SSD 超详细入门(代码+原文)
文章目录
- 前言
- 背景及总览
-
- 1.SSD:惊人的速度
- 2. Faster RCNN(Two stage)VS SSD(One-stage)
- 3.SSD的改进及效果:
- 一、网络架构组成
-
- 1.1 组成
- 1.2 预测
- 1.3 Multilayer
- 1.4 架构代码
- 1.5 各层输出
- 二、SSD的创新细节
-
- 2.1 Multi-scale feature maps for detection(多尺度特征图用于检测)
- 2.2 MultiBox
-
- 概念
- 组成
- 输出
- ❓为什么要有不同的横纵比?
- Anchor 计算
-
- Anchor box number
- Anchor size
- MultiBoxLayer代码
- Default box代码
- 2.3 Dilation
- 三、SSD的训练
-
- 3.1 Loss function及代码
-
- ❓为什么要用SmoothL1Loss?
- Smooth1Loss代码
- 3.2 先验框匹配
- 3.3 Hard negative mining(硬负挖掘)
-
- ❓为什么需要保留负样本?
- 3.3 Data augmentation(数据增强)
- 四、结果
- 4.1 Inference time(推测时间)
-
- NMS(非极大值抑制)
- 4.2 mAP及速度表现
- 五、总结
前言
代码地址:Github:amdegroot/ssd.pytorch
我在入门学习计算机视觉的适合,看一些经典的论文原文比较吃力。于是通过看各种参考文献及查阅各路资料,入门的角度写了一些博客,希望能够和大家一起进步。
如果你对同为one-stage算法的YOLO比较感兴趣,可以参考:
- 《YOLO 超详细入门(含开源代码)——网络结构、细节、目标损失函数、优点》
笔者在阅读《SSD: Single Shot MultiBox Detector》原文后,根据自身理解及查阅资料,以入门角度尽可能想要还原论文细节,水平有限,欢迎交流。
背景及总览
1.SSD:惊人的速度
SSD: Single Shot MultiBox Detector(by C. Szegedy et al.) 的论文于 2016 年 11 月下旬发布,在目标检测任务的性能和精度方面创下新纪录,得分超过 74% mAP(平均 平均精度) ) 在PascalVOC和COCO等标准数据集上以每秒 59 帧的速度运行。
若对指标评价有一些问题,可参考:《目标检测基础(TP,recall,PR曲线,mAP,NMS)》
SSD 专为实时目标检测(Real-Time)而设计。Faster R-CNN 使用区域提议网络(Region Proposal Network)来创建边界框并利用这些框对对象进行分类。
若想了解Faster RCNN,可参考《Faster RCNN超详细入门 02网络细节与训练方法 (anchors,RPN,bbox,bounding box,Region proposal layer……)》
2. Faster RCNN(Two stage)VS SSD(One-stage)
虽然Faster RCNN(two-stage)被认为是当时最先进且准确性最高的网络,但整个过程以每秒 7 帧的速度运行,这个速度远低于实时处理的需求(我们的视频每秒都至少有24帧)。one-stage(SSD)训练方法准确度不如two-stage(Faster RCNN),且训练不均衡,但速度较快。
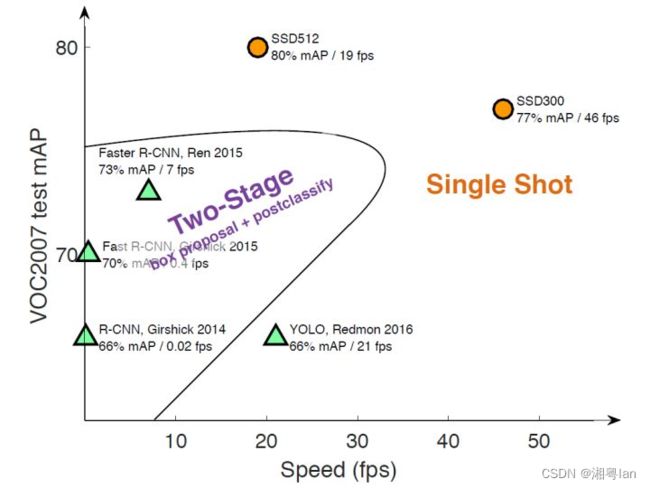
3.SSD的改进及效果:
SSD 通过消除对区域提议网络(Region Proposal Network)来加速运行速度。而这导致了部分精度的下降。为了提高精度,SSD 采用了一些方法进行改进,包括多尺度特征(multi-scale features)和默认框(default boxes)。这些改进使得SSD 能够仅仅使用较低分辨率的图像,也能达到足以媲美 Faster R-CNN 的准确度,而这进一步推高了速度。根据下面的比较,我们可以看到SSD具有实时处理的能力及速度,而且在准确率方面,甚至超过了 Faster R-CNN 。(准确率指标为mean average mAP:即预测的精度。)
