损失函数——负对数似然
阅读本文可以了解如下内容:
- 似然
- 似然估计
- 对数似然
- 负对数似然
1. 似然
在开始之前需要区分一个知识:似然(likelihood)和概率(probability)。概率是一个事件发生的可能性,而似然指的是影响概率的未知参数。也就是说,概率是在该未知参数已知的情况下所得到的结果;而似然是该参数未知,我们需要根据观察结果,来估计概率模型的参数。
用数学方法可以描述为:
假设 X X X是离散随机变量,其概率质量函数 p p p依赖于参数$\theta $,则:
L ( θ ∣ x ) = p θ ( x ) = P θ ( X = x ) L(\theta|x)=p_{\theta}(x)=P_{\theta}(X=x) L(θ∣x)=pθ(x)=Pθ(X=x)
其中 L ( θ ∣ x ) L(\theta|x) L(θ∣x)为参数 θ \theta θ的似然函数, x x x为随机变量 X X X的某一值。1
如果我们发现:
L ( θ 1 ∣ x ) = P θ 1 ( X = x ) > P θ 2 ( X = x ) = L ( θ 2 ∣ x ) L(\theta_{1}|x)=P_{\theta_{1}}(X=x)>P_{\theta_{2}}(X=x)=L(\theta_{2}|x) L(θ1∣x)=Pθ1(X=x)>Pθ2(X=x)=L(θ2∣x)
那么似然函数就可以反映出这样一个朴素推测:在参数 θ 1 \theta_{1} θ1下随机变量 X X X取到 x x x的可能性大于在参数 θ 2 \theta_{2} θ2下随机向量 X X X取到 x x x的可能性。换句话说,我们更有理由相信,相对于 θ 2 \theta_2 θ2, θ 1 \theta_{1} θ1更有可能是该概率模型的真实参数。2
综上,概率(密度)表达给定 θ \theta θ下样本随机向量 X = x X=x X=x的可能性,而似然表达了给定样本 X = x X=x X=x下参数 θ 1 \theta_{1} θ1(相对于另外的参数 θ 2 \theta_{2} θ2)为真实值的可能性。我们总是对随机变量的取值谈概率,而在非贝叶斯统计的角度下,参数是一个实数而非随机变量,所以我们一般不谈一个参数的概率。
2. 最大似然估计(Maximum Likelihood Estimation, MLE)
假设我们有一个非常复杂的数据分布 P d a t a ( x ) P_{data}(x) Pdata(x),但是我们不知道该分布的数学表达形式,所以我们需要定义一个分布模型 P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ),该分布由参数 θ \theta θ决定。
我们的目标是求得参数 θ \theta θ使得定义的分布 P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ)尽可能的接近 P d a t a ( x ) P_{data}(x) Pdata(x)。
下面我们来看看最大似然估计如何操作:
- 从 P d a t a ( x ) P_{data}(x) Pdata(x)中采集m个样本 x 1 , x 2 , . . . , x m {x_{1},x_{2},...,x_{m}} x1,x2,...,xm
- 计算样本的似然函数 L = ∏ i = 1 m P G ( x i ; θ ) L=\prod_{i=1}^{m}P_{G}(x^{i};\theta) L=∏i=1mPG(xi;θ)
- 求使得似然函数 L L L最大的参数 θ \theta θ: θ ∗ = arg max θ ∏ i = 1 m P G ( x i ; θ ) \theta^{*}=\arg \max _{\theta}\prod_{i=1}^{m} P_{G}(x^{i};\theta) θ∗=argmaxθ∏i=1mPG(xi;θ)
当来自 P d a t a ( x ) P_{data}(x) Pdata(x)的样本 x 1 , x 2 , . . . , x m {x_{1},x_{2},...,x_{m}} x1,x2,...,xm在 P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ)分布模型出现的概率越高,也就是 ∏ i = 1 m P G ( x i ; θ ) \prod_{i=1}^{m}P_{G}(x^{i};\theta) ∏i=1mPG(xi;θ)越大, P G ( x ; θ ) P_{G}(x;\theta) PG(x;θ)和 P d a t a ( x ) P_{data}(x) Pdata(x)越接近。3
3. 对数似然
在知道了最大似然估计之后就容易理解对数似然了。从公式可以看到,似然函数是很多个数相乘的形式: L = ∏ i = 1 m P G ( x i ; θ ) L=\prod_{i=1}^{m}P_{G}(x^{i};\theta) L=∏i=1mPG(xi;θ)。
然而很多数相乘并不容易计算,也不方便求导。如果我们对它取对数,连乘就会变成连加,计算起来要方便的多,求导也变得更加容易。
