【实践】美团外卖图谱推荐比赛冠军经验分享:从多领域优化到AutoML框架
猜你喜欢
0、【免费下载】2021年12月热门报告盘点1、如何搭建一套个性化推荐系统?2、快手推荐系统精排模型实践.pdf3、全民K歌推荐系统算法、架构及后台实现4、微博推荐算法实践与机器学习平台演进5、腾讯PCG推荐系统应用实践6、强化学习算法在京东广告序列推荐场景的应用7、飞猪信息流内容推荐探索8、华为项目管理培训教材9、预训练模型在华为信息流推荐中的实践
本文结合笔者在7次Kaggle/KDD Cup中的冠军经验,围绕多领域建模优化、AutoML技术框架以及面对新问题如何分析建模等三个方面进行了介绍。希望能够帮更多同学了解比赛中通用的高效建模方法与问题理解思路。
1 背景与简介
2 多领域建模优化
2.1 推荐系统问题
2.2 时间序列问题
2.3 自动化机器学习问题
3 AutoML技术框架
3.1 自动化框架概述
3.2 自动化特征工程
3.3 自动化模型优化
3.4 AutoML框架近期实战:MDD Cup 2021美团外卖图谱推荐比赛冠军方案
4 通用建模方法与理解
4.1 建模框架与方法
4.2 同工业界方法联系
4.3 建模关键理解
总结
1 背景与简介
反馈快速、竞争激烈的算法比赛是算法从业者提升技术水平的重要方式。从若干行业核心问题中抽象出的算法比赛题目具有很强的实际意义,而比赛的实时积分榜促使参加者不断改进,以试图超越当前的最佳实践,而且获胜方案对于工业界与学术界也有很强的推动作用,例如KDD Cup比赛产出的Field-Aware Factorization Machine(FFM)算法[1]、ImageNet比赛产出的ResNet模型[2]在业界都有着广泛的应用。
美团到店广告质量预估团队在美团内部算法大赛MDD Cup中获得了第一名,受大赛组委会的邀请,希望分享一些比较通用的比赛经验。本文是笔者7次Kaggle/KDD Cup冠军经验(如下图1所示)的分享,希望能帮助到更多的同学。

大家都知道,Kaggle/KDD Cup的比赛均为国际顶级赛事,在比赛圈与工业界有着很大的影响力。具体而言,Kaggle是国际上最大的顶级数据挖掘平台,拥有全球几十万用户,通过高额奖金与分享氛围产出了大量优秀算法方案,例如Heritage Health奖金高达三百万美元。目前,Kaggle比赛在艾滋病研究、棋牌评级和交通预测等方面均取得了突出成果,得益于此,Kaggle平台后来被Google公司收购。
ACM SIGKDD (国际数据挖掘与知识发现大会,简称 KDD)是数据挖掘领域的国际顶级会议。KDD Cup比赛是由SIGKDD主办的数据挖掘研究领域的国际顶级赛事。从1997年开始,每年举办一次,是目前数据挖掘领域最具影响力的赛事。该比赛同时面向企业界和学术界,云集了世界数据挖掘界的顶尖专家、学者、工程师、学生等参加,为数据挖掘从业者们提供了一个学术交流和研究成果展示的平台。
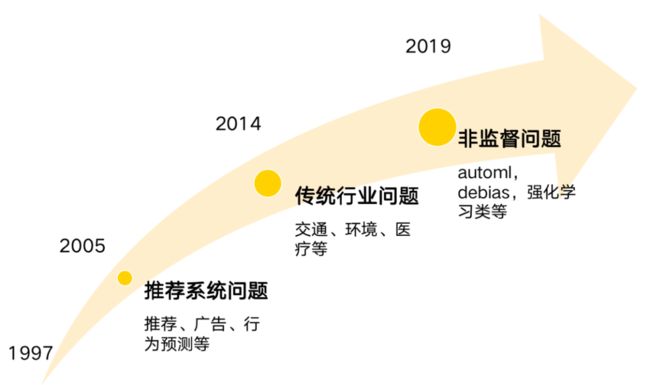
通过分析不难发现,KDD Cup举办20年来,一直紧密结合工业界前沿与热点问题,演进主要分为三个阶段。第一阶段从2002年左右开始,专注于互联网的热点推荐系统方面问题,包括推荐、广告,行为预测等;第二阶段聚焦在传统行业问题,比较关注教育、环境、医疗等领域;而在第三阶段,自2019年以来,重点关注非监督问题,例如AutoML、Debiasing、强化学习等问题,这类比赛的共同特点是通过以前方法难以解决现有的新问题。这三个阶段趋势也一定程度反应着当前工业界与学术界的难点与重点,无论从方式、方法,还是从问题维度,都呈现出从窄到宽,从标准向非标准演进的趋势。
本文会先介绍笔者的7次KDD Cup/Kaggle比赛冠军的方案与理解,问题涉及推荐、广告、交通、环境、人工智能公平性等多个领域问题。接着会介绍在以上比赛中发挥关键作用的AutoML技术框架,包括自动化特征工程,自动化模型优化,自动化模型融合等,以及如何通过该技术框架系统性建模不同的问题。最后再介绍以上比赛形成的通用方法,即面对一个新问题,如何进行分析、理解、建模、与挑战解决、从而实现问题的深度优化。
本文主要面向以下两类读者,其他感兴趣的同学也欢迎了解。
算法比赛爱好者,希望理解国际数据挖掘顶级比赛冠军方案的方法与逻辑,取得更好的名次。
工业界工程师与研究员,借鉴比赛方法,应用于实际工作,取得更优的结果。
2 多领域建模优化
本部分将我们将以上比赛分为三个部分进行方案介绍,第一部分为推荐系统问题;第二部分为时间序列问题,跟第一部分的重要差别在于预测的是未来的多点序列,而非推荐系统的单点预估;第三部分为自动化机器学习问题,该问题比赛输入不为单一数据集,而是多问题的多数据集,并且在最终评估的b榜数据集问题也是未知的。因此,对于方案的鲁棒性要求非常高。如表1所示,后续将具体介绍七个比赛赛道的获胜方案,但会合并为五个核心解决方案进行具体的介绍。

2.1 推荐系统问题
