PSPNet :语义分割
PSPNet :语义分割
随着卷积神经网络在目标检测任务上的推进,它也开始被用于更精细的图像处理任务:语义分割和实例分割。目标检测只需要预测图像中每个对象的位置和类别,语义分割还要把每个像素都进行分类,而实例分割的任务则更难,要进一步把每个对象的不同实例都区分开。

图像语义分割(semantic segmentation),从字面意思上理解就是让计算机根据图像的语义来进行分割。语义分割是对图像中的每一个像素进行分类,目前广泛应用于医学图像与无人驾驶等。语义在语音识别中指的是语音的意思,在图像领域,语义指的是图像的内容,对图片意思的理解。
文章目录
- PSPNet :语义分割
- 一、VOC2012_AUG数据集简介
- 二、PSPNet模型结构
- 三、实验过程
- 四、深入思考
- 五、源码
- 六、项目链接
一、VOC2012_AUG数据集简介
VOC12_AUG:基于voc扩充的一个语义分割数据集。其组成可参考:https://blog.csdn.net/lscelory/article/details/98180917。类别继承自voc,共20个类别。
下载地址: http://home.bharathh.info/pubs/codes/SBD/download.html
img文件夹:原始数据集,内含11355张rgb图片,20类目标 + 1类背景。
cls文件夹:原始数据集,内含11355个语义分割.mat文件,label信息用数值0-21表示,0代表背景信息, 1-20代表图片中目标物体种类。

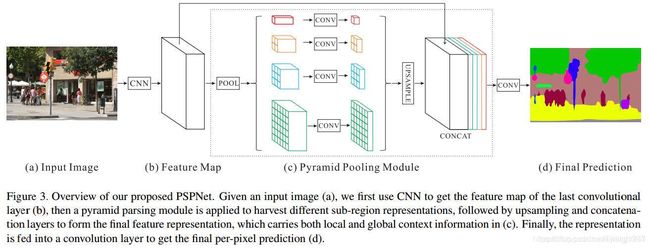
二、PSPNet模型结构
全卷积网络FCN的缺点,在于缺少合适的策略来使用全局场景分类信息。金字塔场景分析网络PSPNet通过结合局部和全局信息来提高最终预测的可靠性。
模型通过金字塔池化模块在四个不同的粗细尺度上进行特征融合。最粗尺度对特征图进行全局平均池化,产生单格输出;加细尺度把特征图分成不同子区域,产生多格输出。不同尺度级别的输出对应不同大小的特征图,然后低维特征图通过双线性插值进行上采样获得相同大小的特征。最后,不同级别的特征被拼接为最终的金字塔池化全局特征。
一、第1部分:网络输入。
inputs_size = (473, 473, 3)
inputs = Input(shape=inputs_size)
二、第2部分:特征提取网络backbone,采用mobile_net_v2结构。
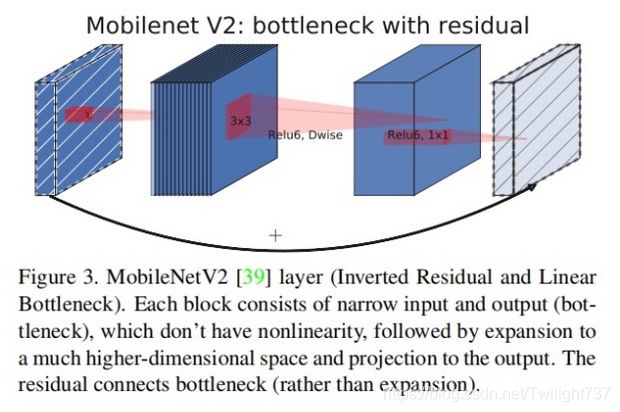 通过多次卷积、池化、跨层连接进行特征提取, 最后输出两个特征层:
通过多次卷积、池化、跨层连接进行特征提取, 最后输出两个特征层:
f4为辅助分支 - (None, 30, 30, 96) 。(备注:此分支在代码中并未用上。)
o为主干部分 - (None, 30, 30, 320)。
f4 = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=12, skip_connection=True) # (None, 30, 30, 96)
o = _inverted_res_block(x, filters=320, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=16, skip_connection=False) # (None, 30, 30, 320)
三、第3部分:利用金字塔池化模块,在四个不同的粗细尺度上进行特征融合。
主干特征提取结果feature map,shape = (None, 30, 30, 320),记为1。
