卷积神经网络的可视化(一)(可视化中间激活)(猫狗分类问题,keras)
目录
- 卷积神经网络的可视化
-
- 可视化中间激活
-
- 在猫狗分类数据集上从头训练一个卷积神经网络
-
- 分割出一个小型数据集
- 构建网络
- 数据预处理
- 利用批量生成器拟合模型
- 绘制损失曲线和精度曲线
- 使用数据增强
- 利用数据增强生成器训练卷积神经网络
- 可视化单个通道
- 将每层激活的所有通道可视化
- References
总结自《Python 深度学习》(François Chollet)第5章。
卷积神经网络的可视化
人们常说,深度学习模型是黑盒,即模型学到的表示很难用人类可以理解方式来提取和呈现。但对于卷积神经网络来说绝对不是这样。卷积神经网络的表示非常适合可视化,很大程度上是因为它们是视觉概念的表示(可在《深入理解卷积神经网络》中结尾部分了解卷积神经网络与神经科学的关联)。我们将介绍介绍三种最容易理解也最容易的方法:
- 可视化卷积神经网络的中间输出(中间激活):有助于理解卷积神经网络连续的层如何对输入进行变换,也有助于初步了解卷积神经网络每个过滤器的含义。
- 可视化卷积神经网络的过滤器:有助于精确理解卷积神经网络中每个过滤器容易接受的视觉模式或视觉概念。
- 可视化图像中类激活的热力图:有助于理解图像的哪个部分被识别为属于某个类别,从而可以定位图像中的物体。这对于我们判断网络是否学到了真正有含义的表示非常有意义。
本节将介绍可视化卷积神经网络的中间输出。
可视化中间激活
在猫狗分类数据集上从头训练一个卷积神经网络
猫狗分类数据集是一个相对小型的数据集,数据集中包含 25000 张猫和狗的图像(12500 张狗,12500 张猫)。但我们将只使用训练集中的 2000 张图像用于训练,1000 张用于验证,1000 张用于测试。数据集可在 https://www.kaggle.com/c/dogs-vs-cats/data 下载。如果 kaggle 无法登录,可从这里下载:kaggle 猫狗图像分类数据集。
分割出一个小型数据集
import os, shutil
original_dataset_dir = '../input/dogs-vs-cats/train' # 原始数据集路径
base_dir = '../input/dogs-vs-cats-small' # 新的小数据集路径
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'val')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
"""猫的训练图像目录"""
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
"""狗的训练图像目录"""
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
"""猫的验证图像目录"""
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
"""狗的验证图像目录"""
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
"""猫的测试图像目录"""
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
"""狗的测试图像目录"""
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
"""将前1000 张猫的图像复制到 train_cats_dir"""
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fnames)
shutil.copyfile(src, dst)
"""将接下来 500 张猫的图像复制到 validation_cats_dir"""
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
"""将接下来 500 张猫的图像复制到 test_cats_dir"""