本节主要介绍Kaggle Outbrain Ads Click Prediction和KDD Cup 2020 Debiasing比赛。二者任务都是面向用户下一次点击预估问题,但因为应用场景与背景的不同,存在着不同的挑战:前者的数据规模庞大,涉及到数亿个用户在千级别数量异构站点上的数十亿条浏览记录,对模型优化、融合有着严格的要求;后者则尤为关注推荐系统中的偏差问题,要求参赛选手提出有效的解决方案,来缓解选择性偏差以及流行度偏差,从而提高推荐系统的公平性。本节将分别介绍这两场比赛。
Kaggle Outbrain Ads Click Prediction:基于多层级多因子的模型融合方案
竞赛问题与挑战:竞赛要求在Outbrain网页内容发现平台上,预估用户下一次点击网页广告,具体参考:Kaggle Outbrain比赛介绍详情[26]。参赛选手会面对以下两个重要挑战:
异构性:平台提供需求方平台(DSP)广告投放服务,涉及到用户在数千个异质站点上的行为刻画。
超高维稀疏性:特征高维稀疏,数据规模庞大,包含了7亿个用户、20亿次浏览记录。
基于多层级多因子的模型融合方案:针对本次赛题的挑战,我们队采用了基于多层级多因子的模型融合方案来进行建模。一方面对于异构站点行为,单一模型不易于全面刻画,另一方面,亿级别的数据规模给多模型的分别优化带来了较大的空间。由于FFM具有强大的特征交叉能力以及较强的泛化能力,能更好地处理高维稀疏特征。因此,我们选择该模型作为融合基模型的主模型。模型融合通过不同模型学习到有差异性的内容,从而有效挖掘用户在不同站点上的异质行为。模型融合的关键是产生并结合“好而不同”的模型[3][4]。基于多层级多因子的模型融合方案首先通过模型差异性、特征差异性多个角度来构造模型之间的差异性,然后通过多层级以及使用基学习器的多特征因子(模型pCTR预估值、隐层表征)进行融合:
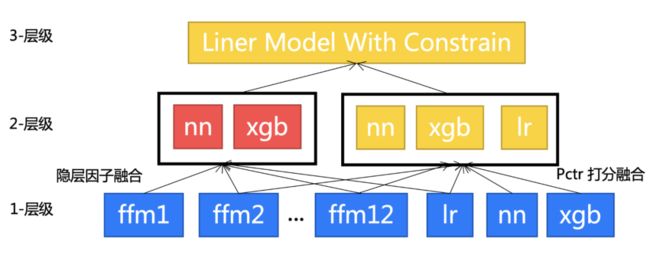
具体地,如上图3所示。第一层级的目的是构建出有差异性的单个模型,主要通过不同类型的模型在用户最近行为、全部行为数据以及不同特征集合上分别进行训练,来产生差异性。第二层级则通过不同单个模型的组合进一步产生差异性,差异性的提升来源于两个方面,分别是模型组合方式的不同(用不同模型,根据单模型特征进行打分)以及用于模型组合的特征因子的不同,这里特征因子包括模型的打分以及模型中的隐层参数。第三层级则是考虑如何将不同融合结果组合在一起。由于划分出来的验证数据集较小,如果使用复杂非线性模型往往容易过拟合。所以这里使用了一个基于约束的线性模型来获得第二层级模型的融合权重。
上述方案同我们业务中模型相比,采用更多的模型融合,在取得高精度的同时产生了更高的开销,而在实际业务中要更加注重效果与效率的平衡。
KDD Cup 2020 Debasing:基于i2i多跳游走的Debiasing方案
竞赛问题与挑战:竞赛是以电子商务平台为背景,预估用户下一次点击的商品。并围绕着如何缓解推荐系统中的选择性偏差以及流行度偏差进行展开,具体参考:KDD Cup 2020 Debiasing比赛介绍详情[27]。推荐系统中的偏差问题有很多,除了上述两种偏差,还有曝光偏差、位次偏差等等[5][6]。我们团队之前也对位次偏差进行了相关研究[7]。而本次竞赛为了更好地衡量推荐系统对历史低热度商品的推荐效果,选手的成绩主要采用NDCG@50_half指标进行排名。该指标是从整个评测数据集中取出一半历史曝光少的点击商品,由于是低热度且有被点击的商品,可以跟更好的评估偏差问题。本次比赛包含了以下挑战:
赛题只提供点击数据,构造候选集时需要考虑选择性偏差问题。
不同商品热度差异大,商品历史点击次数呈现一个长尾分布,数据存在严重的流行度偏差问题,并且评估指标 NDCG@50_half 用于考察低热度商品的排序质量。
基于i2i游走的Debiasing排序方案:我们的方案为基于i2i建模的排序框架。如图所示,整体流程包含四个阶段:i2i构图与多跳游走、i2i样本构建、i2i建模以及u2i排序。前两个阶段解决了选择性偏差问题,后两个阶段则侧重于解决流行度偏差问题。
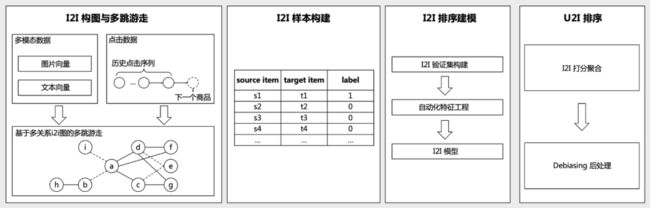
第一个阶段是基于用户行为数据和商品多模态数据构建i2i图,并在该图上多跳游走生成候选样本。这种方式扩大了商品候选集,更好地近似系统真实候选集,缓解了选择性偏差。
第二个阶段是根据不同i2i关系计算i2i候选样本的相似度,从而决定每种i2i关系下候选样本的数量,最终形成候选集。通过不同候选的构造方法,探索出更多有差异的候选商品,可以进一步缓解选择性偏差问题。
第三个阶段包括基于i2i样本集的自动化特征工程,以及使用流行度加权的损失函数进行消除流行度偏差的建模。自动化特征工程中包含了商品多模态信息的刻画,这类信息能够反应商品在热度信息以外的竞争关系,能够一定程度上缓解流行度偏差问题。而流行度加权的损失函数定义如下:
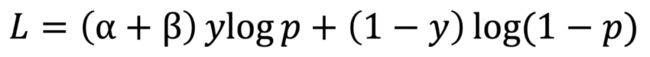
其中,参数α与流行度成反比,来削弱流行商品的权重,从而消除流行度偏差。参数β是正样本权重,用于解决样本不平衡问题。
第四个阶段首先将i2i打分通过Max操作进行聚合,突出打分集合中低热度商品的高分信号,从而缓解流行度偏差问题。然后对商品列表的打分结合商品热度进行调整处理,进而缓解流行度偏差问题。
