讲推荐算法,就不得不提协同过滤,协同过滤是推荐系统中比较经典的推荐算法之一,我们常用的协同过滤算法共有两种,既 基于物品的协同过滤、基于用户的协同过滤;它们的效果由训练模型的数据特征选取、训练过程中的算法调优以及之后的应用场景共同决定;另外算法很难做到一招鲜吃遍天,想通过单一算法解决所有用户场景是不可能的。
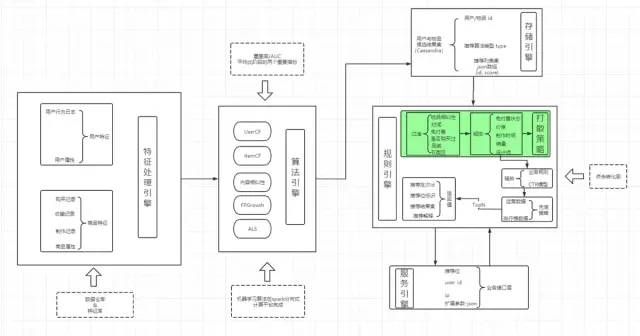
在开始讲推荐算法之前,我们先简单了解一下推荐系统的架构,对算法在推荐系统中的定位有一个初步的认知;一个完整的推荐系统会包含特征工程、召回、过滤、兜底、重排、abTest三部分,其中召回和排序模块会用到算法模型。
特征工程:决定一个算法所能达到的效果高度,不是算法本身,而是数据特征,在训练模型时选用的数据维度和数据体量往往能决定最终的模型效果。
召回:这里召回会有很多种方法,主要分离线和在线召回,如协同过滤、频繁项挖掘、用户/商品画像、热门Top、运营促销规则召回,偶尔也会用到一些基于深度学习模型的召回,如 KNN 召回。
过滤:召回之后,会进行过滤,主要是和应用场景相关,如已购商品过滤掉、同商品过滤、过期热点商品过滤掉等 。
兜底:当过滤完之后发现数据不足时需要触发兜底策略,为了快速实现效果,这里一般会采用人工配置策略。
重排:这里主要通过算法模型配合一些人工运营的规则进行二次精排序,主要使用GBDT、LR等算法对候选池列表进行CTR预估。
abTest:用来进行线上流量切分,因为种种原因,模型正式部署之前需要先在线上切分小流量进行效果验证。
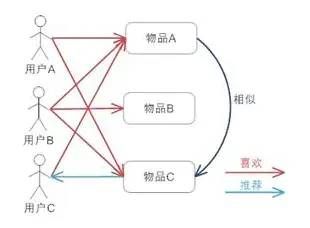
基于物品协同过滤
物品的协同过滤是基于物品相似度矩阵构建得出的,而物品相似矩阵又是基于用户对物品的偏好关系建立的:
1,计算物品间相似度,完成物品相似矩阵构建
2,通过用户对该物品相似物品的评价来反推用户对该物品的偏好程度
相似度计算公式
其中N(i)与N(j)分别为喜欢i的用户数与喜欢j的用户数,N(i)∩N(j)表示同时喜欢两者的用户数
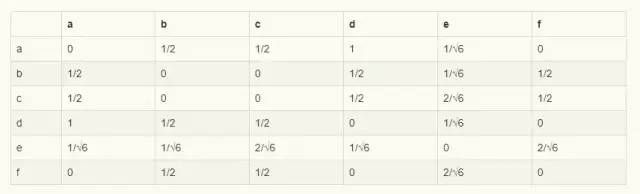
假设存在如下购买关系:
| 用户 | 商品 |
|---|---|
| A | a,c,d,e |
| B | c,e,f |
| C | a,b,d |
| D | b,e,f |
按照上述公式,求得物品间相似矩阵如下:
物品偏好计算公式
上述公式计算用户u对物品j的偏好程度,其中物品j不在用户u的偏好列表
P(u,j)为用户u对物品j的兴趣度。
W(j,i)为物品j、i的相似度。
R(u,i)为u对i的兴趣度,例如购买过代表10,加入购物车8,收藏6,点赞4,浏览1等等。也可以是用户对物品的评分,比如电影评分等。本文为了描述简单,统一设为1。
N(u)为用户u偏好物品集合。
S(j,K)为N(u)中与j最相似的K个物品集。这里我们假设k=3,模拟对用户A进行物品推荐
不在用户A偏好列表N(A)中的商品是b、f,分别计算用户A与b、f的兴趣度。
N(A) = {a, c, d, e}
S(b, 3) = {a, d, f}
S(f, 3) = {b, c, e}
R(u, i) = 1
P(A,b)=W(b,a)*R(u,a) + W(b,d)*R(u,d) + W(b,f)*R(u,f) = 0.5+0.5+0 = 1
P(A,f)=W(f,c)+W(f,e)=0.5+2/√6 > 1这里为用户推荐物品f
思考
举一个例子,在我们的商品中邀请函类的会议和会展的样例相似度很高,假设有0.8;但招生和招聘相似度仅为0.4。那么用户A历史购买5件邀请函和5件招生招聘类模板后,理应在用户下次购买前为用户推荐邀请函与招生招聘类模板各一个,但实际当中模型只会推荐邀请函而不会推荐招生招聘类模板给到用户A,因为邀请函商品间相似度大于招生招聘类;这样以来模型的召回率就会大大降低。
