DAB-DETR:Dynamic Anchor Boxes Are Better Queries for DETR阅读笔记
DAB-DETR阅读笔记
-
- (一) Title
- (二) Summary
- (三) Problem Statement
- (四) Method
-
- 4.1 为什么位置先验能够加速训练?
- 4.2 本文的主要工作
-
- 4.2.1 直接学习anchor boxes
- 4.2.2 Anchor Update
- 4.2.3 Width & Height调制高斯核
- 4.2.4 温度系数的调整
- (五) Experiments
- (六) Conclusion
- (七) Notes
(一) Title

论文:https://arxiv.org/abs/2201.12329
代码:https://github.com/SlongLiu/DAB-DETR
(二) Summary
本文方法
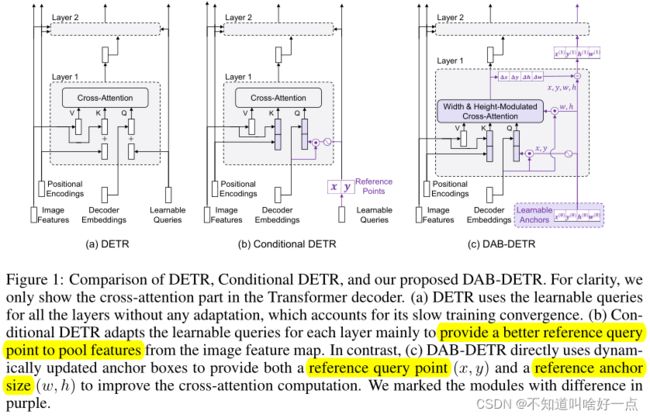
提出了一种使用dynamic anchor boxes的query formulation for DETR,直接将box coordinates作为Transformer解码器的queries,并且逐层更新.这种做法的优势在于:
- 可以利用显式的位置先验(explicit positional priors),改善query-to-feature的相似性并且能够消除DETR中收敛慢的问题
- 允许我们modulate the positional attention map 使用边界框的长和宽信息
这种方式好像是在采用一个逐层的soft ROI pooling的方式不断调整queries
性能表现
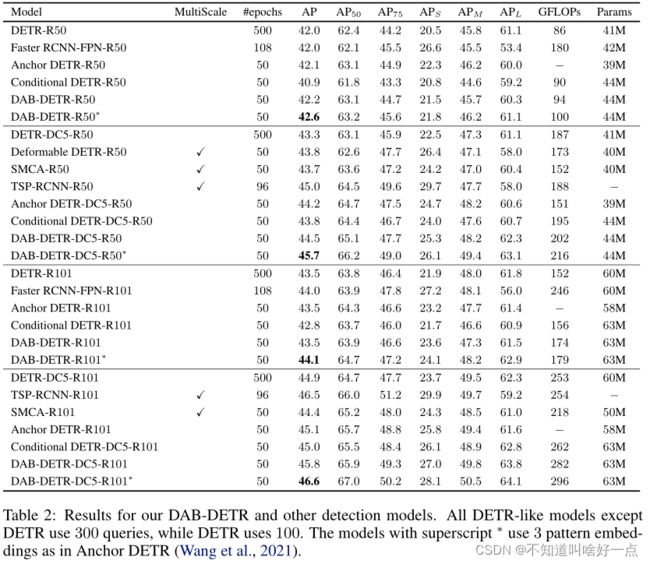
在DETR-like检测模型中基于相同的设置,取得了COCO数据集上的最佳性能表现,使用ResNet50-DC5作为骨干网络训练了50个epoch达到了45.7%的AP
(三) Problem Statement
DETR的出现,将目标检测问题看成是set prediction,不需要使用非极大值抑制进行边界框的筛选,然而DETR中存在着收敛缓慢的问题,需要训练500个epoch才能够得到较好的性能表现.
现有的很多研究都针对DETR queries的设计来进行改进从而实现更快的训练收敛速度以及更佳的性能表现.不过大多数的尝试都在将DETR中的每一个query同一个特定的空间位置相关联,并且在technical solutions上是有很大不同的:
- Conditional DETR学习了一个conditional spatial query通过采用一个基于content feature的query来实现对图像特征更好的匹配。
- Efficient DETR引入了一个dense prediction module来选择top-K个object queries
- Anchor DETR中将queries形式化成2D的anchor points,同时将每一个query同一个特定的空间位置进行关联
- Deformable DETR中直接将2D参考点看成queries,在每一个参考点间进行deformable cross-attention
从上面的工作中,其实可以看出仅仅利用的2D的空间点作为anchor points,并没有考虑目标的scales.