关于该比赛的更多细节,大家可以参考《KDD Cup 2020 Debiasing比赛冠军技术方案及在美团的实践》一文。
2.2 时间序列问题
时序系列问题:时间序列问题相比于推荐系统问题的有较大差异。在任务上,推荐系统预测的是未来单个点,而时间序列预测未来多个点;在数据上,推荐系统通常包含用户、商品、上下文等多维信息,时间序列通常包含时间空间上变化的数值序列信息。
时间序列竞赛:在本文中,时间序列竞赛主要介绍KDD Cup 2018 Fresh Air和KDD Cup 2017 HighWay Tollgates Traffic Flow Prediction。它们都是时间序列问题,前者是预测未来两天的污染物浓度以及变化,后者是预测未来几个小时高速交通情况和变化。它们的共同点一是传统行业问题,实际意义强;二是存在各种突变性、稳定性低;三是都涉及到多地域、多空间问题,需结合时空进行建模。它们的异同点是污染物浓度突变需要一个短期时间才能发生,数据在突变时存在一定规律性,但交通突变具有强偶发性,交通道路容易受到偶发性车祸、偶发性地质灾害等影响,数据不会呈现出明显的规律性。
KDD Cup 2018 Fresh Air:基于时空门控DNN和Seq2Seq的空气质量预测方案
竞赛问题及挑战:竞赛目标是预测北京和伦敦48个站点在未来48小时里PM2.5/PM10/O3的浓度变化,具体参考:KDD Cup 2018比赛介绍详情[28]。参赛选手需要解决以下两个挑战:
时序性:预测未来48小时的污染浓度情况,实际污染物浓度存在突变的情况。如图5所示,站点2在05-05以及05-06、05-07之间存在大量的波动和突变。
空间性:不同站点上污染物浓度有明显差异,并且和站点之间的拓扑结构相关联。如图所示,站点1、2的波形有较大差别,但是在05-07产生了相同的凸起。
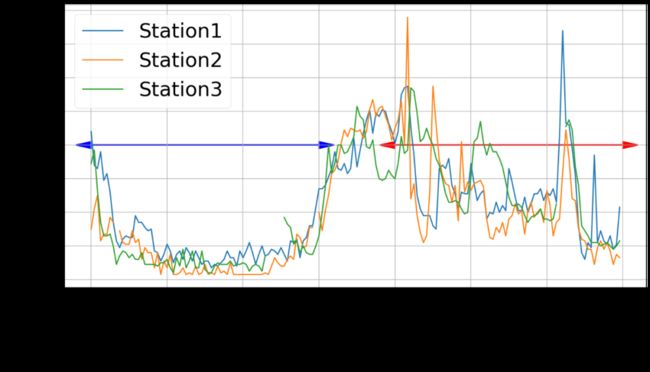
基于Spatial-temporal Gated DNN与Seq2Seq的模型融合方案[9]:为了强化时间序列和空间拓扑的建模,我们引入了Spatial-temporal Gated DNN与Seq2Seq两个模型,并与LightGBM一起构建模型融合方案,具体如下:
(1)Spatial-temporal Gated DNN:对于时序问题而言,由于未来预测临近时间点的统计特征值差异较小,直接使用DNN模型会使得不同小时和站点的预测值差异性小,因此我们在DNN中引入Spatial-temporal Gate来突出时空信息。如下图6所示,Spatial-temporal Gated DNN采用了双塔结构,拆分了时空信息和其他信息,并且通过门函数来控制和强调时空信息,最终能够提高模型对时空的敏感度,实验中发现引入swish激活函数f(x) = x · sigmoid(x)能提升模型精度。
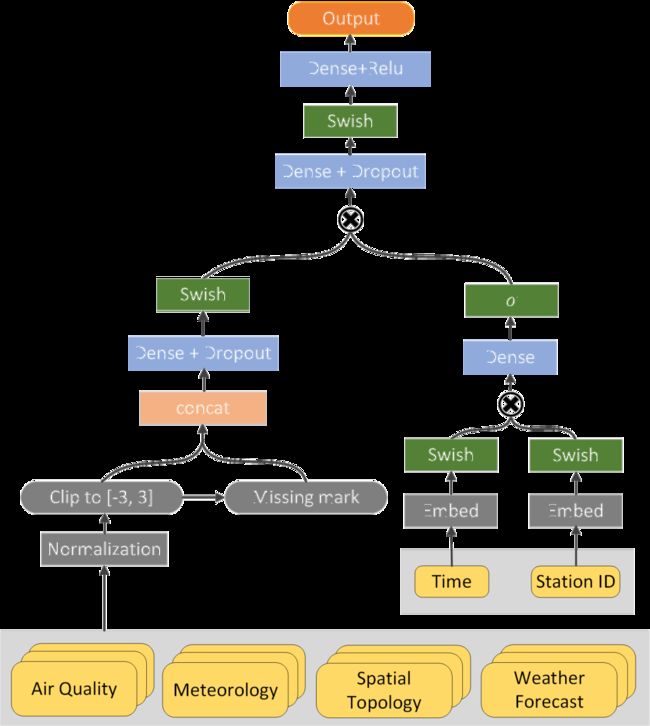
(2)Seq2Seq:尽管Spatial-temporal Gated DNN相比DNN对时空信息进行了强化,但是它们的数据建模方式都是将样本的历史数据复制48份,分别打上未来48小时的标签,相当于分别预测48小时的污染浓度值。这种方式其实和时间序列预测任务有所脱离,失去了时间连续性。而Seq2Seq建模方式可以很自然地解决这一问题,并且取得了不错的效果。下图7是本次比赛中,我们采用的Seq2Seq模型结构。针对时序性挑战,历史天气特征通过时间前后组织成序列输入到编码器当中,解码器依赖于编码结果以及未来天气预报特征进行解码,得到48小时的污染物浓度序列。未来天气预报信息对齐到解码器每个小时的解码过程中,解码器可以通过天气预报中的天气信息(比如风级、气压等)来有效预估出突变值。针对空间性挑战,方案在模型中加入站点嵌入以及空间拓扑结构特征来刻画空间信息,在模型中和天气信息进行拼接以及归一化,从而实现时空联合建模。

(3)模型融合:我们队采用了Stacking融合的方式,单个学习器通过不同模型、数据、建模方式来构建差异性。LightGBM模型使用了天气质量、历史统计、空间拓扑等特征,Spatial-temporal Gate则是引入了门结构,强化了时空信息。Seq2Seq利用序列到序列的建模方式,刻画了序列的连续性、波动性。最后使用了基于约束的线性模型将不同的单个学习器进行融合。
更多详情,大家可参考SIGKDD会议论文:AccuAir: Winning Solution to Air Quality Prediction for KDD Cup 2018。
KDD Cup 2017 Traffic Flow Prediction:基于交叉验证降噪与多损失融合的高稳定性交通预测方案
竞赛问题及挑战:竞赛目标是以20分钟为时间窗口,给定前2小时高速公路入口到关卡的行驶状况,预测未来2小时的行驶状况,具体可参考:KDD Cup 2017比赛介绍详情[29]。竞赛根据行驶状况的不同,分为了行驶时间预测和交通流量预测两个赛道。参赛选手需要解决以下两个挑战:
数据小、噪声多。如下图8所示,框中时间段的数值分布和其他时间段的分布有明显的差异。

