对输入句子使用词向量进行编码,并结合单词的上下文和位置编码来更好地捕获词序信息。然后,第一层注意力通过一个对角矩阵捕获单词与目标实体之间的相关性。进而,对得到的输出矩阵应用卷积操作,以捕获n-gram等上下文信息,并进行max-pooling操作。接下来,第二层池化注意力捕获卷积特征中对关系分类最有用的特征。主要使用的符号如下所示:
1)Classification Objective
文本使用关系嵌入,为每个关系分配一个embedding向量,模型的输出是一个![]() ,并提出了计算模型输出和目标关系的距离:
,并提出了计算模型输出和目标关系的距离:

其中![]() 随模型一起训练得到。
随模型一起训练得到。
基于这个距离,定义损失函数margin-based pairwise loss function:

其中,1是margin,![]() 是模型输出和目标输出的距离,
是模型输出和目标输出的距离,![]() 是所有标签不正确的样本中,得分最高的样本:
是所有标签不正确的样本中,得分最高的样本:
2)Input Representation
首先把每个词转换为词向量和位置向量的组合:

然后把每个词表示成其临近k个词的拼接表示:
 ,其中
,其中![]()
3)Input Attention Mechanism
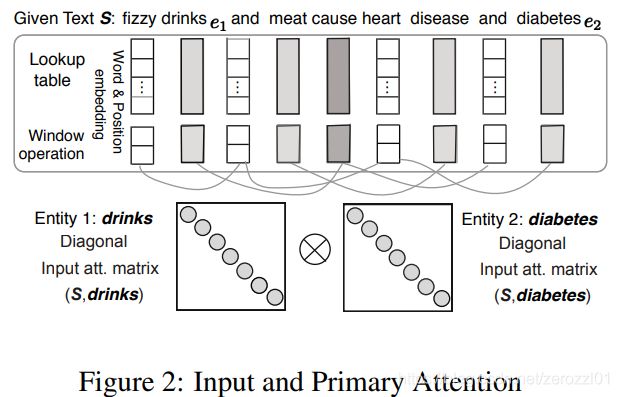
考虑到位置向量可能无法完美的捕获到每个词对目标词的关注信息,本文首先引入第一层注意力机制。
首先使用向量内积计算得分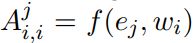 ,然后进行归一化,得到权重矩阵:
,然后进行归一化,得到权重矩阵:

每个词对于两个实体分别计算,最后结果以两个矩阵的形式表示。
得到每个词针对两个实体的注意力权重之后,对之前的词表征进行处理,文中给出的处理方法有三种:
- sum:
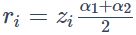
- concat:

- substract:
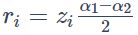
最后得到ri为词的注意力加权表征:R = [r1,r2,. . . ,rn]。
4)Convolutional Max-Pooling with Secondary Attention
首先对上一步输出的词表征进行卷积运算,得到R*

然后,使用第二层注意力机制,计算每个表征对于关系的重要性,计算方式如下
首先初始化关系嵌入的矩阵![]() 和注意力矩阵
和注意力矩阵![]() ,然后计算得分矩阵
,然后计算得分矩阵![]() 。
。
然后对G进行归一化,得到每个词表征对每个关系的注意力权重大小:

最后把卷积的结果和注意力权重矩阵相乘,并对结果进行max-pooling,得到模型的最终输出:
![]()
实验结果

特征分析

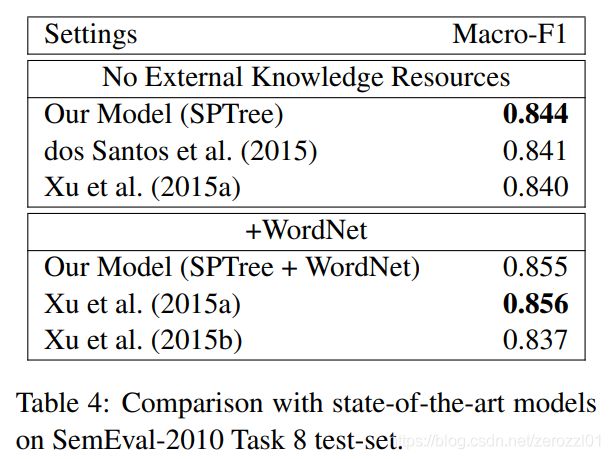
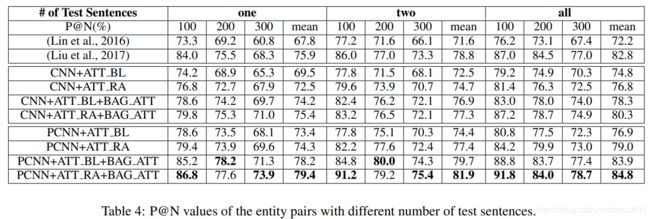
2.4.2 性能对比
| 发表年份 | 模型 | 特点 | 输入特征 | F1值 |
| 2014 | Relation Classification via Convolutional Deep Neural Network | CNN | Word and Position Embeddings, WordNet | 82.7 |
| 2015 | Relation Extraction: Perspective from Convolutional Neural Networks | CNN + 多粒度卷积核 | Word and Position Embeddings | 82.8 |
| 2015 | Classifying Relations by Ranking with Convolutional Neural Networks | CNN + ranking loss | Word and Position Embeddings | 84.1 |
| 2015 | Bidirectional Long Short-Term Memory Networks for Relation Classification | BiLSTM | Word and Position Embeddings, POS, NER, WordNet, Dependency Feature | 84.3 |
| 2016 | Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification | BiLSTM + Attention | Word and Position Embeddings | 84.0 |
| 2016 | Relation Classification via Multi-Level Attention CNNs | CNN + Multi-level Attention + ranking loss | Word and Position Embeddings | 88.0 |
| 2016 | Bidirectional Recurrent Convolutional Neural Network for Relation Classification | SDP + BiLSTM + CNN | Word Embeddings, WordNet, NER, WordNet | 86.3 |
3.5 Joint Model(联合抽取)方法
3.5.1论文笔记
================================================================================================
ACL 2016:End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures
================================================================================================
概述
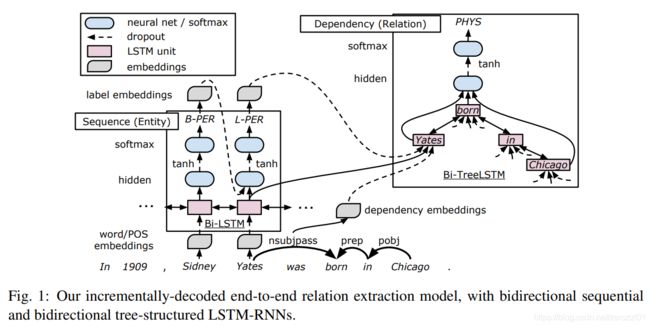
本文提出使用端到端的神经网络同时提取实体及其对应的关系。这篇论文首次将神经网络模型用于解决实体关系联合抽取任务,属于这块领域的开山之作。
模型通过把双向树状LSTM堆叠在双向序列LSTM上,同时捕获词序列和依赖树结构的信息,使得两个模型可以共享部分参数。
模型架构
模型主要由三部分组成:word embeddings layer (embedding layer)、word sequence based LSTM-RNN layer (sequence layer)、dependency subtree based LSTM-RNN layer (dependency layer)。
解码过程中,在sequence layer上进行贪婪的、从左到右的实体检测,在dependency layer上实现关系分类,其中基于LSTM的每一个子树对应于两个被检测实体之间的一个候选关系。
1)embedding layer
模型中主要有四个Embedding层,分别用来表示词嵌入v(w)、词性(POS)嵌入v(p)、依存关系嵌入v(d)以及实体标签嵌入v(e)。
2)Sequence Layer
该层主要用于实体识别任务,输入是词嵌入以及POS嵌入的拼接,即t时刻的输入为![]() 。对输入使用BiLSTM进行编码,最终输出为
。对输入使用BiLSTM进行编码,最终输出为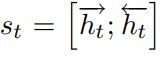 。
。
3)Entity Detection
本文把命名实体识别看作序列标注任务,使用BILOU (Begin, Inside, Last, Outside, Unit)标签体系。
模型t时刻的输入为该时刻Sequence Layer的输出加上上一时刻的实体标签嵌入,这样可以考虑到上一个词的预测结果,从而考虑到标签上的依赖性。然后使用两层全连接层加上softmax得到实体识别的结果。解码时使用贪心算法从左到右计算结果。

