2020李宏毅机器学习笔记— 9. Recurrent Neural Network(RNN循环神经网络)
文章目录
- 摘要
- 1.Introduction(引入)
-
- 1.1 Slot Filling
- 1.2 把词用向量来表示的方法
-
- 1-of-N encoding / one-hot
- Beyond 1-of-N encoding
- 1.3 存在的问题
- 2.Recurrent Neural Network(RNN)
-
- 2.1 RNN的特性
- 2.2 Example
- 2.3 RNN 处理slots filling问题
- 2.4 RNN有不同的变形
- 2.5 Bidirectional RNN
- 3. Long Short-term Memory(LSTM)
-
- 3.1 three gate
- 3.2 Memory Cell
- 3.3 LSTM Example
- 3.4 传统神经网络和LSTM的区别
- 3.5 LSTM for RNN
- 3.6 Multiple-layer LSTM
- 4. Learning Target
-
- 4.1 Loss Function(损失函数)
- 4.2 Training(训练)
- 4.3 分析 error surface
- 4.4 Why RNN 不好 Training ?
- 4.5 Helpful Techniques
- 4.6 GRU (Gated Recurrent Unit)
- 5. RNN的应用
-
- 5.1 输入和输出都是一个向量序列
- 5.2(Many to one)输入一个向量序列,输出是一个向量,多对一
- 5.3 (Many to many)输入和输出都是向量序列,但是输出更短,多对多
- 5.4 输入和输出都是向量序列,向量长度不同,多对多,sequence to sequence learning
- 6. RNN vs Structured Learning
-
- Integrated Together
- 总结与展望
摘要
首先本章通过Slot Filling的例子,引出了传统的NN在这个订票系统中会出现问题,为了应对复杂的语句,从而需要NN有记忆力,这便是RNN。其次,讲解LSTM(长短期记忆)的组成,它由四部分组成,每个LSTM本质上就是一个neuron,特殊之处在于有4个输入,一个输出,以及LSTM的工作过程和原理。然后,讲解了如何训练RNN,以及训练会遇到的问题梯度消失和梯度爆炸以及解决办法使用Clipping方法。以及讲解了RNN的各种应用,特别是在语音方面的应用。最后,对比RNN与Structured Learning,得出结论Deep 和structure 的结合是未来。
1.Introduction(引入)
1.1 Slot Filling
slot filing :槽位填充,也就是序列标注的一种,类似于命名实体识别,只是更细化。
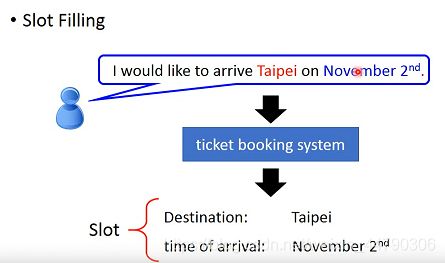
在智能客服、智能订票系统中,往往会需要slot filling技术,它会分析用户说出的语句,将时间、地址等有效的关键词填到对应的槽上,并过滤掉无效的词语。

词汇要转化成vector,可以使用1-of-N编码等方式,此外我们可以尝试使用Feedforward Neural Network来分析词汇,判断出它是属于时间或是目的地的概率。
1.2 把词用向量来表示的方法
1-of-N encoding / one-hot

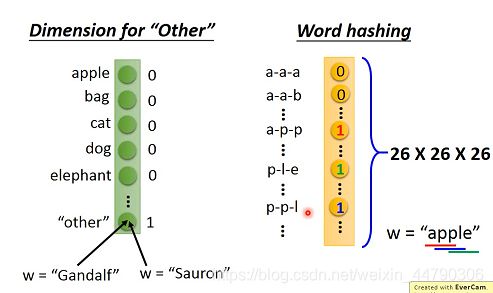
Beyond 1-of-N encoding
多一个纬度other,不在词典中的词汇归类入other
1.3 存在的问题
词汇表示为一个向量,输入是这个向量,输出是一个概率分布,属于某种的概率,神经网络在输入同一个词输出的概率分布是一样的,但是这样是不对的(如下图会出现问题)。