极值对结果影响大,评估指标使用了MAPE,如下式,其中 At 代表实际值,Ft 代表预测值,当实际值为较小值(特别为极小值)时,这一项对整个和式的贡献拥有很大的权重。

基于交叉验证降噪的极值点优化模型融合方案:
(1)基于交叉验证的降噪,由于在线仅能进行一天一次的提交,并且最终的评测会由A榜测试集切到B榜测试集,并且由于A榜数据集小在线评测指标存在不稳定性,故而离线迭代验证的方式就显得尤为重要。为了能使离线迭代置信,我们采用两种验证方式进行辅助,第一种是下一天同时间段验证,我们在训练集最后M天上对每一天都取在线同一时间段的数据集,得到M个验证集。第二种是N-fold天级采样验证,类似N-fold交叉验证,我们取最后N天的每一天数据作为验证集,得到N个验证集。这两种方法共同辅助模型离线效果的迭代,保证了我们在B榜上的鲁棒性。
(2)极值点问题优化和模型融合:由于MAPE对于极值较敏感,我们在标签、损失、样本权重等不同方面分别进行多种不同处理,例如标签上进行Log变换和Box-Cox变换,Log变换是对标签进行Log转换,模型拟合后对预估值进行还原,这样能帮助模型关注于小值同时更鲁棒,损失使用MAE、MSE等多种,样本权重上利用标签对样本进行加权等,我们在XGBoost、LightGBM、DNN上引入这些处理生成多个不同模型进行模型融合,优化极值点问题,达到鲁棒效果。
备注:特别感谢共同参加KDD Cup 2017的陈欢、燕鹏、黄攀等同学。
2.3 自动化机器学习问题
自动化机器学习问题[10]主要包括KDD Cup 2019 AutoML和KDD Cup 2020 AutoGraph比赛。该类问题,一般具有以下三个特性:
数据多样性强:15+个数据集,来源于不同领域问题,且不会标识数据来源,要求选手设计的自动化机器学习框架能够兼容多领域的数据,并对不同领域数据做出一定的适配。
自动化的鲁棒性:公共排行榜与私有榜评测数据不一样,最终评分按照多个数据集的平均排名/得分得到,要求能够在不曾见过的数据集上得到鲁棒的结果。
性能限制:与现实问题搜索空间有较大对应,需要在有限时间和内存上求解。
KDD Cup 2020 AutoGraph:基于代理模型的自动多层次图学习优化方案
竞赛问题及挑战:自动化图表示学习挑战赛(AutoGraph)是第一个应用于图结构数据的AutoML挑战,详情请见KDD Cup 2020 AutoGraph 比赛介绍[30]。竞赛选择图结点多分类任务来评估表示学习的质量,参与者需设计自动化图表示学习[11-13]解决方案。该方案需要基于图的给定特征、邻域和结构信息,高效地学习每个结点的高质量表示。比赛数据从真实业务中收集,包含社交网络、论文网络、知识图谱等多种领域共15个,其中5个数据集可供下载,5个反馈数据集评估方案在公共排行榜的得分,剩余5个数据集在最后一次提交中评估最终排名。
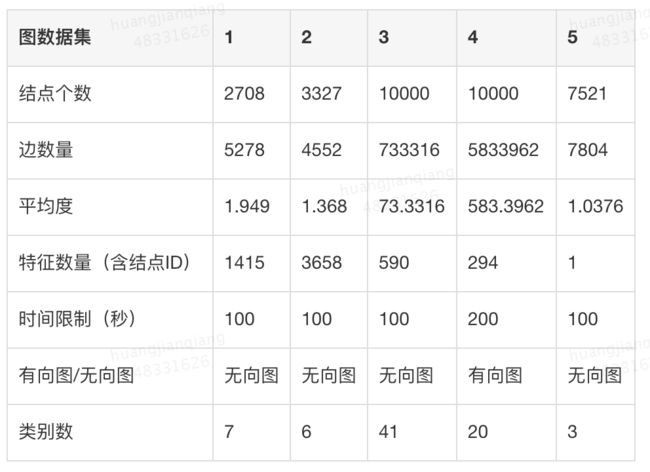
每个数据集给予了图结点id和结点特征,图边和边权信息,以及该数据集的时间预算(100-200秒)和内存算力(30G)。每个训练集随机将划分40%结点为训练集,60%结点为测试集,参赛者设计自动化图学习解决方案,对测试集结点进行分类。每个数据集会通过精度(Accuracy)来确定排名,最终排名将根据最后5个数据集的平均排名来评估。综上,本次比赛需要在未见过的5个数据集上直接执行自动化图学习方案,参赛者当时面临着以下挑战:
图模型具有高方差、稳定性低等特点。
每个数据集都有严格的时间预算和内存算力限制。
基于代理模型的自动化多层次模型优化[14]
多类别层次化图模型优化:
(1)候选图模型的生成:现实世界中的图通常是多种属性的组合,这些属性信息很难只用一种方法捕捉完全,因此,我们使用了基于谱域、空域、Attention机制等多种不同类型的模型来捕捉多种属性关系。不同模型在不同数据集上效果差异较大,为了防止后续模型融合时加入效果较差的模型,会对GCN、GAT、APPNP、TAGC、DNA、GraphSAGE、GraphMix、Grand、GCNII等候选模型进行快速筛选,得到模型池。
(2)层次模型集成:这部分共包含两个维度的集成。第一层为模型自集成,为了解决图模型对初始化特别敏感,同种模型精度波动可达±1%的问题,采用了同模型的自集成,同时生成多个同种模型,并取模型预测的平均值作为该种模型的输出结果,成功降低了同种模型方差,提高了模型在不同数据集上的稳定性。第二层为不同模型集成,为了有效地利用来自本地和全球邻域的信息,充分捕获图的不同性质,我们采用加权集成了不同种类的图模型,进一步提高性能。同时针对在参数搜索阶段,需要同时优化模型内参数α,以及多种模型加权集成参数β,使用模型集成参数和模型内参数通过互迭代的梯度下降进行求解,有效提升了速度。
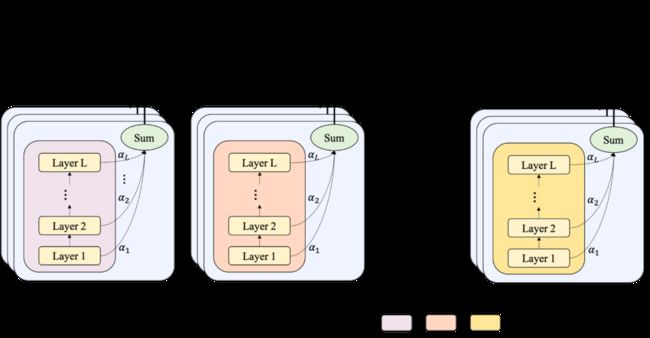
基于代理模型与最终模型的两阶段优化:数据集采样,对子图根据Label进行层次采样,减少模型验证时间;代理模型与Bagging,计算多个较小隐层模型的平均结果,快速对该类模型进行评估。使用Kendall Rank和SpeedUp平衡准确度与加速倍率,得到合适的代理模型。最终通过代理模型得到了最优的超参数,然后再对最终的大模型在搜索好的参数上进行模型训练。