4)Dependency Layer
该层主要关注两个实体在依存树中的最短路径(shortest path),使用树状结构的BiLSTM(即自底向上和自顶向下)捕获目标实体对周围的依赖结构信息,最后得到他们之间的关系表示。
本文提出一种新的基于树结构的 LSTM,相同类型的子节点共享参数矩阵,同时允许可变数量的子节点。
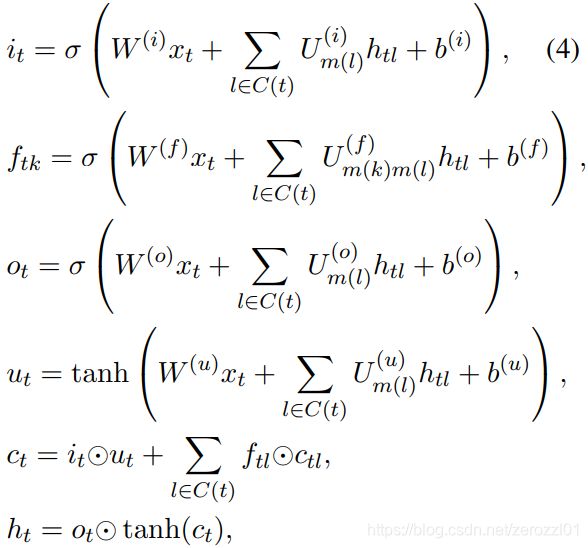
本层堆叠在Sequence Layer上,输入是该时刻Sequence Layer的输出、依存关系嵌入和实体标签嵌入的拼接![]() 。Dependency layer可以依赖Sequence layer的输出,实体识别的结果间接地对关系分类的结果加以影响。
。Dependency layer可以依赖Sequence layer的输出,实体识别的结果间接地对关系分类的结果加以影响。
5)Relation Classification
对于树结构的BiLSTM,存在两个传输方向,即从子节点到根节点方向 "↑",和从根节点到子节点方向 "↓"。本层的输入,为根节点位置↑方向上的隐藏状态,和两个实体的↓方向上的隐藏状态的拼接,即
![]()
与实体检测相似,最后使用两层全连接层加上softmax得到关系分类的结果

此外,考虑到每个输出都是只考虑到单词之间的关系,而无法利用整个实体的信息,为了缓解这个问题,本文将Sequence layer上对应实体的隐藏层状态求平均拼接到dp上,即

实验结果

================================================================================================
ACL 2017:Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme
================================================================================================
概述
本文指出,之前的关系抽取研究还是会依赖NER、依存关系树等外部特征。本文在仅使用词向量的情况下,得到了SOTA的效果。之前虽然也有端到端的基于神经网络关系抽取模型, 通过共享参数的方法将两个任务整合到同一个模型当中,但是实体抽取与关系识别任务仍然是两个分离的过程。
本文提出了一种新颖的标记方案,直接对三元组进行建模,它包含实体信息和它们所持有的关系。通过将实体关系联合抽取任务转化为序列标记问题,可以很容易地使用神经网络来建模,而不需要复杂的特征工程。此外,本文还开发了具有偏置损失函数的端到端模型,以适应提出的新型标注方式,可以增强相关实体之间的关联。
标注方式
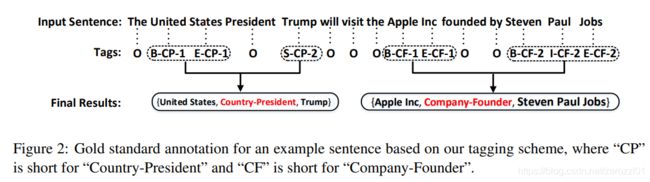
需要抽取的三元组可以表示为:(Entity1,RelationType,Entity2),其中,Entity1和Entity2需要抽取的文中的实体,RelationType为预定义的Entity1和Entity2之间的关系。
对于无关的对象用标签"O"标注。
实体对象的标签由三部分组成:单词位置、关系类型、关系角色
- 单词位置使用 "BIES" 的方式来标注,表示单词在实体中的位置信息
- 关系类型直接从预定义的关系集合中获得
- 关系角色直接用 "1" 和 "2" 表示,用于表示实体在三元组中的位置
标签的总数为2×4×|R|+1,其中|R|是预定义的关系集的大小。
解码的时候,将具有相同关系类型的实体组合为一个三元组以获得最终结果。如果一个句子包含两个或两个以上关系类型相同的三元组,则将每两个实体根据最临近原则组合成一个三元组。
模型架构
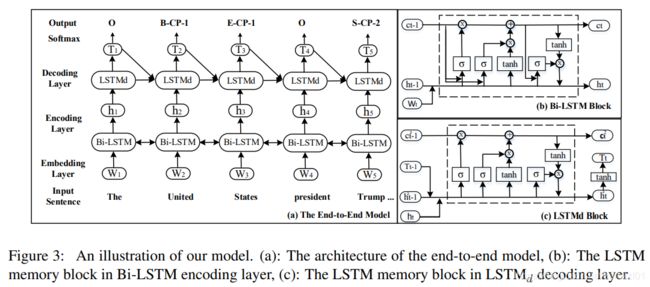
模型主要包含两部分,一个BiLSTM层用于对句子进行编码,一个基于LSTM带有偏置损失的解码层。
1)The Bi-LSTM Encoding Layer
本层的输入为词向量,W = {w1, ...wt , wt+1...wn},输出为前向和后向LSTM的拼接![]() 。
。
2)The LSTM Decoding Layer
本层t时刻的输入为:当前时刻编码层的输出![]() ,前一时刻的预测输出
,前一时刻的预测输出![]() ,还有本层上一时刻的隐藏状态
,还有本层上一时刻的隐藏状态![]() 和
和![]() 。其中,
。其中,![]() 。
。
最后,把T输入到最后的全连接层,得到分类得分,并进行归一化,得到最后的分类概率:

3)The Bias Objective Function

上式中,|D|是训练集的大小,Lj是句子xj的长度,![]() 是单词xj中词t的标注,
是单词xj中词t的标注,![]() 是模型输出的归一化标注概率。此外,I(O)是一个开关函数,以区分标注 ‘O’ 与 其他标注。他被定义如下:
是模型输出的归一化标注概率。此外,I(O)是一个开关函数,以区分标注 ‘O’ 与 其他标注。他被定义如下:
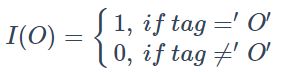
简单来说,就是使得模型对于实体标签与其他标签的关注程度不一样,而参数α就是偏置权重,α越大,模型对于实体的相关标注的偏向性就越大。
实验结果
特征分析

================================================================================================
EMNLP 2018:Joint entity recognition and relation extraction as a multi-head selection problem
================================================================================================

概述
本文指出目前的关系抽取研究存在依赖外部的NLP工具提取特征和无法处理关系重叠的问题。
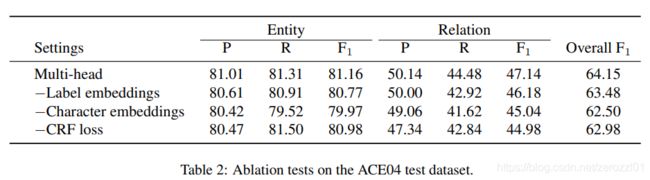
本文把每个实体的最后一个token称作head,在判断关系的时候,为了避免造成信息冗余,只判断每个实体的最后一个token与其他实体的最后一个token的关系(head与head之间的关系)。将实体关系联合抽取问题看作是一个multi-head selection的问题,即任何一个实体都可能与其他实体存在关系,解决关系重叠问题。
模型架构
本模型主要包含以下四部分:embedding layer、BiLSTM encoding layer、CRF layer、sigmoid scoring layer
1)embedding layer
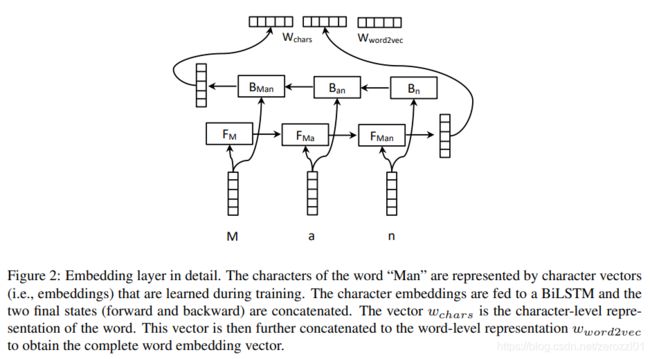
本层主要用于生成词的特征表示,包括word embeddings和character embeddings两个部分。引入character embeddings是因为可以通过其融入一些形态学特征。
2)BiLSTM encoding layer
利用多层BiLSTM对句子进行编码,每一个时刻的输出为两个方向的向量的拼接:

3)CRF layer
本层使用线性链条件随机场
![]()
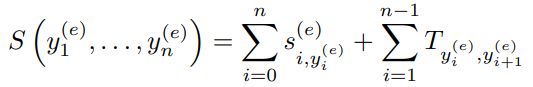
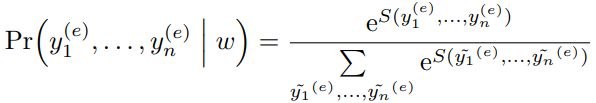
模型对于命名实体识别的标签引入label embedding,得到CRF的解码结果后,把标签转化为label embedding,然后和BiLSTM层的结果进行拼接,得到下一层的输入
![]()
4)sigmoid scoring layer
对于每一个head,可以对应其他多个heads,我们为每组![]() 计算得分,其中,
计算得分,其中,![]() 是heads的向量表示,
是heads的向量表示, 是对应的关系的向量表示。
是对应的关系的向量表示。
我们通过以下公式计算词wi、wj在给定关系rk时的得分:
![]()
之后把得分映射为概率值:
![]()
最后得到关系抽取的结果。
本模型的损失函数包括命名实体识别损失![]() 和关系抽取损失
和关系抽取损失![]() 两部分,其中
两部分,其中![]() 表示为:
表示为:

最后通过![]() 训练模型。
训练模型。
实验结果

特征分析
================================================================================================
ACL 2020:A Novel Hierarchical Binary Tagging Framework for Joint Extraction of Entities and Relations
================================================================================================

概述
目前的研究很少关于如何解决关系重叠的问题。本文提出一个级联二元标记框架(CASREL)来处理关系抽取问题。
不同于之前的研究把将关系视为实体对上的离散分类标签,本框架将关系建模为将句子中的subjects映射到objects的函数,这样可以很自然的处理关系重叠的问题。形式化来说,之前的研究学习分类器![]() ,而本文学习映射
,而本文学习映射![]() 。在本框架下,关系抽取可以分解为两个过程:首先,确定句子中所有可能的subjects;然后对每个subjects应用多个relation-specific的标记模块来同时识别所有可能的关系和对应的objects。
。在本框架下,关系抽取可以分解为两个过程:首先,确定句子中所有可能的subjects;然后对每个subjects应用多个relation-specific的标记模块来同时识别所有可能的关系和对应的objects。
模型架构
本模型包含两个部分:一个BERT Encoder,一个Cascade Decoder。首先通过BERT Encoder得到每个词的特征表示,然后进入Cascade Decoder进行解码。
Cascade Decoder包含以下两个部分:一个subjects标记模块、一个relation-specific objects标记模块。
1)Subject Tagger
本层用于识别句子中所有可能的subjects,输入为BERT Encoder的输出。其通过两个二分类器,分别给每个词分配一个二进制标签(0/1),检测出该词是否subjects的起始和结束位置。

![]() 表示该词是subjects的起始位置,
表示该词是subjects的起始位置,![]() 表示该词是subjects的结束位置,
表示该词是subjects的结束位置,![]() 为第i个词通过BERT的编码后的输出。
为第i个词通过BERT的编码后的输出。
训练过程中,使用以下函数进行优化:
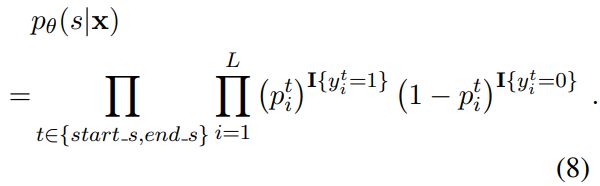
解码时,对于句子中存在多个subjects的情况,开始指针与结束指针通过就近匹配原则进行配对。
2)Relation-specific Object Taggers
本层包含一组relation-specific的和Subject Tagger结构一致的Object Taggers。简单来说,每种关系有一个对应的Object Taggers。