一、网络架构组成
1.1 组成
SSD目标检测分为两个部分:
- 提取feature map。
- 应用conv layers来检测目标。
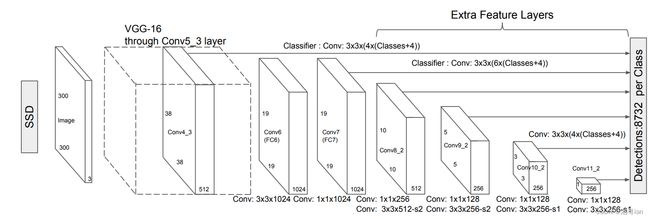
SSD架构首先会先经过VGG16的神经网路, 接着加上一层layer norm 与 一些convolution 来帮助加深网路,但舍弃了全连接层,添加了辅助卷积层(从conv6开始),从而能够从多个尺度上提取特征并逐渐减小每个后续层的输入大小,即放缩尺寸。(因为VGG-16在高质量图像分类任务中的强大性能以及它能够在迁移学习中改善结果,所以被经常用作基础网络。)

1.2 预测
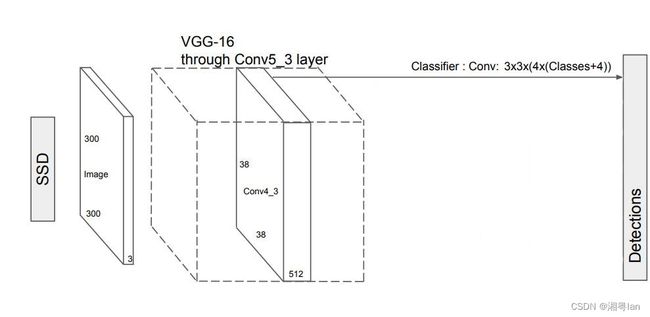
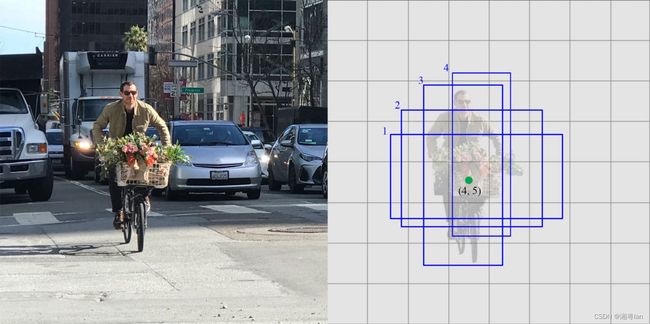
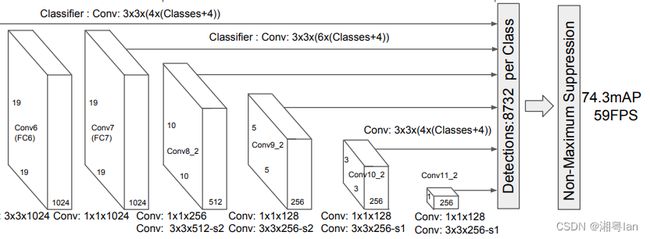
SSD 使用VGG16提取特征图,然后用Conv4_3层检测目标。为了说明,我们将 Conv4_3 在空间上绘制为 8 × 8(原本是 38 × 38)。对于每个单元格grid,它预测了4个目标对象。
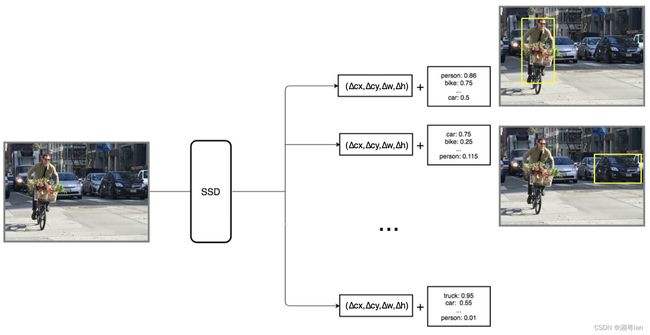
每个预测目标由一个bounding box(边界框)和每个类的 21 个分数组成(20个类 + 1个null即没有类或者说为背景类,共21个分数),我们选择最高分数所在类作为有界对象的类。Conv4_3 总共进行 38 × 38 × 4 次预测:38 x 38 个单元格,无论特征图的深度,每个单元格都要进行 4 次预测。因为许多预测不包含任何目标对象,所以 SSD 保留了一个“0”类,表示它没有对象。
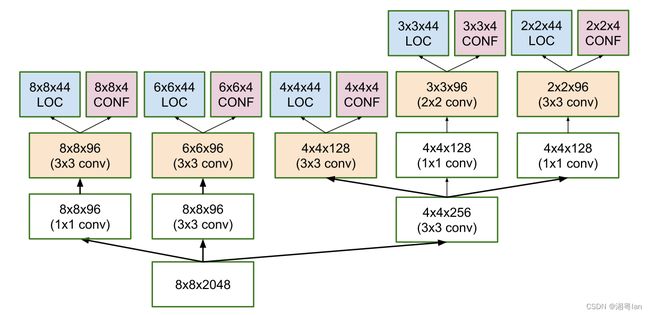
1.3 Multilayer
最后要进行输出时, 我们并不会只取最后的输出, 而是会将在几层卷积层的输出合并起来, 一起来输出, 这样越前面的卷积层对小目标的信息掌握度也越高, 越后面的卷积层也可以掌握大目标的信息, 相当于做了一次特征融合。 YOLOv2中为了解决对小目标的检测效果不佳的问题,采取了类似的方法,图片如下:
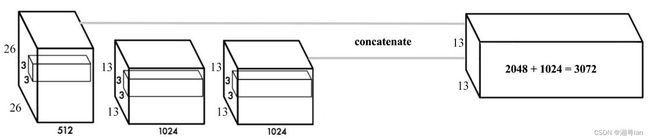
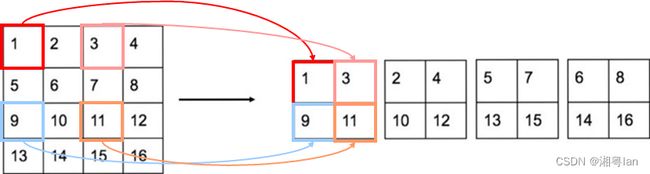
YOLOv2将 26 × 26 × 512 层使用按行列隔行采样的方法,抽取 2x2 的局部区域,然后将其转化为 channel 维度,便可以巧妙地reshape为 13 × 13 × 2048。然后与原始的 13 × 13 ×1024 输出层连接。现在我们在新的 13 × 13 × 3072 层上应用卷积滤波器来进行预测,相当于做了一次特征融合,有利于检测小的目标。
而SSD是分别将 l2norm, conv7, conv8_2, conv9_2, conv10_2, conv11_2 的输出一起收集起来输入到multilayer当中。
1.4 架构代码
class SSD300(nn.Module):
input_size = 300
def __init__(self):
super(SSD300, self).__init__()
# model
self.base = self.VGG16()
self.norm4 = L2Norm(512, 20) # 38
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, padding=1, dilation=1)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1, dilation=1)
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1, dilation=1)
