EasyNLP 发布融合语言学和事实知识的中文预训练模型 CKBERT
导读
预训练语言模型在NLP的各个应用中都有及其广泛的应用;然而,经典的预训练语言模型(例如BERT)缺乏对知识的理解,例如知识图谱中的关系三元组。知识增强预训练模型使用外部知识(知识图谱,字典和文本等)或者句子内部的语言学知识进行增强。我们发现,知识注入的过程都伴随着很大规模的知识参数,下游任务fine-tune的时候仍然需要外部数据的支撑才能达到比较好的效果,从而无法在云环境中很好的提供给用户进行使用。CKBERT(Chinese Knowledge-enhanced BERT)是EasyNLP团队自研的中文预训练模型,结合了两种知识类型(外部知识图谱,内部语言学知识)对模型进行知识注入,同时使得知识注入的方式方便模型可扩展。我们的实验验证也表明CKBERT的模型精度超越了多种经典中文模型。在本次的框架升级中,我们将多种规模的CKBERT模型贡献给开源社区,并且这些CKBERT模型与HuggingFace Models完全兼容。此外,用户也可以在阿里云机器学习平台PAI上方便地利用云资源使用CKBERT模型。
EasyNLP(https://github.com/alibaba/EasyNLP)是阿⾥云机器学习PAI 团队基于 PyTorch 开发的易⽤且丰富的中⽂NLP算法框架,⽀持常⽤的中⽂预训练模型和⼤模型落地技术,并且提供了从训练到部署的⼀站式 NLP 开发体验。EasyNLP 提供了简洁的接⼝供⽤户开发 NLP 模型,包括NLP应⽤ AppZoo 和预训练 ModelZoo,同时提供技术帮助⽤户⾼效的落地超⼤预训练模型到业务。由于跨模态理解需求的不断增加,EasyNLP也⽀持各种跨模态模型,特别是中⽂领域的跨模态模型,推向开源社区,希望能够服务更多的 NLP 和多模态算法开发者和研 究者,也希望和社区⼀起推动 NLP /多模态技术的发展和模型落地。
本⽂简要介绍CKBERT的技术解读,以及如何在EasyNLP框架、HuggingFace Models和阿里云机器学习平台PAI上使⽤CKBERT模型。
中文预训练语言模型概览
在这一节中,我们首先简要回顾经典的中文预训练语言模型。目前中文预训练语言模型主要包括了两种类型:
- 通用领域的预训练语言模型,主要包括了BERT、MacBERT和PERT等模型;
- 知识增强的中文预训练模型,主要包括了ERNIE-baidu,Lattice-BERT,K-BERT和ERNIE-THU等模型。
通用领域的预训练语言模型
BERT直接使用Google发布的基于中文维基文本语料进行训练的模型。MacBERT是BERT的改进版本,引入了纠错型掩码语言模型(MLM as correction,Mac)预训练任务,缓解了“预训练-下游任务”不一致的问题。在掩码语言模型(MLM)中,引入了[MASK]标记进行掩码,但[MASK]标记并不会出现在下游任务中。在MacBERT中,使用相似词来取代[MASK]标记。相似词通过Synonyms toolkit 工具获取,算法基于word2vec相似度计算。同时,MacBERT也引入了Whole Word Masking和N-gram Masking技术。当要对N-gram进行掩码时,会对N-gram里的每个词分别查找相似词;当没有相似词可替换时,将使用随机词进行替换。由于一定程度的乱序文本不影响语义理解,PBERT从乱序文本中学习语义知识。它对原始输入文本进行一定的词序调换,从而形成乱序文本(因此不会引入额外的[MASK]标记),其学习目标是预测原Token所在的位置。
知识增强的中文预训练模型
BERT在预训练过程中使用的数据仅是对单个字符进行屏蔽,例如下图所示,训练BERT时通过“哈”与“滨”的局部共现判断出“尔”字,但是模型其实并没有学习到与“哈尔滨”相关的知识,即只是学习到“哈尔滨”这个词,但是并不知道“哈尔滨”所代表的含义。ERNIE-Baidu在预训练时使用的数据是对整个词进行屏蔽,从而学习词与实体的表达,例如屏蔽“哈尔滨”与“冰雪”这样的词,使模型能够建模出“哈尔滨”与“黑龙江”的关系,学到“哈尔滨”是“黑龙江”的省会以及“哈尔滨”是个冰雪城市这样的含义。

与ERNIE-Baidu类似,Lattice-BERT利用Word-Lattice结构整合词级别信息。具体来说,Lattice-BERT设计了一个Lattice位置注意机制,来表达词级别的信息,同时提出了Masked Segment Prediction的预测任务,以推动模型学习来自丰富但冗余的内在Lattice信息。