具体详情,大家可参考团队ICDE 2022论文,AutoHEnsGNN: Winning Solution to AutoGraph Challenge for KDD Cup 2020。
3 AutoML技术框架
3.1 自动化框架概述

经过上述的多场比赛,团队在多领域建模中不断总结与优化,抽象出其中较为通用的模块,总结得到针对数据挖掘类问题时的一套较为通用的解决方案——AutoML框架。该框架包含数据预处理,自动化特征工程[15]和自动化模型优化[16-20]三个部分。其中数据预处理部分主要负责特征分类、数据编码、缺失值处理等常见的基础操作,不过多展开。主要针对AutoML框架的自动化特征工程和自动化模型优化两个部分进行详细介绍。
3.2 自动化特征工程
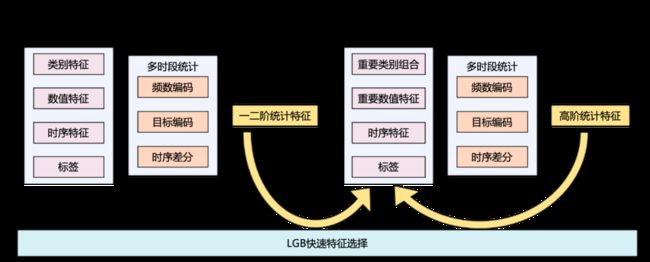
特征工程是机器学习中至关重要的工作,特征的好坏直接决定了模型精度的上限。目前常见的方式是人工手动对特征进行组合与变换,但人工特征挖掘存在速度较慢、无法挖掘全面等问题。因此,设计全面挖掘的自动化特征工程能够比较好地解决上述问题,自动化特征工程主要包含三个部分:
一、二阶特征算子:对数据的基础操作,可以得到更为复杂的高阶特征。特征算子包含三个,频数编码是指对于类别型特征在样本中次数、nunique等值的统计。目标编码指对数值型特征进行均值、求和、最大最小、百分位等操作。时序差分是指对于对时间特征进行差分处理。一阶算子使用一个实体计算,二阶算子使用二个实体计算,如用户在某品类下的订单数量,使用了用户与品类两个实体。
快速特征选择:因为自动化特征工程是针对全部实体依次按照不同特征算子进行的笛卡尔积组合,会产生大量的无效特征,故需要进行快速特征选择。使用LightGBM模型快速识别有效特征及无用特征,从指标提升及特征重要性角度考虑,裁剪掉没用的特征,同时标识重要特征与其他特征再次进行更为高阶的组合。
高阶特征算子:基于一、二阶特征算子组合构建的新特征,进一步与其他特征进行高阶组合,基于K阶(K>=1)的K+1高阶组合循环迭代,能够产出大量人为考虑不足的高阶特征。
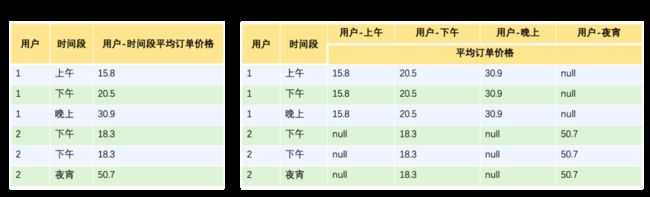
高阶特征算子按多实体结果是否完全匹配,分为Match方式——匹配全部实体,All方式——匹配部分实体,得到另一实体的全部值的计算结果,这样两种特征产出方式。下图中举例说明,Match方式匹配用户与时间段两个实体,得到用户在该时间段的平均订单价格;All方式则只匹配用户,得到用户在所有时间段的平均订单价格。
相较于DeepFM、DeepFFM等算法,自动化特征工程具有三个方面的优势。首先在存在多表信息的情况下,容易利用非训练数据的信息,如在广告场景中,通过特征可以利用自然数据的信息,相比直接使用自然数据训练,不容易产生分布不一致等问题;其次,只通过模型自动交叉学习,对于某些强特征交叉没有手动构造学习得充分,许多显示交叉特征如用户商品点击率等往往有较强的业务意义,让模型直接感知组合好的特征往往比自动学习特征间的关系更为简单;第三方面对于许多高维度稀疏ID特征,如亿级别以上的推荐或广告场景中,DeepFM、DeepFFM对于这些特征的学习很难充分,自动化特征工程能给这些稀疏ID构造很强的特征表示。
3.3 自动化模型优化

基于重要度的网格搜索:在我们框架中采用的是全局基于重要度按照贪心的方式进行搜索,加快速度;得到的最优结果再进行小领域更详细网格搜索,缓解贪心策略导致的局部最优。根据以往比赛经验,总结不同模型的超参重要性排序如下:
LightGBM:学习率>样本不平衡率>叶子数>行列采样等。
DNN:学习率>Embedding维度>全连接层数和大小。值得一提的是,超参搜索在整个迭代过程中会进行多次,同时迭代前期与迭代后期参数搜索策略也有所不同,迭代前期,一般会选择更大的学习率,更小Embedding维度和全连接层数等,降低模型参数量加快迭代速度,而在后期则选择更多参数,获得更好的效果。
模型融合:模型融合的关键点在于构造模型间的差异性,LightGBM和DNN的模型本身差异性较大,同种模型中差异性主要体现在,数据差异、特征差异、超参差异三个方面。数据差异主要通过自动化行采样实现,自动生成不同数据采样的模型;特征差异通过自动化列采样,生成特征采样的模型;超参差异通过高优参数扰动生成,在最优局部进行参数组网格局部扰动。模型融合方法一般Blending、Stacking或简单Mean Pooling等,融合前进行需要进行模型粒度剪枝(去除效果较差的模型避免影响融合效果)与正则化。
3.4 AutoML框架近期实战:MDD Cup 2021美团外卖图谱推荐比赛冠军方案
在2021年8-9月美团举行的内部算法比赛MDD Cup 2021中,美团到店广告平台质量预估团队应用了AutoML框架并获得了冠军。下面结合这场比赛,介绍框架在具体问题中的应用。
