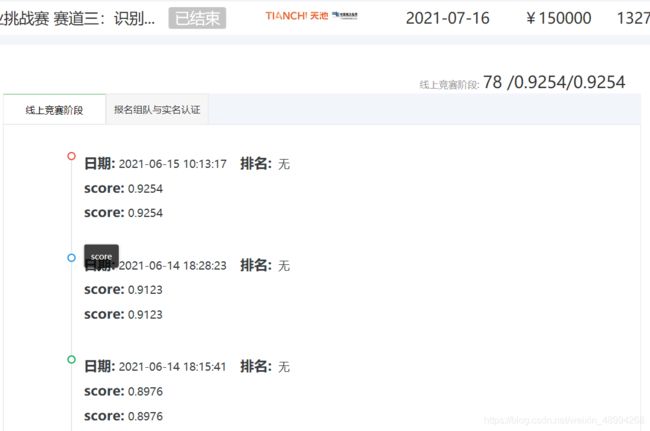
天池算法赛——广东电网智慧现场作业挑战赛 赛道三:识别高空作业及安全带佩戴
记录下第一次正式参加线上算法比赛的解题流程。虽然错过了B榜时间,但收获匪浅!
相关数据集及下文代码可见 识别高空作业及安全带_数据集及相关代码.txt
目录
- 项目介绍
- 数据处理
-
- 标签数据提取
- 标签数据集制作
- 模型训练
- 数据整合
- 可视化显示
- 继续改进思路
-
- 数据增强
-
- 赛道一二数据提取
- 最终结果
项目介绍
大赛链接:广东电网智慧现场作业挑战赛 赛道三:识别高空作业及安全带佩戴。

数据处理
标签数据提取
从csv中提取出标签数据转存成json文件,再将json文件转为单个的coco数据集格式标签,其中box坐标为归一化后的x,y,w,h。
(1)将csv数据标签存为json文件。(data_deal.py)根据具体文本格式改写自己的数据处理的代码。
'''
官方给出的csv中的
{
"meta":{},
"id":"88eb919f-6f12-486d-9223-cd0c4b581dbf",
"items":
[
{"meta":{"rectStartPointerXY":[622,2728],"pointRatio":0.5,"geometry":[622,2728,745,3368],"type":"BBOX"},"id":"e520a291-bbf7-4032-92c6-dc84a1fc864e","properties":{"create_time":1620610883573,"accept_meta":{},"mark_by":"LABEL","is_system_map":false},"labels":{"鏍囩":"ground"}}
{"meta":{"pointRatio":0.5,"geometry":[402.87,621.81,909,1472.01],"type":"BBOX"},"id":"2c097366-fbb3-4f9d-b5bb-286e70970eba","properties":{"create_time":1620610907831,"accept_meta":{},"mark_by":"LABEL","is_system_map":false},"labels":{"鏍囩":"safebelt"}}
{"meta":{"rectStartPointerXY":[692,1063],"pointRatio":0.5,"geometry":[697.02,1063,1224,1761],"type":"BBOX"},"id":"8981c722-79e8-4ae8-a3a3-ae451300d625","properties":{"create_time":1620610943766,"accept_meta":{},"mark_by":"LABEL","is_system_map":false},"labels":{"鏍囩":"offground"}}
],
"properties":{"seq":"1714"},"labels":{"invalid":"false"},"timestamp":1620644812068
}
'''
import pandas as pd
import json
import os
from PIL import Image
df = pd.read_csv("3train_rname.csv",header=None)
df_img_path = df[4]
df_img_mark = df[5]
# print(df_img_mark)
# 统计一下类别,并且重新生成原数据集标注文件,保存到json文件中
dict_class = {
"badge": 0,
"offground": 0,
"ground": 0,
"safebelt": 0
}
dict_lable = {
"badge": 1,
"offground": 2,
"ground": 3,
"safebelt": 4
}
data_dict_json = []
image_width, image_height = 0, 0
ids = 0
false = False # 将其中false字段转化为布尔值False
true = True # 将其中true字段转化为布尔值True
for img_id, one_img in enumerate(df_img_mark):
# print('img_id',img_id)
one_img = eval(one_img)["items"]
# print('one_img',one_img)
one_img_name = df_img_path[img_id]
img = Image.open(os.path.join("./", one_img_name))
# print(os.path.join("./", one_img_name))
ids = ids + 1
w, h = img.size
image_width += w
# print(image_width)
image_height += h
# print(one_img_name)
i=1
for one_mark in one_img:
# print('%d '%i,one_mark)
one_label = one_mark["labels"]['标签']
# print('%d '%i,one_label)
try:
dict_class[str(one_label)] += 1
# category = str(one_label)
category = dict_lable[str(one_label)]
bbox = one_mark["meta"]["geometry"]
except:
dict_class["badge"] += 1 # 标签为"监护袖章(红only)"表示类别"badge"
# category = "badge"
category = 1
bbox = one_mark["meta"]["geometry"]
i+=1
one_dict = {}
one_dict["name"] = str(one_img_name)
one_dict["category"] = category
one_dict["bbox"] = bbox
