pytorch实现AlexNet(含完整代码)
写在前面
本人小白,下面的文字简单记录自己在pytorch的基础之上,实现AlexNet文章中的模型,也希望能和其他的朋友一起交流心得。(记录贴,只用来整理自己思路)
AlexNet论文
AlexNet的文章中主要介绍了利用deep convolutional neural networks(深度卷积神经网络)在数据集中取得很好的结果。在当时,其开创性主要包括以下几个方面:模型构建,ReLu(),Local Response Normalization,Overlapping Pooling以及Reducing Overfitting。
ReLu()
当时的神经网络中激活函数主要采用的是tanh(x)和sigmoid(x)函数,文章中提出使用Relu()函数来降低训练的时间,具体区别可以看这里:Relu()和tanh(),sigmoid()
LNR
LNR在网络中主要用来归一化,但是在后来神经网络的发展过程中已经不经常使用,所以这里不再赘述
Overlapping Pooling
文章中池化层的stride=2,kernal_size=3,因此部分数据会有重叠,这种池化层的设计与stride=2,kernal_size=2的相比,会降低0.4%的错误率
Reducing Overfitting
减小过拟合的方法有两种,数据增强和DropOut。
模型构建
AlexNet的卷积网络包含5个卷积层,3个全连接层,具体的顺序如下:
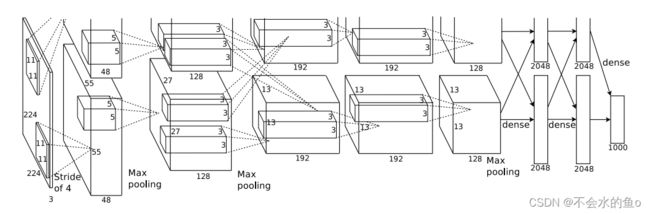
其中在1,2层卷积之后,使用Max pooling池化层,3,4,5层之后再次使用Max Pooling层。之后是三个全连接层。
原文在两个GPU上运行,因此会把数据分为两部分,而且图片格式为224X224X3,之后的卷积层、池化层的stride,padding都需要手动计算。
数据集
数据集下载
这次采用的数据集是猫狗数据集,提取码485q 网盘链接
下载之后解压,会得到一个训练集,其中猫和狗的图片会在同一个文件夹中,因此我们需要先将其分类,再进行下一步的操作。(因为在训练时如果不分类无法进行,当然,如果有更好的方法,望告知)
数据集分类
首先,新建一个文件夹 'train_0',下面包含两个空文件夹 '0' ,'1' 之后会将train里面的文件分别移动到'train_0'下面的'0','1'中。
import os
import re
import shutil
origin_path=r'E:\buttle\kaggle\train'
target_path_0=r'E:\buttle\kaggle\train_0\0'
target_path_1=r'E:\buttle\kaggle\train_0\1'
file_list=os.listdir(origin_path)
for i in range(len(file_list)):
old_path=os.path.join(origin_path,file_list[i])
print(file_list[i])
result=re.findall(r'\w+',file_list[i])[0]
if result=='cat':
shutil.move(old_path,target_path_0)
else:
shutil.move(old_path,target_path_1)origin_path,target_path_0,tarfet_path_1的绝对路径对照自己的进行设置
file_list=os.listdir(origin_path)接收路径,返回指定的路径下文件或者文件夹列表,列表元素类型为 ‘str’,实际上列表中元素均为文件夹下图片的名称
for i in range(len(file_list)):
old_path=os.path.join(origin_path,file_list[i])
result=re.findall(r'\w+',file_list[i])[0]遍历列表,old_path指的是列表下的每一个图片的路径
观察到每一张图片的名称都会有‘cat’,‘dog’这种含有分类信息的字符,因此匹配图片名称中的字符。
findall()函数返回图片名称中字符的列表,其中re.findall()[0]元素是‘cat'或者‘dog’,因此可以作为分类的条件。
if result=='cat':
shutil.move(old_path,target_path_0)
else:
shutil.move(old_path,target_path_1)根据名称,把图片移动到对应的文件夹中
AlexNet代码复现
网络模型构建
1.卷积层的构建
class AlexNet(nn.Module):
def __init__(self,num_classes=2):
super(AlexNet, self).__init__()
self.features=nn.Sequential(
nn.Conv2d(3,48, kernel_size=11),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(48,128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(128,192,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192,192,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192,128,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
)类的继承,Sequential的使用
其中Conv2的()的参数,尤其是有关stride和padding的,需要自己计算。
2.全连接层的构建
self.classifier=nn.Sequential(
nn.Linear(6*6*128,2048),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(2048,2048),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(2048,num_classes),
)这里面我没有过多关注Dropout()应该放的位置
3.前向传播
def forward(self,x):
x=self.features(x)
x=torch.flatten(x,start_dim=1)
x=self.classifier(x)
return x中间卷积层---全连接层,需要将x由6*6*128的张量变为一维向量,因此需要用到flatten()
flatten()和view()函数有什么区别?