self.conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
self.conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
self.conv8_1 = nn.Conv2d(1024, 256, kernel_size=1)
self.conv8_2 = nn.Conv2d(256, 512, kernel_size=3, padding=1, stride=2)
self.conv9_1 = nn.Conv2d(512, 128, kernel_size=1)
self.conv9_2 = nn.Conv2d(128, 256, kernel_size=3, padding=1, stride=2)
self.conv10_1 = nn.Conv2d(256, 128, kernel_size=1)
self.conv10_2 = nn.Conv2d(128, 256, kernel_size=3)
self.conv11_1 = nn.Conv2d(256, 128, kernel_size=1)
self.conv11_2 = nn.Conv2d(128, 256, kernel_size=3)
# multibox layer(第二章节会讲)
self.multibox = MultiBoxLayer()
def forward(self, x):
hs = []
h = self.base(x)
hs.append(self.norm4(h)) # conv4_3
h = F.max_pool2d(h, kernel_size=2, stride=2, ceil_mode=True)
h = F.relu(self.conv5_1(h))
h = F.relu(self.conv5_2(h))
h = F.relu(self.conv5_3(h))
h = F.max_pool2d(h, kernel_size=3, padding=1, stride=1, ceil_mode=True)
h = F.relu(self.conv6(h))
h = F.relu(self.conv7(h))
hs.append(h) # conv7
h = F.relu(self.conv8_1(h))
h = F.relu(self.conv8_2(h))
hs.append(h) # conv8_2
h = F.relu(self.conv9_1(h))
h = F.relu(self.conv9_2(h))
hs.append(h) # conv9_2
h = F.relu(self.conv10_1(h))
h = F.relu(self.conv10_2(h))
hs.append(h) # conv10_2
h = F.relu(self.conv11_1(h))
h = F.relu(self.conv11_2(h))
hs.append(h) # conv11_2
loc_preds, conf_preds = self.multibox(hs)
return loc_preds, conf_preds
(其中涉及的mutibox我们接下来会讲)我们可以看到在inference的时候有一个 hs 的list, 会将所有的output收集起来并且一起输入到multibox取得location prediction, confidence prediction。
1.5 各层输出
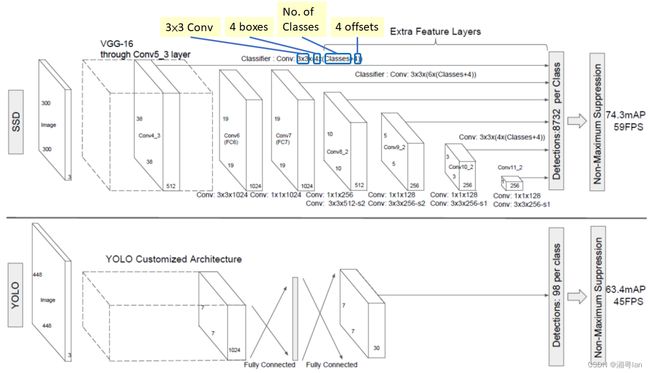
为了进行更准确的检测,不同层的特征图也通过一个小的 3×3 卷积进行目标检测,如上所示。
- 例如,在 Conv4_3,它的大小为 38×38×512。应用了 3×3 转换。并且有4 个边界框,每个边界框都有 (classes + 4) 个输出。因此,在 Conv4_3 处,输出为 38×38×4×( c +4)。假设有 20 个对象类加上 1 个背景类,输出为 38×38×4×(21+4) = 144,400。就边界框的数量而言,有 38×38×4 = 5776 个边界框。
