经典CNN模型介绍及Pytorch实现
文章目录
- 前言
- 一、LeNet
-
- 1. LeNet介绍
- 2. LeNet核心代码
- 3. LeNet在MNIST上测试
- 二、AlexNet
-
- 1. AlexNet介绍
- 2. AlexNet核心代码
- 3. AlexNet在MNIST上测试
- 三、VGGNet
-
- 1. VGGNet介绍
- 2. VGGNet核心代码
- 3. VGGNet在MNIST上测试
- 四、GoogLeNet
-
- 1. GoogLeNet介绍
- 2. GoogLeNet核心代码
- 3. GoogLeNet在MNIST上测试
- 五、ResNet
-
- 1. ResNet介绍
- 2. ResNet核心代码
- 六、卷积神经网络的一些说明
-
- 1. 卷积层输出维度的计算公式
- 2. 激励层的实践经验
前言
本文主要介绍了一些经典的卷积神经网络模型,包括LeNet、AlexNet、VGGNet、GoogLeNet和ResNet,其中前三个模型属于单分支网络结构,后两个模型属于多分支网络结构。
一、LeNet
1. LeNet介绍
Yann Lecun在1988年提出的LeNet是早期具有代表性的一个卷积神经网络。LeNet-5网络模型已经使用了近些年卷积神经网络中能见到的几乎所有基础操作,包括卷积层、池化层和反向传播训练方法等。
当时Lecun使用该网络模型帮助银行识别文档中的手写数字,输入的图像仅有32像素×32像素大小而且是灰度图像。该模型结构受限于当时的计算能力,不能用来设计为更加复杂的模型,也不能处理更大的图像。
2. LeNet核心代码
LeNet-5网络结构核心代码如下:
import torch.nn as nn
import torch.nn.functional as F
#Lenet network
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5) #in_channels, out_channels, kernel_size, stride=1 ...
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, num_classes)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), kernel_size=(2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), kernel_size=(2, 2))
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
3. LeNet在MNIST上测试
LeNet在MNIST上测试代码如下:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
# batch*1*28*28(每次会送入batch个样本,输入通道数1(黑白图像),图像分辨率是28x28)
# 下面的卷积层Conv2d的第一个参数指输入通道数,第二个参数指输出通道数,第三个参数指卷积核的大小
self.conv1 = torch.nn.Conv2d(1, 6, 5) # 输入通道数1,输出通道数6,核的大小5
self.conv2 = torch.nn.Conv2d(6, 16, 5) # 输入通道数6,输出通道数16,核的大小5
# 下面的全连接层Linear的第一个参数指输入通道数,第二个参数指输出通道数
self.fc1 = torch.nn.Linear(16*4*4, 120) # 输入通道数是16*4*4,输出通道数是120
self.fc2 = torch.nn.Linear(120, 84) # 输入通道数是120,输出通道数是84,即10分类
self.fc3 = torch.nn.Linear(84, 10) # 输入通道数是84,输出通道数是10,即10分类
def forward(self, x):
in_size = x.size(0) # 在本例中in_size=512,也就是BATCH_SIZE的值。输入的x可以看成是512*1*28*28的张量。
out = self.conv1(x) # batch*1*28*28 -> batch*6*24*24(28x28的图像经过一次核为5x5的卷积,输出变为24x24)
out = F.relu(out) # batch*6*24*24(激活函数ReLU不改变形状))
out = F.avg_pool2d(out, 2, 2) # batch*6*24*24 -> batch*6*12*12(2*2的池化层会减半)
out = self.conv2(out) # batch*6*12*12 -> batch*16*8*8(再卷积一次,核的大小是5)
out = F.relu(out) # batch*20*10*10
out = F.avg_pool2d(out, 2, 2) # batch*16*8*8 -> batch*16*4*4(2*2的池化层会减半)
out = out.view(in_size, -1) # batch*16*4*4 -> batch*256(out的第二维是-1,说明是自动推算,本例中第二维是16*4*4)
out = self.fc1(out) # batch*256 -> batch*120
out = F.relu(out) # batch*120
out = self.fc2(out) # batch*120 -> batch*84
out = F.relu(out)
out = self.fc3(out) # batch*84 -> batch*10
out = F.log_softmax(out, dim=1) # 计算log(softmax(x))
return out