除了语言学知识,更多的工作利用知识图谱中的事实性知识丰富中文预训练模型的表征。其中,K-BERT提出了面向知识图谱的知识增强语言模型,将三元组作为领域知识注入到句子中。然而,过多的知识融入会导致知识噪音,使句子偏离其正确的含义。为了克服知识噪音, K-BERT引入了Soft-position和Visibel Matrix来限制知识的影响。由于K-BERT能够从预训练的BERT中加载模型参数,因此通过配备KG,可以很容易地将领域知识注入到模型中,而不需要对模型进行预训练。EasyNLP框架也集成了K-BERT的模型和功能(看这里)。

ERNIE-THU是一种融入知识Embedding的预训练模型。它首先使用TAGME提取文本中的实体,并将这些实体链指到KG中的对应实体对象,然后获得这些实体对象对应的Embedding。实体对象的Embedding由知识表示方法(例如TransE)训练得到。此外,ERNIE-THU在BERT模型的基础上进行改进,除了MLM、NSP任务外,重新添加了一个和KG相关的预训练目标:Mask掉Token和Entity (实体) 的对齐关系,并要求模型从图谱的实体中选择合适的Entity完成对齐。

自研CKBERT模型技术详解
由于当前的知识增强预训练模型大都使用外部知识(知识图谱,字典和文本等)或者句子内部的语言学知识进行增强,同时知识注入的过程都伴随着很大规模的知识参数,下游任务fine-tune的时候仍然需要外部数据的支撑才能达到比较好的效果,从而无法在云环境中很好的提供给用户进行使用。CKBERT(Chinese Knowledge-enhanced BERT)是EasyNLP团队自研的中文预训练模型,结合了两种知识类型(外部知识图谱,内部语言学知识)对模型进行知识注入,同时使得知识注入的方式方便模型可扩展。针对实际的业务需求,我们提供了三种不同规模参数量的模型,详细配置如下所示:
| 模型配置 | alibaba-pai/pai-ckbert-base-zh | alibaba-pai/pai-ckbert-large-zh | alibaba-pai/pai-ckbert-huge-zh |
| 参数量(Parameters) | 151M | 428M | 1.3B |
| 层数(Number of Layers) | 12 | 24 | 24 |
| 注意力头数(Attention Heads) | 12 | 16 | 8 |
| 隐向量维度(Hidden Size) | 768 | 1024 | 2048 |
| 文本长度(Text Length) | 128 | 128 | 128 |
| FFN 层维度 | 3072 | 4096 | 8192 |
CKBERT的模型架构如下图所示:
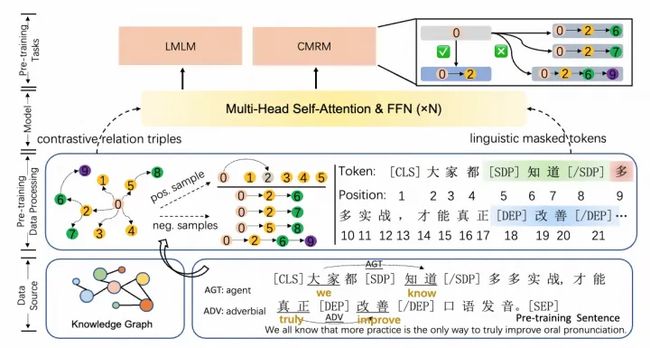
为了方便模型进行扩展参数,模型只在数据输入层面和预训练任务层面进行了改动,没有对模型架构进行改动。因此,CKBERT的模型结构与社区版的BERT模型对齐。在数据输入层,一共要处理两部分的知识,外部图谱三元组和句子级内部的语言学知识。针对语言学知识,我们使用了哈工大LTP平台进行句子数据的处理,进行语义角色标注和依存句法分析等,然后根据规则,将识别结果中重要的成分进行标注。针对外部三元组知识是根据句子中出现的实体构造实体的正负三元组样本,正样本是根据图谱中1-hop 实体进行的采样,负样本是根据图谱中multi-hop进行的采样,但负样本的采样过程只能在规定的多跳范围内,而不能在图谱中距离太远。
CKBERT采用两种预训练任务进行模型的预训练,语言学感知的掩码语言模型和多跳知识对比学习:
- 语言学感知的掩码语言模型(Linguistic-aware MLM):在语义依存关系中的主体角色(施事者AGT和当事者EXP )部分用[MASK]进行遮掩,同时在词的前后都加上[SDP][/SDP],附加上词汇的边界信息。在依存句法关系中,将主谓冰关系,定中关系,并列关系等按照上述mask机制进行处理为[DEP][/DEP]。整体进行预训练的token数量是整句话的15%,其中40%进行随机MASK,30%和30%分配到语义依存关系和依存句法关系词汇上来。损失函数如下:

- 多跳知识对比学习:将上述构造的正负样本数据针对该注入的实体进行处理,每一个句中实体构造1个正样本,4个负样本,通过标准的infoNCE损失任务进行外部知识的学习。损失函数如下:
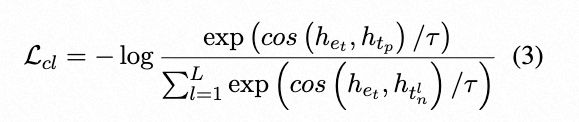
其中,
![]()
是预训练模型产生的上下文实体表示,
![]()
表示正样本的三元组表示结果,
![]()
表示负样本的三元组表示结果。
CKBERT模型的实现
在EasyNLP框架中,我们的模型实现分为三个部分:数据预处理,模型结构微调和损失函数的设计。首先,在数据预处理环节,主要由以下两个步骤组成:1.NER实体及语义关系的提取;2.知识图谱的信息注入。关于NER实体及语义信息的提取,主要采用LTP(Language Technology Platform)对原始句子进行分词和句法分析,该部分的核心代码如下所示:
def ltp_process(ltp: LTP,
data: List[Dict[str, Union[str, List[Union[int, str]]]]]):
"""use ltp to process the data
Args:
Dict ([str, str]): data
example:
{'text':['我叫汤姆去拿伞。'],...}
Returns:
Dict[str, str]: result
"""
new_data = list(map(lambda x:x['text'][0].replace(" ", ""), data))
seg, hiddens = ltp.seg(new_data)
result = {}
result['seg'] = seg
result['ner'] = ltp.ner(hiddens)
result['dep'] = ltp.dep(hiddens)
result['sdp'] = ltp.sdp(hiddens)
for index in range(len(data)):
data[index]['text'][0] = data[index]['text'][0].replace(" ", "")
data[index]['seg'] = result['seg'][index]
data[index]['ner'] = result['ner'][index]
data[index]['dep'] = result['dep'][index]
data[index]['sdp'] = result['sdp'][index]该部分完成之后需要基于原始句子中的语义依存关系对相应的词进行整体的mask,该部分的mask策略参考BERT的mask策略的设计,给不同类型的关系分配特定的概率,并基于该概率对不同类型关系进行mask,该部分的核心代码如下:
def dep_sdp_mask(left_numbers: List[int],
data_new: List[List[Union[int, str]]],
markers_: List[List[int]],
selected_numbers_: set,
number_: int,
marker_attrs: Dict[str, List[int]]) -> int:
""" mask the `mask_labels` for sdp and dep and record the maskers for each mask item
Args:
left_numbers (List[int]): the options that have not been used
data_new (List[List[Union[int, str]]]): preprocessed data for original dep and sdp
markers_ (List[List[int]]): a list that is uesd to save the maskers for each mask item
selected_numbers_ (set): a set that is used to save the selected options
number_ (int): the number of mask labels
marker_attrs Dict[str, List[int]]: marker attributes