l ( θ ) = ∑ i = 1 m log ( P G ( x i ; θ ) ) l(\theta)=\sum_{i=1}^{m}\log (P_{G}(x^{i};\theta)) l(θ)=i=1∑mlog(PG(xi;θ))
这样一来就变成了我们非常熟悉的求极值过程, θ \theta θ为自变量,我们需要找到某一个 θ \theta θ,使得 l ( θ ) l(\theta) l(θ)最大。只需对 θ \theta θ求导然后令导数等于0即可。
最大似然估计的一般步骤如下:
(1) 写出似然函数;
(2) 对似然函数取对数,得到对数似然函数;
(3) 求对数似然函数的关于参数组的偏导数,并令其为0,得到似然方程组;
(4) 解似然方程组,得到参数组的值。
4. 负对数似然(Negative log-likelihood, NLL)1
由于对数似然是对概率分布求对数,概率 P ( x ) P(x) P(x)的值为 [ 0 , 1 ] [0,1] [0,1]区间,取对数后为 ( − ∞ , 0 ] (-\infty ,0] (−∞,0]区间。再在前面加个符号,变成 [ 0 , ∞ ) [0,\infty) [0,∞)区间。
l ( θ ) = − ∑ i = 1 m log ( P G ( x i ; θ ) ) l(\theta)=-\sum_{i=1}^{m}\log (P_{G}(x^{i};\theta)) l(θ)=−i=1∑mlog(PG(xi;θ))
**写到这你有没有发现,这个公式不就是交叉熵吗?**只是少了一项 p ( x i ) p(x_{i}) p(xi),但是真实标签的概率为1,所以省掉了。
关于交叉熵的理解可以参考我的另一篇博客。
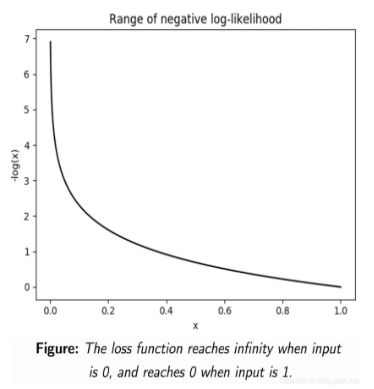
我们期望似然估计越大越好,取完负号之后就是负对数似然越小越好,因此负对数似然函数可以作为损失函数。
Pytorch中对应的负对数似然损失函数为:
torch.nn.NLLLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
值得注意的是,在使用该损失函数的时候并不需要将标签转换成one-hot形式,c类标签,就用c-1个数表示即可。
输入与输出数据的形状:
- input: (N,C)
- output:(N)
其中N为batch size,C为分类数量。假设batch size为3,有5个类别。我们用一段代码看看torch.nn.NLLLoss()如何使用:
>>> import torch
>>> m = torch.nn.LogSoftmax(dim=1)
>>> loss = torch.nn.NLLLoss()
>>> input = torch.randn(3,5,requires_grad=True)
>>> input
tensor([[ 0.1076, -1.4376, -0.6307, 0.6451, -1.5122],
[ 1.5105, 0.7662, -1.7587, -1.4581, 1.1357],
[-1.4673, -0.5111, -0.0779, -0.7404, 1.4447]], requires_grad=True)
>>> target = torch.tensor([1, 0, 4])
>>> output = loss(m(input), target)
>>> output.backward()
计算结果为:
tensor(1.3537)
实际上这段代码计算的是交叉熵,因为在pytorch交叉熵的官方文档中写道4:
This criterion (CrossEntropyLoss) combines
LogSoftmaxandNLLLossin one single class.
它先将输入经过log softmax函数,得到一个输出:
>>> data = nn.LogSoftmax(dim=1)(input)
>>> data
tensor([[-1.2812, -2.8264, -2.0195, -0.7437, -2.9010],
[-0.8118, -1.5561, -4.0810, -3.7804, -1.1866],
[-3.3349, -2.3787, -1.9455, -2.6080, -0.4229]])
然后根据负对数似然估计的公式,得到如下等式:
L o s s = − ( − 2.8264 − 0.8118 − 0.4229 ) / 3 = 1.3537 Loss = - (-2.8264 - 0.8118 - 0.4229 )/3 = 1.3537 Loss=−(−2.8264−0.8118−0.4229)/3=1.3537
和函数计算结果相同。
值得注意的是,nn.NLLLoss()函数虽然叫负对数似然损失函数,但是该函数内部并没有像公式里那样进行了对数计算,而是在激活函数上使用了nn.LogSoftmax()函数,所以nn.NLLLoss()函数只是做了求和取平均然后再取反的计算,在使用时要配合logsoftmax函数一起使用,或者直接使用交叉熵损失函数。
负对数似然(negative log-likelihood) ↩︎ ↩︎
如何理解似然函数 ↩︎
如何通俗地理解概率论中的「极大似然估计法」? ↩︎
torch.nn.CrossEntropyLoss ↩︎