- Conv7:19×19×6 = 2166 个框(每个位置 6 个框)
- Conv8_2:10×10×6 = 600 个框(每个位置 6 个框)
- Conv9_2:5×5×6 = 150 个框(每个位置 6 个框)
- Conv10_2:3×3×4 = 36 个框(每个位置 4 个框)
- Conv11_2:1×1×4 = 4 个框(每个位置 4 个框)
YOLO最后为 7×7个位置 ,每个位置有 2 个边界框,因此YOLO 只得到了 7×7×2 = 98 个box。而SSD 有 8732 个边界框,比 YOLO 的多得多。
二、SSD的创新细节
2.1 Multi-scale feature maps for detection(多尺度特征图用于检测)

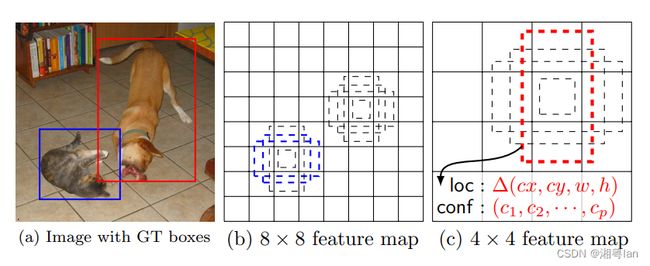
SSD使用多层(多尺度特征图)来独立检测目标。我们知道 CNN 可以逐渐降低空间的维度,特征图的分辨率也随之降低。SSD 使用较低分辨率的层(即比较小的层)来检测大规模的目标;使用较高分辨率的层(即比较大的层)来检测小规模的目标。例如,8 x 8 特征图用于检测小目标,4 × 4 特征图用于检测大目标。
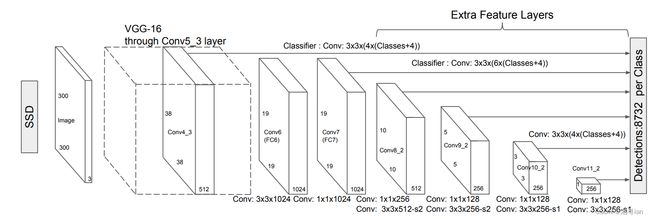
SSD 在 VGG16 之后又增加了 6 个辅助卷积层。其中五个将被添加用于对象检测。在其中的三个层中,我们进行了 6 个预测而不是 4 个。SSD 总共使用 6 个层进行了 8732 个预测。
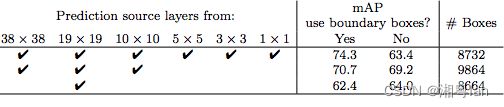
不出所料,多尺度特征图显著提高了准确度。上图是用于目标检测的,不同数量的特征图层的精度。
2.2 MultiBox
概念
MultiBox是一种快速的边界框坐标预测方法,且与类别无关。在 MultiBox 中使用了 Inception风格的卷积网络。
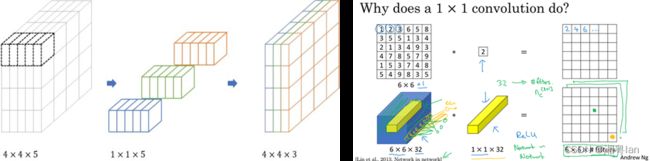
其中 1x1 卷积有助于降维,因为维数会减少(但“宽度”和“高度”将保持不变)。
组成
每个单元grid得每个先验框default box,其都输出一套独立的检测值,对于一个bouding box,主要分为两个部分:
-
各类别的置信度或者评分
- 21 个分数(20个类 + 1个null即背景类,共21个分数),我们选择最高分数所在类作为有界对象的类。Conv4_3 总共进行 38 × 38 × 4 次预测:38 x 38 个单元格,无论特征图的深度,每个单元格都要进行 4 次预测。因为许多预测不包含任何目标对象,所以 SSD 保留了一个“0”类,表示它没有对象。
- 在预测过程中,置信度最高的那个类别就是边界框所属的类别。特别的,当第一个置信度最高时,表示边界框中并不包含目标。
-
边界框的location
- 组成: ( c x , c y , w , h ) (c_{x},c_{y},w,h) (cx,cy,w,h) , ( c x , c y ) (c_{x},c_{y}) (cx,cy)表示边界框的中心坐标, ( w , h ) (w,h) (w,h)表示宽高。但是真实预测其实只是预测边界框相对于anchor先验框的偏差值(offset)。此处和Faster RCNN一致。
建议参考《Faster RCNN超详细入门 02网络细节与训练方法 (anchors,RPN,bbox,bounding box,Region proposal layer……)》
输出
- 在经过一定的卷积进行特征提取后,我们得到一个大小为m × n(位置数)的特征层,具有p个通道,例如上面的 8×8 或 4×4。并且在这个m × n × p特征层上应用了一个 3×3 的卷积。
- 对于每个位置,我们有k个边界框。这 k 个边界框具有不同的大小和纵横比。
- 对于每个边界框,我们将计算C类分数和相对于原始默认边界框形状的 4 个偏移量。
- 因此,我们得到了( c +4) kmn 个输出。
❓为什么要有不同的横纵比?
