深度学习的学习与实践(1):从AE,VAE,到AAE
前置知识:自编码器入门
前段时间在改论文的过程中,审稿人给出了关于使用对抗自编码器算法的建议——2020.2
以上算是序
自编码器(autoencoder)是一种无监督学习神经网络
基本定义
本质上来说,自编码器是一种所谓”生成模型“,也就是根据给定的数据集去学习数据的分布函数,然后通过调整神经网络的参数使输出和原数据集尽量一致。一般的,自编码器的原型是一个单隐层的神经网络

从输入层到隐层的过程可以理解为一个“编码”(encode)过程,即用更低维度的一组数据来特征化的表示原数据。而隐层到输出层的过程则可以看作一个“解码”(decode)过程,即从特征化数据中还原出原数据。整个网络一般通过最小化输出 X ^ \hat{X} X^与原输入 X X X之间的重构误差 L ( X ^ , X ) L(\hat{X}, X) L(X^,X)来进行训练。
自编码器的网络特征
自编码器所构建的神经网络一般有以下两个特征:
1.隐层神经元数必须比输入层少。因为隐层要起到编码,也就是压缩信息的作用,否则就起不到提取数据特征的目的,而变成了无意义的复制;
2.隐层通常并不是简单的单层结构。如果我们采用单隐层,那么当采用线性激活函数时,编码过程就变成了类似主成分分析降维效果,丢失掉一部分特征之间隐含的非线性关系。所以最好采用多层网络结构,留出足够储存隐含关系的空间
对抗自编码器
AAE(adversarial autoencoder)是一种改进型的自编码器算法,来源是这篇paper。它是一种对变分自编码器(VAE)和生成对抗网络(GAN)的结合,在变分自编码器的基础上引入了对抗网络,从而实现了使用对抗训练框架来实现对潜变量 z z z 的惩罚约束,替换了变分自编码器算法中复杂的基于变分贝叶斯推导和最小化KL散度的惩罚约束过程。
必要的补充:VAE
说实话原文paper是没怎么说明算法的具体细节的,对于没有学习过变分自编码器算法的人来说看起来就是一头雾水,所以需要顺便学习下VAE变分自编码器算是一种相当经典的生成模型。它所采用的“变分推断”(variational inference,参考知乎上一篇很好的回答)的方法适合于解决机器学习中的概率学习问题。
我们通过一般的生成问题来简单的梳理下变分自编码器的算法结构:
前提条件:已知真实样本 X X X, 需要推知随机变量 x x x的分布 p ( x ) p(x) p(x)
这样其实就是一个很典型的概率学习问题,而一般的生成问题其实都可以看作是概率问题。比如比较典型的图像生成问题,本质上就是通过现有的图像样本去学习生成图像数据的概率分布,然后通过得到的分布去生成更多的图像样本。
事实上,当我们说需要学习数据的概率分布时,我们会很自然的想到极大似然估计等参数估计方法。但是这些方法只有在给定概率分布的前提下才能使用。然而我们面对的问题中,不光概率分布的参数 θ \theta θ未知,概率分布本身 p p p也未知。
因此,为了解决这一问题,变分自编码器算法中引入了变分推断的方法。简单来说,所谓变分推断的方法就是,当我们想要得到随机变量 x x x的分布 p p p而无法直接得到时,我们就在另一个样本空间 Z Z Z中构建一个分布已知的中间变量(潜变量) z z z(比如高斯分布),然后通过映射得到 z z z的分布 q q q在样本空间 X X X中的映射分布。由于 z z z的分布 q q q是我们自己设定的,所以 z z z在 X X X中映射就是可控的,我们就可以使用分布 q q q去逐渐逼近 p p p从而达到尽可能得到真实分布 p p p的目的。那么AE和VAE的区别也就在于,变分推断的引入使得原本只能求解潜变量 z z z和原变量 x x x之间单值映射关系的AE变为了求解 z z z和 x x x之间分布 p p p和 q q q映射关系的VAE,从而能够实现更好的生成效果。关于为什么分布映射会比单值映射有更好的效果,参考下面一段文字
假如在AE中,一张满月的图片作为输入,模型得到的输出是一张满月的图片;一张弦月的图片作为输入,模型得到的是一张弦月的图片。当从满月的code和弦月的code中间sample出一个点,我们希望是一张介于满月和弦月之间的图片,但实际上,对于AE我们没办法确定模型会输出什么样的图片,因为我们并不知道模型从满月的code到弦月的code发生了什么变化
——引自blog《AE&VAE》
现在我们来简单梳理一下VAE的算法流程(这一部分巨™烦,但是搞懂对后续理解很有帮助)
其结构和一般的自编码器类似,由encoder和decoder组成,而其特点则在于在loss(损失函数)的设计和参数更新的过程中采用了的变分推断的方法。算法流程大致如下:
1、先向encoder网络中输入样本 x i x_i xi,得到 q ϕ ( z ∣ x i ) q_\phi(z|x_i) qϕ(z∣xi)的充分统计量 μ \mu μ和 σ \sigma σ;
2、由正态分布 q ϕ ( z ∣ x i ) q_\phi(z|x_i) qϕ(z∣xi)抽样得到 z i z_i zi;
3、向decoder网络输入 z i z_i zi,得到重构样本 x i ^ \hat{x_i} xi^;
4、根据设计好的Loss,反向传播修正两个网络的参数,直到得到最佳参数。
Loss主要通过变分推断进行构造。首先假设X中的N个样本独立同分布,且每个样本都服从随机分布 p ( ⋅ ) p(\cdot) p(⋅),所以构造由N个随机变量构成的联合分布 p ( x 1 , . . . , x N ) = ∏ i = 1 N p ( x i ) p(x_1,...,x_N) = \prod^N_{i=1} p(x_i) p(x1,...,xN)=∏i=1Np(xi),根据最大似然的观点联合概率取最大值时,样本最大程度服从同一个分布。
所以首先对联合分布取对数似然
然后我们构造另一个分布已知的随机变量z,尝试通过推导含有xz的联合分布和条件分布的算式来逼近原分布,并同时满足联合分布在x上的边沿分布为p(x)。推导过程可以假设x为离散变量:

也可以假设x为连续变量
可以看出两种表述在推导上没有本质的区别,但后者推导时加上了 p , q p,q p,q分布的参数 θ \theta θ和 ϕ \phi ϕ,表述更加完整,有助于帮助理解,所以我们按照后一种的思路来学习整个推导过程。如此显然我们可以看出最后一个等式的第一项就是我们所构造的KL散度,即 D K L ( q ϕ ( z ∣ x i ) ∣ ∣ p θ ( z ∣ x i ) ) D_{KL}(q_\phi(z|x_i)||p_\theta(z|x_i)) DKL(qϕ(z∣xi)∣∣pθ(z∣xi)),而第二项我们令其为 L ( θ , ϕ ; x i ) L(\theta,\phi;x_i) L(θ,ϕ;xi),表示该函数是在 x i x_i xi给定的情况下关于真实分布的参数 θ \theta θ和近似分布的参数 ϕ \phi ϕ的表达式。根据KL散度的定义可知第一项大于等于0,那么 L ( θ , ϕ ; x i ) L(\theta,\phi;x_i) L(θ,ϕ;xi)就是我们所求的 l o g p ( x i ) logp(x_i) logp(xi)的下界,也叫变分推断下界。所以后续的工作就是通过 L ( θ , ϕ ; x i ) L(\theta,\phi;x_i) L(θ,ϕ;xi)对 θ , ϕ \theta,\phi θ,ϕ求梯度,从而使 L ( θ , ϕ ; x i ) L(\theta,\phi;x_i) L(θ,ϕ;xi)获得最大值。
为了方便计算,还需要对 L ( θ , ϕ ; x i ) L(\theta,\phi;x_i) L(θ,ϕ;xi)进行进一步推导,过程如下:

从连等式最后一项可以看出,第一项反映的是z的真实分布p与给定x的后验分布的近似分布q的距离(KL散度)。第二项则可以理解为 l o g p θ ( x i ∣ z ) logp_\theta(x_i|z) logpθ(xi∣z)在分布 q ϕ ( z ∣ x i ) q_\phi(z|x_i) qϕ(z∣xi)上的期望,即样本在经过编码为潜变量z后,还能从z的近似分布采样回原样本x的概率的平均值。
然后,我们针对第一项,假设 p θ ( z ) p_\theta(z) pθ(z)是J维标准正态分布 N ( z ; O , I ) N(z;O,I) N(z;O,I)
(这里使用了一个reparametrization trick的方法,因为z是一个我们无法计算导数的随机变量,这会导致反向传播种的梯度下降无法使用,所以我们将其先设为一个分布已知的值,从而能使反向传播得以计算其导数。具体方法后面会提到)
q ϕ ( z ∣ x i ) q_\phi(z|x_i) qϕ(z∣xi)是与之相似的参数为 μ \mu μ和 σ \sigma σ的J维正态分布,且 μ i \mu_i μi和 σ i \sigma_i σi分别为对应参数矢量各维度的值。那么关于第一项的KL散度就可以求出其解析解:
− D K L ( q ϕ ( z ∣ x i ) ∣ ∣ p θ ( z ) ) = ∫ z q ϕ ( z ) ⋅ l o g p θ ( z ) d z − ∫ z q ϕ ( z ) ⋅ l o g q ϕ ( z ) d z = ∫ N ( z ; μ , σ ) l o g N ( z ; O , I ) d z − ∫ N ( z ; μ , σ ) l o g N ( z ; μ , σ ) d z = − J 2 l o g ( 2 π ) − 1 2 ∑ i = 1 J ( μ i 2 + σ i 2 ) − ( − J 2 l o g ( 2 π ) − 1 2 ∑ i = 1 J ( 1 + l o g σ i 2 ) ) = 1 2 ∑ i = 1 J ( 1 + l o g σ i 2 − μ i 2 − σ i 2 ) -D_{KL}(q_\phi(z|x_i)||p_\theta(z)) = \int_z q_\phi (z) \cdot log\ p_\theta(z) dz - \int_z q_\phi (z) \cdot log\ q_\phi(z) dz\\ = \int{N(z;\mu,\sigma)log\ N(z;O,I)dz } \ -\ \int{N(z;\mu,\sigma)log\ N(z;\mu,\sigma)dz }\\ =-\frac{J}{2}log(2\pi) - \frac{1}{2}\sum_{i=1}^J(\mu_i^2+\sigma_i^2) \ -\ (-\frac{J}{2}log(2\pi) - \frac{1}{2}\sum_{i=1}^J(1+log\sigma_i^2))\\ =\frac{1}{2}\sum_{i=1}^J(1+ log\sigma_i^2 - \mu_i^2-\sigma_i^2) −DKL(qϕ(z∣xi)∣∣pθ(z))=∫zqϕ(z)⋅log pθ(z)dz−∫zqϕ(z)⋅log qϕ(z)dz=∫N(z;μ,σ)log N(z;O,I)dz − ∫N(z;μ,σ)log N(z;μ,σ)dz=−2Jlog(2π)−21i=1∑J(μi2+σi2) − (−2Jlog(2π)−21i=1∑J(1+logσi2))=21i=1∑J(1+logσi2−μi2−σi2)
关于第二项,由于第二项的积分是很难直接计算的,牵扯到了x的后验概率 q ϕ ( z ∣ x i ) q_\phi(z|x_i) qϕ(z∣xi)关于z的分布,这一分布我们是通过近似逼近的,无法直接获得,所以我们考虑采用蒙特卡洛方法去获得采样结果:

需要注意的是,这个 z j z^j zj并不是从假设的z分布直接采样,而是使用上面提到的reparametrization trick方法来得到,具体做法是:
先从 N ( 0 , 1 ) N(0,1) N(0,1)上采样 ϵ \epsilon ϵ,然后通过 z = σ ⋅ ϵ + μ z=\sigma⋅\epsilon+\mu z=σ⋅ϵ+μ得到。很多地方只是解释了为什么要用这样的方法,而没有解释为什么不能直接用假设的z的分布即 N ( 0 , 1 ) N(0,1) N(0,1)的采样结果。我猜测应该是因为在这一过程中必须引入需要优化的参数 σ \sigma σ和 μ \mu μ,这样才能保证 z ∼ N ( μ , σ ) z∼N(μ,σ) z∼N(μ,σ)的同时,还可以正常使用梯度下降对这一过程进行优化
如果只采样一次,即L = 1,则得到:
![]()
z i z_i zi即为采样点,这个式子可以看作迭代过程中对于解码器decoder的优化,因为第二项本身代表的是解码器还原样本x的能力。
综合起来看,第一项和第二项在优化函数 L ( θ , ϕ ; x i ) L(\theta,\phi;x_i) L(θ,ϕ;xi)中分别代表了编码器和解码器两部分。第一项试图使编码器对x的编码结果更接近我们引入或者说假设的已知分布(高斯分布),第二项则努力使解码器的输出结果更加接近原样本x。
而由 L ( θ , ϕ ; x i ) L(\theta,\phi;x_i) L(θ,ϕ;xi)推导的最后一项我们可以发现最大化 L ( θ , ϕ ; x i ) L(\theta,\phi;x_i) L(θ,ϕ;xi)本身等价于最小化KL散度,这也和我们使得p,q两分布尽可能接近的目标恰好一致。
最终我们可以得到式子:
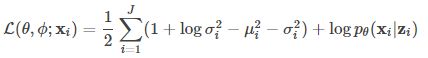
最终训练用的Loss其实就是对 L ( θ , ϕ ; x i ) L(\theta,\phi;x_i) L(θ,ϕ;xi)的一个取反(由求最大变为求最小,方便反向传播处理)。然后 l o g p θ ( x i ∣ z i ) logp_\theta(x_i|z_i) logpθ(xi∣zi)则使用重建样本re_x和x之间的逐位二进制交叉熵来代替