Returns:
int: 0 mean no mask, the others mean the number of masked ids
"""
np.random.shuffle(left_numbers)
for item_ in left_numbers:
target_item = data_new[item_]
seg_ids = np.array(target_item[:2]) - 1
delete_ids = np.where(seg_ids < 1)[0]
seg_ids = np.delete(seg_ids, delete_ids)
temp_ids = seg2id(seg_ids)
ids = []
for item in temp_ids:
ids += item.copy()
if check_ids(ids):
length_ = len(ids)
if number_ > length_:
for id_ in ids:
mask_labels[id_] = 1
if target_item[2] in marker_attrs:
detail_info.append([
target_item,
[seg_data[target_item[0] - 1],seg_data[target_item[1] - 1]],
])
if len(temp_ids) == 1:
markers_.append([temp_ids[0][0], temp_ids[0][-1]])
elif len(temp_ids) == 2:
for i in marker_attrs[target_item[2]]:
markers_.append([temp_ids[i][0], temp_ids[i][-1]])
selected_numbers_.add(item_)
return length_
else:
return 0
return 0在完成对原始句子的预处理之后,在模型的dataloader里需要对数据进行知识注入,由于模型中引入了对比学习,因此该部分需要在数据转换阶段同时生成positive和negative的样本数据。实现这一过程的核心代码如下:
def get_positive_and_negative_examples(
self,
ner_data: str,
negative_level: int = 3) -> Union[bool, Dict[str, List[str]]]:
"""get the positive examples and negative examples for the ner data
Args:
ner_data (str): the ner entity
negative_level (int, optional): the deepth of the relationship. Defaults to 3.
Returns:
Union[bool, Dict[str, List[str]]]: if the `ner_data` not in `konwledge`, return False, otherwise, return the positive and negative examples
"""
knowledge: Dict[str, Dict[str, str]] = self.Knowledge_G
common_used = set()
def get_data(key: str,
data: Dict[str, str],
results: List[str],
deep: int,
insert_flag: bool = False):
"""get the negative examples recursively
Args:
key (str): the ner
data (Dict[str, str]): the related data about `key`
results (List[str]): a list used to save the negative examples
deep (int): the recursive number
insert_flag (bool, optional): whether insert data to `results`. Defaults to False.