对主干特征o按pool_size = (30, 30)进行池化,shape = (None, 1, 1, 80),再利用双线性插值tf.image.resize函数上采样,得到shape = (None, 30, 30, 80)的特征提取结果feature map,记为2。
对主干特征o按pool_size = (15, 15)进行池化,shape = (None, 2, 2, 80),再利用双线性插值tf.image.resize函数上采样,得到shape = (None, 30, 30, 80)的特征提取结果feature map,记为3。
对主干特征o按pool_size = (10, 10)进行池化,shape = (None, 3, 3, 80),再利用双线性插值tf.image.resize函数上采样,得到shape = (None, 30, 30, 80)的特征提取结果feature map,记为4。
对主干特征o按pool_size = (5, 5)进行池化,shape = (None, 6, 6, 80),再利用双线性插值tf.image.resize函数上采样,得到shape = (None, 30, 30, 80)的特征提取结果feature map,记为5。
将1、2、3、4、5进行特征图拼接: o = Concatenate(axis=-1)(pool_outs)
(30, 30, 320) + (30, 30, 80) + (30, 30, 80) + (30, 30, 80) + (30, 30, 80) = (30, 30, 640)
最后得到多尺度特征融合结果:shape = (None, 30, 30, 640)
四、第4部分:网络输出。
先经过一轮卷积操作,再把通道数切换成n_classes,最后tf.image.resize函数上采样。
Conv2D(out_channel//4, (3, 3),padding=‘same’, use_bias=False) # (None, 30, 30, 80)
BatchNormalization() # (None, 30, 30, 80)
Activation(‘relu’) # (None, 30, 30, 80)
Dropout(0.1) # (None, 30, 30, 80)
Conv2D(n_classes, (1, 1), padding=‘same’) # (None, 30, 30, 21)
Lambda(resize_images)([o, img_input]) # (None, 473, 473, 21)
o = Activation(“softmax”) # (None, 473, 473, 21)
三、实验过程
网络模型共有175层,训练前先导入网上下载好的mobile_net_v2权重, by_name=True, skip_mismatch=True跳过不匹配结构,然后把其对应的前146层网络冰冻起来,开始训练。
优化器adam = Adam(lr=1e-4),训练50个epoch左右,val loss在0.2附近达到瓶颈。此时对于(473, 473)大小的rgb图片,所有像素值总计分类精度达到93%左右,效果还算不错。
测试集语义分割结果如下,背景像素默认为天蓝色:












四、深入思考
Ques1:PSPNet和FCN有什么区别?
PSPNet和U-Net、FCN相比,两者区别在于特征提取的方式不同。应该说,PSPNet特征提取的效果是更佳的,它采用了更多样化的卷积尺寸,提取到的特征更具多样性。而相比起来,U-Net从头到位都是在一个feature map模板上不断上采样做操作,相比起来提取到的特征更佳单一。
U-Net上采样是利用的是反卷积操作,而PSPNet用的是双线性插值进行上采样。
Ques2:可不可以拿语义分割来做目标检测?