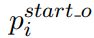 表示该词是objects的起始位置,
表示该词是objects的起始位置,![]() 表示该词是objects的结束位置,
表示该词是objects的结束位置,![]() 为第i个词通过BERT的编码后的输出,
为第i个词通过BERT的编码后的输出,![]() 为输入subjects的起始位置到结束位置的所有词的特征表示(
为输入subjects的起始位置到结束位置的所有词的特征表示(![]() )的平均池化。
)的平均池化。
训练过程中,使用以下函数进行优化:
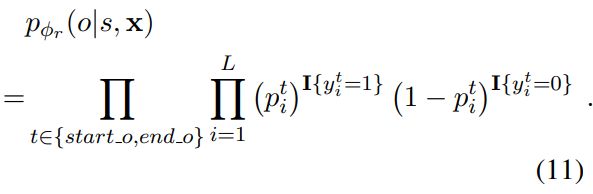
3)Data Log-likelihood Objecti
最后使用以下损失函数![]() 对模型进行联合训练:
对模型进行联合训练:

实验结果

4 半监督学习方法
4.1 优点、缺点
优点是:
- 可以利用丰富的知识库信息,减少一定的人工标注
缺点是:
- 引入大量噪声,存在语义漂移现象
- 无法识别新的关系
4.2 方法分类
半监督学习主要是利用少量的标注信息进行学习,这方面的工作主要是基于Bootstrap的方法以及远监督学习(distance supervision)方法。
1)基于Bootstrap的方法
主要是利用少量实例作为初始种子(seed tuples)的集合,然后利用pattern学习方法进行学习,通过不断迭代从非结构化数据中抽取实例,然后从新学到的实例中学习新的pattern并扩充pattern 集合,寻找和发现新的潜在关系三元组。
2)远监督学习(distance supervision)
主要是利用知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力。
4.3 Bootstrapping
Bootstrapping比较常见的方法有DIPRE和Snowball。和DIPRE相比,Snowball通过对获得的模板pattern进行置信度计算,一定程度上可以保证抽取结果质量。
Bootstrapping的优点是构建成本低,适合大规模的关系任务并且具备发现新关系的能力,但也存在对初始种子较为敏感、存在语义漂移、准确率等问题。
4.4 远监督学习(distance supervision)
4.4.1简介
2009年Mintz等人提出了远监督学习方法。远监督学习借助外部知识库为数据提供标签,从而省去人工标注的麻烦。Mintz提出一个假设,如果知识库中存在某个实体对的某种关系,那么所有包含此实体对的数据都表达这个关系。理论上,这让关系抽取的工作大大简化。但远监督学习也有副作用,因为不用人为的标注,只能机械地依赖外部知识库,将同一实体对的所有数据都会标注为同一种关系,其标签的准确度就会大大的降低。比如“汉武帝封卫青为大将军”,外部知识库中有关系:君臣(汉武帝,卫青)。在这句中,“君臣”关系是正确的,但在另一句话中“汉武帝是卫青姐姐的丈夫”,这里表达的关系是:亲属(汉武帝,卫青),而不是“君臣”,此时外部知识库提供的信息就是不准确的,从而引入大量的噪声。因此目前在远监督学习这个方向上的研究几乎都是聚焦在如何降噪。
2010年Riedel对Mintz的远程监督方法进行改进,提出EALO(Expressed-at-least-once)假设:如果知识库中存在某个实体对的某种关系,那么至少有一个提到此实体对的数据表达了此种关系。这个假设相对之前的假设温和了许多,也确实更贴进实际。但这假设也将抽取工作变得复杂,人们并不知道有哪些数据表达了知识库中提到的关系,哪些是噪声。因此Riedel引入另一个称为多示例学习(multi-instance learning)的技术。多示例学习是一种监督学习模式,虽然因为信息不充足,无法为每个数据样本打标签,但可以对具有某种特征的数据样本集合打标签,这样的样本集合称为袋(bag)。即在多示例学习中,每个bag有标签,而每个bag中含有多个数据样本,每个样本即为一个示例(instance),同一bag内的多个instance共享同一标签。
形式化的表示,设示例集X={x1,x2,...,xN},根据某种映射 f1,将示例集映射到bag空间B={B1,B2,...,BM},然后,将经过某种映射f2,将bag空间映射到标签空间L={L1,L2,...,LT}:
![]()
比如在关系抽取中,f1表示的一般为将同一实体对放在同一个bag中。而f2映射则是要学习的机器学习模型,将每个bag正确地打上标签。
当前主流的关系抽取模型几乎都在使用引入多示例学习的远程监督方法,再结合深度学习。
4.4.2论文笔记
================================================================================================
EMNLP 2015:Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks
================================================================================================

概述
本文指出,目前的基于远监督学习的关系抽取问题存在两个问题:1、难以解决噪声数据问题;2、依赖其他NLP工具的输出特征。
本文提出一个新的网络架构Piecewise Convolutional Neural Networks(PCNNs),结合multi-instance learning(多示例学习),用于解决以上两个问题。
针对第一个问题,本文设计了一个基于bag级别的目标函数,在学习过程中,可以考虑实例标签的不确定性,一定程度上缓解了标签错误的问题。
针对第二个问题,本文提出的PCNNs不依赖于任何NLP工具的输出。相对于传统的max pooling,PCNN把输入句子根据两个实体的位置切分成三段,每段分别使用piecewise max pooling,这样可以更好的捕获信息。
模型架构
本模型主要包括四部分:Vector Representation、Convolution、Piecewise Max Pooling、Softmax Output
1)Vector Representation
本层的输入是句子中的词,输出是词的Word Embeddings和Position Embeddings的拼接,其中每个词的Position是该词到两个实体的相对距离。
2)Convolution
对上一层的词的特征表示进行卷积运算。
3)Piecewise Max Pooling
对于关系抽取来说,普通的max pooling对于隐含层的维度减低太剧烈,难以捕获细粒度的特征,也无法捕获两个实体之间的结构信息。在关系抽取中,根据所选择的两个实体,可以将输入的句子分为三个部分。因此,本文提出piecewise max pooling,它返回每个部分中的最大值,而不是整个句子的最大值。
形式化的表示,我们把卷积层的第i个卷积核输出分成三段:![]() ,piecewise max pooling分别计算每段的最大值:
,piecewise max pooling分别计算每段的最大值:![]() ,最后得到该卷积核的池化后的表示:
,最后得到该卷积核的池化后的表示:![]() 。
。
然后,我们把所有卷积核的池化后的值拼接起来,然后使用tanh进行激活,得到本层的输出:![]() 。
。
4)Softmax Output
本层把上一层的输出输入到一个全连接层,得到最后的输出,并通过softmax得到分类概率: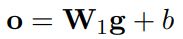 。
。
训练过程中为了防止过拟合,加入dropout,所以也可以表示为:![]() 。
。
多示例学习(Multi-instance Learning)
假设我们的训练数据有T个bags:![]() ,每个bag里面有
,每个bag里面有![]() 个样本:
个样本:![]() 。每个样本属于关系r的概率可以表示为:
。每个样本属于关系r的概率可以表示为:

多实例学习的目标,是使用bag的标签进行分类,而不是实例的标签。我们定义基于bag的损失函数:

其中,j基于以下规则选取:
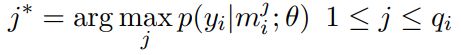
简单来说,训练过程中,我们并没有使用全部的样本实例,而是选取每个bag中预测概率最高的实例作为该bag的预测标签,计算损失,训练模型。
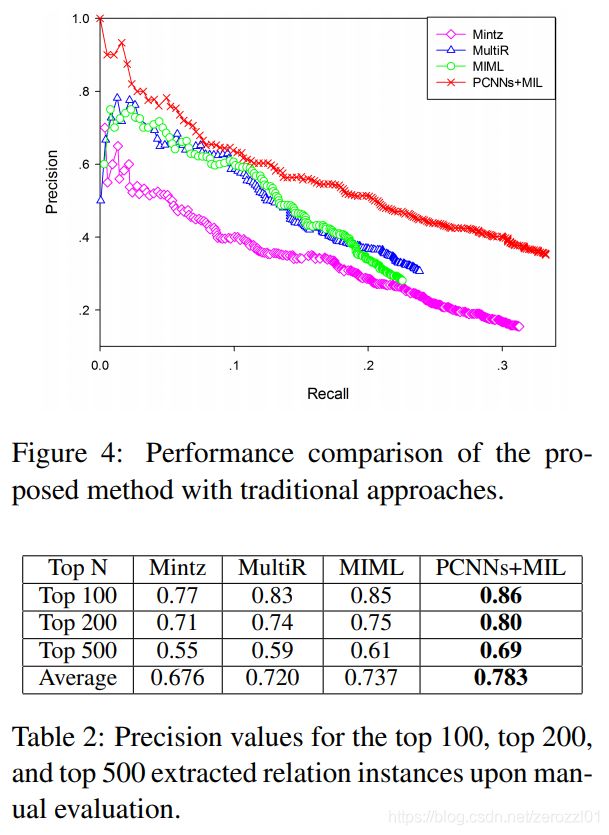
实验结果
================================================================================================
ACL 2016:Neural Relation Extraction with Selective Attention over Instances
================================================================================================
概述
本文提出一个基于句子级别注意力的关系提取模型,缓解远监督学习带来的噪声数据问题。
本文指出,之前的multi-instance learning对于每个实体对的bag只使用概率最高的句子进行训练和预测,浪费了大量被忽略的句子所包含的信息。本文提出的模型,在同一个bag的多个实例上建立句子级别的注意力,动态地减少噪声实例的权重,这样可以减少噪声数据的影响,但是同时也可以使用所有的句子信息。
模型架构

本模型包括两部分:
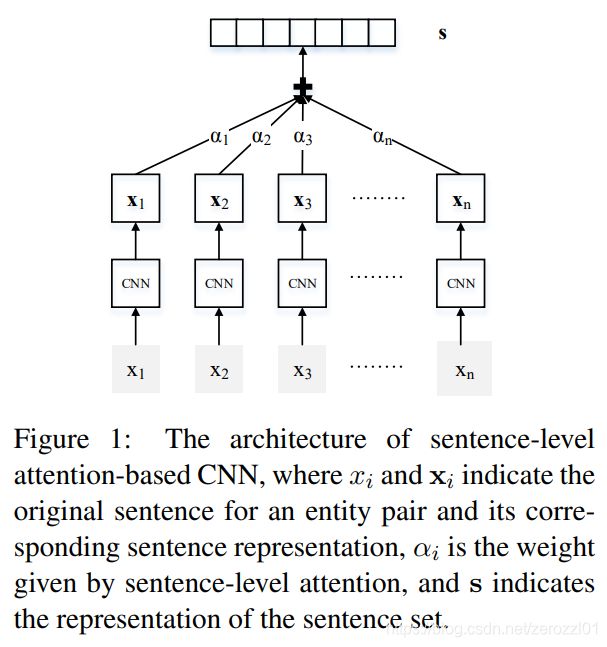
- Sentence Encoder:对于给定实体对以及其对应的bag的其中一个句子,把句子编码成向量表示。
- Selective Attention over Instances:对于给定实体对以及其对应的bag的所有句子的向量表示,使用句子级别注意力来为每个句子计算其对于所在bag对应关系的权重。
1)Sentence Encoder
首先把每个词转换成Word Embeddings和Position Embeddings的拼接表示![]() 。
。
然后对句子进行卷积运算,接着通过max pooling或者piecewise max pooling对卷积结果进行池化,最后把池化的结果输入到激活层,得到最终的句子表示![]() 。
。
2)Selective Attention over Instances
给定一对实体对的bag中的所有句子的向量表示![]() ,我们通过以下公式计算该bag的最终表示:
,我们通过以下公式计算该bag的最终表示:


![]()
其中A是一个需要学习参数矩阵,r是bag对应的关系的向量表示。
然后,我们把bag的向量表示输入到全连接层,得到最终的输出
![]()
其中,d是需要学习的偏置,M是所有的关系的表示矩阵。
最后通过softmax得到每个关系的概率输出:

损失函数定义为:
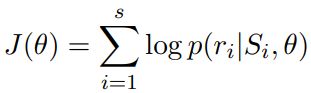
实验结果


================================================================================================
AAAI 2018:Reinforcement Learning for Relation Classification from Noisy Data
================================================================================================

概述
之前的远监督学习关系分类方法基于bag级别进行分类,无法准确的把句子和关系进行关联。此外,当bag中的所有句子都没有描述对应关系时,这些方法都没办法很好的处理这种情况。
本文提出了一种新的关系分类框架,该框架能够从带有噪声的数据中选择正确的句子进行关系分类,该框架直接过滤掉有噪声的句子,而不仅仅是降低噪声句子的权重。该框架由两个关键模块组成:实例选择器和关系分类器。实例选择器从有噪声的数据中选择正确表示对应关系的句子,并将所选择的句子输入到关系分类器中。关系分类器进行句子级别关系分类,并为实例选择器提供奖励。两个模块共同训练,优化实例选择和关系分类过程。
方法论
1)实例选择器
本文将实例选择看作一个强化学习问题,agent是实例选择器,environment由数据和关系分类器一起组成,双方进行交互。实例选择器的目标是确定哪个句子真正描述了对应的关系,并且选择作为一个训练实例。当完成选择后,把选中的训练实例集提供给关系分类器用作训练,并从关系分类器的反馈中获得一个奖励,根据奖励优化策略函数。
本文把训练语句实例划分为N个bags,B = {B1 , B2 , . . . , BN },bag的划分方式和传统的远监督学习方法一样,把所有包含相同实体对的句子划分在一个bag当中。每当完成一个bag中句子的扫描,就计算相应的奖励,更新一次策略函数。相对于完成整个训练集的扫描再计算奖励,这样可以获得更多的奖励,提高训练效率。
当实例选择器训练完成后,我们把所有由实例选择器选择出的句子合并成一个新的训练集,用于训练关系分类器。
状态si是一个向量![]() ,由当前句子xi、句子xi中的实体对hi和ti、之前已经选中的的句子{x1,···,xi−1}联合表示。当前句子的向量表示,由关系分类器的网络提取得到。实体的向量表示,取一个预先训练好的知识图谱的实体的向量表示。选中句子的联合表示,取所有之前已经选中句子的向量表示的平均值。
,由当前句子xi、句子xi中的实体对hi和ti、之前已经选中的的句子{x1,···,xi−1}联合表示。当前句子的向量表示,由关系分类器的网络提取得到。实体的向量表示,取一个预先训练好的知识图谱的实体的向量表示。选中句子的联合表示,取所有之前已经选中句子的向量表示的平均值。
动作ai ∈ {0, 1},用来指示xi是否被选择为一个训练实例。ai的取值由策略函数决定,本文采用logistic函数作为策略函数:

当对一个bag中的所有句子完成选择后![]() ,会获得一个最终奖励
,会获得一个最终奖励![]() ,其他状态的奖励为零:
,其他状态的奖励为零:

其中,![]() 是所有选中句子的集合,r是bag对应的标签,
是所有选中句子的集合,r是bag对应的标签, 是由关系分类器计算得到。
是由关系分类器计算得到。
对于![]() 为空的特殊情况,把奖励设置为bag中所有句子的预测值的平均,这使得实例选择器能够有效的处理噪声包的情况。
为空的特殊情况,把奖励设置为bag中所有句子的预测值的平均,这使得实例选择器能够有效的处理噪声包的情况。
对于目标选择器,目标函数定义为:

策略更新方式为:

2)关系分类器
一般的用于关系分类的卷积神经网络,这里不作详细介绍。
3)联合训练
我们首先使用噪声数据对关系分类器做预训练,然后使用预训练好的关系分类器,对实例选择器做预训练,最后再对实例选择器和关系分类器做联合训练。


实验结果


================================================================================================
ACL 2018:Robust Distant Supervision Relation Extraction via Deep Reinforcement Learning
================================================================================================
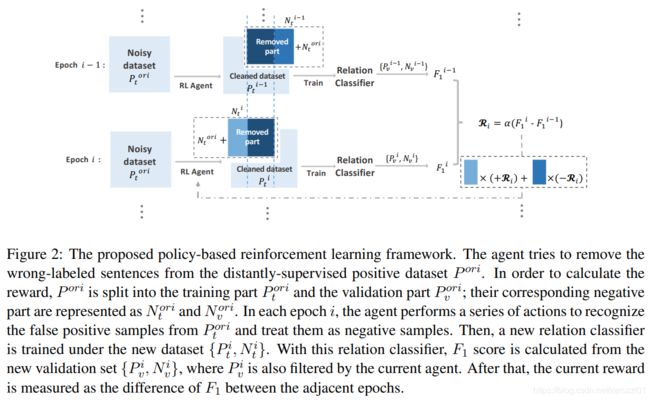
概述
本文提出,假阳性样本对于远监督学习的训练效果有很大影响。提出使用深度强化学习,自动识别每个关系类型的假阳性样本。与之前研究不同,本文并没有直接移除假阳性样本,而是将它们重新分配到反面实例中。本文设计了一个深度强化学习agent,其目标是根据关系分类器的性能变化来学习选择是删除还是保留候选实例。

方法论
首先介绍本文提出的强化学习模型。
状态s由当前句子的向量表示和之前被删除的句子的向量表示拼接得到。当前句子的向量表示,由关系分类器的网络提取得到。之前被删除的句子的向量表示,取所有之前被删除的句子的向量表示的平均值。
动作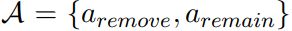 ,用来指示当前句子xi是否假阳性样本。
,用来指示当前句子xi是否假阳性样本。
奖励由关系分类器的F1值变化决定,表示为![]() 。奖励的值在一个连续的空间当中,相对于{−1、1}这种二元空间更合理。为了随机性,我们使用最近5个epoch的平均F1来计算奖励。
。奖励的值在一个连续的空间当中,相对于{−1、1}这种二元空间更合理。为了随机性,我们使用最近5个epoch的平均F1来计算奖励。
策略网络使用普通的CNN网络。
1)预训练策略网络
本文假设,在高质量的远监督数据集中,真阳性样本在数量上比假阳性样本具有明显的优势。因此,直接将远监督正集作为正集,并随机抽取部分远监督负集作为负集。考虑到负样本越多,对agent学习越有利,所以选择的负样本的数量是正样本数量的10倍。
目标函数采用交叉熵函数(其中负标签对应删除动作,正标签对应保留动作):
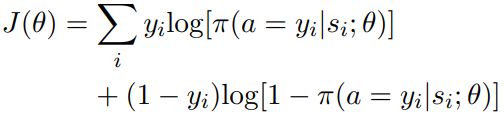
为了避免过拟合噪声数据,当预训练准确率到达85% ~ 90%时,停止训练。
1)重训练策略网络
我们把原始的远监督数据集分为正训练集![]() 和正验证集
和正验证集![]() ,并随机选取负训练集
,并随机选取负训练集![]() 和负验证集
和负验证集![]() 。
。
每一次迭代,agent从![]() 中移除一部分假阳性样本
中移除一部分假阳性样本![]() ,得到一个新的正训练集
,得到一个新的正训练集![]() 和新的负训练集
和新的负训练集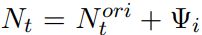 。使用
。使用![]() 训练关系分类器,然后使用训练好的关系分类器对原始的验证集
训练关系分类器,然后使用训练好的关系分类器对原始的验证集![]() 进行过滤,得到
进行过滤,得到![]() 并使用它来计算当前关系分类器的F1值。最后,利用当前的F1值和和前一时期的F1值的差值来计算奖励。
并使用它来计算当前关系分类器的F1值。最后,利用当前的F1值和和前一时期的F1值的差值来计算奖励。
为了训练一个更加robust的agent,我们加入以下几个策略:
a) 每个epoch删除固定或者少于固定数量的句子,这样可以让agent学会删除更加重要的假阳性样本,而不是删除更多的样本。
b) 为了让agent学会每次删除不一样的样本,而不是每次都只删除容易区分的样本,我们定义以下目标函数:
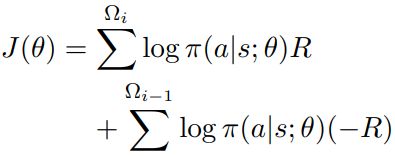
其中,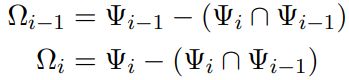 。
。
如果F1分在第i次迭代中增加,则表示第i次迭代的行为比第i-1次迭代中的行为更合理,所以,我们将正奖励分配给![]() ,负奖励分配个
,负奖励分配个![]() ,反之亦然。
,反之亦然。
c) 使用agent重新对训练集进行过滤。
整个训练过程如下所示:

实验结果


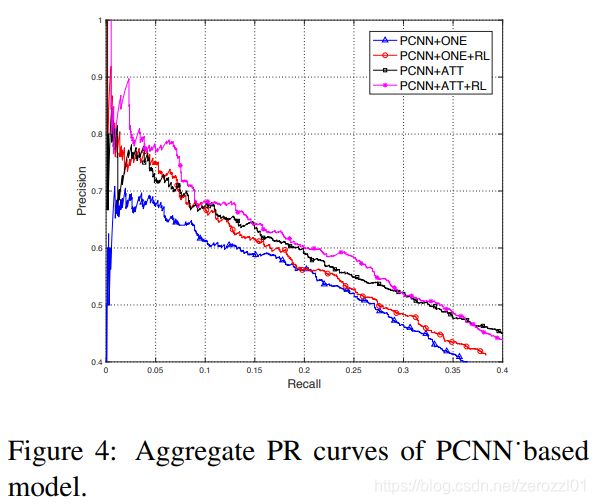
================================================================================================
NAACL 2019:Distant Supervision Relation Extraction with Intra-Bag and Inter-Bag Attentions
================================================================================================
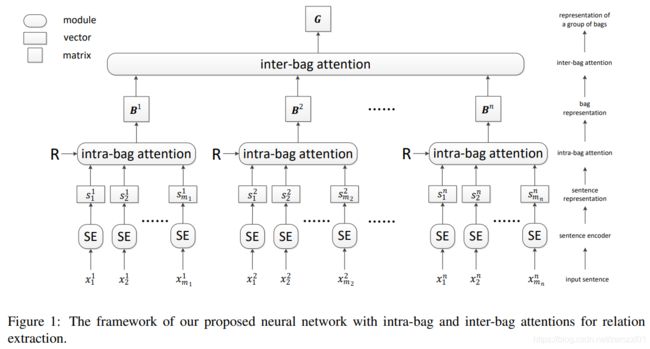
概述
本文提出,之前的远监督学习的研究主要集中如何通过intra-bag的句子级别注意力减少噪声数据的影响,本文结合intra-bag的句子级别注意力和inter-bag的bag级别注意力,处理噪声问题。
首先,计算bag内的每个句子对于各个关系标签的注意力权重,而不仅仅是计算对于该bag关系标签的注意力权重。然后,对于具有相同关系标签的多个bag组成的bag group,计算bag间的相似度,并把多个bag的向量表示进行加权组合。最后,训练模型时,以bag group作为训练样本。
模型架构
我们用![]() 表示一组具有相同关系标签的bags,
表示一组具有相同关系标签的bags,![]() 表示一个bag内的句子,
表示一个bag内的句子,![]() 表示一个句子。
表示一个句子。
本模型主要包含三个部分:
- Sentence Encoder:给定一个句子
 和两个实体在句子中的位置,使用CNN或者PCNN把句子编码成向量表示
和两个实体在句子中的位置,使用CNN或者PCNN把句子编码成向量表示 。
。 - Intra-Bag Attention:给定一个bag内的所有句子向量表示以及关系标签的embedding矩阵R,计算每个句子对于每个关系的注意力权重
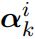 、整个bag对于每个关系的向量表示
、整个bag对于每个关系的向量表示 ,其中k表示第k种关系。
,其中k表示第k种关系。 - Inter-Bag Attention:给定一组具有相同关系标签的bags的向量表示,计算bag group内各个bag间的相似度,并得到该bag group的向量表示。
1)Sentence Encoder
首先把每个词转换成Word Embeddings和Position Embeddings的拼接表示![]()
![]() 。
。
然后对句子进行卷积运算,接着通过piecewise max pooling对卷积结果进行池化,得到最终的句子表示![]() 。
。
2)Intra-Bag Attention
对于每种关系k分别计算bag对于该关系的向量表示:

其中![]() 是关系索引,
是关系索引, 是句子j对于关系k的注意力权重,通过以下公式计算:
是句子j对于关系k的注意力权重,通过以下公式计算:
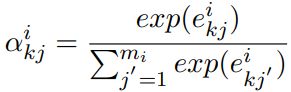
![]()
其中![]() 是关系向量矩阵的第k行,也就是关系k的向量表示。
是关系向量矩阵的第k行,也就是关系k的向量表示。
最后得到整个bag的向量表示:![]()
3)Inter-Bag Attention
对于每种关系k分别计算bag group对于该关系的向量表示:
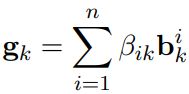
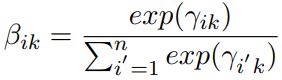
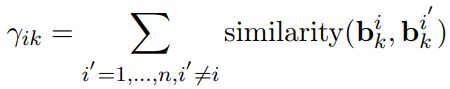
![]()
计算前需要做归一化处理:![]()
然后把![]() 和关系向量相乘,得到最后的得分:
和关系向量相乘,得到最后的得分:
![]()
最后再用softmax得到分类概率
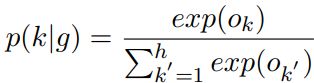
4)Objective Function
首先,将训练集中包含两个相同实体的所有句子放到一个bag中。然后,我们将每n个共享相同关系标签的bag放到一个bag group中。需要注意的是,在本文的方法中,一个训练样本就是一个bag group。
最后损失函数如下所示:

实验结果

5 无监督学习方法
5.1 优点、缺点
优点是:
- 无需人工标注数据
- 可以自动发现新的关系
缺点是:
- 难以描述聚类的结果
- 召回率低
5.2 论文笔记
================================================================================================
ACL 2016:Discrete-State Variational Autoencoders for Joint Discovery and Factorization of Relations
================================================================================================

概述
================================================================================================
ACL 2019:Unsupervised Information Extraction: Regularizing Discriminative Approaches with Relation Distribution Losses
================================================================================================
概述
本文指出,之前的无监督学习的关系抽取方法依赖手工特征和其他NLP工具的输出。并且存在总是预测同一种关系,或预测结果均匀分布的问题。
本文提出端到端的神经网络模型实现无监督学习关系抽取。并且提出两种损失函数,解决预测结果分布的问题:
- skewness loss:鼓励分类器把一个句子以尽可能高的概率预测到一个关系上。
- distribution distance loss:鼓励分类器将一组句子尽量分散到多个不同的关系中。
模型架构

本模型使用fill-in-the-blank任务给模型提供训练的信号,具体来说,对于给定句子“The ![]() was the currency of
was the currency of ![]() between 1863 and 1985.”,模型需要预测出
between 1863 and 1985.”,模型需要预测出![]() 对应的词。
对应的词。
为了正确的预测出![]() ,我们可以直接学习预测缺失的实体,但在这种情况下,我们将无法学习一个关系分类器。然而,在预测实体之前,我们想首先了解这个句子表达的语义关系,我们假设这种关系可以通过围绕两个实体的其他文本来预测,然后,我们通过预测的关系和另一个实体,尝试预测缺失的实体。
,我们可以直接学习预测缺失的实体,但在这种情况下,我们将无法学习一个关系分类器。然而,在预测实体之前,我们想首先了解这个句子表达的语义关系,我们假设这种关系可以通过围绕两个实体的其他文本来预测,然后,我们通过预测的关系和另一个实体,尝试预测缺失的实体。
形式化的表示如下:

其中,![]() 和
和![]() 是两个实体,s是围绕两个实体的其他文本,r是两个实体间的关系。
是两个实体,s是围绕两个实体的其他文本,r是两个实体间的关系。
1)Unsupervised Relation Classifier
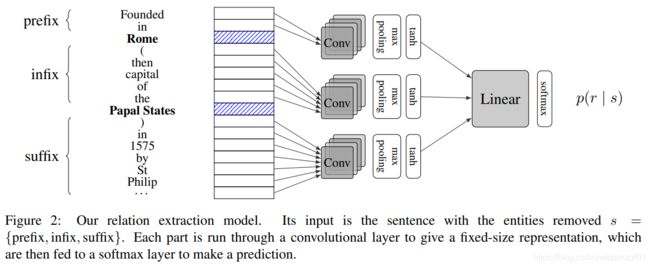
本模型把输入分为三段{prefix,infix,suffix},注意,两个实体没有包含在内。然后使用三个权重不共享的卷积模块,分别对三段进行卷积。卷积模块包含卷积、max pooling、tanh激活三部分。最后把三部分的输出相加,并通过一个全连接层,再通过一个softmax得到最后的关系分类结果。
![]()
2)Link Predictor
Link Predictor的目的是为Unsupervised Relation Classifier提供监督学习信号。使用以下形式计算:
![]()
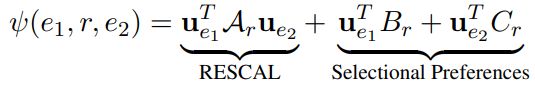
其中![]() 是实体向量矩阵,
是实体向量矩阵,![]() 、
、![]() 是参数矩阵。
是参数矩阵。
训练过程中,由于难以穷举所有的所有的实体,所以使用Negative Sampling的方式训练模型。
损失函数如下所示:

3)RelDist loss
只使用![]() 作为损失函数会非常不稳定,一般来说会出现以下两种情况:
作为损失函数会非常不稳定,一般来说会出现以下两种情况:
- 分类器不确定要表达的是哪一种关系,输出遵循均匀分布
- 所有的句子都被分类成同一种关系
在这两种情况下,Link Predictor可以通过忽略Relation Classifier的输出,简单地利用实体间的共存现象来最小化![]() 。
。
为了克服上述问题,本文增加了两个额外的损失:Skewne loss、Dispersi loss。
Skewne loss:为了避免Relation Classifier对单个句子的预测结果成均匀分布,我们希望预测结果的熵尽可能的低:![]() 。
。
Dispersi loss:为了避免Relation Classifier把所有句子都预测成同一种关系,我们加入KL散度,让所有句子的预测结果尽量靠近均匀分布,让输出结果尽可能分散到各个关系当中:![]() 。
。
最后我们把所有的损失函数进行汇总:![]() 。其中
。其中![]() 和
和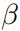 是超参数,由人工设置。
是超参数,由人工设置。
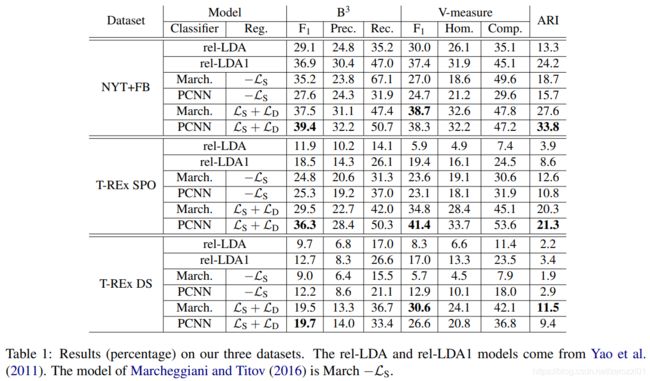
实验结果
================================================================================================
ACL 2020:Revisiting Unsupervised Relation Extraction
================================================================================================
概述
本问题提出,实体类型对Unsupervised Relation Extraction(URE)有强的归纳倾向,仅使用命名实体的类型来进行URE,就可以得到很好的效果。
具体来说,给定一个由两个实体组成的句子及其对应的实体类型,例如PERSON和LOCATION,我们将关系归纳为实体类型的组合,例如PERSON-LOCATION。
同时本文也证明了,之前的研究中的link predictor的确可以提供一个良好的学习信号。
模型架构
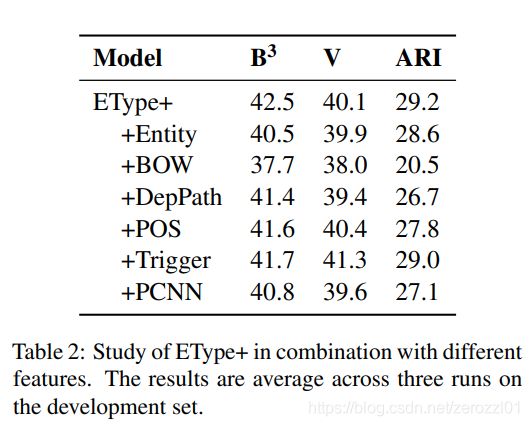
本文提出两个模型EType和EType+。
1)EType
给定两个实体的类型![]() 、
、![]() 作为输入,EType把它们的连接
作为输入,EType把它们的连接![]() 作为关系输出。
作为关系输出。
2)EType+
EType的一个问题是,关系类型的数量随实体类型的数量指数增长。例如,4个实体类型的组合,将导致16种关系类型。
为了提取任意数量的关系类型,我们构建一个以实体类型组合为输入的由单层前馈神经网络组成的关系分类器:
![]()
其中![]() 是实体类型的one-hot编码。然后我们结合link predictor训练模型。
是实体类型的one-hot编码。然后我们结合link predictor训练模型。
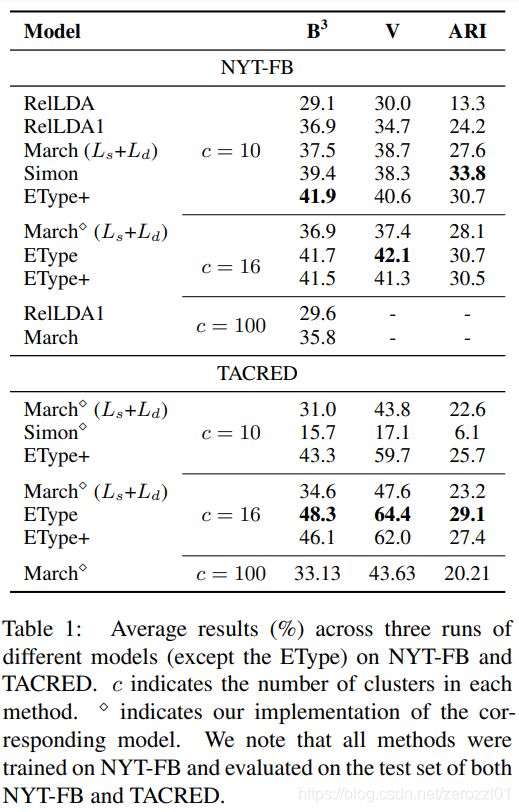
实验结果
特征分析