优化方式,将不同类别物品相似度进行归一化:
这里设置开业、庆典、会议、会展、招生、招聘、促销7类商品,相似矩阵如下:
| 开业 | 庆典 | 会议 | 会展 | 招生 | 招聘 | 促销 | |
|---|---|---|---|---|---|---|---|
| 开业 | 0 | 0.8 | 0.8 | 0.6 | 0.2 | 0.2 | 0.2 |
| 庆典 | 0.8 | 0 | 0.8 | 0.6 | 0.2 | 0.2 | 0.2 |
| 会议 | 0.8 | 0.8 | 0 | 0.6 | 0.2 | 0.2 | 0.2 |
| 会展 | 0.6 | 0.6 | 0.6 | 0 | 0.2 | 0.2 | 0.2 |
| 招生 | 0.2 | 0.2 | 0.2 | 0.2 | 0 | 0.4 | 0.4 |
| 招聘 | 0.2 | 0.2 | 0.2 | 0.2 | 0.4 | 0 | 0.5 |
| 促销 | 0.2 | 0.2 | 0.2 | 0.2 | 0.4 | 0.5 | 0 |
不难看出这是一个对称矩阵,其中邀请函相关的相似度很高,招生、招聘类的相似度偏低。假设用户A的兴趣列表N(A)={开业,庆典,招生,促销},待推荐列表{会议、会展、招聘}
继续令k=3
S(招生,3)={开业,庆典,会展}
S(会展,3)={开业,庆典,会议}
S(招聘,3)={招生,促销,开业}
P(A,会议)=W(会议,开业)+W(会议,庆典)=1.6
P(A,会展)=W(会展,开业)+W(会展,庆典)=1.2
P(A,招聘)=W(招聘,促销)+W(招聘,招生)+W(招聘,庆典)=1.1
未做归一化前,推荐商品为:会议和会展
归一化处理后,相似矩阵如下:
| 开业 | 庆典 | 会议 | 会展 | 招生 | 招聘 | 促销 | |
|---|---|---|---|---|---|---|---|
| 开业 | 0 | 1 | 1 | 1 | 0.5 | 0.4 | 0.4 |
| 庆典 | 1 | 0 | 1 | 1 | 0.5 | 0.4 | 0.4 |
| 会议 | 1 | 1 | 0 | 1 | 0.5 | 0.4 | 0.4 |
| 会展 | 0.75 | 0.75 | 0.75 | 0 | 0.5 | 0.4 | 0.4 |
| 招生 | 0.25 | 0.25 | 0.25 | 0.3 | 0 | 0.8 | 0.8 |
| 招聘 | 0.25 | 0.25 | 0.25 | 0.3 | 1 | 0 | 1 |
| 促销 | 0.25 | 0.25 | 0.25 | 0.3 | 1 | 1 | 0 |
上面的矩阵已经不再对称了。用户A对会议、会展、招聘的偏好程度如下:
P(A,会议)=W(会议,开业)+W(会议,庆典)=2
P(A,会展)=W(会展,开业)+W(会展,庆典)=1.5
P(A,招聘)=W(招聘,促销)+W(招聘,招生)+W(招聘,庆典)=2
此时推荐商品为:会议和招聘
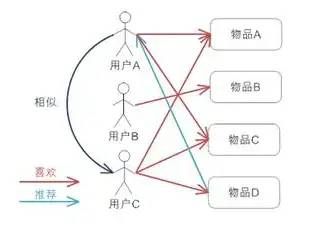
基于用户协同过滤
俗话说“物以类聚、人以群分”,拿看电影这个例子来说,如果你喜欢《蝙蝠侠》、《碟中谍》、《星际穿越》、《源代码》等电影,另外有个人也都喜欢这些电影,而且他还喜欢《钢铁侠》,则多半你也喜欢《钢铁侠》这部电影。
根据上述基本原理,我们可以将基于用户的协同过滤推荐算法拆分为两个步骤:
找到与目标用户兴趣相似的用户集合
寻找该用户未购买且相似用户有过购买的物品集,通过相似用户对物品集的打分来反推该用户对物品集的偏好程度
余弦相似度计算公式
其中N(u)∩N(v)表示用户u与用户v共同的偏好物品数量
同样假设存在如下购买关系:
| 用户 | 物品 |
|---|---|
| A | a,c,d,e |