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
"""将前1000 张狗的图像复制到 train_dogs_dir"""
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
"""将接下来 500 张狗的图像复制到 validation_dogs_dir"""
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
"""将接下来 500 张狗的图像复制到 test_dogs_dir"""
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
可以通过 len(os.listdir(filepath)) 验证每个分组中分别包含多少张图像。
构建网络
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
可通过 model.summary() 查看特征图的维度如何随着每层变化。还不清楚特征图维度如何计算的话,也可以查看我之前的文章《深入理解卷积神经网络》。
编译模型:《基于梯度的学习》为大家列出了该如何选择输出层激活函数和对应的损失函数。
from tensorflow.keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
数据预处理
将数据输入神经网络之前,应该将数据格式化为经过预处理的浮点数张量。现在我们的原始数据是 JPEG 格式的图像,因此数据预处理步骤大致如下:
- 读取图像文件
- 将 JPEG 文件解码为 RGB 像素网格
- 将这些像素网格转换为浮点数张量
- 将像素值(0-255)缩放到 [0, 1] 区间
但 keras 提供有自动完成这些步骤的工具:ImageDataGenerator 类,可以快速创建 Python 生成器,能够将硬盘上的图像文件自动转换为预处理好的张量批量。
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size = (150, 150),
batch_size = 16,
class_mode = 'binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150, 150),
batch_size = 16,
class_mode = 'binary'
)
注意,在使用 flow_from_directory 时,一定要规划好文件的存放路径。flow_from_directory 中指定的路径下必须还要有存放不同类文件的子目录。就这个例子来说,我们的 train_dir 下还有分别存放猫和狗图像的 cats 和 dogs 子目录。
利用批量生成器拟合模型
我们共有 2000 个训练样本和 1000 个测试样本,因此,每个 epoch 的训练批次和验证批次分别为 125 和 63。或者直接使用 len(train_generator) 和 len(validation_generator) 计算。
history = model.fit_generator(
train_generator,
steps_per_epoch=125,
epochs=30,
validation_data=validation_generator,
validation_steps=63
)
保存模型:
model.save('cats_and_dogs_small_1.h5')
绘制损失曲线和精度曲线
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc)+1)
plt.plot(epochs, acc, 'bo', label='Training Acc')
plt.plot(epochs, val_acc, 'r', label='Validation Acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training Loss')