为了在query中引入scale信息,在Transformer Decoder的cross-attention中,提出使用一个4维的边界框坐标 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)作为DETR的queries,然后再进行逐层的更新,通过每一个anchor box的位置以及尺度信息来为cross-attention提供更好的空间先验。
实际上DETR中的每一个query包括两部分:content part(decorder self-attention ouput)以及positional part(learnable queries in DETR),对应到代码上的表现为:
首先是transformer的forward函数def forward(self, src, mask, query_embed, pos_embed): # flatten NxCxHxW to HWxNxC bs, c, h, w = src.shape src = src.flatten(2).permute(2, 0, 1) pos_embed = pos_embed.flatten(2).permute(2, 0, 1) query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1) mask = mask.flatten(1) tgt = torch.zeros_like(query_embed) memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed) hs = self.decoder(tgt, memory, memory_key_padding_mask=mask, pos=pos_embed, query_pos=query_embed) return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)这里decoder的输入
tgt是跟query_embed同维度的零向量memory是Transformer编码器的输出,query_embed是nn.Embedding(num_queries, hidden_dim).weight.unsqueeze(1).repeat(1, batch_size, 1)得到的mask是骨干网络输出最后一个level的特征图进行decompose,即src, mask = features[-1].decompose()pos_embed是骨干网络中对于输出特征图的positional embedding在Decoder layer的forward函数中,观察cross-attention对应的multihead_attn
def forward_post(self, tgt, memory, tgt_mask: Optional[Tensor] = None, memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None, pos: Optional[Tensor] = None, query_pos: Optional[Tensor] = None): q = k = self.with_pos_embed(tgt, query_pos) tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask, key_padding_mask=tgt_key_padding_mask)[0] tgt = tgt + self.dropout1(tgt2) tgt = self.norm1(tgt) tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos), key=self.with_pos_embed(memory, pos), value=memory, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0] tgt = tgt + self.dropout2(tgt2) tgt = self.norm2(tgt) tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt)))) tgt = tgt + self.dropout3(tgt2) tgt = self.norm3(tgt) return tgt从交叉注意力中我们可以看到query由两部分组成,一个是
tgt,这个是来自self-atten的输出,另一个是query_pos,是nn.Embedding(num_queries, hidden_dim).weight.unsqueeze(1).repeat(1, batch_size, 1)得到的,而DETR中with_pos_embed采取的是将tgt和query_pos相加的方式得到cross-atten的query输入的。因此这里的tgt和query_pos分别对应着本文所说的content part以及positional part(注:上述代码来源于DETR)
而在本文中接着进一步指出cross-attention中keys也是由两部分组成的,即content part(编码后的图像特征)以及positional part(positional embedding),从代码中我们可以看出key=self.with_pos_embed(memory, pos),其中memory是Transformer编码器的输出,pos表示骨干网络中对于输出特征图的positional embedding。
因此,在Transformer解码器中,queries能够被解释为基于queries-to-feature的相似性度量,从特征图上获取到能够同query匹配上的features,同时考虑了content信息以及positional信息,content similarity从特征中获取到相关的语义信息,positional similarity在query position附近提供位置约束。博主自己的一些看法是query中包含的content部分是零向量,而positional部分是embedding向量,在保存的checkpoint中,就是可学习的变量,说实话,感觉真离谱啊,明明什么都没有告诉query,它却能够通过梯度反向传播学习到自己想要的是什么,然后从特征信息中获取对应的特征。对于key来说则是将特征信息同特征信息对应的位置编码加和起来
考虑到不给query任何提示,学习的效率太差,就跟没有指导一样,学习起来事倍功半,query表示我有精力但是进展落后太多,因此,本文中就用anchor box的center position ( x , y ) (x,y) (x,y)来pool feature,然后使用anchor box的size ( w , h ) (w,h) (w,h)来调整cross-attention map,将中心点坐标用于queries,能够逐层进行更新。完整的框图如下所示
(四) Method
4.1 为什么位置先验能够加速训练?