"""
nonlocal knowledge
common_used.add(key)
if deep == 0:
return
else:
for key_item in data:
if data[key_item] not in common_used and insert_flag == True:
results.append(data[key_item])
if data[key_item] in knowledge and data[key_item] not in common_used:
get_data(data[key_item], knowledge[data[key_item]], results, deep - 1, True)
all_examples = {
'ner': ner_data,
'positive_examples': [],
'negative_examples': []
}
if ner_data in knowledge:
tp_data = knowledge[ner_data]
negative_examples = []
if '描述' in tp_data:
positive_example = tp_data['描述']
else:
keys = list(tp_data.keys())
choice = np.random.choice([_ for _ in range(len(keys))], 1)[0]
positive_example = tp_data[keys[choice]]
# # the description usually contains the ner entity, if not, concate the `ner_data` and the positive example
if ner_data in positive_example:
all_examples['positive_examples'].append(positive_example)
else:
all_examples['positive_examples'].append(ner_data + positive_example)
get_data(ner_data, tp_data, negative_examples, negative_level)
# concate the ner entity and each negative example
negative_examples = list(map(lambda x: ner_data + x if ner_data not in x else x, negative_examples))
all_examples['negative_examples'] = negative_examples
return all_examples
return False在完成知识注入之后,模型的数据预处理环节就实现了。紧接着,由于知识注入需要额外添加特殊的Token,因此,在模型的Embedding层需要重新调整大小,该部分的实现代码如下:
model.backbone.resize_token_embeddings(len(train_dataset.tokenizer))
model.config.vocab_size = len(train_dataset.tokenizer)在对模型结构进行微调之后,最后就是修改原始的loss函数,由于引入了对比学习,这里需要在原来loss的基础之上新加一个对比学习的loss(CKBert采用SimCLS作为对比学习的loss函数),该部分的核心代码实现如下:
def compute_simcse(self, original_outputs: torch.Tensor,
forward_outputs: torch.Tensor) -> float:
original_hidden_states = original_outputs['hidden_states'].unsqueeze(-2)
loss = nn.CrossEntropyLoss()
forward_outputs = torch.mean(forward_outputs, dim=-2)
cos_result = self.CosSim(original_hidden_states, forward_outputs)
cos_result_size = cos_result.size()
cos_result = cos_result.view(-1, cos_result_size[-1])
labels = torch.zeros(cos_result.size(0), device=original_outputs['hidden_states'].device).long()