该神经网络会先处理“arrive”和“leave”这两个词汇,然后再处理“Taipei”,这时对NN来说,输入是相同的,它没有办法区分出“Taipei”是出发地还是目的地。
如果神经网络是有记忆的,如果NN在看到“Taipei”的时候,还能记住之前已经看过的“arrive”或是“leave”,就可以根据上下文得到正确的答案。这种有记忆力的神经网络,就叫做Recurrent Neural Network(RNN)。
2.Recurrent Neural Network(RNN)
2.1 RNN的特性
每次hidden layer里的neural产生输出的时候都会存到内存中,在下一次有input的时候,hidden layer的neural不止会考虑input,还会考虑内存中的值。

2.2 Example
假设weight都是1,没有bias,激活函数都是线性的。
输入和输出都是一个序列。
第一次输入:内存中还没存过东西,都是0,输入为1,计算后存入内存
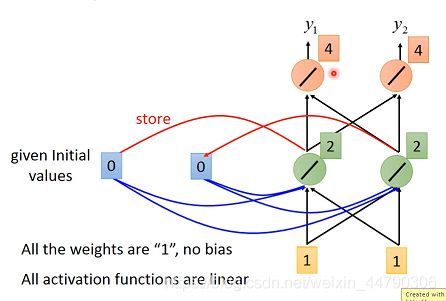
第二次:考虑输入和内存,得到新的结果并且保存
虽然两次输入是一样的,输出结果是不一样的,因为内存中的值是不一样的,每次NN的输出都要考虑memory中存储的临时值,而不同的输入产生的临时值也尽不相同。

第三次:重复上述步骤,输入2,2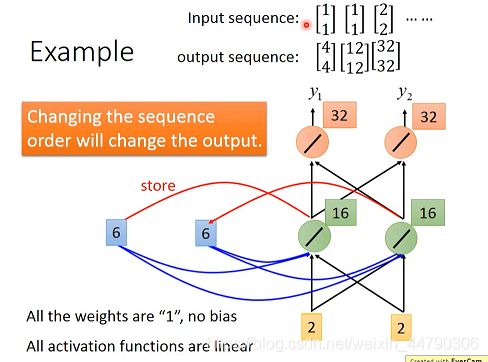
注意:在RNN中,改变输入序列的顺序,将会改变输出。
2.3 RNN 处理slots filling问题
注意:下图中同一个RNN在三个不同时间点被分别使用了三次,并非是三个不同的NN。