data_dict_json.append(one_dict)
print(image_height / ids, image_width / ids)
print(dict_class)
print(len(data_dict_json))
print(data_dict_json[0])
with open("./data.json2", 'w') as fp:
json.dump(data_dict_json, fp, indent=1, separators=(',', ': ')) # 缩进设置为1,元素之间用逗号隔开 , key和内容之间 用冒号隔开
fp.close()
生成data.json文件:
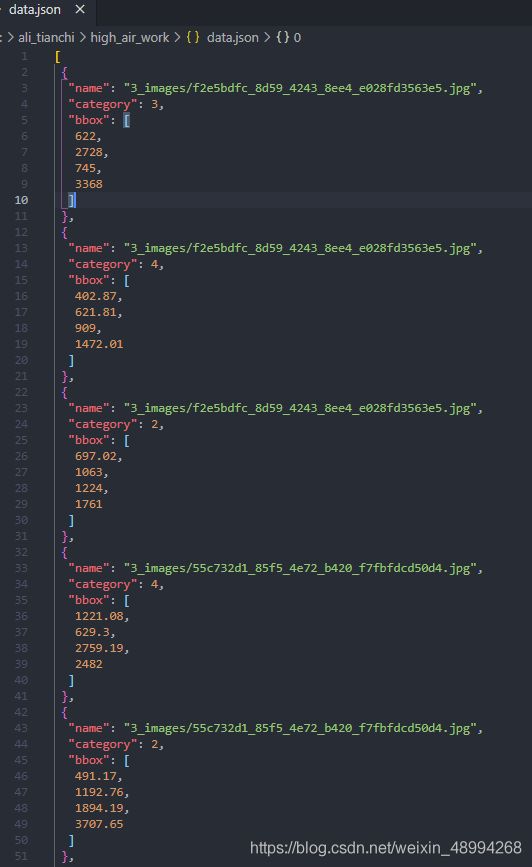
标签数据集制作
(2)将data.json文件按照coco数据的标签格式准备数据(将json文件按照图片的名称保存labels信息)json_to_txt.py 这里将所有的标签都减了一,可以不改,自己对的上就可以,当前标签:“badge”: 0,“offground”: 1,“ground”: 2,“safebelt”:3 bbox做了归一化(这个分数据集,有的数据集格式不一样,具体情况具体改)
import json
import os
import cv2
file_name_list = {}
with open("./data.json", 'r', encoding='utf-8') as fr:
data_list = json.load(fr)
file_name = ''
label = 0
[x1, y1, x2, y2] = [0, 0, 0, 0]
for data_dict in data_list:
for k,v in data_dict.items():
if k == "category":
label = v
if k == "bbox":
[x1, y1, x2, y2] = v
if k == "name":
file_name = v[9:-4]
if not os.path.exists('./data1/'):
os.mkdir('./data1/')
print('./3_images/' + file_name + '.jpg')
img = cv2.imread('./3_images/' + file_name + '.jpg')
size = img.shape # (h, w, channel)
dh = 1. / size[0]
dw = 1. / size[1]
x = (x1 + x2) / 2.0
y = (y1 + y2) / 2.0
w = x2 - x1
h = y2 - y1
x = x * dw
w = w * dw
y = y * dh
h = h * dh
# print(size)
# cv2.imshow('image', img)
# cv2.waitKey(0)
content = str(label-1) + " " + str(x) + " " + str(y) + " " + str(w) + " " + str(h) + "\n"
if not content:
print(file_name)
with open('./data1/' + file_name + '.txt', 'a+', encoding='utf-8') as fw:
fw.write(content)
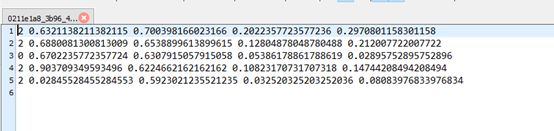
模型训练
参考:yolov5训练自己的数据集(一文搞定训练)
数据集划分(这里之前有一个步骤! 因为划分数据集的时候的脚本是按照文件名索引的,但是这次的图片的格式不止一种,所以在此之前先将所有的图片都改为统一的后缀:remane.py)
import os
class BatchRename():
# 批量重命名文件夹中的图片文件
def __init__(self):
self.path = './3_images' #表示需要命名处理的文件夹
def rename(self):
filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) #获取文件长度(个数)
print(total_num)
i = 1 #表示文件的命名是从1开始的
for item in filelist:
# print(item)
file_name=item.split('.',-1)[0]
# print(file_name)
src = os.path.join(os.path.abspath(self.path), item)
# print(src)
dst = os.path.join(os.path.abspath(self.path), file_name + '.jpg')
# print(dst)
try:
os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print ('total %d to rename & converted %d jpgs' % (total_num, i))
if __name__ == '__main__':
demo = BatchRename()
demo.rename()修改训练参数(路径及自己的类别)
训练
编写自己的detect.py文件(这里其实不用改,只需要将所需要的参数都存下来就行,都在检测结果中,detect.py文件里传入下面参数)

数据整合
检测出的结果(图片和所有的标签文件):
每个txt中存了当前图片检测出的cls bbox score:

我们要做的是按照主办方提供的测试数据的csv中的图片顺序,去到结果文件夹中索引对应的检测结果,并将所有的结果按照主办方给出的数据格式存到json文件中。result_imerge_2.py文件(这里由于训练数据标签与提交的标签并不完全相同,提交的结果必须是所属类的对应的人的标签,所以这里需要对结果整合,提取有用数据,目前我们的逻辑关系还需要进一步改善)
import pandas as pd
import json
import os
import copy
global data_dict_json
data_dict_json = []
def check_equip(id, equip_list, people_list, cls_result, cls_result2=-1):