plt.plot(epochs, val_loss, 'r', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
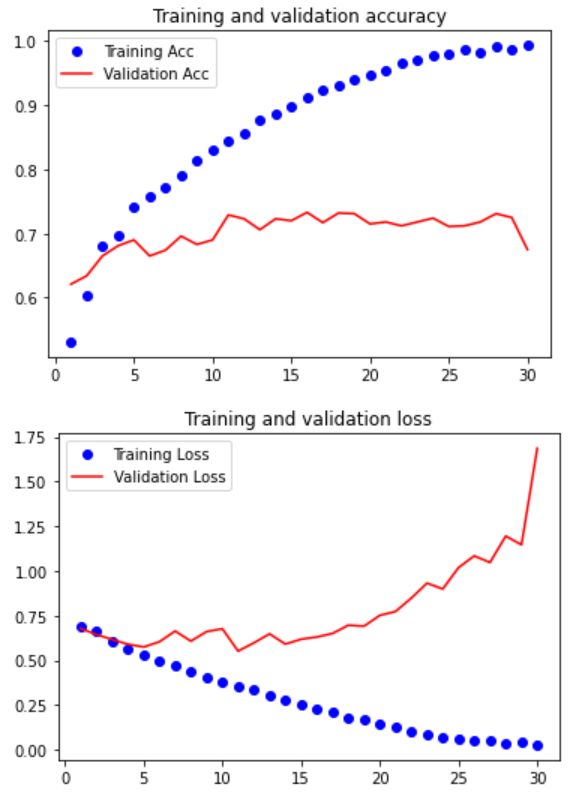
显然模型过拟合了。这是可以预料到的,因为我们使用了较少的训练样本。下面我们用数据增强降低过拟合。
使用数据增强
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
"""
rotation_range 是角度值(0-180),表示图像随机旋转的角度范围
width_shift_range,height_shift_range 是图像在水平或垂直方向上平移的范围
(相对于总宽度或总高度的比例)
shear_range 是随机错切变换的角度
zoom_range 是图像随机缩放的范围
fill_mode 是用于填充新像素的方法
"""
显示几张随即增强后的训练图像:
from keras.preprocessing import image
fnames = [os.path.join(train_cats_dir, fname) for
fname in os.listdir(train_cats_dir)]
img_path = fnames[6]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img) # 转换为 Numpy 数组
x = x.reshape((1,) + x.shape) # 将形状变为 (1, 150, 150, 3)
i = 0
plt.figure(figsize=(10, 10))
for batch in datagen.flow(x, batch_size=1):
plt.subplot(2, 2, i + 1)
plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
我们可以向密集连接分类器之前再加入一个 Dropout 层,进一步降低过拟合:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Dropout(0.5))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
利用数据增强生成器训练卷积神经网络
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1./255) # 验证数据不能增强
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size = (150, 150),
batch_size = 32,
class_mode = 'binary'
)
history = model.fit_generator(
train_generator,
steps_per_epoch=63,
epochs=100,
validation_data=validation_generator,
validation_steps=32
)
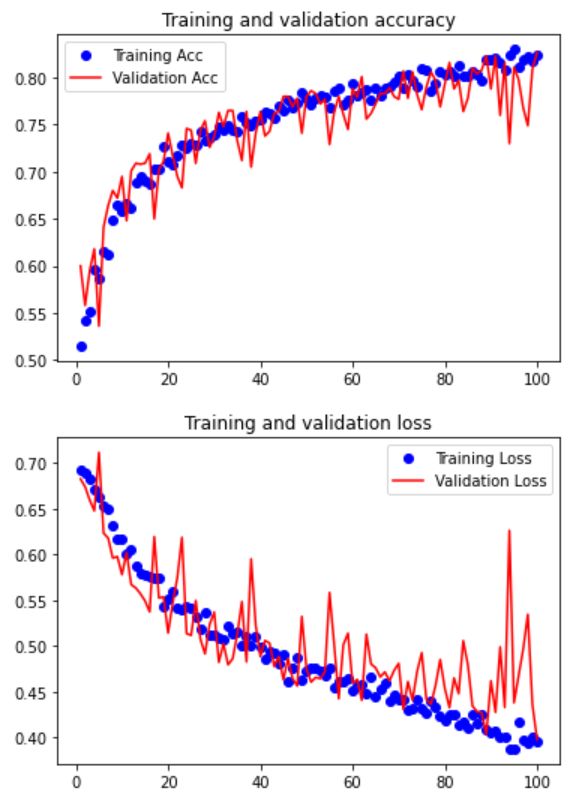
保存模型
model.save('cats_and_dogs_small_2.h5')
我们将可视化这个模型的中间激活值。
可视化单个通道
从测试集输入一张猫的图像并进行预处理:
img_path = '../input/catsANDdogs_small/test/cats/cat.1700.jpg'
from keras.preprocessing import image
import numpy as np
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis=0)
img_tensor /= 255.
提取模型前八层的输出:
from keras import models
# 模型实例化
layer_outputs = [layer.output for layer in model.layers[:8]]
activation_model = models.Model(inputs=model.input, outputs=layer_outputs)