- “arrive”的vector作为x1输入RNN,通过hidden layer生成a1,再根据a1生成y1,表示“arrive”属于每个slot的概率,其中a1会被存储到memory中
- “Taipei”的vector作为x2输入RNN,此时hidden layer同时考虑和存放在memory中的a1,生成a2,再根据a2生成y2,表示“Taipei”属于某个slot的概率,此时再把a2存到memory中
- 以此类推即可
 即使输入同样是“Taipei”,我们依旧可以根据前文的“leave”或“arrive”来得到不一样的输出。
即使输入同样是“Taipei”,我们依旧可以根据前文的“leave”或“arrive”来得到不一样的输出。
2.4 RNN有不同的变形
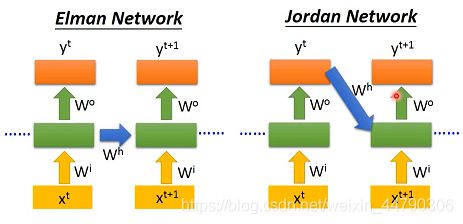
Elman Network:将hidden layer的输出保存在memory里,在下一个时间点读出来
Jordan Network:将整个neural network的输出保存在memory里,在下一个时间点读出来
2.5 Bidirectional RNN
RNN 还可以是双向的,你可以同时训练一对正向和反向的RNN,把它们对应的hidden layer x t x^t xt 拿出来,都接给一个output layer,得到最后的 y t y^t yt。
双向RNN的好处:NN在产生输出的时候,它能够看到的范围是比较广的,这就相当于RNN在看了整个句子之后,才决定每个词汇具体要被分配到哪一个槽中,这会比只看句子的前一半要更好。
3. Long Short-term Memory(LSTM)
前文提到的RNN只是最简单的版本,并没有对memory的管理多加约束,可以随时进行读取,而现在常用的memory管理方式叫做长短期记忆(Long Short-term Memory),简称LSTM。
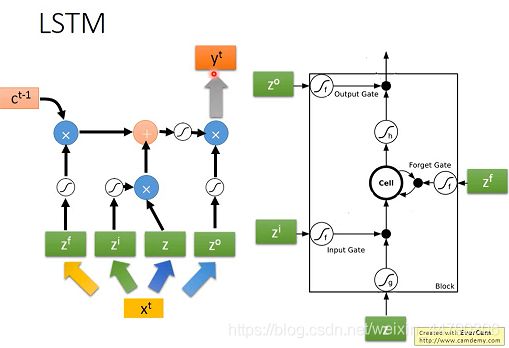
3.1 three gate
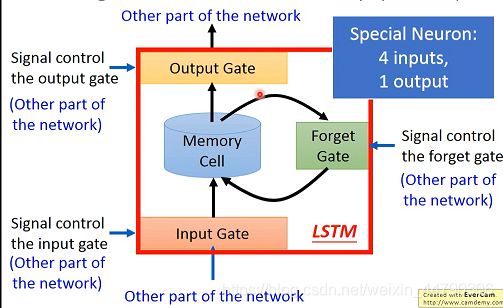
neutral的input想要写入内存前需要经过一系列的闸门。
input gate:打开的时候neutral的input才可以被写入内存
output gate:外界其他的neutral是否可以通过内存读出值。
forget gate(遗忘门):什么时候内存要把过去的东西忘掉
以上三个gate都是需要NN网络自己学习。
LSTM可以看作有四个input,一个output
- 4个input=想要被存到memory cell里的值+操控input gate的信号+操控output gate的信号+操控forget gate的信号
- 1个output=想要从memory cell中被读取的值
3.2 Memory Cell
如果从表达式的角度看LSTM,它比较像下图中的样子:
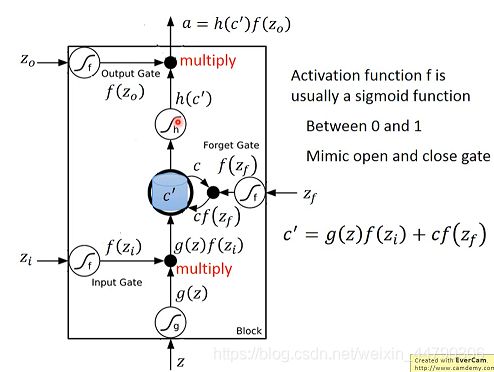
- z是想要被存到cell里的输入值
- zi是操控input gate的信号
- zo是操控output gate的信号
- zf是操控forget gate的信号
- a是综合上述4个input得到的output值
把z、zi、zo、zf通过activation function,分别得到g(z)、f(zi)、f(zo)、f(zf),其中对zi、zo和zf来说,它们通过的激活函数一般会选sigmoid function,因为它的输出在0~1之间,代表gate门被打开的程度。
令g(z)与f(zi)相乘得到g(z)f(zi),然后把原先存放在cell中的c与f(zf)相乘得到cf(zf),两者相加得到存在memory中的新值c’ = g(z)f(zi) + cf(zf)。
- 若f(zi) = 0,则相当于没有输入,若f(zi) = 1,则相当于直接输入g(z)
- 若f(zf) = 1,则保存原来的值c并加到新的值上,若f(zf) = 0,则旧的值将被遗忘清除
从中也可以看出,forget gate的逻辑与我们的直觉是相反的,控制信号打开表示记得,关闭表示遗忘。
3.3 LSTM Example
下图演示了一个LSTM的基本过程,x1、x2、x3是输入序列,y是输出序列,基本原则是:
- 当时x2=1,将x1的值写入memory
- 当时x2=-1,将memory里的值清零
- 当时x3=1,将memory里的值输出

具体举个实例如下:
图上标记出来的权重假设是已经训练好的参数

完整流程:(假想已知参数,不用梯度下降了)
依次输入310,420,200,101,3-10

3.4 传统神经网络和LSTM的区别
传统的神经网络

LSTM
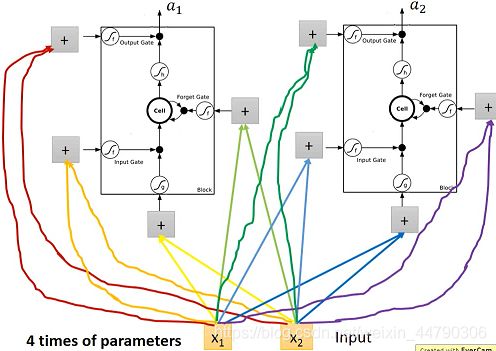
在原来的neuron里,1个input对应1个output,而在LSTM里,4个input才产生1个output,并且所有的input都是不相同的,从中也可以看出LSTM所需要的参数量是一般NN的4倍。
3.5 LSTM for RNN