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.4f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
print('\nAccuracy: {}/{} ({:.4f}%)\n'.format(
correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
BATCH_SIZE = 512 # 大概需要2G的显存
EPOCHS = 10 # 总共训练批次
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=BATCH_SIZE)
test_datasets = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_datasets,
shuffle=False,
batch_size=BATCH_SIZE)
model = Net().to(DEVICE)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)
运行10次后模型精度达到98.58%。
二、AlexNet
1. AlexNet介绍
在LeNet之后,随着计算能力的提升,研究者不断地提升模型的表达能力。最明显的是卷积层数的增加,每一层的内部通道数目也在增加。其中的一个经典网络模型就是2012年ImageNet竞赛的冠军AlexNet。AlexNet凭借深度学习方法打败了以往所有传统的特征算法(包括SIFT),并且准确率大幅提高。
AlexNet成功的另一个原因是ImageNet数据集的出现。在大数据时代,深度模型的学习离不开大量数据的训练,而此前一直没有能够让深度模型充分训练的大规模数据。AlexNet以绝对优势取得2012年ImageNet竞赛冠军后,使得深度学习逐渐成为学术研究热点,卷积神经网络称为计算机视觉任务上的主要模型。
2. AlexNet核心代码
AlexNet-7网络结构核心代码如下:
import torch.nn as nn
import torch.nn.functional as F
class AlexNet(nn.Module):
def __init__(self, num_classes=NUM_CLASSES):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 2 * 2, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 2 * 2)
x = self.classifier(x)
return x
3. AlexNet在MNIST上测试
AlexNet在MNIST上测试代码如下:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
# batch*1*28*28(每次会送入batch个样本,输入通道数1(黑白图像),图像分辨率是28x28)
# 下面的卷积层Conv2d的第一个参数指输入通道数,第二个参数指输出通道数,第三个参数指卷积核的大小
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5, stride=1, padding=2)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=3, stride=1, padding=1)
self.conv3 = torch.nn.Conv2d(20, 40, kernel_size=3, stride=1, padding=1)
self.conv4 = torch.nn.Conv2d(40, 40, kernel_size=3, stride=1, padding=1)
self.conv5 = torch.nn.Conv2d(40, 20, kernel_size=3, stride=1, padding=1)
# 下面的全连接层Linear的第一个参数指输入通道数,第二个参数指输出通道数
self.fc1 = torch.nn.Linear(20*7*7, 400)
self.fc2 = torch.nn.Linear(400, 100)
self.fc3 = torch.nn.Linear(100, 10)
self.droupout = torch.nn.Dropout(p=0.5)
def forward(self, x):
in_size = x.size(0)
out = self.conv1(x)
out = F.relu(out)
out = F.max_pool2d(out, 2, 2)
out = self.conv2(out)
out = F.relu(out)
out = F.max_pool2d(out, 2, 2)
out = self.conv3(out)
out = F.relu(out)
out = self.conv4(out)
out = F.relu(out)
out = self.conv5(out)
out = F.relu(out)
out = out.view(in_size, -1)
out = self.droupout(out)
out = self.fc1(out)
out = F.relu(out)
out = self.droupout(out)
out = self.fc2(out)
out = F.relu(out)
out = self.fc3(out)
out = F.log_softmax(out, dim=1)
return out
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.4f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