MDD Cup 2021需要参赛者根据用户、商家在图谱中的属性、用户的历史点击、实时点击以及下单行为,预测下次购买的商家。包含四周的135万个订单行为,涉及20万个用户,2.9万个商家,17.9万个菜品,订单关联菜品数据共438万条,构成知识图谱。使用Hitrate@5作为评价指标。
数据预处理阶段:进行特征分类、异常值处理、统一编码等操作。主要涉及用户(用户画像特征等)、商家(品类、评分、品牌等)、菜品(口味、价格、食材等)三种实体数据及点击、购买(LBS、价格、时间等)两类交互数据,对原始数据进行特征分类、数据编码、缺失值处理等常见预处理操作。
自动化特征工程:一、二阶特征算子,首先对于类别、数据、时序、标签四类原始特征,按照可抽象的三种实体及两类交互数据进行一、二阶特征交叉,运用频数编码、目标编码与时序差分算子操作,在多时段上统计得到一、二阶统计特征。举例说明,如频数编码可计算用户点击某商家的次数、用户购买商家品类的nunique值,用户在某场景的下单数量等。目标编码可计算用户的平均订单价格,用户点击次数最多的商家品类等。时序差分可计算如用户购买某口味菜品的平均时间差等。多时段统计则意味着上述特征均可在不同时段上计算得到。
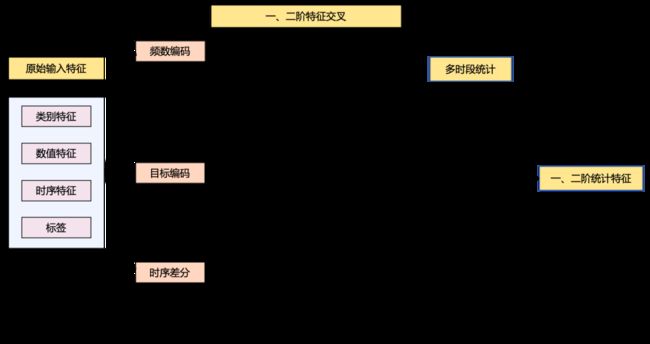
快速特征选择,上述自动产出的一、二阶统计特征数量共有1000+,其中存在大量无效特征,故使用LightGBM模型,从指标提升与重要性角度进行特征筛选与重要标识。如用户 x 菜品口味的特征没什么效果,进行筛除;用户最常购买的价格区间则很有效果,标识为重要特征进行高阶组合。
高阶特征算子,基于一、二阶特征算子组合构建的新特征,可以作为输入进行高阶特征组合。这里值得一提的是,高阶特征组合存在两种形式,第一种原始特征的更高阶组合,如用户在某个商家中最喜欢的菜品口味,结合三个实体,并不需要额外的运算,第二种需使用一、二阶新特征,其中频数编码的结果可以直接使用,目标编码与时序差分需要先进行数值分桶操作转换为离散值后才可使用,如用户订单价格区间的众数 x 商家订单价格平均值的分桶的联合count。循环进行特征组合与筛选后就得到了最终的特征集。
自动化模型优化:模型部分使用了LightGBM和DIN的融合方案,迭代过程中多次进行了自动超参搜索,通过自动化行、列采样及最优参数局部扰动构造了具有差异性的多个模型,融合得到最终的结果。
4 通用建模方法与理解
本节会就比赛的通用建模方法进行介绍,即面对一个新问题,如何进行快速高效的整体方案设计。
4.1 建模框架与方法
在面对新问题时,我们主要将技术框架分为以下三个阶段,即探索性建模、关键性建模、自动化建模。三个阶段具有逐渐深化,进一步补充的作用。
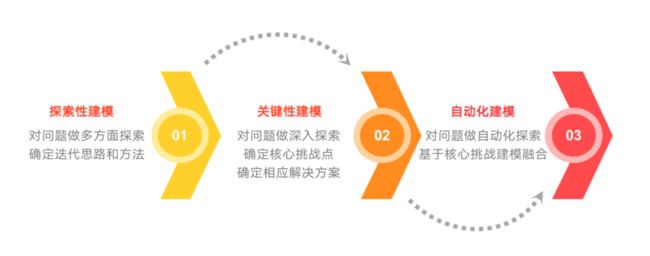
探索性建模:比赛前期,首先进行问题理解,包括评估指标与数据表理解,然后进行基础的模型搭建,并线上提交验证一致性。在一致性验证过程中往往需要多次提交,找到同线上指标一致的评估方式。探索性建模的核心目标是要找到迭代思路与方法,所以需要对问题做多方面探索,在探索中找到正确的方向。
一般在非时序问题,采用N-fold方法构造多个验证集,并可以灵活变换生成种子,得到不同的集合。而在时序问题,一般会采用滑窗方式,构造同线上提交时间一致的验证集,并可以向前滑动k天,来构造k个验证集。在多个验证集评估中,可以参考均值,方差,极值等参考指标综合评估,得到同线上一致的结果。
关键性建模:比赛中期,会就关键问题进行深挖,达成方案在榜单Top行列,在问题理解方面,会尽可能就评估方式进行损失函数自定义设计。
分类问题优化,可以结合Logloss、AUC Loss[21]、NDCG Loss等不同损失函数进行Mix Loss设计。而回归问题的损失函数设计要更复杂,一方面可以结合平方误差,绝对值误差等进行损失函数设计,另一方面可以结合Log变换,Box-Cox变换等解决回归异常值等问题。
自动化建模:比赛后期,由于基于人的理解一方面在细节与角度有盲区,另一方面较难进行抽象关系的建模,所以我们会采用自动化建模进行补充。如下图18所示,先基于关系型多表输入,进行自动化关联,然后通过生成式自动化特征工程构建大量特征,再进行特征选择与迭代,然后基于模型输入进行自动化超参搜索与模型选择,最终基于多模型进行自动化融合构建,将生成的多元化模型关系进行选择与赋权。
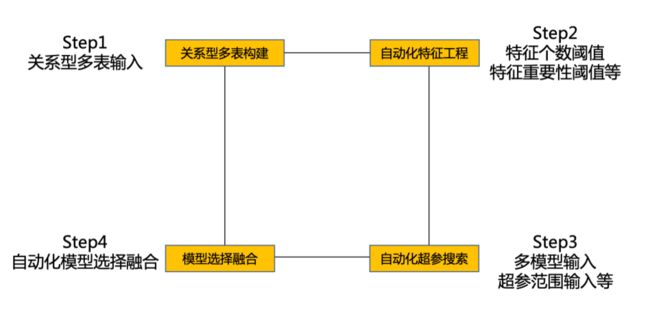
自动化建模一般采用如图18的框架,先进行多表关联,然后基于先扩展后过滤的逻辑进行特征选择,下一步基于精选特征与多个超参范围进行超参搜索,最后采用XGBoost[22]、LightGBM、DNN、RNN、FFM等不同模型进行自动化模型融合。
4.2 同工业界方法联系
算法比赛相对于工业界实际情况而言,一个重要区别是工业界涉及线上系统,在工程方面性能的挑战更大,在算法方面涉及更多的线上线下效果一致性问题。因此算法比赛会在模型复杂度、模型精度更进一步,在算法比赛中也产出了ResNet、Field-aware Factorization Machine(FFM)、XGBoost等算法模型,广泛应用于工业界实际系统。
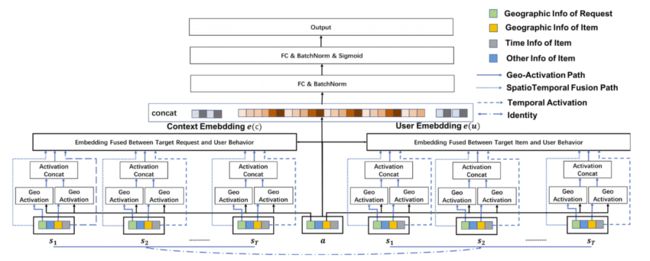