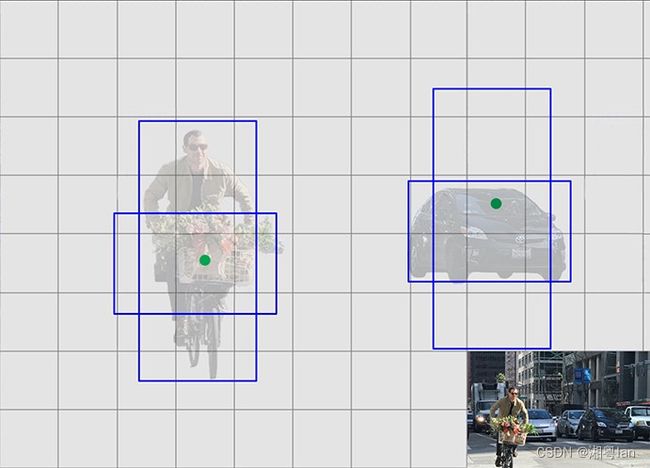
早期训练中,对人和车预测的bounding box形状可能都是竖直的。对人也许应该这样预测,因为行人的横纵比为0.41,但汽车显然需要水平的bounding box来预测。我们只需要一个猜测是正确,只要有一个猜测能找到物体就行,因此如果从生活中常见的猜测开始,那么初始训练就会更加地稳定。(比如预测一个横的,一个纵的)
- Confidence Loss(置信度损失):衡量网络对计算出的边界框的客观性的置信度。分类交叉熵用于计算这种损失。
- Location Loss(位置损失):这衡量了网络的预测边界框与训练集的真实边界框的距离。这里使用L2-Norm 。
Anchor 计算
Anchor box number

每一层的feature maps 有不同数量的anchor,而总共有三个形状, 一个是正方形, 其最小边框的size是 m i n _ s i z e min\_size min_size, 最大边框是 ( m i n _ s i z e ∗ m a x _ s i z e ) \sqrt{(min\_size *max\_size)} (min_size∗max_size)。长宽比有2,3,因此两个正方形跟四个长方形, 一共六种形状如上图。
每层anchor number的参数配置[4,6,6,6,4,4], 4代表只有正方形加上长宽比为2的长方形, 共四种, 6代表全部形状的anchor box。
而每一层的layer width, layer height 乘以anchor number, 我们就能得出所有的anchor box。每层的feature maps 长宽为{38, 19, 10, 5, 3, 1}。
所以共有:38 × 38 × 4 + 19 × 19 × 6 + 10 × 10 × 6 + 5 × 5 × 6 + 3 × 3 × 4 + 1 × 1 × 4 = 8732个anchor boxes。
Anchor size

论文当中,假设 S m i n = 0.2 , S m a x = 0.9 S_{min} = 0.2, S_{max} = 0.9 Smin=0.2,Smax=0.9,初始的default box scale为0.1。
s 1 = 0.2 + ( 0.9 − 0.2 ) ( 5 – 1 ) ∗ ( 1 – 1 ) = 0.2 s_{1} = 0.2 +\frac {(0.9 - 0.2)} {(5–1)} * (1–1) = 0.2 s1=0.2+(5–1)(0.9−0.2)∗(1–1)=0.2
s 2 = 0.2 + ( 0.9 − 0.2 ) ( 5 – 1 ) ∗ ( 2 – 1 ) = 0.375 s_{2} = 0.2 + \frac {(0.9 - 0.2)} {(5–1)} * (2–1) = 0.375 s2=0.2+(5–1)(0.9−0.2)∗(2–1)=0.375(四舍五入至0.37)
s 3 = 0.2 + ( 0.9 − 0.2 ) ( 5 – 1 ) ∗ ( 3 – 1 ) = 0.55 s_{3} = 0.2 + \frac{(0.9 - 0.2)} {(5–1)} * (3–1) = 0.55 s3=0.2+(5–1)(0.9−0.2)∗(3–1)=0.55(由于在计算上几乎都是直接0.37+0.17 = 0.54, 故我们直接使用0.54)。
……
m i n _ s i z e = 300 ∗ 0.1 = 30 min\_size = 300 * 0.1 = 30 min_size=300∗0.1=30(初始的default box scale为0.1)
m i n _ s i z e = 300 ∗ s 1 = 60 min\_size = 300 * s1= 60 min_size=300∗s1=60
m i n _ s i z e = 300 ∗ s 2 = 111 min\_size = 300 * s2=111 min_size=300∗s2=111
……
| layer | min_size | max_size |
|---|---|---|
| conv4_3 | 30 | 60 |
| fc7 | 60 | 111 |
| conv6_2 | 111 | 162 |
| conv7_2 | 162 | 213 |
| conv8_2 | 213 | 264 |
| conv9_2 | 264 | 315 |
MultiBoxLayer代码
class MultiBoxLayer(nn.Module):
num_classes = 21
num_anchors = [4,6,6,6,4,4]
in_planes = [512,1024,512,256,256,256]
def __init__(self):
super(MultiBoxLayer, self).__init__()
self.loc_layers = nn.ModuleList()
self.conf_layers = nn.ModuleList()
for i in range(len(self.in_planes)):
self.loc_layers.append(nn.Conv2d(self.in_planes[i], self.num_anchors[i]*4, kernel_size=3, padding=1))
self.conf_layers.append(nn.Conv2d(self.in_planes[i], self.num_anchors[i]*21, kernel_size=3, padding=1))
Default box代码
'''Compute default box sizes with scale and aspect transform.'''
scale = 300.