for people in people_list:
dict4 = {}
dict_cls = {'image_id': id, 'category_id': -1, 'bbox': [], 'score': 0}
x1, y1, x2, y2, score2 = people
if equip_list:
for equip in equip_list:
dict1, dict2, dict3 = {}, {}, {}
equip_x1, equip_y1, equip_x2, equip_y2, score = equip
center_x = (int(equip_x1) + int(equip_x2)) / 2
center_y = (int(equip_y1) + int(equip_y2)) / 2
if center_x > int(x1) and center_x < int(x2) and center_y < int(y2) and center_y > int(y1):
dict1 = copy.deepcopy(dict_cls)
dict1['image_id'] = id
dict1['category_id'] = cls_result
dict1['bbox'] = list(map(int, people[:-1]))
dict1['score'] = float(score2)
if dict1['category_id'] != -1:
if not dict1 in data_dict_json:
data_dict_json.append(dict1)
dict2 = copy.deepcopy(dict_cls)
dict2['image_id'] = id
dict2['category_id'] = cls_result2
dict2['bbox'] = list(map(int, people[:-1]))
dict2['score'] = float(score2)
if dict2['category_id'] != -1:
if not dict2 in data_dict_json:
data_dict_json.append(dict2)
else:
dict3 = copy.deepcopy(dict3)
dict3['image_id'] = id
dict3['category_id'] = cls_result2
dict3['bbox'] = list(map(int, people[:-1]))
dict3['score'] = float(score2)
if dict3['category_id'] != -1:
if not dict3 in data_dict_json:
data_dict_json.append(dict3)
else:
dict4 = copy.deepcopy(dict_cls)
dict4['image_id'] = id
dict4['category_id'] = cls_result2
dict4['bbox'] = list(map(int, people[:-1]))
dict4['score'] = float(score2)
if dict4['category_id'] != -1:
if not dict4 in data_dict_json:
data_dict_json.append(dict4)
def save_json(file_lines):
badge_list = []
off_list = []
ground_list = []
safebelt_list = []
person_list=[]
for line in file_lines:
line2 = str(line.strip('\n'))
content = line2.split(' ', -1)
if int(content[0]) == 0:
badge_list.append(content[:])
elif int(content[0]) == 1:
off_list.append(content[:])
person_list.append(content[:-1])
elif int(content[0]) == 2:
ground_list.append(content[:])
person_list.append(content[:-1])
elif int(content[0]) == 3:
safebelt_list.append(content[:])
# print('+++++++',person_list)
return person_list
df = pd.read_csv("3_testa_user.csv", header=None)
df_img_path = df[0]
for id, one_img in enumerate(df_img_path):
# dict_data={}
file_name_img = (str(one_img)).split('/', -1)[1]
# print(file_name_img)
file_name_label = file_name_img.split('.', -1)[0] + '.txt'
# print(file_name_label)
path = os.path.join("./exp_epo50_089/labels/", file_name_label) # +file_name_label
file = open(path, 'r')
file_lines = file.readlines()
# print(id, file_lines)
person_list=save_json(file_lines)
dict1, dict2, dict3 = {}, {}, {}
for line in file_lines:
# dict1, dict2, dict3 = {}, {}, {}
# print('___+++___')
line2 = str(line.strip('\n'))
content = line2.split(' ', -1)
cls, equip_x1, equip_y1, equip_x2, equip_y2, score = content[:]