在空气质量预测中,我们采用了时空结合的Spatial-temporal Gated DNN网络进行有效建模,同空气质量问题相接近,在美团的实际业务中也面临着时空相结合的建模问题,以用户行为序列建模为例。我们对用户的历史时空信息和当前时空信息进行了充分的建模和交互[24]。我们分辨出用户行为的三重时空信息,即:用户点击发生时的时间、用户请求发出的地理位置、用户所点击的商户的地理位置。
基于上述三重时空信息,我们提出Spatio-temporal Activator Layer(如图19):三边时空注意力机制神经网络来对用户历史行为进行建模,具体通过对请求经纬度信息、商户经纬度信息和请求时间的交互进行学习。针对空间信息交叉,我们进一步采用地理位置哈希编码和球面距离相结合的方式;针对时间信息交叉,我们也采用绝对与相对时间相结合的方式,有效实现用户行为序列在不同时空条件下的三边表达。最后,经上述网络编码后的时空信息经过注意力机制网络融合,得到LBS场景下用户超长行为序列对不同请求候选的个性化表达。
相比较而言,比赛中的Spatial-temporal Gated DNN更注重时空融合信息对于预测值的影响,由于需要预测的时间序列问题,更侧重于不同的时间、空间信息有能够将差异性建模充分。而在美团业务中的时空网络注重于细粒度刻画空间信息,源于不同的球面距离,不同的区块位置影响大,需要多重信息深度建模。更多详情,大家可参考团队的CIKM论文:Trilateral Spatiotemporal Attention Network for User Behavior Modeling in Location-based Search[23]。
在实际建模中,相对于比赛涉及到更多线上部分,而比赛主要专注于离线数据集的精度极值。同Debiasing比赛相比,在实际线上系统中,涉及到Bias等更多的问题,以Position Bias为例,实际的展示数据高位点击率天然高于低位,然而一部分是源于用户高低位之间的浏览习惯差异,因此对于数据的直接建模不足以表征对于高低位广告点击率与质量的评估。我们在美团实际广告系统中,设计了位置组合预估框架进行建模,取得不错的效果,这里不再详述。具体详情,大家可参考团队SIGIR论文:Deep Position-wise Interaction Network for CTR Prediction[7]。
4.3 建模关键理解
一致的评估方式是决定模型泛化能力的关键
在比赛的机制中,通常最终评测的Private Data和此前一直榜单的Public Data并不是一份数据,有时切换数据会有几十名的名次抖动,影响最终排名。因此避免过拟合到常规迭代的Public Data是最终取胜的关键。那么在此问题上,如何构造同线上分布一致的验证集呢?从一致性角度,一般会构造时间间隔一致的验证集。而部分问题数据噪音较重,可以用动态滑窗等方式构造多个验证集相结合。一致的验证集决定着后面的迭代方向。
大数据注重模型的深化,小数据注重模型的鲁棒
不同数据集注重的内容不一样,在数据充分的场景下,核心问题是模型深化,以解决特征之间交叉,组合等复杂问题。而在小数据下,因为噪音多,不稳定性强,核心问题是模型的鲁棒。高数据敏感性是方案设计的关键。
方差与偏差的平衡是后期指导优化的关键
从误差分解角度去理解,平方误差可以分解为偏差(Bias)与方差(Variance)[25],在中前期模型复杂度较低时,通过提升模型复杂度,能够有效减低偏差。而在偏差已经被高度优化的后期,方差的优化是关键,因此在后期会通过Emsemble等方式,在单模型复杂度不变的基础上,通过模型融合优化结果。
AutoML的关键是人为先验的不断减少
在运用AutoML框架的同时,会有一些超参数等隐蔽的人为先验,把AutoML技术也以模型视角来理解,同样存在模型复杂度越高越容易过拟合的问题,迭代中的一个关键问题不是评估效果的好坏,而是方案是否存在不必要的超参数等信息,能否不断地简化AutoML的建模,不断地自动化,自适应适配各类问题。
最后,也特别感谢Convolution Team、Nomo Team、Getmax Team、Aister Team等队伍的队友们。
总结
本文基于笔者7次算法比赛的冠军经历,分享推荐系统、时间序列及自动化机器学习等不同领域比赛中的算法经验,接着结合具体问题介绍AutoML技术框架,最后总结比赛中通用的建模方案,结合工业界方案介绍其与比赛的联系。希望文章中的一些算法比赛相关经验能够帮助算法爱好者更好地参与竞赛,能为大家提供一些思路,启迪更多的工程师与研究员在实际工作中取得更优结果。未来,我们团队将持续关注国际算法竞赛,积极进行比赛思路与工业方案结合的尝试,同时也欢迎大家加入我们团队,文末附有招聘信息,期待你的邮件。
作者简介
胡可、兴元、明健、坚强,均来自美团广告平台质量预估团队。
参考文献
[1] Juan Y , Zhuang Y , Chin W S , et al. Field-aware Factorization Machines for CTR Prediction[C]// the 10th ACM Conference. ACM, 2016.
