Mysql事务隔离级别、锁、MVCC(多版本并发控制)
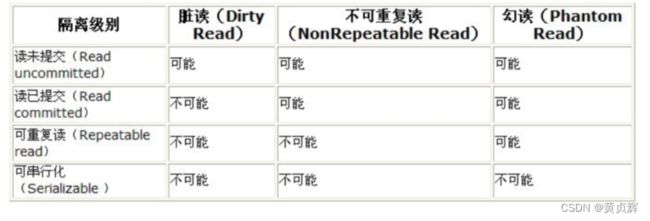
事务隔离级别
1、读未提交(Read Uncommitted) 能读到其他事务未提交的数据
2、读已提交(Read Committed) 能读到其他事务已提交的数据
3、可重复读(Repeatable Read) 不管其他事务修改完提交的数据,只要是在本事务内,多次读取,都是一样的结果,但若是本事务自己修改了,那是会根据数据库最新的数据去修改的,再查询时,也是最新的修改结果
4、串行化(Serializable) 每个事务按顺序执行
4种隔离级别存在的问题:
脏读:事务a读取事务b未提交的数据,事务b回滚了之后,事务a不知道。不符合一致性。
不可重复读:事务a内部多次读取时,事务b修改完提交了,事务a中途读取到了事务b提交的数据,前后不一致。不符合隔离性。
幻读:事务a按相同的条件去查询之前查过的数据,却发现事务b插入的新数据。不符合隔离性。
事务执行用例
可以通过以下sql 设置某次会话的事务隔离级别
读未提交
set session TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
读已提交
set session TRANSACTION ISOLATION LEVEL READ COMMITTED;
可重复读(数据库默认级别)
set session TRANSACTION ISOLATION LEVEL REPEATABLE READ;
这里主要研究的是可重复读(Repeatable Read)
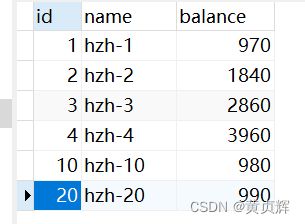
新建一个account表数据

行锁、表锁、间隙锁、死锁的验证
模拟两个会话
(1)验证行锁: 一个session开启事务更新不提交,另一个session更新同一条记录会阻塞,更新不同记录不会阻塞
这里where 的条件是 id,是主键索引,默认加行锁
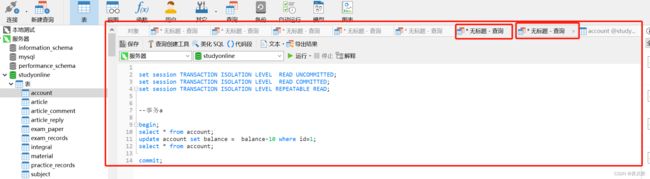
(2)验证无索引行锁升级为表锁:
锁一般是加在索引字段上的,不是加在一整条数据上的,
这里where 条件是name,它是没有建立name的索引,本来我们以为是加行锁,但是它会升级为表锁,事务a执行下面sql
begin;
update account set balance = balance-10 where name='hzh-2' ;
那么会锁住一整个表,事务b执行任何一条写事务都会被阻塞,除非给name加上索引。
(3)验证间隙锁:
事务a执行
begin;
select * from account;
update account set balance = balance-10 where id>=1 and id<=10;
底层会给该id范围加锁,在本事务commit前,当其他事务修改,删除,插入id为1-10时,阻塞
事务b在执行修改,删除,插入时,id=1到10 会被阻塞
begin;
insert into account values(5,'hzh-5',5000);
注意1:若表中数据是id=1,2,3,4,10,20这6条数据; 条件是where id>=7 and id<=17;
因为7在4-10之间,所以涉及到的4-10的整个区间都是会被锁到,包括4,同理10-20也会被锁。并不是只有7-17会被锁,而是4-20。
注意2:若表中数据是id=1,2,3,4,10,20这6条数据; 条件是where id=15;15在10-20之间,所以间隙锁锁的是10-20,
两个事务即使生成的间隙锁的范围是一样的,也不会发生冲突,因为间隙锁目的是为了防止其他事务插入数据,因此间隙锁与间隙锁之间是相互兼容的。
新增两行数据进去
(4)验证死锁1:
1、事务a
begin;
update account set balance = balance-10 where id=1 ;
2、事务b
begin;
update account set balance = balance-10 where id=2 ;
3、事务a
update account set balance = balance-10 where id=2 ;
4、事务b
update account set balance = balance-10 where id=1 ;
死锁报错
> 1213 - Deadlock found when trying to get lock; try restarting transaction
> 自动回滚其中一个事务,另一个事务正常继续执行。
验证不同事务获取间隙锁兼容,再相互插入得死锁:
按照time 1,2,3,4执行
事务a
begin;
update account set name='hzh-15' where id=15;--time1,间隙锁锁住了10-20
insert into account values(15,'hzh-15',1000);--time3,被事务b阻塞,等待事务b释放间隙锁
事务b
begin;
update account set name='hzh-16' where id=16;--time2,间隙锁锁住了10-20与事务a的间隙锁兼容,还不会死锁
insert into account values(16,'hzh-16',1000);--time4,想等待事务a释放间隙锁,此时形成循环等待,死锁。
可重复读例1:
a 事务先查询和修改,b事务再查询,a事务再commit, b事务再查询。
b事务查询的数据全程不受a事务影响
步骤1、a 事务
begin;
select * from account;
update account set balance = balance-10 where id=1;
select * from account;
此时还没有commit
a事务查询到自己修改的 第一行数据的 balance变成990
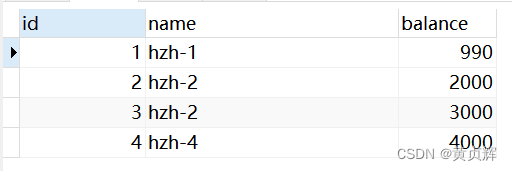
步骤2、b事务
begin;
select * from account;
此时还没有commit
b事务查询到的第一行数据的 balance还是1000
因为是可重复读级别,a事务没有提交是查不到了,就算a事务提交也查不到。
因为这个隔离级别要保证b事务多次读取,结果都一样。
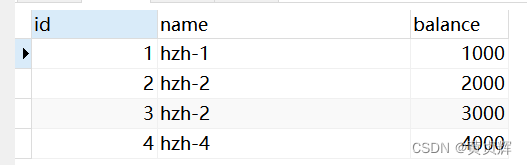
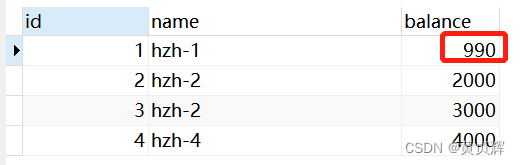
步骤3、现在我们去事务a commit; 再 select * from account;
发现数据确实是改好了。
步骤4、再去事务b执行看 select * from account; 还是1000;这个隔离级别保证了b事务多次读取,结果都一样。commit之后结束事务了再查询,就能查到了。