loss_ = loss(cos_result, labels)
return loss_CKBERT加速预训练
由于CKBERT的预训练需要耗费大量时间和计算资源,我们有必须对CKBERT的预训练进行加速。由于CKBERT采用PyTorch框架实现,与Tensorflow 1.x Graph Execution方式相比,PyTorch采用Eager Execution的方式运行,具有很好的易用性、容易开发调试等特点。但是,Pytorch缺少模型的Graph IR(Intermediate Representation)表达,因此无法进行更深度的优化。受到LazyTensor 和Pytorch/XLA(https://github.com/pytorch/xla)的启发,PAI团队在PyTorch框架中开发了TorchAccelerator,旨在解决PyTorch上的训练优化问题,在保证用户易用性和可调试行的基础上,提升用户训练速度。
由于LazyTensor在Eager Execution到Graph Execution转化过程中还存在很多缺陷。通过将Custom Operation封装进XLA CustomCall、对Python代码进行AST解析等手段,TorchAccelerator提升了Eager Execution到Graph Execution的完备性和转化性能,通过多Stream优化、Tensor异步传输等手段提升编译优化效果。

从实验结果来看,将TorchAccelerator和AMP(Automatic Mixed Precision,混合精度训练)结合起来使用,训练速度将会有40%以上的提升,说明在AMP和TorchAccelerator进行相互作用下有比较好的加速效果。
CKBERT实验效果评测
为了验证CKBERT模型在各种任务上的精度,我们在多个公开数据集上验证了句子分类和NER任务的效果,如下所示:
CLUE数据集实验效果
| 模型 |
Text Classification |
Question Answering |
Total Score |
|||||||
| AFQMC |
TNEWS |
IFLYTEK |
OCNLI |
WSC |
CSL |
CMRC |
CHID |
C3 |
||
| BERT |
72.73 |
55.22 |
59.54 |
66.53 |
72.49 |
81.77 |
73.40 |
79.19 |
57.91 |
69.72 |
| MacBERT |
69.90 |
57.93 |
60.35 |
67.43 |
74.71 |
82.13 |
73.55 |
79.51 |
58.89 |
70.28 |
| PERT |
73.61 |
54.50 |
57.42 |
66.70 |
76.07 |
82.77 |
73.80 |
80.19 |
58.03 |
70.18 |
| ERNIE-Baidu |
73.08 |
56.22 |
60.11 |
67.48 |
75.79 |
82.14 |
72.86 |
80.03 |
57.63 |
69.83 |
| Lattice-BERT |
72.96 |
56.14 |
58.97 |
67.54 |
76.10 |
81.99 |
73.47 |
80.24 |
57.80 |
70.29 |
| K-BERT |
73.15 |
55.91 |
60.19 |
67.83 |
76.21 |
82.24 |
72.74 |
80.29 |
57.48 |
70.35 |
| ERNIE-THU |
72.88 |
56.59 |
59.33 |
67.95 |
75.82 |
82.35 |
72.96 |
80.22 |
56.30 |
69.98 |
| CKBERT-base |
73.17 |
56.44 |
60.65 |
68.53 |
76.38 |
82.63 |
73.55 |
81.69 |
57.91 |
71.36 |
| CKBERT-large |
74.75 |
55.86 |
60.62 |
70.57 |
78.89 |
82.30 |
73.45 |
82.34 |
58.12 |
72.23 |
| CKBERT-huge |
75.03 |
59.72 |
60.96 |
78.26 |
85.16 |
89.47 |
77.25 |
97.73 |
86.59 |
78.91 |
| CKBERT-huge (ensemble) |
77.05 |
61.16 |
61.19 |
82.80 |
87.14 |
94.23 |
80.40 |
97.91 |
87.26 |
81.02 |
NER数据集实验效果