这里只是深入分析了一下为了引入位置先验能够加速收敛的原因,读了几遍,还是觉得写得不是理解。
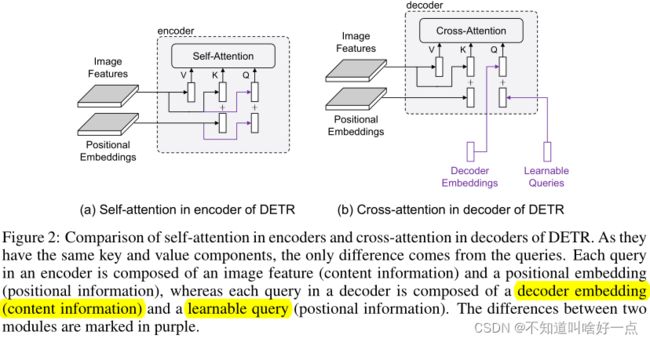
首先比较DETR中encoder的self-attention同decoder中的cross-attention在结构上的差异。
从表中可以看到,self-attention同cross-attention之间的差异主要是在queries上,在encoder中queries同key是完全相同的,在decoder中queries是由decoder中self-attention的输出以及可学习的query构成.
在本文中,实际上分析了cross-attention中哪个子模块会影响模型的收敛,这里的思考是来自于decoder中的cross-attention同encoder中的self-attention的比较,在decoder中最初的输入是被初始化成0的(注:博主觉得论文中的描述存在一些问题),这里最初的输入指的是decoder中self-attention的输入,实际上decoder embeddings同key的注意力计算相当于将decoder embedding投影到key所在的空间,得到key上每一个维度的分量,然后再下一层的decorder中self-attention计算同encorder中的计算方式是相同的.这里key的组成并没有什么问题。主要是queries中没有任何先验,而实际上不同的query应该关注特定的目标
cross-attention中收敛慢的两个原因是:
- it is hard to learn the queries due to the optimization challenge
- the positional information in the learned queries is not encoded in the same way as the sinusoidal positional encoding used for image features.
这里指出的第一个问题指的是可学习方式引入的queries,通过梯度反向传播进行学习的过程非常缓慢,如果说将这个可学习的queries换成一个比较好的queries,也就是即使我采用了一个学习的比较好的queries,对应的收敛性能也并没有改善.
博主觉得这里即使说我先对learnable queries进行学习,也无法帮助我获得更快的收敛速度
接着针对第二个问题,实际上learnabe queries用于从特定的区域中来filter objects,将图像特征positional embedding同learnable queries之间的attention map进行可视化(这里可视化的结果是query和key中的positional part吗,根据理解应该是这样的)的结果如下所示:
图中每一个query被看成是一个位置先验来让decoder关注到感兴趣的区域上,图(a)中query能够作为位置约束,不过他们不好,原因在于query能对应多个模式(一个query看到多个attention高的地方),并且在注意力权重上的差异不大。造成了无法将有用的位置信息引入到特征提取阶段,收敛慢。在本文中是通过将query形式化成dynamic anchor boxes,使其关注到特定的区域,同(b)中不同的是在DAB-DETR中还引入了尺度信息来调整注意力权重。

4.2 本文的主要工作
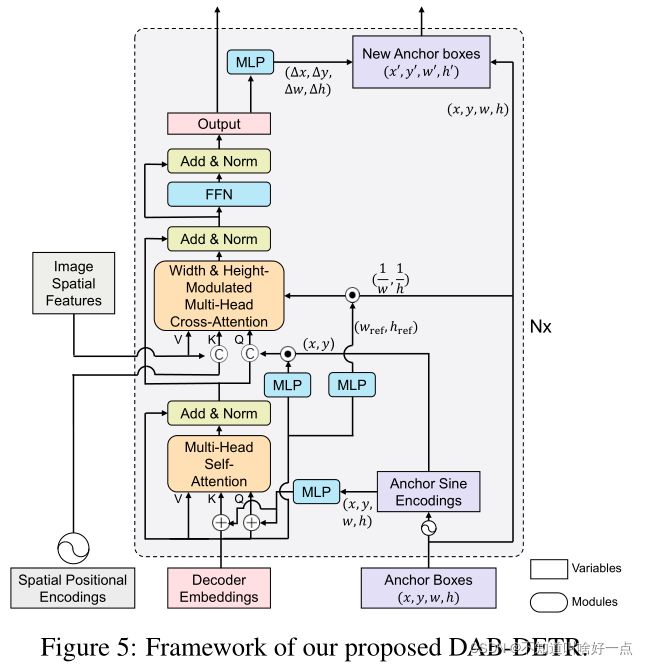
模型的整体框架包括CNN骨干网络、Transformer encoders和Transformer decoders以及prediction heads,其中解码器如上图所示。
主要流程:经过CNN提取图像空间特征,然后经过Transformer encoders中进一步refine 特征,接着dual queries,包括positional queries(anchor boxes)以及content queries(decoder embeddings),被fed到decoder中提取同anchor对应的特征,然后dual queries通过decoder layer逐层更新,最终预测目标的label以及边界框信息,通过bipartite matching实现loss的计算。
4.2.1 直接学习anchor boxes
从anchors中derive positional queries,那么这里的anchors是从哪来的呢?