steps = [s / scale for s in (8, 16, 32, 64, 100, 300)]
sizes = [s / scale for s in (30, 60, 111, 162, 213, 264, 315)]
aspect_ratios = ((2,), (2,3), (2,3), (2,3), (2,), (2,))
feature_map_sizes = (38, 19, 10, 5, 3, 1)
# 38×38×4+19×19×6+10×10×6+5×5×6+3×3×4+1×1×4=8732
num_layers = len(feature_map_sizes)
boxes = []
for i in range(num_layers):
fmsize = feature_map_sizes[i] # feature map size
for h,w in itertools.product(range(fmsize), repeat=2):
# for each point in feature map
cx = (w + 0.5)*steps[i]
cy = (h + 0.5)*steps[i]
s = sizes[i]
boxes.append((cx, cy, s, s))
s = math.sqrt(sizes[i] * sizes[i+1])
boxes.append((cx, cy, s, s))
s = sizes[i]
for ar in aspect_ratios[i]:
boxes.append((cx, cy, s * math.sqrt(ar), s / math.sqrt(ar)))
boxes.append((cx, cy, s / math.sqrt(ar), s * math.sqrt(ar)))
self.default_boxes = torch.Tensor(boxes)
2.3 Dilation
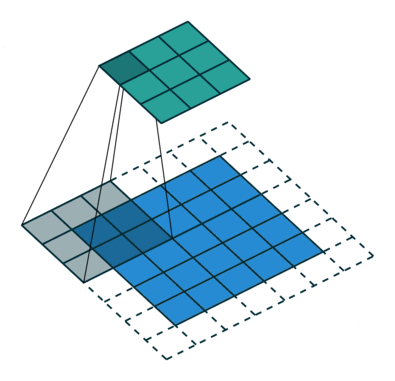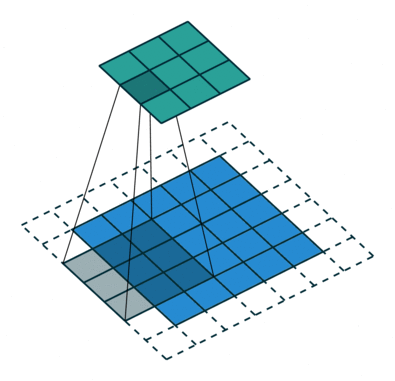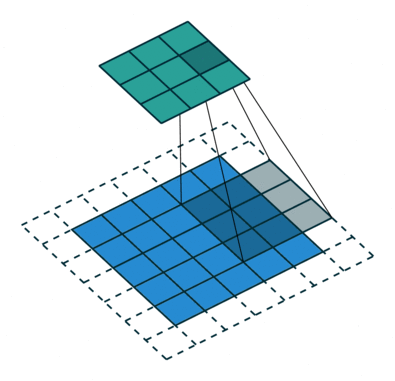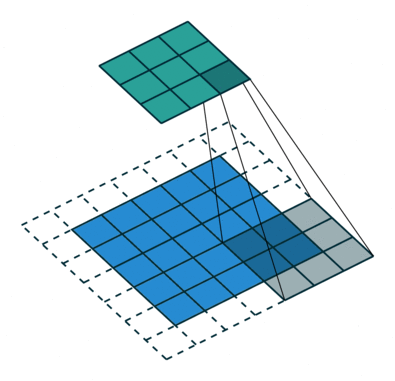
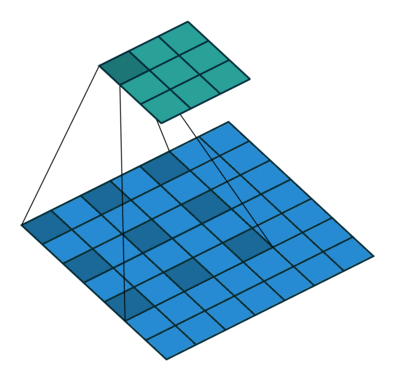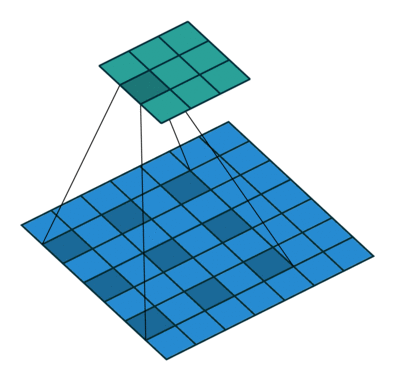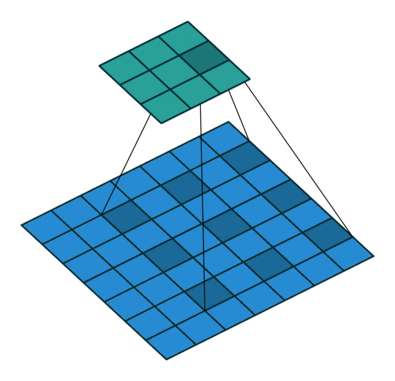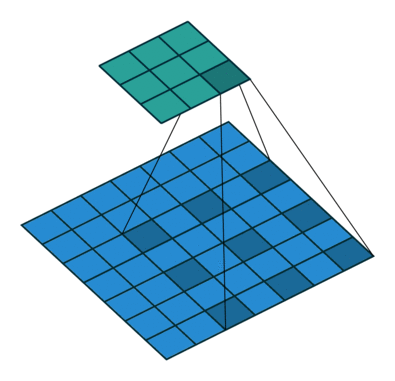
SSD使用 ILSVRC 分类数据集进行了预训练,分别将VGG16的全连接层fc6和fc7转换成 3 × 3 3\times3 3×3 卷积层 conv6和 1 × 1 1\times1 1×1 卷积层conv7,同时将池化层pool5由原来的stride=2的 2 × 2 2\times2 2×2 变成stride=1的 3 × 3 3\times 3 3×3
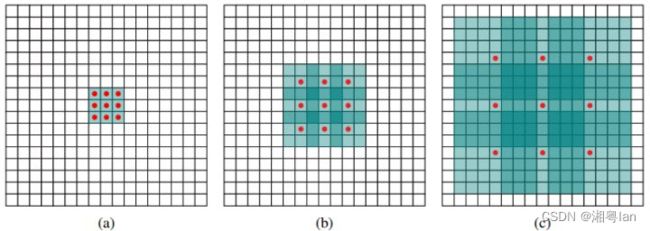
普通3 x 3的conv, 所能看到的视野就是 3 x 3 , 但使用dilation 1, 视野可以变为7 * 7。
(a)是普通的 3 × 3 3\times3 3×3 卷积,其视野就是 3 × 3 3\times3 3×3 ,(b)是扩张率为1,此时视野变成 7 × 7 7\times7 7×7 ,(c)扩张率为3时,视野扩大为 15 × 15 15\times15 15×15,但是视野的特征更稀疏了。Conv6采用 3 × 3 3\times3 3×3 大小但dilation rate=6的扩展卷积。
使用如上所示的Dilation卷积可以增加感受野,同时与传统卷积相比保持相对较少的参数数量。
然后移除dropout层和fc8层,并新增一系列卷积层,在检测数据集上做finetuing。
其中VGG16中的Conv4_3层将作为用于检测的第一个特征图。conv4_3层特征图大小是 38\times38 ,但是该层比较靠前,其norm(范数)较大,所以在其后面增加了一个L2 Normalization层,以保证和后面的检测层差异不是很大,这个和Batch Normalization层不太一样,其仅仅是对每个像素点在channle维度做归一化,而Batch Normalization层是在[batch_size, width, height]三个维度上做归一化。 归一化后一般设置一个可训练的放缩变量gamma。