| 模型 | MSRA | Onto. | Resu. | |
| BERT | 95.20 | 54.65 | 81.61 | 94.86 |
| MacBERT | 95.07 | 54.93 | 81.96 | 95.22 |
| PERT | 94.99 | 53.74 | 81.44 | 95.10 |
| ERNIE-Baidu | 95.39 | 55.14 | 81.17 | 95.13 |
| Lattice-BERT | 95.28 | 54.99 | 82.01 | 95.31 |
| K-BERT | 94.97 | 55.21 | 81.98 | 94.92 |
| ERNIE-THU | 95.25 | 53.85 | 82.03 | 94.89 |
| CKBERT-base | 95.35 | 55.97 | 82.19 | 95.68 |
| CKBERT-large | 95.58 | 57.09 | 82.43 | 96.08 |
| CKBERT-huge | 96.79 | 58.66 | 83.87 | 97.19 |
上述结果说明,首先在CLUE数据集上:(1)知识增强预训练模型的性能相较于BERT均有较大提升,在一定程度说明了知识的注入能帮助模型进行更好的语义推理;(2)跟先前的较好的baseline模型相比,CKBERT的性能进一步得到了提升,这也说明了异构知识的注入有利于模型性能的提升;(3)模型参数量越大,异构知识的的注入所带来的提升越明显,这在我们的huge模型和base模型之间的对比上可以看出。其次,在NER数据集上:(1)知识增强预训练模型的性能相较于BERT也有一定的提升;(2)CKBERT模型相较于其他baseline模型的提升较大,这进一步说明了异构知识的注入对于模型性能的提升是有帮助的。
CKBERT模型使⽤教程
以下我们简要介绍如何在EasyNLP框架使⽤CKBERT模型。
安装EasyNLP
⽤户可以直接参考GitHub(https://github.com/alibaba/EasyNLP)上的说明安装EasyNLP算法框架。
模型预训练
以下介绍CKBERT模型的预训练调用过程,如果用户没有自行预训练的需求可以跳过此部分。
数据准备
CKBERT是一个知识嵌入的预训练模型,需要用户自己准备相应的原始训练数据(xxx.json)和知识图谱(xxx.spo),其中数据分隔均使用\t分隔符。训练数据的格式为{'text':['xxx'], 'title':'xxx'},样例如下:
{'text': ['我想,如果我没有去做大学生村官,恐怕我这个在昆明长大的孩子永远都不能切身感受到云南这次60年一遇的特大旱情的严重性,恐怕我只是每天看着新闻上那些缺水的镜头,嘴上说要节水,但事实行动保持不了三天。 我任职的地方在昆明市禄劝县的一个村委会,说实话这里距离禄劝县城不远,自然环境不算很差。目前,只有一个自然村保证不了饮用水。一个自然村基本能保证有饮用水到5月。这里所说的饮用水,是指从山肚子里出来的水,积在小水坝或是水塘里又通过管道输送到村子里的水,和我们城市里真正意义上消过毒的、能安全饮用的饮用水不同。在整个输送的过程中,可能已经产生了有害物质。我觉得是。 没有饮用水的那个自然村叫大海子村,50户,近200多人。地处山头,交通很不便利,走路大概要1个半小时到两个小时,而且坡度比较大,是一个苗族村寨。地理条件限制,基本没有什么经济作物,算是靠天吃饭的那种。今年遇到60年一遇的干旱,村里的两个水窖都基本干了,之前几天,他们村长来反映,几个老人已经是抬个小板凳坐到窖底用碗舀水了。 面对这么严峻的旱情,村委会的领导和各小组长都在想办法。但是上山的路路面情况差,大车重车上不去;周边水源地少。最可行的办法就是从武定那边绕路上去。但每天运水上去也不是办法,长远来看还是要修建一个小水坝。村委会的领导主动捐款,村民也自行筹资,开始自救。 最近每个周末都回家,添置防晒品,因为基本每天都上山下村去了解情况,必须掌握辖区内13个村小组水资源的情况。我每次回家见到朋友们,第一句就是,要节约用水啊~~ 朋友们,你们现在看到的只是简单理解的"缺水"。你们所不知道的是,没水小春作物面临绝收、4月份插秧没有水泡秧田、5月份种烤烟也没有水。。。那么对农民就意味着今年一年就没有了收入。我们现在能努力做好的,只是保证人的饮用水。 上周就在想能不能通过什么渠道帮村民们做点事。叔叔叫我弄个抗旱的基金,他发动周围的朋友来捐赠,希望能口口相传带动多一点朋友。我正在筹备阶段,看怎样才能做到最大的公开透明,让捐赠的人完全放心。 周一接到一个朋友的电话,说他们公司想为旱灾献点爱心,想买点水送去我们那儿。昨天见了负责人,很谦和的一个姐姐,她说大家都想做点什么,觉得捐钱没什么意义,想亲自送水到最需要的地方。 其实人家只是家私营的小公司,但我真的很感谢他们。