可重复读例2:
a事务先查询后,b事务修改后提交,a事务再修改并查询再提交
步骤1、事务a先查询
begin;
select * from account;
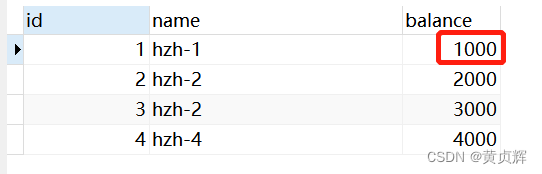
步骤2、事务b 执行更新后提交,此时数据库真实数据已经是990
begin;
select * from account;
update account set balance = balance-10 where id=1;
commit;
步骤3、事务a 再查询 select * from account; 依然是1000,符合可重复读 多次读取结果都一样。
但是若此时执行
update account set balance = balance-10 where id=1;
select * from account;
会怎么样呢?
它会去根据数据库的真实数据 990-10=980 来作为真实结果。
也就是说a事务在看到1000时减10,直接变成980,但这是对的,因为它确实需要在事务b 990的基础上减去10=980
只有增删改时会根据数据库的真实数据去操作,查询是不会的。
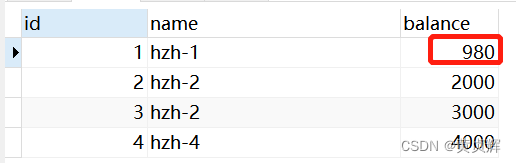
这样的效果是大部分开发中所需要的,读取数据时不受其他事务影响,增删改时需要根据最新数据修改,mysql的底层是怎么做到这样的呢? 就是 MVCC(多版本并发控制)做到的
MVCC(Multi-Version Concurrency Control 多版本并发控制)
数据库表隐藏的2个相关字段 DB_TRX_ID(创建事务id), DB_ROLL_PTR(回滚指针),执行begin时不会申请事务id,begin之后的第一条增删改查sql才会触发去申请事务id,事务id根据申请的前后顺序严格递增。