语义分割是对每个像素都进行分类,而实例分割进一步把每个类别的不同实例的像素都区分开。
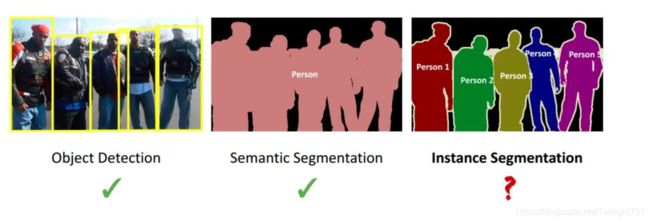
对于单对象目标检测问题,也就是每张rbg图片上每类目标物体最多只能出现一次的情况,可以拿语义分割进行目标检测,而且此时检测效果应该会不错。但对于多个对象的目标检测,语义分割会将这些像素点全分类到一起,无法间隔开来,此时必须要借助实例分割。
Ques3:四种最常见的上采样操作:
常见的上采样方法有双线性插值、转置卷积、上采样(unsampling)和上池化(unpooling)。其中前两种方法较为常见,后两种用得较少。
(1)双线性插值。
双线性插值,又称为双线性内插。在数学上,双线性插值是对线性插值在二维直角网格上的扩展,用于对双变量函数(例如 x 和 y)进行插值。其核心思想是在两个方向分别进行一次线性插值。
在FCN中上采样用的就是双线性插值,双线性插值方法中不需要学习任何参数。
(2)反卷积。
转置卷积像卷积一样需要学习参数。如果我们想要网络学习到最好地上采样的方法,这个时候就可以采用转置卷积,它具有可以学习的参数。
可以将一个卷积操作用一个矩阵表示,无非就是将卷积核重新排列到我们可以用普通的矩阵乘法进行矩阵卷积操作。从本质来说,我们通过在输入矩阵中的元素之间插入0进行补充,从而实现尺寸上采样,然后通过普通的卷积操作就可以产生和转置卷积相同的效果。
(3)上采样(Upsamppling)。
unsampling针对对应的上采样区域,全部填充的相同的值,比较粗糙。
(4)上池化(UpPooling)。
unpooling将原始值填充到上采样对应的位置上,其他位置则以0来进行填充,比较粗糙。
Ques4:源码中的上采样插值是否过于粗糙,直接由(30, 30)上采样扩充成(473, 473)尺寸?
o = Conv2D(n_classes, (1, 1), kernel_initializer=random_normal(stddev=0.02),
padding=‘same’)(o) # (None, 30, 30, 21)
o = Lambda(resize_images)([o, img_input]) # (None, 473, 473, 21)
刚开始的时候觉得这里的resize太过粗糙了,居然直接放大了16倍,特征非常不精密。
但后来仔细想想,本来语义分割里,属于同一类的区域也常常是一大片一大片聚集的,不太可能出现不同类别像素点非常零散的分布,本就是一大片区域密集出现,因此粗糙点应该也不影响效果。
Ques5:数据处理中碰到的一些问题。
(1)对于语义分割标注图片,利用Image.open函数能直接读出png文件的标注信息,得到一个单通道矩阵,对应位置处的像素值由0-20记录,正好对应不同目标物体类别。但不能利用opencv读取,此时得到的是一个三通道矩阵,标注信息反而丢失了。
(2)对语义分割标注label的resize操作,必须采用cv2.INTER_NEAREST最邻近插值。普通线性插值、样条插值会破坏原始像素点标记信息,产生新的类别数值,标注信息不再准确。在resize图像缩放时,新的像素内容应该和周边区域是一样的,利用最邻近插值,自然标记类别也一样。
cv2.INTER_NEAREST最邻近插值完美解决了语义分割的缩放问题,以后可以针对模型任意缩放尺寸,调整至最佳语义分割效果。
Ques6:源码复现中遇到的最大bug。
我利用10000张图片进行训练,1355张图片进行测试,训练20个epoch左右,val loss降低到0.2附近出现完全瓶颈,再也没办法降低下去。
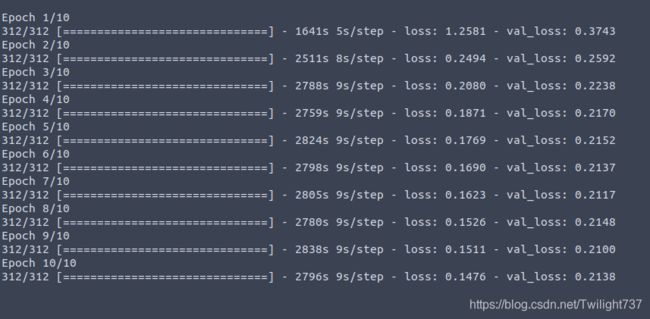
利用此时的权重进行语义分割,效果却极差。我原以为是算法或数据集的问题,损失函数在0.2附近降低不下去了,导致效果不好,模型训练效果不佳。反复debug之后,发现是检测代码有一句出现了逻辑bug。
原本写的是:
psp_model.load_weights(‘Logs/2/epoch055-loss0.050-val_loss0.223.h5’, by_name=True, skip_mismatch=True)
应该改成:
psp_model.load_weights(‘Logs/2/epoch055-loss0.050-val_loss0.223.h5’)
原来问题出在,我加载训练好的权重进行语义分割预测时,并没有完整加载进所有权重,部分网络层被skip跳过了,采用的还是最开始随机初始化的权重,模型预测效果自然极差。修改完这个bug之后,VOC2012数据集每张图片的所有像素值分类精度能达到93%左右,非常不错。
而且我发现,在冰冻backbone特征提取网络层后,剩余部分只需要用600张左右就能训练出不错的效果,val loss也能降低到0.2附近,并不需要用到上万张图片。
五、源码
主函数:
import numpy as np
import cv2
import os
from read_data_path import make_data
from psp_model import get_psp_model
from train import SequenceData
from train import train_network
from train import load_network_then_train
from detect import detect_semantic
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
class_dictionary = {0: 'background', 1: 'aeroplane', 2: 'bicycle', 3: 'bird', 4: 'boat',
5: 'bottle', 6: 'bus', 7: 'car', 8: 'cat', 9: 'chair',
10: 'cow', 11: 'dining_table', 12: 'dog', 13: 'horse', 14: 'motorbike',
15: 'person', 16: 'potted_plant', 17: 'sheep', 18: 'sofa', 19: 'train',
20: 'TV_monitor'}
if __name__ == "__main__":
train_x, train_y, val_x, val_y, test_x, test_y = make_data()
psp_model = get_psp_model()
psp_model.summary()
train_generator = SequenceData(train_x, train_y, 32)
test_generator = SequenceData(test_x, test_y, 32)