center_x = (int(equip_x1) + int(equip_x2)) / 2
center_y = (int(equip_y1) + int(equip_y2)) / 2
# print(content)
if int(content[0])==1:
dict3['image_id'] = int(id)
dict3['category_id'] = 3
dict3['bbox'] = list(map(int, content[1:-1]))
dict3['score'] = float(content[-1])
if dict3 not in data_dict_json:
data_dict_json.append(dict3)
elif int(content[0])==0:
for i in person_list:
print(i)
cls,x1,y1,x2,y2=i
if int(center_x)<int(x2) and int(x1)<int(center_x) and int(y1)<int(center_y) and int(center_y)<int(y2):
dict1['image_id'] = int(id)
dict1['category_id'] = 1
dict1['bbox'] = list(map(int, i[1:]))
# print(' ',list(map(int, i_list[1:-1])))
dict1['score'] = float(content[-1])
if dict1 not in data_dict_json:
data_dict_json.append(dict1)
elif int(content[0])==3:
for i in person_list:
cls,x1,y1,x2,y2=i
if int(center_x) < int(x2) and int(x1) < int(center_x) and int(y1) < int(center_y) and int(
center_y) < int(y2):
dict2['image_id'] = int(id)
dict2['category_id'] = 2
dict2['bbox'] = list(map(int, i[1:]))
dict2['score'] = float(content[-1])
if dict2 not in data_dict_json:
data_dict_json.append(dict2)
with open("./data_result2.json", 'w') as fp:
json.dump(data_dict_json, fp, indent=1, separators=(',', ': ')) # 缩进设置为1,元素之间用逗号隔开 , key和内容之间 用冒号隔开
fp.close()生成结果:data_result.json文件
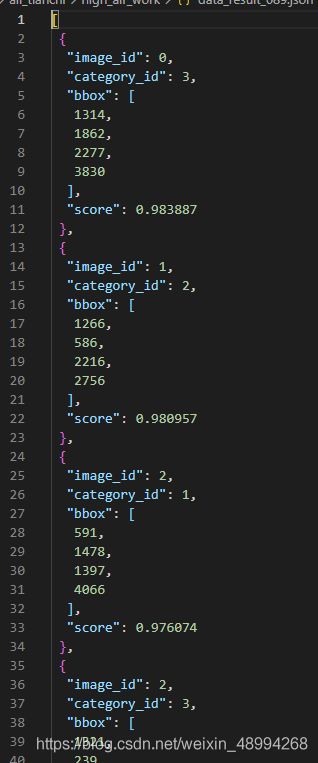
可视化显示
将最后的结果在原图上画出来。可以方便我们查看结果的正确程度。result_show.py
import cv2
import json
import os
import pandas as pd
file_name_list= {}
df = pd.read_csv("3_testa_user.csv",header=None)
# print(df[0][0])
dict_cls={1:'guarder',2:'safebeltperson',3:'offgroundperson'}
with open("data_resultcopy2.json",'r',encoding='utf-8')as fr:
data_list = json.load(fr)
# file_name = ''
# label = 0
# [x, y, w, h] = [0, 0, 0, 0]
i=0
for data_dict in data_list:
print(data_dict)
img_id = data_dict['image_id']
print(img_id)
file_path=df[0][img_id]
save_path='test_view_data_resultcopy2/'
if not os.path.exists(save_path):
os.mkdir(save_path)
save_name=save_path+str(i)+'_'+(str(df[0][img_id])).split('/',-1)[1]
print(save_name)
img = cv2.imread(file_path)
# cv2.imshow('a',img)
# cv2.waitKey(0)
cls=dict_cls[data_dict['category_id']]
score=data_dict['score']
x1,y1,x2,y2=data_dict['bbox']
# print(x1,y1,x2,y2)
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 0, 255), 2)
cv2.putText(img,str(cls)+' '+str(score),(x1,y1),cv2.FONT_HERSHEY_SIMPLEX,2,(0,0,255),3)
cv2.imwrite(save_name,img)
i+=1
继续改进思路
数据增强
观察得到offground与ground都是人。所以为了最后提交的人的框的准确度提高,将所有的offground与ground还有赛道一和二中的person类组成一个大的person数据集作为第4个标签。最后索引person类的bbox会更准确点。然后对于小目标袖标,我们将赛道一和二中的数据进行提取。
赛道一二数据提取
根据所给的csv标签,单独提取出袖标和person的标签数据,存入json文件。利用data_deal.py文件,如下:

对提出来的数据进行可视化:

将json标签转为归一化后的coco数据集格式json_to_txt.py
将原始数据集中的图片统一成jpg格式(方便划分数据集)
将所需的标签对应的图片copy出来,然后加到赛道三的数据中copy_file.py (继续将赛道二,赛道一都用该方法将袖标数据提出来,所要注意的是每个赛道的label要改的与官方提示一致)

最终结果