print('\nAccuracy: {}/{} ({:.4f}%)\n'.format(
correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
BATCH_SIZE = 512 # 大概需要2G的显存
EPOCHS = 10 # 总共训练批次
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=BATCH_SIZE)
test_datasets = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_datasets,
shuffle=False,
batch_size=BATCH_SIZE)
model = Net().to(DEVICE)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)
运行10次后模型精度达到99.08%。
三、VGGNet
1. VGGNet介绍
Simonyan和Zisserman在2014年的ImageNet竞赛中使用了19层的网络结构VGGNet,比AlexNet的7层网络结构增加两倍多。尽管VGGNet使用了如此多的参数,其依然没有夺得ImageNet竞赛的冠军。但是该网络结构的16层版本在学术界被广泛使用,并在其他如目标检测、目标语义分割等视觉任务上取得了显著的效果。
2. VGGNet核心代码
VGGNet网络结构核心代码如下:
import torch.nn as nn
import torch.nn.functional as F
def VGGNet():
def VGGLayers(configs):
channels = 1 # 输入通道数
layers = []
# 根据配置,将多个VGGBlock串联在一起组成VGGNet
for (N, C) in configs:
# 每个block指定N个卷积层,每层通道数是C个
for _ in range(N):
conv = torch.nn.Conv2d(channels, C, kernel_size=3, padding=1)
layers += [conv, torch.nn.ReLU(inplace=True)]
channels = C
layers += [torch.nn.MaxPool2d(kernel_size=2, stride=2)]
return torch.nn.Sequential(*layers)
net = nn.Sequential(
VGGLayers(configs=[(2, 64), (2, 128), (3, 256), (3, 512), (3, 512)]),
nn.Flatten(),
nn.Linear(512*7*7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 1000)
)
return net
3. VGGNet在MNIST上测试
VGGNet在MNIST上测试代码如下:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
def VGGLayers(configs):
channels = 1 # 输入通道数
layers = []
# 根据配置,将多个VGGBlock串联在一起组成VGGNet
for (N, C) in configs:
# 每个block指定N个卷积层,每层通道数是C个
for _ in range(N):
conv = torch.nn.Conv2d(channels, C, kernel_size=3, padding=1)
layers += [conv, torch.nn.ReLU(inplace=True)]
channels = C
layers += [torch.nn.MaxPool2d(kernel_size=2, stride=2)]
return torch.nn.Sequential(*layers)
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
# batch*1*28*28(每次会送入batch个样本,输入通道数1(黑白图像),图像分辨率是28x28)
# 下面的卷积层Conv2d的第一个参数指输入通道数,第二个参数指输出通道数,第三个参数指卷积核的大小
self.VGG = VGGLayers(configs=[(2, 6), (3, 16)])
# 下面的全连接层Linear的第一个参数指输入通道数,第二个参数指输出通道数
self.fc1 = torch.nn.Linear(16*7*7, 500)
self.fc2 = torch.nn.Linear(500, 200)
self.fc3 = torch.nn.Linear(200, 10)
self.droupout = torch.nn.Dropout(p=0.5)
def forward(self, x):
in_size = x.size(0) # 在本例中in_size=512,也就是BATCH_SIZE的值。输入的x可以看成是512*1*28*28的张量。
out = self.VGG(x)
out = out.view(in_size, -1)
out = self.fc1(out)
out = F.relu(out)
out = self.droupout(out)
out = self.fc2(out)
out = F.relu(out)
out = self.droupout(out)
out = self.fc3(out)
out = F.log_softmax(out, dim=1) # 计算log(softmax(x))
return out