数据增强
def DataEnhance(sourth_path,aim_dir,size):
name=0
#得到源文件的文件夹
file_list=os.listdir(sourth_path)
#创建目标文件的文件夹
if not os.path.exists(aim_dir):
os.mkdir(aim_dir)
for i in file_list:
img=Image.open('%s\%s'%(sourth_path,i))
name+=1
transform1=transforms.Compose([
transforms.ToTensor(),
transforms.ToPILImage(),
transforms.Resize(size),
])
img1=transform1(img)
img1.save('%s/%s'%(aim_dir,name))
数据增强,实质上就是在数据过少的情况下,对原有的数据进行灰度、裁切、旋转、镜像、明度、色调、饱和度变化的一系列过程,用来增加数据量。
ima-=Ima.open(Ima_path) --打开路径下的图片,并且类型为PIL类型
transform:在torchvision下面的类,主要用于图形的变换
transform.Compose()--串联多个图形变换
transfrom.Totensor()和transform.ToPILImage()--将输入数据的通道进行转换,并且将数据归一化到[0,1],详细解释可以看这里:关于Totensor和ToPILImage
transform.Resize()--重新设置图片大小,通过拉伸改变图片
最后将源路径图片变换后保存到目标路径
训练集、测试集、验证集的导入
在前面,我们已经将图片分类好,并且经过数据增强,增加了数据集的数量,下一步,我们准备将数据集如何导入代码
#归一化处理
normalize=transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
path_1=r'E:\buttle\kaggle\train'
trans_1=transforms.Compose([
transforms.Resize((65,65)),
transforms.ToTensor(),
normalize,
])
#数据集
train_set=ImageFolder(root=path_1,transform=trans_1)
#数据加载器
train_loader=torch.utils.data.DataLoader(train_set,batch_size=BATCH_SIZE,
shuffle=True,num_workers=0)transform.Normalize()--逐通道对图像标准化,可以加快模型的收敛性,普遍认为
![]()
更详细的解析参考:关于Normalize的理解
ImageFolder(root,transform=None,target_transform=None,loader=default_loader)
其中root--存储路径,transform--图片转换
该函数默认数据集已经自动按照要求分类,每一个文件夹下面保存一个类别的图片
dataset=ImageFolder(...)