假设我们现在有一整排的LSTM作为neuron,每个LSTM的cell里都存了一个scalar值,把所有的scalar连接起来就组成了一个vector c ( t − 1 ) c ^( t-1) c(t−1),在时间点t,输入了一个vector xt ,它会乘上一个matrix,通过转换得到z,而z的每个dimension就代表了操控每个LSTM的输入值。
同理经过不同的转换得到操控每个LSTM的门信号,同理经过不同的转换得到zi、zf和zo,得到操控每个LSTM的门信号。
下图是单个LSTM的运算情景,其中LSTM的4个input分别是z、zi、zf和zo的其中1维,每个LSTM的cell所得到的input都是各不相同的,但它们却是可以一起共同运算的,整个运算流程如图:
把hidden layer的最终输出yt以及当前cell的值ct都连接到下一个时间点的输入上。
因此在下一个时间点操控这些gate值,不只是看输入的 x ( t + 1 ) x ^(t+1) x(t+1),还要看前一个时间点的输出ht和cell值ct,你需要把 x ( t + 1 ) x ^(t+1) x(t+1)、ht和ct这3个vector并在一起,乘上4个不同的转换矩阵,去得到LSTM的4个输入值z、zi、zf、zo,再去对LSTM进行操控。
注意:下图是同一个LSTM在两个相邻时间点上的情况

3.6 Multiple-layer LSTM
上图是单个LSTM作为neuron的情况,事实上LSTM基本上都会叠多层,如下图所示,左边两个LSTM代表了两层叠加,右边两个则是它们在下一个时间点的状态。

4. Learning Target
4.1 Loss Function(损失函数)
依旧是Slot Filling的例子,我们需要把model的输出yi与映射到slot的reference vector求交叉熵,比如“Taipei”对应到的是“dest”这个slot,则reference vector在“dest”位置上值为1,其余维度值为0,其他词同理。

RNN的output和reference vector的cross entropy之和就是损失函数,也是要minimize的对象,需要注意的是,word要依次输入model,比如“arrive”必须要在“Taipei”前输入,不能打乱语序。
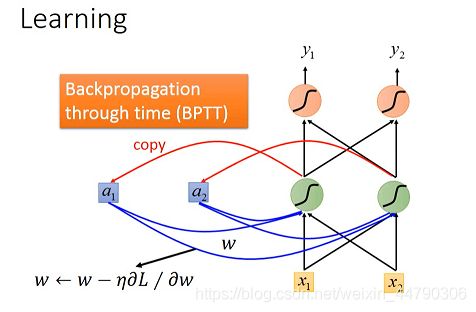
4.2 Training(训练)
有了损失函数后,训练其实也是用梯度下降法,为了计算方便,这里采取了反向传播(Backpropagation)的进阶版,Backpropagation through time,在high sequence上做运算,所以BPTT要考虑时间的信息。
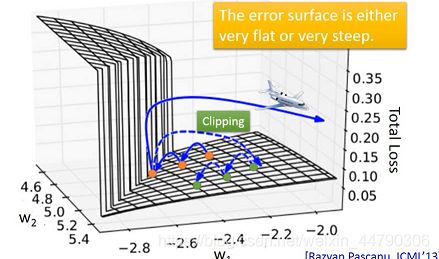
事实上RNN的训练并没有那么容易,我们希望随着epoch的增加,参数的更新,loss应该要像下图的蓝色曲线一样慢慢下降,但在训练RNN的时候,你可能会遇到类似绿色曲线一样的学习曲线,loss剧烈抖动,并且会在某个时刻跳到无穷大,导致程序运行失败。如下图:

4.3 分析 error surface

RNN的error surface,即loss由于参数产生的变化,是非常陡峭崎岖的,上图中,z轴代表loss,x轴和y轴代表两个参数w1和w2,可以看到loss在某些地方非常平坦,在某些地方又非常的陡峭。
如果此时你的训练过程类似下图中从下往上的橙色的点,它先经过一块平坦的区域,又由于参数的细微变化跳上了悬崖,这就会导致loss上下抖动得非常剧烈;如果你的运气特别不好,一脚踩在悬崖上,在悬崖上的gradient很大,但是之前的gradient很小learning rate很大,所以现在很大的gradient乘以很大的learning rate,导致参数update很大,起飞。
解决方法——clipping
设置一个阈值,高于这个阈值的值就都设置为这个阈值。
当gradient即将大于某个threshold的时候,就让它停止增长,比如当gradient大于15的时候就直接让它等于15。
4.4 Why RNN 不好 Training ?
举一个最简单的RNN的例子:
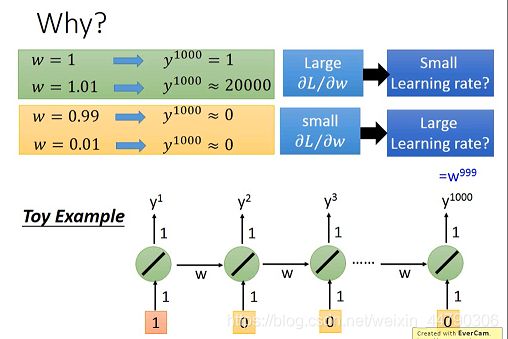
RNN的训练问题来自于,把同样的东西反复使用,w的改变可能会几乎没有影响(上图下面的情况),有影响的话就会是很严重的影响。(上图上面的情况)。
RNN经常会遇到这两个问题:
- 梯度消失(gradient vanishing),一直在梯度平缓的地方停滞不前
- 梯度爆炸(gradient explode),梯度的更新步伐迈得太大导致直接飞出有效区间
RNN不好训练的原因不在于激活函数,而是来自于他有high sequence,同样的weight在不同的时间点被反复地使用。
4.5 Helpful Techniques
有什么技巧可以帮我们解决这个问题呢?
LSTM就是最广泛使用的技巧,它会把error surface上那些比较平坦的地方去掉,从而解决梯度消失(gradient vanishing)的问题。但是不能解决梯度爆炸(gradient explode)的问题,在使用LSTM的时候,大部分地方都是变化很剧烈地,所以需要把learning rate设置的很小,进行训练。

大厂面试问题:
Q问:为什么要把RNN换成LSTM?
A 答:LSTM可以解决梯度消失的问题
Q问:为什么LSTM能够解决梯度消失的问题?
A答:RNN和LSTM对memory的处理其实是不一样的:
- 在RNN中,每个新的时间点,memory里的旧值都会被新值所覆盖
- 在LSTM中,每个新的时间点,memory里的值会乘上f(gf)与新值相加
对RNN来说,weight 对memory的影响每次都会被清除,而对LSTM来说,除非forget gate被打开,否则weight对memory的影响就不会被清除,而是一直累加保留,因此它不会有梯度消失的问题。
关键点:用LSTM overfitting严重,可以尝试改用GRU
4.6 GRU (Gated Recurrent Unit)
另一个版本GRU (Gated Recurrent Unit),只有两个gate,需要的参数量比LSTM少,并且不容易 overfitting,它的基本精神是旧的不去,新的不来,GRU会把input gate和forget gate连起来,当forget gate把memory里的值清空时,input gate才会打开,再放入新的值。此外,还有很多技术可以用来处理梯度消失的问题,比如Clockwise RNN、SCRN等。
神奇的地方:
- 当用一般RNN的网络时候,用单位矩阵初始化transition matrix weight转换矩阵的权重,再使用ReLU的激活函数的时候,可以得到很好的效果。
- 一般的训练方法,初始化weight是random的时候,ReLU与sigmoid相比,sigmoid的效果会更好,但是如果用单位矩阵初始化transition matrix weight转换矩阵的权重的情况下,使用ReLU效果更好。
5. RNN的应用
5.1 输入和输出都是一个向量序列
在Slot Filling中,我们输入一个word vector输出它的label,除此之外RNN还可以做更复杂的事情。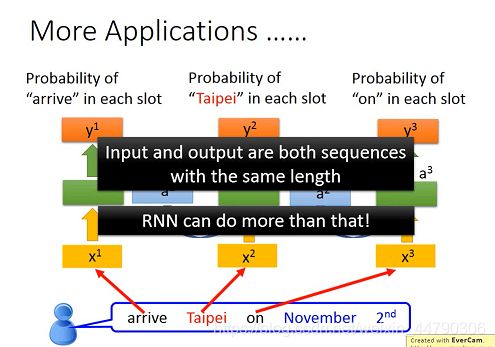
5.2(Many to one)输入一个向量序列,输出是一个向量,多对一
语义情绪分析,我们可以把某影片相关的文章爬下来,并分析其正面情绪or负面情绪,RNN的输入是字符序列,在不同时间点输入不同的字符,并在最后一个时间点输出该文章的语义情绪。