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.4f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
print('\nAccuracy: {}/{} ({:.4f}%)\n'.format(
correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
BATCH_SIZE = 512 # 大概需要2G的显存
EPOCHS = 10 # 总共训练批次
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=BATCH_SIZE)
test_datasets = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_datasets,
shuffle=False,
batch_size=BATCH_SIZE)
model = Net().to(DEVICE)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)
运行10次后模型精度达到99.07%。
四、GoogLeNet
1. GoogLeNet介绍
GoogLeNet在2014年的ImageNet竞赛中夺冠并取得了6.7%的Top-5分类错误率。目前在ImageNet数据集上人类识别的Top-5错误率为5.1%,GoogLeNet的结果表明卷积神经网络模型在该数据集上已经逼近人类的识别能力。GoogLeNet网络结构如下图所示:
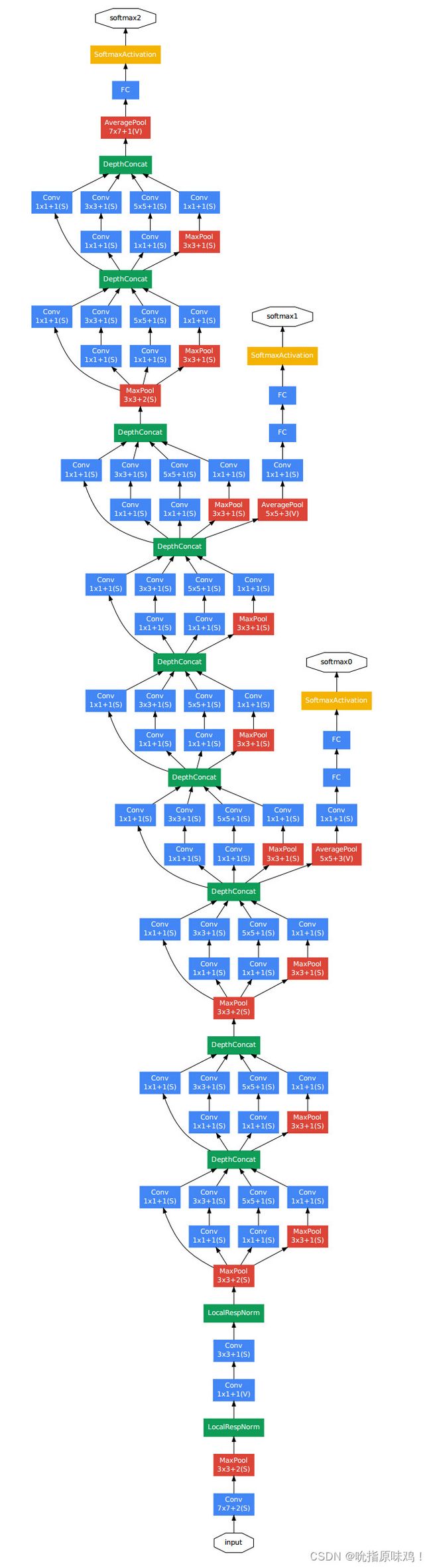
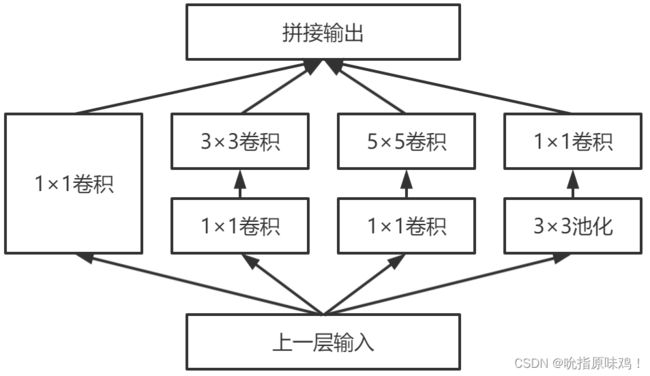
GoogLeNet网络使用多个基本组成模块组成最终的卷积神经网络,该基本组成模块被GoogLeNet提出者称为Inception模块。GoogLeNet提出者之后又提出多个改进版本的网络结构,主要也是在Inception模块的基础上改进。原始的Inception模块如下图所示,包含几种不同大小的卷积层,即1×1卷积层、3×3卷积层和5×5卷积层,还包括一个3×3的最大池化层。这些卷积层和池化层得到的特征拼接在一起作为最终的输出,同时也是下一个模块的输入。
2. GoogLeNet核心代码
GoogLeNet网络结构核心代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class Inception(nn.Module):
"""
1、输入通过Inception模块的4个分支分别计算,得到的输出宽和高相同(因为使用了padding),而通道不同。
2、将4个分支的通道进行简单的合并,即得到Inception模块的输出。
3、每次卷积之后都使用批正则化`BatchNorm2d`,并使用relu函数进行激活。
"""
def __init__(self, in_planes, n1x1, n3x3red, n3x3, n5x5red, n5x5, pool_planes):
super(Inception, self).__init__()
# 1x1 conv branch
self.b1 = nn.Sequential(
nn.Conv2d(in_planes, n1x1, kernel_size=1),
nn.BatchNorm2d(n1x1),
nn.ReLU(True),
)
# 1x1 conv -> 3x3 conv branch
self.b2 = nn.Sequential(
nn.Conv2d(in_planes, n3x3red, kernel_size=1),
nn.BatchNorm2d(n3x3red),
nn.ReLU(True),
nn.Conv2d(n3x3red, n3x3, kernel_size=3, padding=1),
nn.BatchNorm2d(n3x3),
nn.ReLU(True),
)
# 1x1 conv -> 5x5 conv branch
self.b3 = nn.Sequential(
nn.Conv2d(in_planes, n5x5red, kernel_size=1),
nn.BatchNorm2d(n5x5red),
nn.ReLU(True),
# 2个3x3卷积代替1个5x5卷积
nn.Conv2d(n5x5red, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5),
nn.ReLU(True),
nn.Conv2d(n5x5, n5x5, kernel_size=3, padding=1),
nn.BatchNorm2d(n5x5),
nn.ReLU(True),
)
# 3x3 pool -> 1x1 conv branch
self.b4 = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
nn.Conv2d(in_planes, pool_planes, kernel_size=1),
nn.BatchNorm2d(pool_planes),
nn.ReLU(True),
)
def forward(self, x):
y1 = self.b1(x)
y2 = self.b2(x)
y3 = self.b3(x)
y4 = self.b4(x)
return torch.cat([y1, y2, y3, y4], 1)
class GoogLeNet(nn.Module):
def __init__(self):
super(GoogLeNet, self).__init__()
self.pre_layers = nn.Sequential(
nn.Conv2d(3, 192, kernel_size=3, padding=1),