若需详细了解Dilation可参考《如何理解空洞卷积(dilated convolution)?》
三、SSD的训练
3.1 Loss function及代码
SSD的output分两类, 分别是判断类别的classification, 与为了增加box准确度的location offset,。输出分别为21和4。 21代表类别总共有21种(20种目标类别+1种背景类别), 而4代表 x , y , w , h x, y, w, h x,y,w,h的偏移量(offset)。
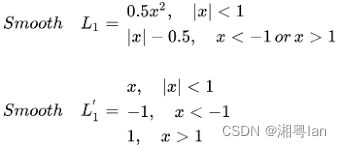
有关loc的loss, 使用的是SmoothL1Loss, 这个loss function我们并不陌生, 在fasterRCNN也可以看到。
❓为什么要用SmoothL1Loss?
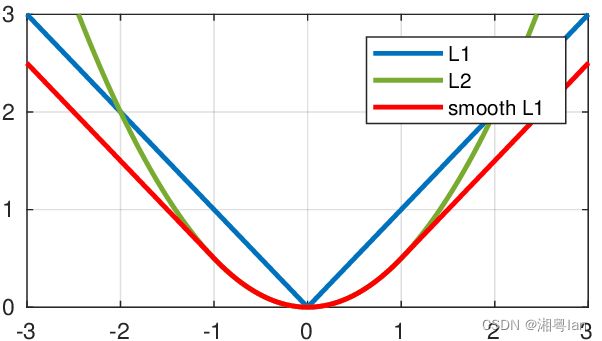
根据fast rcnn的说法,“… L1 loss that is less sensitive to outliers than the L2 loss used in R-CNN and SPPnet.” 也就是smooth L1 loss让loss对于离群点更加鲁棒,即:相比于L2损失函数,其对离群点、异常值(outlier)不敏感,梯度变化相对更小,训练时不容易跑飞。
*注意:smooth L1和L1-loss函数的区别在于,L1-loss在0点处导数不唯一,可能影响收敛。smooth L1的解决办法是在0点附近使用平方函数使得它更加平滑。
若需详细了解Smooth1Loss可参考《损失函数:L1 loss, L2 loss, smooth L1 loss》
Smooth1Loss代码
# loc_loss = SmoothL1Loss(pos_loc_preds, pos_loc_targets)
pos_mask = pos.unsqueeze(2).expand_as(loc_preds)
pos_loc_preds = loc_preds[pos_mask].view(-1,4)
pos_loc_targets = loc_targets[pos_mask].view(-1,4)
loc_loss = F.smooth_l1_loss(pos_loc_preds, pos_loc_targets, size_average=False)
# conf_loss = CrossEntropyLoss(pos_conf_preds, pos_conf_targets)
+ CrossEntropyLoss(neg_conf_preds, neg_conf_targets)
conf_loss = F.cross_entropy(conf_preds.view(-1,self.num_classes), \
conf_targets.view(-1), reduce=False) # [N*8732,]
3.2 先验框匹配
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。
Yolo中,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框负责预测它。
SSD中,先验框与ground truth的匹配原则有两点:
1、每个ground truth找到与其IOU最大的先验框,互相匹配。该先验框称为正样本(先验框对应的预测box)
若有个先验框没有与ground truth匹配,就只能与背景匹配,就是负样本。(一个图片中ground truth少,但先验框多,这样匹配,很多先验框会是负样本,正负样本不均衡)。
2、对剩余未匹配先验框,若某个ground truth的IOU大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。
这样ground truth可能与多个先验框匹配。

3.3 Hard negative mining(硬负挖掘)
在训练过程中,由于大多数边界框的 IoU 较低,因此被解释为负训练示例,我们最终可能会在训练集中得到不成比例的负示例。因此,不要使用所有负面预测,而是将负面与正面示例的比例保持在 3:1 左右。 具体做法:先将每一个物体位置上对应 predictions(default boxes)是 negative 的 boxes 进行排序。按照 default boxes 的 confidence 的大小, 选择最高的几个。 保证最后 negatives、positives 的比例接近3:1。这可以使模型具有更快的优化和更稳定的训练效果。
❓为什么需要保留负样本?