在decoder中存在着两种类型的注意力模块,包括self-attention以及cross-attention,分别用来进行query updating以及feature probing,并且在每一个模块中都需要query,key以及value。
整个decoder的计算流程是:
- 首先第 q q q个anchor记作 A q = ( x q , y q , w q , h q ) A_q=(x_q,y_q,w_q,h_q) Aq=(xq,yq,wq,hq),并且 x q , y q , w q , h q ∈ R x_q,y_q,w_q,h_q\in \mathbb{R} xq,yq,wq,hq∈R, C q ∈ R D C_q \in \mathbb{R}^D Cq∈RD, P q ∈ R D P_q \in \mathbb{R}^D Pq∈RD分别对应content query[图中的Decoder Embeddings]以及positional query[图中的Anchor Boxes经过Anchor Sine Encodings以及MLP之后得到的向量], D D D表示解码器embeddings以及positional queries对应的维度。
- positional query P q P_q Pq是利用MLP生成的
P q = MLP ( PE ( A q ) ) P_{q}=\operatorname{MLP}\left(\operatorname{PE}\left(A_{q}\right)\right) Pq=MLP(PE(Aq))
PE表示对于浮点数的正弦位置编码,需要注意的是MLP的参数是在所有的解码器层之间进行共享的, A q A_q Aq是一个四元组, PE ( A q ) \operatorname{PE}\left(A_{q}\right) PE(Aq)的过程如下所示:
PE ( A q ) = PE ( x q , y q , w q , h q ) = Cat ( PE ( x q ) , PE ( y q ) , PE ( w q ) , PE ( h q ) ) \operatorname{PE}\left(A_{q}\right)=\operatorname{PE}\left(x_{q}, y_{q}, w_{q}, h_{q}\right)=\operatorname{Cat}\left(\operatorname{PE}\left(x_{q}\right), \operatorname{PE}\left(y_{q}\right), \operatorname{PE}\left(w_{q}\right), \operatorname{PE}\left(h_{q}\right)\right) PE(Aq)=PE(xq,yq,wq,hq)=Cat(PE(xq),PE(yq),PE(wq),PE(hq))
其中 PE \operatorname{PE} PE是将一个浮点数映射到 D / 2 D/2 D/2维的向量上,即 P E : R → R D / 2 \mathrm{PE}: \mathbb{R} \rightarrow \mathbb{R}^{D / 2} PE:R→RD/2,接着通过 MLP \operatorname{MLP} MLP将 2 D 2D 2D维度的特征向量映射到 D D D维度上,即 M L P : R 2 D → R D \mathrm{MLP}: \mathbb{R}^{2D} \rightarrow \mathbb{R}^{D} MLP:R2D→RD,其中MLP包含两个子模块,每一个子模块都是由一个linear层以及一个ReLU函数构建,在第一个子模块的linear层将特征进行了reduction。- self-attention模块,queries为content queries和positional query之和,keys同queries相同,value为content queries.
Self-Attn: Q q = C q + P q , K q = C q + P q , V q = C q \text { Self-Attn: } \quad Q_{q}=C_{q}+P_{q}, \quad K_{q}=C_{q}+P_{q}, \quad V_{q}=C_{q} Self-Attn: Qq=Cq+Pq,Kq=Cq+Pq,Vq=Cq- cross-attention模块,同Coditional DETR相同,都是将position和content queries进行cat,从而实现content query同positional query的decouple.