nn.BatchNorm2d(192),
nn.ReLU(True),
)
self.a3 = Inception(192, 64, 96, 128, 16, 32, 32)
self.b3 = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
self.a4 = Inception(480, 192, 96, 208, 16, 48, 64)
self.b4 = Inception(512, 160, 112, 224, 24, 64, 64)
self.c4 = Inception(512, 128, 128, 256, 24, 64, 64)
self.d4 = Inception(512, 112, 144, 288, 32, 64, 64)
self.e4 = Inception(528, 256, 160, 320, 32, 128, 128)
self.a5 = Inception(832, 256, 160, 320, 32, 128, 128)
self.b5 = Inception(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AvgPool2d(8, stride=1)
self.linear = nn.Linear(1024, 10)
def forward(self, x):
out = self.pre_layers(x)
out = self.a3(out)
out = self.b3(out)
out = self.maxpool(out)
out = self.a4(out)
out = self.b4(out)
out = self.c4(out)
out = self.d4(out)
out = self.e4(out)
out = self.maxpool(out)
out = self.a5(out)
out = self.b5(out)
out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
3. GoogLeNet在MNIST上测试
GoogLeNet在MNIST上测试代码如下:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
class Inception(torch.nn.Module):
# Inception模块
# 输入ninput:输入通道数
# 输入n1:第一个1×1卷积核分支的输出通道数
# 输入n3pre和n3:第二个3×3卷积核分支的输出通道数
# 输入n5pre和n5:第三个5×5卷积核分支的输出通道数
# 输入npool:第四个池化层分支的输出通道数
def __init__(self, ninput, n1, n3pre, n3, n5pre, n5, npool):
super(Inception, self).__init__()
self.b1 = torch.nn.Sequential(
torch.nn.Conv2d(ninput, n1, kernel_size=1),
torch.nn.ReLU(inplace=True)
)
self.b2 = torch.nn.Sequential(
torch.nn.Conv2d(ninput, n3pre, kernel_size=1),
torch.nn.ReLU(inplace=True),
torch.nn.Conv2d(n3pre, n3, kernel_size=3, padding=1)
)
self.b3 = torch.nn.Sequential(
torch.nn.Conv2d(ninput, n5pre, kernel_size=1),
torch.nn.ReLU(inplace=True),
torch.nn.Conv2d(n5pre, n5, kernel_size=5, padding=2),
torch.nn.ReLU(inplace=True)
)
self.b4 = torch.nn.Sequential(
torch.nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(inplace=True)
)
def forward(self, x):
outpus = [self.b1(x), self.b2(x), self.b3(x), self.b4(x)]
return torch.cat(outpus, dim=1)
class Net(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(74, 20, kernel_size=5)
self.incep1 = Inception(10, 16, 16, 24, 16, 24, 24)
self.incep2 = Inception(20, 16, 16, 24, 16, 24, 24)
self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1344, 10)
def forward(self, x):
in_size = x.size(0)
out = F.relu(self.mp(self.conv1(x)))
out = self.incep1(out)
out = self.conv2(out)
out = self.mp(out)
out = F.relu(out)
out = self.incep2(out)
out = out.view(in_size, -1)
out = self.fc(out)
return out
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if (batch_idx + 1) % 30 == 0:
print('Train Epoch: {} [{}/{} ({:.4f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
print('\nAccuracy: {}/{} ({:.4f}%)\n'.format(
correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
if __name__ == '__main__':
BATCH_SIZE = 512 # 大概需要2G的显存
EPOCHS = 10 # 总共训练批次
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=BATCH_SIZE)
test_datasets = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_datasets,
shuffle=False,
batch_size=BATCH_SIZE)
# for i, img_data in enumerate(train_loader, 1):
# images, labels = img_data
# print('batch{0}:images shape info-->{1} labels-->{2}'.format(i, images.shape, labels))
model = Net().to(DEVICE)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)
运行10次后模型精度达到99.26%。
五、ResNet
1. ResNet介绍
从LeNet到AlexNet再到VGGNet,在ImageNet竞赛上网络深度有逐渐加深的趋势。在2015年的ImageNet竞赛上就出现了152层的网络结构,即ResNet,这远远超出GoogLeNet的22层和VGGNet的16层。ImageNet数据集的识别精度上,ResNet网络的表现超出了人类的认识水平,获得了3.57%的Top-5分类错误率。为了解决由于网络变深导致梯度小时/爆炸的问题,ResNet引入了跳层连接,该结构能够将网络加深到任意深度。
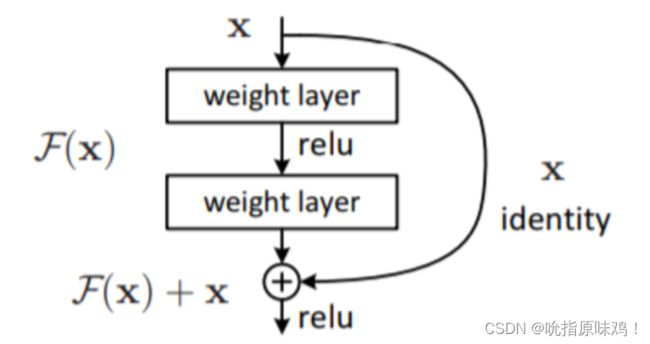
ResNet主要采用跳层连接组成残差模块,包括一个跳层连接和若干卷积层等操作。其中卷积层等操作主要学习一个原始输入x的补充值,参考资料中称为残差值。这样就可将单分支网络结构中的每几层变为双分支结构,增加的跳层连接分支是简单的Identity映射,即f(x)=x操作。残差模块如下图所示:
2. ResNet核心代码
网络结构核心代码如下:
import torch
import torch.nn as nn
# 3x3 convolution
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
# Residual block
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
# ResNet
class Net(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(Net, self).__init__()
self.in_channels = 16
self.conv = conv3x3(3, 16)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self.make_layer(block, 16, layers[0])
self.layer2 = self.make_layer(block, 32, layers[1], 2)
self.layer3 = self.make_layer(block, 64, layers[2], 2)
self.avg_pool = nn.AvgPool2d(8)
self.fc = nn.Linear(64, num_classes)
def make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if (stride != 1) or (self.in_channels != out_channels):
downsample = nn.Sequential(
conv3x3(self.in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels))
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels
for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.avg_pool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
六、卷积神经网络的一些说明
1. 卷积层输出维度的计算公式
如果你的步幅为 1,而且把零填充设置为:
Z e r o P a d d i n g = ( k − 1 ) / 2 Zero Padding=(k-1)/2 ZeroPadding=(k−1)/2
K 是过滤器尺寸,那么输入和输出就能保持一致的空间维度。
计算任意给定卷积层的输出的大小的公式是:
O = ( W − K + 2 P ) / S + 1 O=(W-K+2P)/S+1 O=(W−K+2P)/S+1
其中 O 是输出尺寸,K 是过滤器尺寸,P 是填充,S 是步幅。
2. 激励层的实践经验
①不要用sigmoid!不要用sigmoid!不要用sigmoid!
② 首先试RELU,因为快,但要小心点。
③ 如果2失效,请用Leaky ReLU或者Maxout。
④ 某些情况下tanh倒是有不错的结果,但是很少。