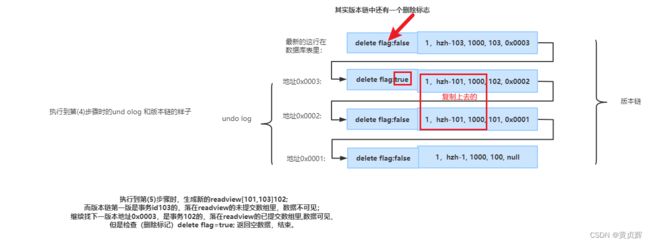
undo log、版本链、readview的理解
一、undo log(回滚日志) :事务每次更新某条记录时,原数据被放入undo log ,新数据在放数据库表里,当事务回滚时,可以undo log查询之前的数据。
二、版本链:版本链=数据库表的某行数据+该行数据的undo log。
三、readview:
每个事务查询sql时会新生成一个readview,它由两部分组成:未提交的事务id数组,已提交的事务id数组;
如readview[101,102]103,[101,102]是未提交的事务id数组,103是已提交的事务id数组
注意:这里的已提交的事务id,是指第二类中的,不包含第一类的已提交
关键点–版本链比对规则:拿着版本链数据里的事务id 照着readview里的数组去判断可不可读,而我们的readview是记录第二类的id,若比第二类的最小id还小,那就属于第一类。
1、若版本链的某个版本 事务id落在第一类,数据可见。
2、若落在第二类,有两种情况:
(1)事务id是未提交事务,数据不可见,仅自己的事务可见;
(2)事务id是已提交事务,数据可见。
3、若落在第三类,未开始事务,肯定不可见;
undo log、版本链、readview的例子分析
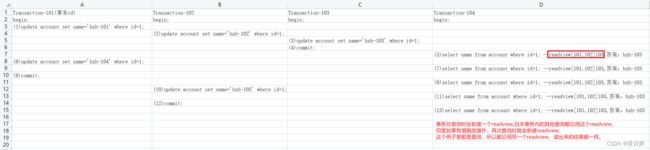
我们以account表的第一条数据为例来分析,新建4个事务,假设按照图中步骤执行各sql
例1:分析
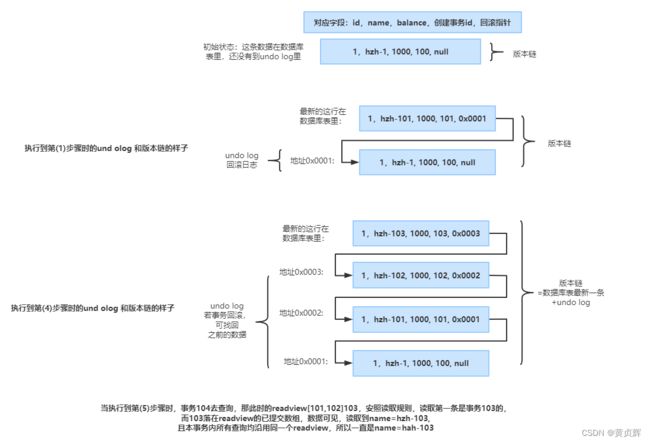
undo log和版本链的动态变化
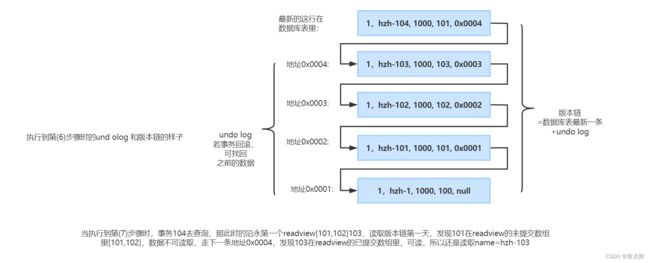
例2分析:

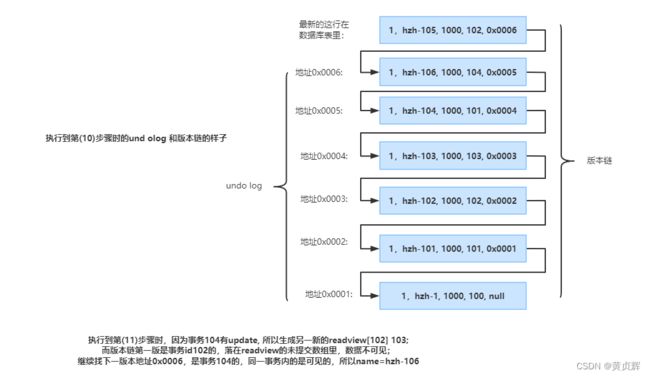
例3分析:
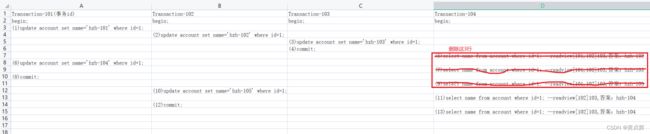
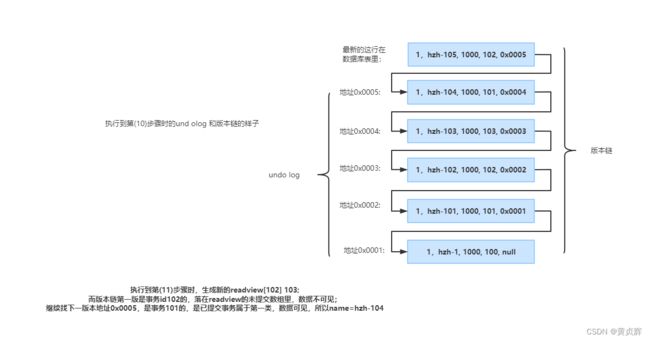
例4分析:
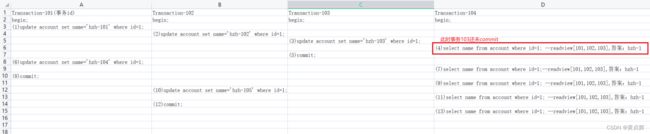

例5分析:(删除操作)

其实上面的几个例子版本链都有deleted flag=false,只是没用到,不指出来。
删除是把原上个版本数据复制一份,然后标上自己的事务id和删除标志为true。
可以看成是更新的一个特殊情况