print(dataset.classes)
>>>['cat','dog']
print(dataset.calss_to_idx)
>>>['cat':0,'dog':1]
print(data.imgs)
>>>[('....jpg',0),('..jpg',1)]个人认为ImageFolder为数据集中每一种图片生成‘label’,并把label和图片一一对应
torch.utils.data.DataLoader--用来将训练集分成多个小组,通过迭代抛出data,其中data中包含了图像的数据(inputs)和标签(labels)
训练
#定义模型
model=AlexNet().to(DEVICE)
#优化器的选择
optimizer=optim.SGD(model.parameters(),lr=0.01,momentum=0.9,weight_decay=0.0005)def train_model(model,device,train_loader,optimizer,epoch):
train_loss=0
model.train()
for batch_index,(data,label) in enumerate(train_loader):
data,label=data.to(device),label.to(device)
optimizer.zero_grad()
output=model(data)
loss=F.cross_entropy(output,label)
loss.backward()
optimizer.step()
if batch_index%300==0:
train_loss=loss.item()
print('Train Epoch:{}\ttrain loss:{:.6f}'.format(epoch,loss.item()))
return train_lossenumerate(iterable,start=0)--返回一个枚举对象,其中包含一个计数值i和通过迭代获取的值data,data中包括了图像数据(inputs)和标签(labels)
model.train()--模型进入训练模式
optimizer.zero_grad()--梯度清零,重新开始记录
loss.item()—只返回loss函数中数据类型,不去管梯度回传的部分,因为loss()中会包含梯度回传,好呢容易跑满显寸
def test_model(model,device,test_loader):
model.eval()
correct=0.0
test_loss=0.0
#不需要梯度的记录
with torch.no_grad():
for data,label in test_loader:
data,label=data.to(device),label.to(device)
output=model(data)
test_loss+=F.cross_entropy(output,label).item()
pred=output.argmax(dim=1)
correct+=pred.eq(label.view_as(pred)).sum().item()
test_loss/=len(test_loader.dataset)
print('Test_average_loss:{:.4f},Accuracy:{:3f}\n'.format(
test_loss,100*correct/len(test_loader.dataset)
))
acc=100*correct/len(test_loader.dataset)
return test_loss,acc测试
model.eval()--模型的测试模式(评估模式),关闭BN层和Dropout层,同时,在评估模式时,使用‘with torch.no_grad():',因为评估模式不需要梯度的回传。
pre=output.argmax(dim=1)--返回在dim=1的维度上(每一列)的最大值的索引号
pred.eq(label.view_as(pred))--其中view_as将label的格式返回成与pred相同的张量
训练开始
list=[]
Train_Loss_list=[]
Valid_Loss_list=[]
Valid_Accuracy_list=[]
#Epoc的调用
for epoch in range(1,EPOCH+1):
#训练集训练
train_loss=train_model(model,DEVICE,train_loader,optimizer,epoch)
Train_Loss_list.append(train_loss)
torch.save(model,r'E:\buttle\kaggle\save_model\model%s.pth'%epoch)
#验证集进行验证
test_loss,acc=test_model(model,DEVICE,valid_loader)
Valid_Loss_list.append(test_loss)
Valid_Accuracy_list.append(acc)
list.append(test_loss)torch.save(model,path)--将模型中可学习的参数保存到指定的路径,在后续的数据处理中,可以将表现好的模型参数加载出来重新进行测试
#验证集的test_loss
min_num=min(list)
min_index=list.index(min_num)
print('model%s'%(min_index+1))
print('验证集最高准确率: ')
print('{}'.format(Valid_Accuracy_list[min_index]))
#取最好的进入测试集进行测试
model=torch.load(r'E:\buttle\kaggle\save_model\model%s.pth'%(min_index+1))
model.eval()
accuracy=test_model(model,DEVICE,test_loader)
print('测试集准确率')
print('{}%'.format(accuracy))torch.load(PATH)--载入模型,然后进行测试
绘图
#字体设置,字符显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#坐标轴变量含义
x1=range(0,EPOCH)
y1=Train_Loss_list
y2=Valid_Loss_list
y3=Valid_Accuracy_list
#图表位置
plt.subplot(221)
#线条
plt.plot(x1,y1,'-o')
#坐标轴批注
plt.ylabel('训练集损失')
plt.xlabel('轮数')plt.reParams[]—设置字体,因为对于中文字体,如果设置不好字体会出现乱码
plt-plot(x,y,'-o') —线条设置
Q&A
准确率为什么*100?