需要保留负样本的原因是因为网络还需要学习并被明确告知什么构成了错误的检测。
3.3 Data augmentation(数据增强)

主要采用的技术有水平翻转(horizontal flip),随机裁剪加颜色扭曲(random crop & color distortion),随机采集块域(Randomly sample a patch)(获取小目标训练样本),如上图所示。
为了处理各种目标大小和形状的变体,每个训练图像都通过以下选项之一随机采样:
- 使用原本的图像,
- 对 IoU 为 0.1、0.3、0.5、0.7 或 0.9 的patch进行采样,
- 随机采样一个patch。
采样的patch将具有 1/2 和 2 之间的纵横比。然后将其调整为固定大小,再翻转一半的训练数据。

此外,我们可以应用照片失真。
以下是数据增强后的性能提升:

四、结果
4.1 Inference time(推测时间)
NMS(非极大值抑制)
与许多其他检测方法相比,SSD 做出了许多预测 (output = 8732),以更好地覆盖位置、比例和纵横比。然而,许多预测不包含任何对象。因此,任何类别置信度分数低于 0.01 的预测都将被消除。
SSD 使用非极大值抑制来删除指向同一目标对象的重复预测。SSD 按置信度分数对预测进行排序。从最高置信度预测开始,SSD 评估任何先前预测的边界框与当前预测的同一类的 IoU 是否高于 0.45。如果找到,当前预测将被忽略。我们最多保留每张图像的前 200 个预测。

4.2 mAP及速度表现
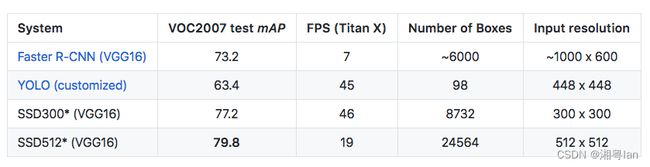
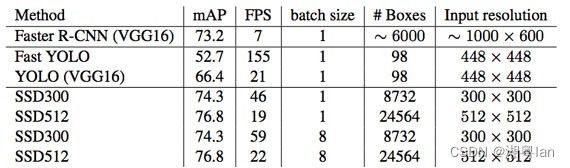
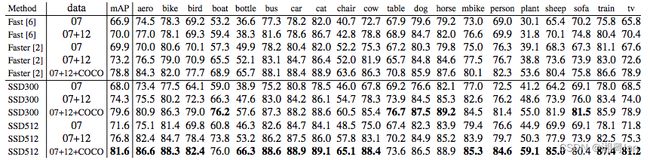
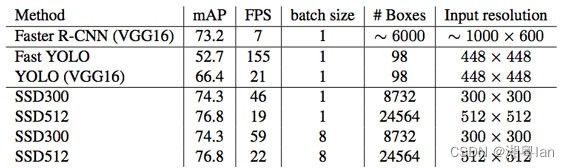
SSD模型使用 SGD 进行训练,initial learning rate(初始学习率)为 0.001,momentum(动量)为 0.9,weight decay(权重衰减)为 0.0005,batch size(批量大小)为 32。在 VOC2007 测试中使用 Nvidia Titan X,SSD 在 VOC2007 测试中达到 59 FPS,mAP 为 74.3%,vs . Faster R-CNN 7 FPS with mAP 73.2% or YOLO 45 FPS with mAP 63.4%。
ps:对于 SSD,它使用 300 × 300 或 512 × 512 的图像大小。
五、总结
- 对于小物体,SSD 的性能比 Faster R-CNN 差。在 SSD 中,只能在更高分辨率的层(最左边的层)中检测到小物体。但这些层包含低级特征,如边缘或色块,分类信息较少。
- 精度随着先验边界框(default anchors)的数量增加而增加,但以速度为牺牲代价。
- SSD 与 R-CNN 相比具有较低的定位误差,但在处理相似类别时的分类误差更大。较高的分类错误可能是因为我们使用相同的边界框进行多类预测。
- SSD 是单阶段检测器(one-stage)。它没有Faster RCNN的区域提议网络(Region Proposal Network),并且直接从特征图一次性得到预测边界框和类。
- 为了提高准确性,SSD引入了:
- 用于预测目标类别和先验边界框的偏移量的小型卷积滤波器。
- 先验框的单独过滤器以处理纵横比的差异。
- 用于目标检测的多尺度特征图。
- SSD 可以进行端到端的训练以获得更好的准确性。SSD 可以做出更多的预测,并在位置、规模和纵横比方面具有更好的覆盖范围。通过上述改进,SSD 可以将输入图像分辨率降低到 300 × 300,并具有相当的精度性能。通过移除区域提议网络并使用较低分辨率的图像,该模型可以以实时速度(Real-Time)运行,同时在准确性方面仍然优于最先进的 Faster R-CNN。