关键词分析,RNN可以分析一篇文章并提取出其中的关键词,这里需要把含有关键词标签的文章作为RNN的训练数据。

5.3 (Many to many)输入和输出都是向量序列,但是输出更短,多对多
以语音识别为例,输入是一段声音信号,每隔一小段时间就 用1个vector来表示,因此输入为vector sequence,而输出则是character sequence。
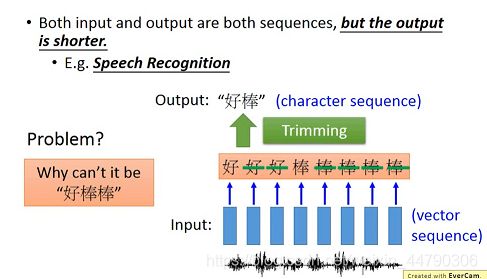
如果依旧使用Slot Filling的方法,只能做到每个vector对应1个输出的character,识别结果就像是下图中的“好好好棒棒棒棒棒”,但这不是我们想要的,可以使用Trimming的技术把重复内容消去,剩下“好棒”。
但“好棒”和“好棒棒”实际上是不一样的,如何区分呢?
需要用到CTC算法,它的基本思想是,输出output的不只是字符,还要填充NULL,输出的时候去掉NULL就可以得到连词的效果。
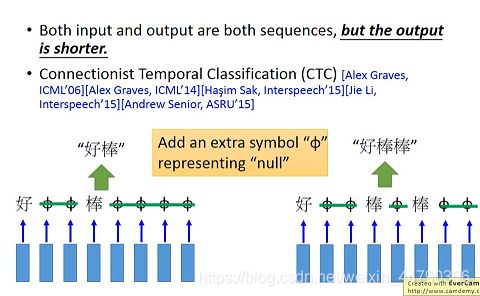
CTC怎么做训练
枚举,把所有可能的都假设做正确的(有巧妙的方法,此处不细讲)

CTC的示例,RNN的输出就是英文字母+NULL,google的语音识别系统就是用CTC实现的,如下图:
5.4 输入和输出都是向量序列,向量长度不同,多对多,sequence to sequence learning
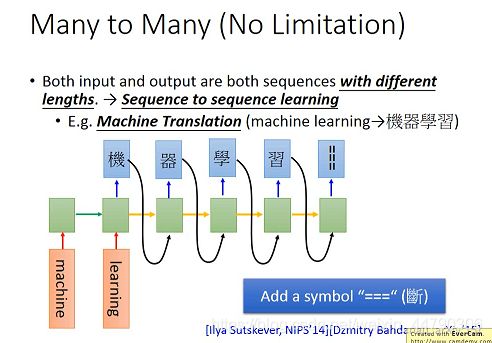
输出正确结果后它不会停下来,给它加一个“===”的符号,代表任务结束。
6. RNN vs Structured Learning
RNN,LSTM vs HMM,CRF,SVM
没有考虑整个语句 考虑了整个语句
cost和error不总是相关 cost和error相关
可以deep 并不一定not always deep

Integrated Together
输入先通过RNN,LSTM,输出再作为HMM,CRF的输入。
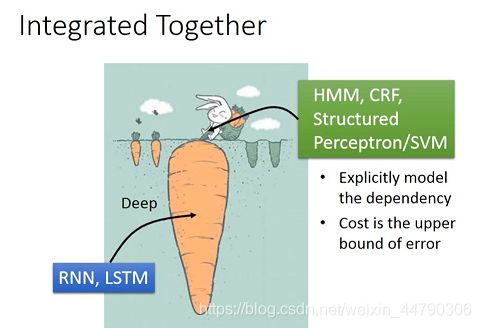
二者可以一起 Learning的,可以一起梯度下降。
在语音识别里的结合,是怎么work的呢?(这里需要去听HMM的工作原理)

总结与展望
本章学习了RNN和LSTM:从Slot Filling案例引出我们需要有记忆力的神经网络RNN,基本的RNN结构已经可以实现记忆了,但是我们一般使用的是LSTM结构,了解了LSTM的组成,工作原理与过程,之所以使用LSTM是因为RNN的训练并没有那么容易,一般的RNN会出现gradient vanishing和gradient explode,使用LSTM它会把error surface上那些比较平坦的地方拿掉,从而解决梯度消失(gradient vanishing)的问题,而gradient explode的解决可以将学习率调小。最后,未来的发展趋势一定是deep与Structured 的结合。