# train_network(train_generator, test_generator, epoch=10)
# load_network_then_train(train_generator, test_generator, epoch=20, input_name='first_weights.hdf5',
# output_name='second_weights.hdf5')
# detect_semantic(test_x, test_y)
read_data_path:准备数据集
import numpy as np
import cv2
import os
class_dictionary = {0: 'background', 1: 'aeroplane', 2: 'bicycle', 3: 'bird', 4: 'boat',
5: 'bottle', 6: 'bus', 7: 'car', 8: 'cat', 9: 'chair',
10: 'cow', 11: 'dining_table', 12: 'dog', 13: 'horse', 14: 'motorbike',
15: 'person', 16: 'potted_plant', 17: 'sheep', 18: 'sofa', 19: 'train',
20: 'TV_monitor'}
# VOC2012_AUG数据集简介:
# 两个文件夹: img文件夹包含11355张rgb图片,cls文件夹包含11355个语义分割.mat文件,id序号完全对应
# 利用scipy.io.loadmat函数读取cls中的.mat文件,可以得到标注信息。
# 读取得到 (h,w) 单通道矩阵,像素值总共有21个类别,由21个数字代替:0、1、2、...、20。
# 0代表背景信息
# 1-20代表图片中目标物体种类
def read_path():
data_x = []
data_y = []
filename = os.listdir('cls')
filename.sort()
for name in filename:
serial_number = name.split('.')[0]
img_path = 'img/' + serial_number + '.jpg'
seg_path = 'cls/' + serial_number + '.mat'
data_x.append(img_path)
data_y.append(seg_path)
return data_x, data_y
def make_data():
data_x, data_y = read_path()
print('all image quantity : ', len(data_y)) # 11355
train_x = data_x[:10000]
train_y = data_y[:10000]
val_x = data_x[10000:]
val_y = data_y[10000:]
test_x = data_x[10000:]
test_y = data_y[10000:]
return train_x, train_y, val_x, val_y, test_x, test_y
mobile_netv2:特征提取backbone
from keras.activations import relu
from keras.layers import Activation, Add, BatchNormalization, Conv2D, DepthwiseConv2D, Input
from keras.initializers import random_normal
inputs_size = (473, 473, 3)
down_sample = 16
block4_dilation = 1
block5_dilation = 2
block4_stride = 2
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
def relu6(x):
return relu(x, max_value=6)
def _inverted_res_block(inputs, expansion, stride, alpha, filters, block_id, skip_connection, rate=1):
in_channels = inputs.shape[-1]
point_wise_filters = _make_divisible(int(filters * alpha), 8)
prefix = 'expanded_conv_{}_'.format(block_id)
x = inputs
# 利用1x1卷积根据输入进来的通道数进行通道数上升
if block_id:
x = Conv2D(expansion * in_channels, kernel_size=1, padding='same',
kernel_initializer=random_normal(stddev=0.02), use_bias=False, activation=None,
name=prefix + 'expand')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999,
name=prefix + 'expand_BN')(x)
x = Activation(relu6, name=prefix + 'expand_relu')(x)
else:
prefix = 'expanded_conv_'
# 利用深度可分离卷积进行特征提取
x = DepthwiseConv2D(kernel_size=3, strides=stride, activation=None,
depthwise_initializer=random_normal(stddev=0.02),
use_bias=False, padding='same', dilation_rate=(rate, rate),
name=prefix + 'depthwise')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999, name=prefix + 'depthwise_BN')(x)
x = Activation(relu6, name=prefix + 'depthwise_relu')(x)
# 利用1x1的卷积进行通道数的下降
x = Conv2D(point_wise_filters, kernel_initializer=random_normal(stddev=0.02),
kernel_size=1, padding='same', use_bias=False, activation=None,
name=prefix + 'project')(x)
x = BatchNormalization(epsilon=1e-3, momentum=0.999, name=prefix + 'project_BN')(x)
# 添加残差边
if skip_connection:
return Add(name=prefix + 'add')([inputs, x])
return x
def get_mobilenet_encoder():
inputs = Input(shape=inputs_size) # (None, 473, 473, 3)
alpha = 1.0
first_block_filters = _make_divisible(32 * alpha, 8) # 32
# 473,473,3 -> 237,237,32
x = Conv2D(first_block_filters, kernel_size=3, kernel_initializer=random_normal(stddev=0.02),
strides=(2, 2), padding='same', use_bias=False, name='Conv')(inputs) # (None, 237, 237, 32)
x = BatchNormalization(epsilon=1e-3, momentum=0.999, name='Conv_BN')(x) # (None, 237, 237, 32)
x = Activation(relu6, name='Conv_Relu6')(x) # (None, 237, 237, 32)
# 237,237,32 -> 237,237,16
x = _inverted_res_block(x, filters=16, alpha=alpha, stride=1,
expansion=1, block_id=0, skip_connection=False) # (None, 237, 237, 16)
# 237,237,16 -> 119,119,24
x = _inverted_res_block(x, filters=24, alpha=alpha, stride=2,
expansion=6, block_id=1, skip_connection=False) # (None, 119, 119, 24)
x = _inverted_res_block(x, filters=24, alpha=alpha, stride=1,
expansion=6, block_id=2, skip_connection=True) # (None, 119, 119, 24)
# 119,119,24 -> 60,60.32
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=2,
expansion=6, block_id=3, skip_connection=False) # (None, 60, 60, 32)
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=1,
expansion=6, block_id=4, skip_connection=True) # (None, 60, 60, 32)
x = _inverted_res_block(x, filters=32, alpha=alpha, stride=1,
expansion=6, block_id=5, skip_connection=True) # (None, 60, 60, 32)
# 60,60,32 -> 30,30.64
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=block4_stride,
expansion=6, block_id=6, skip_connection=False) # (None, 30, 30, 64)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=7, skip_connection=True) # (None, 30, 30, 64)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=8, skip_connection=True) # (None, 30, 30, 64)
x = _inverted_res_block(x, filters=64, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=9, skip_connection=True) # (None, 30, 30, 64)
# 30,30.64 -> 30,30.96
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=10, skip_connection=False) # (None, 30, 30, 96)
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=11, skip_connection=True) # (None, 30, 30, 96)
x = _inverted_res_block(x, filters=96, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=12, skip_connection=True) # (None, 30, 30, 96)
# 辅助分支训练
f4 = x
# 30,30.96 -> 30,30,160 -> 30,30,320
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1, rate=block4_dilation,
expansion=6, block_id=13, skip_connection=False) # (None, 30, 30, 160)
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=14, skip_connection=True) # (None, 30, 30, 160)
x = _inverted_res_block(x, filters=160, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=15, skip_connection=True) # (None, 30, 30, 160)
x = _inverted_res_block(x, filters=320, alpha=alpha, stride=1, rate=block5_dilation,
expansion=6, block_id=16, skip_connection=False) # (None, 30, 30, 320)
f5 = x
return inputs, f4, f5
psp_model:语义分割模型
import tensorflow as tf
import numpy as np
from keras.initializers import random_normal
from keras.layers import *