| B | c,e,f |
| C | a,b,d |
| D | b,e,f |
为了构建用户相似矩阵,这里需要提前将上述关系转化为物品-用户倒排表:
| 物品 | 用户 |
|---|---|
| a | A, B |
| b | C, D |
| c | A, B |
| d | A, C |
| e | A, B, D |
| f | B, D |
根据上述公式求得用户相似矩阵为:
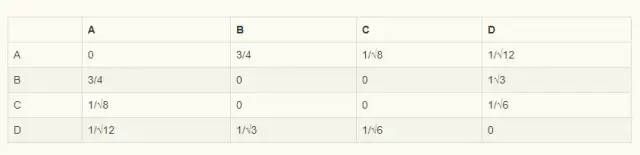
物品偏好计算公式
P(u,j)是用户u对物品i的感兴趣程度。
S(u,K)是与用户u相似度最高的K个用户集。
N(j)是与j有过关联的用户集。
W(u,v)是用户u、v相似度。
R(v,j)是用户v对物品i感兴趣的程度。例如购买过代表10,加入购物车8,收藏6,点赞4,浏览1等等。也可以是用户对物品的评分,比如电影评分等。这里为了简单,统一设为1。收藏6,点赞4,浏览1等等。也可以是用户对物品的评分,比如电影评分等。这里为了简单,统一设为1。
下面我们计算A对其他物品感兴趣的程度。
1、根据已知条件,我们得出未与A发生联系的物品有b、f。
2、设K=3。选取与物品b、f有过联系的用户集中相似度最高的3个用户。在本例中,其实只有2个用户。
P(A,b)=W(AC)+W(AD)=1/√8 + 1/√12
P(A,f)=W(AB)+W(AD)=3/4 + 1/√12显然P(A,f)值更大一些,这里将为用户A推荐物品f
思考
整个算法最关键的就是要计算用户的相似度。两用户产生联系的相同物品越多,二人的相似度就越高,但实际中并非如此,假设用户A、B、C去商场买东西:
A:10件婴儿用品,3件手办模型。
B:10件婴儿用品,3件汽车用品。
C:5件手办模型。
根据人的正常思维判断,A与C用户最为相似,因为虽然A和B都购买了大量婴儿用品,只能说明两者都是孩子父亲,并不能说明兴趣相似,而用户A和用户C都是手办爱好者。
然而通过余弦相似算法会求得用户A和用户B相似最高,因为在他们的购买关系中有大量相同商品。
为了弱化热门商品带来的影响,上述公式可改写为:
i是用户u、v有过共同关联的物品。
N(i)是与物品i有过关联的用户数。
小结
| item-cf | user-cf | |
|---|---|---|
| 定义 | 推荐用户之前感兴趣物品的相关物品 | 推荐与该用户兴趣相同的其他用户喜欢的物品 |
| 特点 | 个性化(京东个性化推荐) | 推荐的物品新颖性强,且模型稳定度低 |
| 性能 | 适合商品较少的数据集 | 适合用户较少的数据集(可优化) |
| 场景 | 推荐位多在详情页 | 多在首页或用户feed使用 |
注:两种推荐算法都没有考虑物品本身的属性和特征,所以在用户的推荐列表中经常会看到一些意想不到的结果,而研发对于这些结果的出现往往无法给出直观的解释
哈利波特问题
也就是我们常说的热门商品问题;举个栗子,我们不能因为川菜厨师和粤菜厨师都买了油盐酱醋,就给粤菜厨师推荐火锅底料吧。
通过取对数对热门商品进行降权处理,有点类似于tf•idf中的idf值,即一个关键词如果出现在大部分文章的内容中,那么这个关键词将不具备对文章的区分性。
拓展思考
一般情况下我们优化提升的目标不止一个,如点击率、订单量、制作量等;单一模型几乎不可能胜任所有的指标提升,这个时候就需要我们平衡取舍或者采用多模型融合技术进行效果提升。
推荐阅读:《阿里巴巴B2B电商算法实战》
送三本书:公众号回复"抽奖",阅读到最后的可以看到这个彩蛋????。

推荐语:本书是阿里巴巴CBU技术部(1688.com)深耕B2B电商15年的经验总结。本书聚焦营销平台商业形态背后的算法和技术能力,试图从技术和商业互为驱动的视角阐述技术如何赋能业务,并结合阿里巴巴集团在基础设域和算法创新上的沉淀,打造出智能B2B商业操作系统。