——其实不*100得到小数,于结果影响不大
数据增强?
——因为数据集图片12500张,所以我在测试的时候没有进行数据的增强
完整代码
import torch
import os
from torch import nn
from torch.nn import functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
from torchvision.datasets import ImageFolder
import torch.optim as optim
import torch.utils.data
from PIL import Image
import torchvision.transforms as transforms
#超参数设置
DEVICE=torch.device('cuda'if torch.cuda.is_available() else 'cpu')
EPOCH=2
BATCH_SIZE=256
#网络模型构建
class AlexNet(nn.Module):
def __init__(self,num_classes=2):
super(AlexNet, self).__init__()
self.features=nn.Sequential(
nn.Conv2d(3,48, kernel_size=11),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(48,128, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(128,192,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192,192,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(192,128,kernel_size=3,stride=1,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2),
)
self.classifier=nn.Sequential(
nn.Linear(6*6*128,2048),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(2048,2048),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(2048,num_classes),
)
def forward(self,x):
x=self.features(x)
x=torch.flatten(x,start_dim=1)
x=self.classifier(x)
return x
#数据预处理
#数据路径
# aim_dir0=r'shdj'
# aim_dir1=r'sdj'
# source_path0=r'efeeeeee'
# source_path1=r'ddddddddd'
#数据增强
# def DataEnhance(sourth_path,aim_dir,size):
# name=0
# #得到源文件的文件夹
# file_list=os.listdir(sourth_path)
# #创建目标文件的文件夹
# if not os.path.exists(aim_dir):
# os.mkdir(aim_dir)
#
# for i in file_list:
# img=Image.open('%s\%s'%(sourth_path,i))
# print(img.size)
#
# name+=1
# transform1=transforms.Compose([
# transforms.ToTensor(),
# transforms.ToPILImage(),
# transforms.Resize(size),
# ])
# img1=transform1(img)
# img1.save('%s/%s'%(aim_dir,name))
#
# name+=1
# transform2=transforms.Compose([
# transforms.ToTensor(),
# transforms.ToPILImage(),
# transforms.ColorJitter(brightness=0.5,contrast=0.5,hue=0.5)
# ])
# img2 = transform1(img)
# img2.save('%s/%s' % (aim_dir, name))
#
# name+=1
# transform3=transforms.Compose([
# transforms.ToTensor(),
# transforms.ToPILImage(),
# transforms.RandomCrop(227,pad_if_needed=True),
# transforms.Resize(size)
# ])
# img3 = transform1(img)
# img3.save('%s/%s' % (aim_dir, name))
#
# name+=1
# transform4=transforms.Compose([
# transforms.Compose(),
# transforms.ToPILImage(),
# transforms.RandomRotation(60),
# transforms.Resize(size),
# ])
# img4 = transform1(img)
# img4.save('%s/%s' % (aim_dir, name))
#
#
# DataEnhance(source_path0,aim_dir0,size)
# DataEnhance(source_path1,aim_dir1,size)
#对文件区分为训练集,测试集,验证集
#归一化处理
normalize=transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
#训练集
path_1=r'E:\buttle\kaggle\train'
trans_1=transforms.Compose([
transforms.Resize((65,65)),
transforms.ToTensor(),
normalize,
])
#数据集
train_set=ImageFolder(root=path_1,transform=trans_1)
#数据加载器
train_loader=torch.utils.data.DataLoader(train_set,batch_size=BATCH_SIZE,
shuffle=True,num_workers=0)
#测试集
path_2=r'E:\buttle\kaggle\test'