from keras.models import *
from keras import backend as K
from mobile_netv2 import get_mobilenet_encoder
n_classes = 20 + 1
def resize_images(args):
x = args[0]
y = args[1]
return tf.image.resize(x, (K.int_shape(y)[1], K.int_shape(y)[2]))
def pool_block(feats, pool_factor, out_channel):
h = K.int_shape(feats)[1] # 30
w = K.int_shape(feats)[2] # 30
# 分区域进行平均池化
# strides = [30,30], [15,15], [10,10], [5, 5]
# pool size = 30/1=30 30/2=15 30/3=10 30/6=5
pool_size = [int(np.round(float(h)/pool_factor)), int(np.round(float(w)/pool_factor))]
strides = pool_size
# [30,30] or [15,15] or [10,10] or [5, 5]
x = AveragePooling2D(pool_size, strides=strides, padding='same')(feats) # (None, 1, 1, 80)
# 利用1x1卷积进行通道数的调整
x = Conv2D(out_channel//4, (1, 1), kernel_initializer=random_normal(stddev=0.02),
padding='same', use_bias=False)(x) # (None, 1, 1, 80)
x = BatchNormalization()(x) # (None, 1, 1, 80)
x = Activation('relu')(x) # (None, 1, 1, 80)
# 利用resize扩大特征层面, 将(1, 1), (2, 2), (3, 3), (6, 6)上采样恢复到(30, 30)
x = Lambda(resize_images)([x, feats]) # (None, 30, 30, 80)
return x
def get_psp_model():
# 通过mobile_net特征提取, 获得两个特征层: f4为辅助分支 - (None, 30, 30, 96) ; o为主干部分 - (None, 30, 30, 320)
img_input, f4, o = get_mobilenet_encoder()
out_channel = 320
# PSP模块,分区域进行池化,将30*30的feature map,分别池化成1x1的区域,2x2的区域,3x3的区域,6x6的区域
# pool_outs列表 :
# [主干部分 - (None, 30, 30, 320),
# 由1*1扩展而成的 - (None, 30, 30, 80),
# 由2*2扩展而成的 - (None, 30, 30, 80),
# 由3*3扩展而成的 - (None, 30, 30, 80),
# 由6*6扩展而成的 - (None, 30, 30, 80)]
pool_factors = [1, 2, 3, 6]
pool_outs = [o]
for p in pool_factors:
pooled = pool_block(o, p, out_channel)
pool_outs.append(pooled)
# 将获取到的特征层进行堆叠
# (30, 30, 320) + (30, 30, 80) + (30, 30, 80) + (30, 30, 80) + (30, 30, 80) = (30, 30, 640)
o = Concatenate(axis=-1)(pool_outs)
# 30, 30, 640 -> 30, 30, 80
o = Conv2D(out_channel//4, (3, 3), kernel_initializer=random_normal(stddev=0.02),
padding='same', use_bias=False)(o) # (None, 30, 30, 80)
o = BatchNormalization()(o) # (None, 30, 30, 80)
o = Activation('relu')(o) # (None, 30, 30, 80)
# 防止过拟合
o = Dropout(0.1)(o) # (None, 30, 30, 80)
# 利用特征获得预测结果
# 30, 30, 80 -> 30, 30, 21 -> 473, 473, 21
o = Conv2D(n_classes, (1, 1), kernel_initializer=random_normal(stddev=0.02),
padding='same')(o) # (None, 30, 30, 21)
o = Lambda(resize_images)([o, img_input]) # (None, 473, 473, 21)
# 获得每一个像素点属于每一个类的概率
o = Activation("softmax", name="main")(o) # (None, 473, 473, 21)
model = Model(img_input, o)
return model
train:训练过程
import cv2
import os
import random
import numpy as np
from keras.utils import Sequence
import math
from psp_model import get_psp_model
from keras.optimizers import Adam
from keras.callbacks import ModelCheckpoint
from PIL import Image
import scipy.io
from keras import optimizers
class_dictionary = {0: 'background', 1: 'aeroplane', 2: 'bicycle', 3: 'bird', 4: 'boat',
5: 'bottle', 6: 'bus', 7: 'car', 8: 'cat', 9: 'chair',
10: 'cow', 11: 'dining_table', 12: 'dog', 13: 'horse', 14: 'motorbike',
15: 'person', 16: 'potted_plant', 17: 'sheep', 18: 'sofa', 19: 'train',