为了rescale positional embeddings,利用conditional spatial query,即通过 MLP ( csq ) : R D → R D \operatorname{MLP}^{(\operatorname{csq})}: \mathbb{R}^{D} \rightarrow \mathbb{R}^{D} MLP(csq):RD→RD从content information章获取到scale vector conditional,然后同 PE ( x q , y q ) \operatorname{PE}\left(x_{q}, y_{q}\right) PE(xq,yq)做element-wise乘法,这样做有什么优势嘛?是怎么想到这样做的
Cross-Attn: Q q = Cat ( C q , PE ( x q , y q ) ⋅ MLP ( c s q ) ( C q ) ) K x , y = Cat ( F x , y , PE ( x , y ) ) , V x , y = F x , y \begin{array}{ll} \text { Cross-Attn: } & Q_{q}=\operatorname{Cat}\left(C_{q}, \operatorname{PE}\left(x_{q}, y_{q}\right) \cdot \operatorname{MLP}^{(\mathrm{csq})}\left(C_{q}\right)\right) \\ & K_{x, y}=\operatorname{Cat}\left(F_{x, y}, \operatorname{PE}(x, y)\right), \quad V_{x, y}=F_{x, y} \end{array} Cross-Attn: Qq=Cat(Cq,PE(xq,yq)⋅MLP(csq)(Cq))Kx,y=Cat(Fx,y,PE(x,y)),Vx,y=Fx,y
式中 F x , y ∈ R D F_{x, y} \in \mathbb{R}^{D} Fx,y∈RD是在 ( x , y ) (x,y) (x,y)位置的特征, ⋅ \cdot ⋅是element-wise乘法,queries和keys中的positional embeddings是通过2D坐标经位置编码生成的。
4.2.2 Anchor Update
在DAB-DETR中,通过每一层的decoder中prediction head预测的relative positions ( Δ x , Δ y , Δ w , Δ h ) (\Delta x,\Delta y,\Delta w,\Delta h) (Δx,Δy,Δw,Δh)来进一步更新anchor boxes.需要注意的是这里所有的prediction heads共享参数
4.2.3 Width & Height调制高斯核
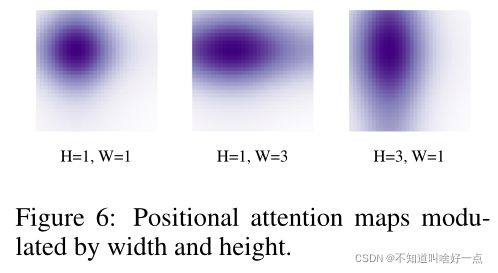
在之前的做法中,不考虑边界框的尺度信息,引入的先验还不够准确,这里将scale信息引入到attention map上。这个尺度先验是引入到cross-attention中的.
原始的positional attention map通过计算keys中的坐标编码,以及queries中的坐标编码的点积得到的,如下所示:
Attn ( ( x , y ) , ( x r e f , y r e f ) ) = ( P E ( x ) ⋅ P E ( x r e f ) + P E ( y ) ⋅ P E ( y r e f ) ) / D \operatorname{Attn}\left((x, y),\left(x_{\mathrm{ref}}, y_{\mathrm{ref}}\right)\right)=\left(\mathrm{PE}(x) \cdot \mathrm{PE}\left(x_{\mathrm{ref}}\right)+\mathrm{PE}(y) \cdot \mathrm{PE}\left(y_{\mathrm{ref}}\right)\right) / \sqrt{D} Attn((x,y),(xref,yref))=(PE(x)⋅PE(xref)+PE(y)⋅PE(yref))/D
其中 D \sqrt{D} D同注意力机制中一样,用来rescale value,保证均值和方差,在这里本文的做法是对positional attention maps通过除以anchor的width和height来进行调整,如下所示:
ModulateAttn ( ( x , y ) , ( x r e f , y r e f ) ) = ( P E ( x ) ⋅ P E ( x r e f ) w q , r e f w q + P E ( y ) ⋅ P E ( y r e f ) h q , r e f h q ) / D \text { ModulateAttn }\left((x, y),\left(x_{\mathrm{ref}}, y_{\mathrm{ref}}\right)\right)=\left(\mathrm{PE}(x) \cdot \mathrm{PE}\left(x_{\mathrm{ref}}\right) \frac{w_{q, \mathrm{ref}}}{w_{q}}+\mathrm{PE}(y) \cdot \mathrm{PE}\left(y_{\mathrm{ref}}\right) \frac{h_{q, \mathrm{ref}}}{h_{q}}\right) / \sqrt{D} ModulateAttn ((x,y),(xref,yref))=(PE(x)⋅PE(xref)wqwq,ref+PE(y)⋅PE(yref)hqhq,ref)/D
式中 w q w_q wq和 h q h_q hq表示anchor A q A_q Aq的宽和高, w q , r e f w_{q,ref} wq,ref和 h q , r e f h_{q,ref} hq,ref是通过content queries C q C_q Cq计算出来的宽和高:
w q , ref , h q , ref = σ ( MLP ( C q ) ) w_{q, \text { ref }}, h_{q, \text { ref }}=\sigma\left(\operatorname{MLP}\left(C_{q}\right)\right) wq, ref ,hq, ref =σ(MLP(Cq))
这种调整positional attention的方式,能够帮助我们提取到具有不同宽和高的特征。
4.2.4 温度系数的调整
对于position encoding,使用正弦函数,定义形式如下:
P E ( x ) 2 i = sin ( x T 2 i / D ) , PE ( x ) 2 i + 1 = cos ( x T 2 i / D ) \mathrm{PE}(x)_{2 i}=\sin \left(\frac{x}{T^{2 i / D}}\right), \quad \operatorname{PE}(x)_{2 i+1}=\cos \left(\frac{x}{T^{2 i / D}}\right) PE(x)2i=sin(T2i/Dx),PE(x)2i+1=cos(T2i/Dx)
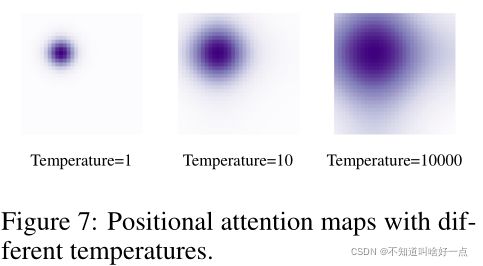
其中 T T T是手工设计的温度系数。上标 2 i 2i 2i以及 2 i + 1 2i+1 2i+1表示encoded向量的索引,温度系数影响positional priors的大小,如下图所示:
T T T越大,注意力图越flatten,其中 x x x表示从0到1之间的浮点数,用来表示边界框坐标,视觉任务相对于自然语言处理任务非常需要不同的温度系数,本文中设置 T = 20 T=20 T=20
(五) Experiments
- 使用ImageNet-pretrained ResNet作为我们的骨干网络,同时使用6个encoders以及6个decoders,骨干网络同先前工作中的相同,用于比较,
- 用于边界框以及label预测的MLP网络在decoder不同层之间进行参数共享。
- 受Anchor DETR启发,我们利用multiple pattern embeddings 来perform multiple predictions at one position,并且将模式设置成3,同Anchor DETR相同等开源了需要把这部分的内容补上
- 最后使用PReLU作为激活函数。
- 数据集采用COCO train2017训练,val2017用于评估。
同DETR-like模型的比较
消融实验
本文引入的各个改进的作用

(六) Conclusion
本文提出使用一种新的query形式化方式,采用dynamic anchor boxes来表示query,通过引入的更好地位置先验以及温度系数,能够适应不同尺度的目标,通过逐层迭代anchor boxes来逐步优化anchor boxes的估计结果,以级联方式执行soft ROI.
(七) Notes
- 将DETR中的每一个query更加显式地关联到specific spatial position,而不是multiple positions,也就是说某一个位置的query应当负责预测特定位置的目标,
- 改善DETR收敛慢的工作大致可以分成两类:对cross-attention计算方式的调整,对queries角色的理解
DETR收敛慢的原因可能是解码器中的cross-attention,因此有研究者提出使用一个encoder-only 模型
为了改进queries的理解,将其同特征的空间位置结合起来,比如Deformable DETR中的reference points,对queries进行调整。- 本文的DAB-DETR同之前的工作的区别是什么呢?