trans_2=transforms.Compose([
transforms.Resize((65,65)),
transforms.ToTensor(),
normalize,
])
test_data=ImageFolder(root=path_2,transform=trans_2)
test_loader=torch.utils.data.DataLoader(test_data,batch_size=BATCH_SIZE,
shuffle=True,num_workers=0)
#验证集
path_3=r'E:\buttle\kaggle\valid'
valid_data=ImageFolder(root=path_2,transform=trans_2)
valid_loader=torch.utils.data.DataLoader(valid_data,batch_size=BATCH_SIZE,
shuffle=True,num_workers=0)
#定义模型
model=AlexNet().to(DEVICE)
#优化器的选择
optimizer=optim.SGD(model.parameters(),lr=0.01,momentum=0.9,weight_decay=0.0005)
#训练过程
def train_model(model,device,train_loader,optimizer,epoch):
train_loss=0
model.train()
for batch_index,(data,label) in enumerate(train_loader):
data,label=data.to(device),label.to(device)
optimizer.zero_grad()
output=model(data)
loss=F.cross_entropy(output,label)
loss.backward()
optimizer.step()
if batch_index%300==0:
train_loss=loss.item()
print('Train Epoch:{}\ttrain loss:{:.6f}'.format(epoch,loss.item()))
return train_loss
#测试部分的函数
def test_model(model,device,test_loader):
model.eval()
correct=0.0
test_loss=0.0
#不需要梯度的记录
with torch.no_grad():
for data,label in test_loader:
data,label=data.to(device),label.to(device)
output=model(data)
test_loss+=F.cross_entropy(output,label).item()
pred=output.argmax(dim=1)
correct+=pred.eq(label.view_as(pred)).sum().item()
test_loss/=len(test_loader.dataset)
print('Test_average_loss:{:.4f},Accuracy:{:3f}\n'.format(
test_loss,100*correct/len(test_loader.dataset)
))
acc=100*correct/len(test_loader.dataset)
return test_loss,acc
#训练开始
list=[]
Train_Loss_list=[]
Valid_Loss_list=[]
Valid_Accuracy_list=[]
#Epoc的调用
for epoch in range(1,EPOCH+1):
#训练集训练
train_loss=train_model(model,DEVICE,train_loader,optimizer,epoch)
Train_Loss_list.append(train_loss)
torch.save(model,r'E:\buttle\kaggle\save_model\model%s.pth'%epoch)
#验证集进行验证
test_loss,acc=test_model(model,DEVICE,valid_loader)
Valid_Loss_list.append(test_loss)
Valid_Accuracy_list.append(acc)
list.append(test_loss)
#验证集的test_loss
min_num=min(list)
min_index=list.index(min_num)
print('model%s'%(min_index+1))
print('验证集最高准确率: ')
print('{}'.format(Valid_Accuracy_list[min_index]))
#取最好的进入测试集进行测试
model=torch.load(r'E:\buttle\kaggle\save_model\model%s.pth'%(min_index+1))
model.eval()
accuracy=test_model(model,DEVICE,test_loader)
print('测试集准确率')
print('{}%'.format(accuracy))
#绘图
#字体设置,字符显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
#坐标轴变量含义
x1=range(0,EPOCH)
y1=Train_Loss_list
y2=Valid_Loss_list
y3=Valid_Accuracy_list
#图表位置
plt.subplot(221)
#线条
plt.plot(x1,y1,'-o')
#坐标轴批注
plt.ylabel('训练集损失')
plt.xlabel('轮数')
plt.subplot(222)
plt.plot(x1,y2,'-o')
plt.ylabel('验证集损失')
plt.xlabel('轮数')
plt.subplot(212)
plt.plot(x1,y3,'-o')
plt.ylabel('验证集准确率')
plt.xlabel('轮数')
#显示
plt.show()
最后,我是按照B站up的视频写的,所以在这儿放个链接,up的视频讲的更加详细。
https://www.bilibili.com/video/BV1aK4y1p7dyhttps://www.bilibili.com/video/BV1aK4y1p7dy https://www.bilibili.com/video/BV1aK4y1p7dy
https://www.bilibili.com/video/BV1aK4y1p7dy
欢迎交流!