20: 'TV_monitor'}
inputs_size = (473, 473, 3)
n_classes = 20 + 1
class SequenceData(Sequence):
def __init__(self, data_x, data_y, batch_size):
self.batch_size = batch_size
self.data_x = data_x
self.data_y = data_y
self.indexes = np.arange(len(self.data_x))
def __len__(self):
return math.floor(len(self.data_x) / float(self.batch_size))
def on_epoch_end(self):
np.random.shuffle(self.indexes)
def __getitem__(self, idx):
batch_index = self.indexes[idx * self.batch_size:(idx + 1) * self.batch_size]
batch_x = [self.data_x[k] for k in batch_index]
batch_y = [self.data_y[k] for k in batch_index]
x = np.zeros((self.batch_size, inputs_size[1], inputs_size[0], 3))
y = np.zeros((self.batch_size, inputs_size[1], inputs_size[0], n_classes))
for i in range(self.batch_size):
img = cv2.imread(batch_x[i])
img1 = cv2.resize(img, (inputs_size[1], inputs_size[0]), interpolation=cv2.INTER_AREA)
img2 = img1 / 255
x[i, :, :, :] = img2
# 利用scipy.io.loadmat函数,label['GTcls'].Segmentation函数,得到语义分割标注信息
# 此时得到一个类别矩阵,像素位置上的数值用0-20记录,分别代表不同目标物体
label = scipy.io.loadmat(batch_y[i], mat_dtype=True, squeeze_me=True, struct_as_record=False)
label1 = label['GTcls'].Segmentation
label2 = cv2.resize(label1, (473, 473), interpolation=cv2.INTER_NEAREST)
label3 = np.eye(n_classes)[label2.reshape([-1])] # (223729, 21)
label4 = label3.reshape((inputs_size[1], inputs_size[0], n_classes)) # (473, 473, 21)
y[i, :, :, :] = label4
# 用来测试读取的label是否会出错的,demon记录该图像上所有类别的种类
# demon = []
# for i1 in range(label2.shape[0]):
# for j1 in range(label2.shape[1]):
# demon.append(label2[i1, j1])
# print(set(demon))
# cv2.namedWindow("Image")
# cv2.imshow("Image", img2)
# cv2.waitKey(0)
# cv2.namedWindow("seg1")
# cv2.imshow("seg1", label2/20)
# cv2.waitKey(0)
return x, y
def train_network(train_generator, validation_generator, epoch):
model = get_psp_model()
model.load_weights('download_weights.h5', by_name=True, skip_mismatch=True)
print('PSPNet网络层总数为:', len(model.layers)) # 175
freeze_layers = 146
for i in range(freeze_layers):
model.layers[i].trainable = False
print(model.layers[i].name)
adam = Adam(lr=1e-3)
log_dir = "Logs/1/"
checkpoint = ModelCheckpoint(log_dir + 'epoch{epoch:03d}_val_accuracy{val_accuracy:.5f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=False, period=1)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
model.fit_generator(
train_generator,
steps_per_epoch=len(train_generator),
epochs=epoch,
validation_data=validation_generator,
validation_steps=len(validation_generator),
callbacks=[checkpoint]
)
model.save_weights('first_weights.hdf5')
def load_network_then_train(train_generator, validation_generator, epoch, input_name, output_name):
model = get_psp_model()
model.load_weights(input_name)
print('PSPNet网络层总数为:', len(model.layers)) # 175
freeze_layers = 146
for i in range(freeze_layers):
model.layers[i].trainable = False
print(model.layers[i].name)
adam = Adam(lr=1e-4)
sgd = optimizers.SGD(lr=1e-4, momentum=0.9)
log_dir = "Logs/2/"