[2] He K , Zhang X , Ren S , et al. Identity Mappings in Deep Residual Networks[J]. Springer, Cham, 2016.
[3] Ali, Jehad & Khan, Rehanullah & Ahmad, Nasir & Maqsood, Imran. (2012). Random Forests and Decision Trees. International Journal of Computer Science Issues(IJCSI). 9.
[4] Robi Polikar. 2006. Ensemble based systems in decision making. IEEE Circuits and systems magazine 6, 3 (2006), 21–45.
[5] Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2020. Bias and Debias in Recommender System: A Survey and Future Directions. arXiv preprint arXiv:2010.03240 (2020).
[6] H. Abdollahpouri and M. Mansoury, “Multi-sided exposure bias in recommendation,” arXiv preprint arXiv:2006.15772, 2020.
[7] Huang J, Hu K, Tang Q, et al. Deep Position-wise Interaction Network for CTR Prediction[J]. arXiv preprint arXiv:2106.05482, 2021.
[8] KDD Cup 2020 Debiasing比赛冠军技术方案及在美团的实践 .
[9] Luo Z, Huang J, Hu K, et al. AccuAir: Winning solution to air quality prediction for KDD Cup 2018[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 1842-1850.
[10] He Y, Lin J, Liu Z, et al. Amc: Automl for model compression and acceleration on mobile devices[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 784-800.
[11] Yang Gao, Hong Yang, Peng Zhang, Chuan Zhou, and Yue Hu. 2020. Graph neural architecture search. In IJCAI, Vol. 20. 1403–1409.
[12] Matheus Nunes and Gisele L Pappa. 2020. Neural Architecture Search in Graph Neural Networks. In Brazilian Conference on Intelligent Systems. Springer, 302– 317.
[13] Huan Zhao, Lanning Wei, and Quanming Yao. 2020. Simplifying Architecture Search for Graph Neural Network. arXiv preprint arXiv:2008.11652 (2020).
[14] Jin Xu, Mingjian Chen, Jianqiang Huang, Xingyuan Tang, Ke Hu, Jian Li, Jia Cheng, Jun Lei: “AutoHEnsGNN: Winning Solution to AutoGraph Challenge for KDD Cup 2020”, 2021; arXiv:2111.12952.
[15] Selsaas L R, Agrawal B, Rong C, et al. AFFM: auto feature engineering in field-aware factorization machines for predictive analytics[C]//2015 IEEE International Conference on Data Mining Workshop (ICDMW). IEEE, 2015: 1705-1709.
[16] Yao Shu, Wei Wang, and Shaofeng Cai. 2019. Understanding Architectures Learnt by Cell-based Neural Architecture Search. In International Conference on Learning Representations.
[17] Kaicheng Yu, Rene Ranftl, and Mathieu Salzmann. 2020. How to Train Your Super-Net: An Analysis of Training Heuristics in Weight-Sharing NAS. arXiv preprint arXiv:2003.04276 (2020).
[18] Haixun Wang, Wei Fan, Philip S Yu, and Jiawei Han. 2003. Mining concept-drifting data streams using ensemble classifiers. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. 226–235.
[19] Robi Polikar. 2006. Ensemble based systems in decision making. IEEE Circuits and systems magazine 6, 3 (2006), 21–45.
[20] Chengshuai Zhao, Yang Qiu, Shuang Zhou, Shichao Liu, Wen Zhang, and Yanqing Niu. 2020. Graph embedding ensemble methods based on the heterogeneous network for lncRNA-miRNA interaction prediction. BMC genomics 21, 13 (2020), 1–12.
[21] Rosenfeld N , Meshi O , Tarlow D , et al. Learning Structured Models with the AUC Loss and Its Generalizations.
[22] Chen T , Tong H , Benesty M . xgboost: Extreme Gradient Boosting[J]. 2016.
[23] Qi, Yi, et al. "Trilateral Spatiotemporal Attention Network for User Behavior Modeling in Location-based Search", CIKM 2021.
[24] 广告深度预估技术在美团到店场景下的突破与畅想.
[25] Geurts P . Bias vs Variance Decomposition for Regression and Classification[J]. Springer US, 2005.
[26] Kaggle Outbrain比赛链接:https://www.kaggle.com/c/outbrain-click-prediction.
[27] KDD Cup 2020 Debiasing比赛链接 https://tianchi.aliyun.com/competition/entrance/231785/introduction.
[28] KDD Cup 2018比赛链接:https://www.biendata.xyz/competition/kdd_2018/.
[29] KDD Cup 2017比赛链接:https://tianchi.aliyun.com/competition/entrance/231597/introduction.
[30] KDD Cup 2020 AutoGraph比赛链接:https://www.automl.ai/competitions/3.
---------- END ----------
「 更多干货,更多收获 」

推荐系统工程师技能树
【免费下载】2021年12月份热门报告盘点
快手推荐系统精排模型实践.pdf
【干货】2021社群运营策划方案.pptx大数据驱动的因果建模在滴滴的应用实践
联邦学习在腾讯微视广告投放中的实践如何搭建一个好的指标体系?如何打造标准化的数据治理评估体系?【干货】小米用户画像实践.pdf(附下载链接)
推荐系统解构.pdf(附下载链接)
短视频爆粉表现指南手册.pdf(附下载链接)
推荐系统架构与算法流程详解如何搭建一套个性化推荐系统?某视频APP推荐策略详细拆解(万字长文)关注我们
智能推荐 个性化推荐技术与产品社区 |
长按并识别关注
|

一个「在看」,一段时光