activations = activation_model.predict(img_tensor)
first_layer_activation = activations[0]
first_layer_activation.shape
"""
Out: (1, 148, 148, 32)
"""
32通道的 148×148 特征图,我们绘制第九个和第十九个通道:(因为训练过程的不确定性,我们的过滤器可能是不一样的)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
plt.matshow(first_layer_activation[0, :, :, 9], cmap='viridis')
plt.title('9th channel')
plt.figure(figsize=(10, 10))
plt.matshow(first_layer_activation[0, :, :, 19], cmap='viridis')
plt.title('19th channel')
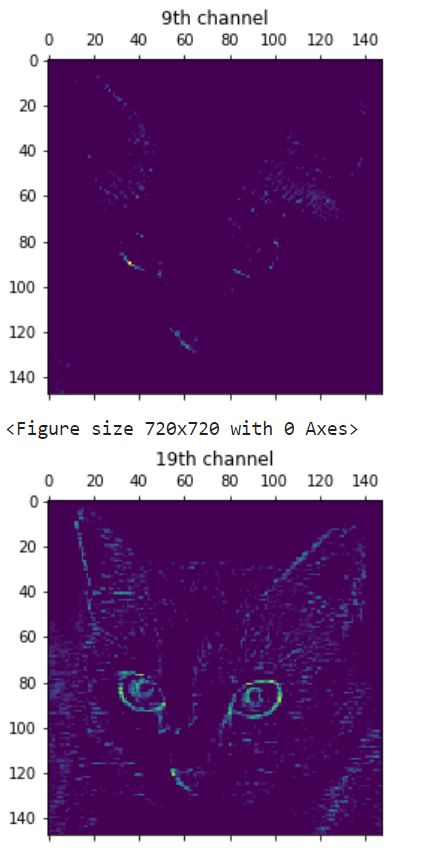
将每层激活的所有通道可视化
layer_names = []
for layer in model.layers[:8]:
layer_names.append(layer.name)
# 每行显示多少个特征图
image_per_row = 16
for layer_name, layer_activation in zip(layer_names, activations):
# layer_activation: (1, size, size, channels)
n_features = layer_activation.shape[-1]
size = layer_activation.shape[1]
# 显示几行
n_cols = n_features // images_per_row
display_grid = np.zeros((size * n_cols, images_per_row*size))
for col in range(n_cols):
for row in range(image_per_row):
channel_image = layer_activation[0, :, :, col*images_per_row+row]
"""为美观而做的处理"""
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
display_grid[col*size:(col+1)*size,
row*size:(row+1)*size] = channel_image
scale = 1./size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, aspect='auto', cmap='viridis')


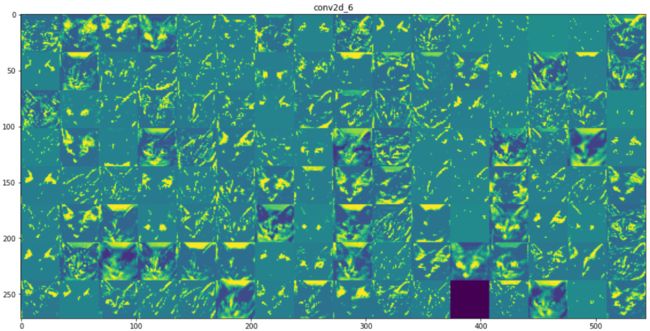
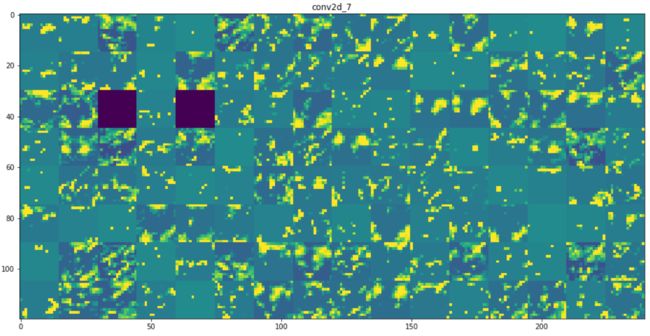
从上面的图中我们可以得出以下几个结论:
- 第一层是各种边缘探测器的集合。在这一阶段,激活激活保留了原始图像中的所有信息。
- 随着层数的加深,激活变得越来越抽象,并且越来越难以直观地理解。它们开始表示更高层次的概念,比如猫耳朵和猫眼睛。层数越深,其表示中关于图像视觉内容的信息就越少,而关于类别的信息就越多。
- 激活的稀疏度随着层数的加深而增大。在第一层里,所有过滤器都被输入图像激活,但在后面的层里,越来越多的过滤器是空白的。也就是说,输入图像中找不到这些过滤器所编码的模式。
深度神经网络可以有效地作为信息蒸馏管道,输入原始数据,反复对其进行变换,将无关信息过滤掉,并放大和细化有用的信息。这与人类和动物感知世界的方式类似,我们可以很轻易的记住场景中的抽象物体,但很难准确地记住这些物体的具体外观。
References
《Python 深度学习》,François Chollet.