checkpoint = ModelCheckpoint(log_dir + 'epoch{epoch:03d}_val_accuracy{val_accuracy:.5f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=False, period=1)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model.fit_generator(
train_generator,
steps_per_epoch=len(train_generator),
epochs=epoch,
validation_data=validation_generator,
validation_steps=len(validation_generator),
callbacks=[checkpoint]
)
model.save_weights(output_name)
detect:检测结果
import numpy as np
import cv2
import os
from read_data_path import make_data
from psp_model import get_psp_model
from train import SequenceData
from train import train_network
from PIL import Image
import scipy.io
# 真实目标物体像素值的标记类别
class_dictionary = {0: 'background', 1: 'aeroplane', 2: 'bicycle', 3: 'bird', 4: 'boat',
5: 'bottle', 6: 'bus', 7: 'car', 8: 'cat', 9: 'chair',
10: 'cow', 11: 'dining_table', 12: 'dog', 13: 'horse', 14: 'motorbike',
15: 'person', 16: 'potted_plant', 17: 'sheep', 18: 'sofa', 19: 'train',
20: 'TV_monitor'}
inputs_size = (473, 473, 3)
# 语义分割结果的颜色表示空间
np.random.seed(1)
color_array = np.zeros((21, 3))
color_array[0, :] = np.array([255, 255, 0]) / 255 # 背景信息设置为天蓝色
# 20个目标物体的颜色表示随机设置
for row in range(1, 21):
r = np.random.random_integers(0, 255)
b = np.random.random_integers(0, 255)
g = np.random.random_integers(0, 255)
color_array[row, :] = np.array([r, b, g]) / 255
def detect_semantic(test_x, test_y):
psp_model = get_psp_model()
psp_model.load_weights('best_val_accuracy0.92490.h5')
# img : 原始rbg图像
# pre_semantic : 模型预测的图像语义分割结果
# true_semantic2 : 真实的语义分割标注信息
for i in range(100):
img = cv2.imread(test_x[i])
size = img.shape
img1 = cv2.resize(img, (inputs_size[1], inputs_size[0]), interpolation=cv2.INTER_AREA)
img2 = img1 / 255
img3 = img2[np.newaxis, :, :, :]
result1 = psp_model.predict(img3) # (1, 473, 473, 2)
result2 = result1[0]
result3 = cv2.resize(result2, (size[1], size[0]), interpolation=cv2.INTER_NEAREST)
mask = np.zeros((size[0], size[1]))
pre_semantic = np.zeros((size[0], size[1], 3))
for j in range(size[0]):
for k in range(size[1]):
index = np.argmax(result3[j, k, :])
mask[j, k] = index
pre_semantic[j, k, :] = color_array[index, :]
# 利用scipy.io.loadmat函数,label['GTcls'].Segmentation函数,得到语义分割标注信息
# 此时得到一个类别矩阵,像素位置上的数值用0-20记录,分别代表不同目标物体
true_semantic = scipy.io.loadmat(test_y[i], mat_dtype=True, squeeze_me=True, struct_as_record=False)
true_semantic1 = true_semantic['GTcls'].Segmentation
true_semantic2 = np.zeros((size[0], size[1], 3))
for j in range(size[0]):
for k in range(size[1]):
index = int(true_semantic1[j, k])
true_semantic2[j, k, :] = color_array[index, :]
# cv2.namedWindow("img")
# cv2.imshow("img", img)
# cv2.waitKey(0)
#
# cv2.namedWindow("true_semantic")
# cv2.imshow("true_semantic", true_semantic2)
# cv2.waitKey(0)
#
# cv2.namedWindow("pre_semantic")
# cv2.imshow("pre_semantic", pre_semantic)
# cv2.waitKey(0)
cv2.imwrite("demo/" + str(i) + '_img' + '.jpg', img/1.0)
cv2.imwrite("demo/" + str(i) + '_true_semantic' + '.jpg', true_semantic2*255)
cv2.imwrite("demo/" + str(i) + '_pre_semantic' + '.jpg', pre_semantic*255)
六、项目链接
如果代码跑不通,或者想直接使用我自己制作的数据集,可以去下载项目链接:
https://blog.csdn.net/Twilight737