姐姐还特别交代我,我们只需要找拖拉机下来帮忙把水运上山去,其他的什么都不用管,他们会安排好的。这个周末,将有 400件矿泉水会送到村民家里。我想,应该可以暂时缓解旱情。再次代村民感谢他们! 下半年,旱情给农民的生产、生活带来的问题还很多。但是我个人的力量很有限,希望能够看到这些帖子的朋友们,如果有能力,有这份心意的话,请给予旱灾地区的农民更多的帮助。 我想大家都知道,昆明80%以上的用水都来自禄劝的云龙水库,云龙的同事们也在"抗旱",他们的工作任务是要保证严格的节约用水,要寻求其他水源用水,从而保证昆明的用水。所以,请每一个昆明人都节水吧,禄劝的很多地方都在缺水,我们那里不算严重的,请珍惜你们现在在用的每一滴水~ 也许,要经历过这样一次触目惊心的大旱才真正知道水的珍贵。希望我们都行动起来,不要再让这样的旱灾侵袭我们的家乡。'], 'title': '旱情记要-----昆明人,请珍惜你们现在在用的每一滴水~'}知识图谱数据格式为三列数据,从左到右分别是实体关系的描述,样例如下:
红色食品 标签 生活
数据预处理
可以使用提供的数据预处理脚本(preprocess/run_local_preprocess.sh)来对原始数据进行一键处理,在经过LTP处理之后,数据样例如下:
{"text": ["我想,如果我没有去做大学生村官,恐怕我这个在昆明长大的孩子永远都不能切身感受到云南这次60年一遇的特大旱情的严重性,恐怕我只是每天看着新闻上那些缺水的镜头,嘴上说要节水,但事实行动保持不了三天。我任职的地方在昆明市禄劝县的一个村委会,说实话这里距离禄劝县城不远,自然环境不算很差。目前,只有一个自然村保证不了饮用水。一个自然村基本能保证有饮用水到5月。这里所说的饮用水,是指从山肚子里出来的水,积在小水坝或是水塘里又通过管道输送到村子里的水,和我们城市里真正意义上消过毒的、能安全饮用的饮用水不同。在整个输送的过程中,可能已经产生了有害物质。我觉得是。没有饮用水的那个自然村叫大海子村,50户,近200多人。地处山头,交通很不便利,走路大概要1个半小时到两个小时,而且坡度比较大,是一个苗族村寨。地理条件限制,基本没有什么经济作物,算是靠天吃饭的那种。今年遇到60年一遇的干旱,村里的两个水窖都基本干了,之前几天,他们村长来反映,几个老人已经是抬个小板凳坐到窖底用碗舀水了。面对这么严峻的旱情,村委会的领导和各小组长都在想办法。但是上山的路路面情况差,大车重车上不去;周边水源地少。最可行的办法就是从武定那边绕路上去。但每天运水上去也不是办法,长远来看还是要修建一个小水坝。村委会的领导主动捐款,村民也自行筹资,开始自救。最近每个周末都回家,添置防晒品,因为基本每天都上山下村去了解情况,必须掌握辖区内13个村小组水资源的情况。我每次回家见到朋友们,第一句就是,要节约用水啊~~朋友们,你们现在看到的只是简单理解的\"缺水\"。你们所不知道的是,没水小春作物面临绝收、4月份插秧没有水泡秧田、5月份种烤烟也没有水。。。那么对农民就意味着今年一年就没有了收入。我们现在能努力做好的,只是保证人的饮用水。上周就在想能不能通过什么渠道帮村民们做点事。叔叔叫我弄个抗旱的基金,他发动周围的朋友来捐赠,希望能口口相传带动多一点朋友。我正在筹备阶段,看怎样才能做到最大的公开透明,让捐赠的人完全放心。周一接到一个朋友的电话,说他们公司想为旱灾献点爱心,想买点水送去我们那儿。昨天见了负责人,很谦和的一个姐姐,她说大家都想做点什么,觉得捐钱没什么意义,想亲自送水到最需要的地方。其实人家只是家私营的小公司,但我真的很感谢他们。姐姐还特别交代我,我们只需要找拖拉机下来帮忙把水运上山去,其他的什么都不用管,他们会安排好的。这个周末,将有400件矿泉水会送到村民家里。我想,应该可以暂时缓解旱情。再次代村民感谢他们!下半年,旱情给农民的生产、生活带来的问题还很多。但是我个人的力量很有限,希望能够看到这些帖子的朋友们,如果有能力,有这份心意的话,请给予旱灾地区的农民更多的帮助。我想大家都知道,昆明80%以上的用水都来自禄劝的云龙水库,云龙的同事们也在\"抗旱\",他们的工作任务是要保证严格的节约用水,要寻求其他水源用水,从而保证昆明的用水。所以,请每一个昆明人都节水吧,禄劝的很多地方都在缺水,我们那里不算严重的,请珍惜你们现在在用的每一滴水~也许,要经历过这样一次触目惊心的大旱才真正知道水的珍贵。希望我们都行动起来,不要再让这样的旱灾侵袭我们的家乡。"], "title": "旱情记要-----昆明人,请珍惜你们现在在用的每一滴水~", "seg": ["我", "想", ",", "如果", "我", "没有", "去", "做", "大学生村官", ",", "恐怕", "我", "这个", "在", "昆明长大", "的", "孩子", "永远", "都", "不能切身感受到", "云南", "这次", "60年", "一遇的", "特大旱情", "的", "严重性", ",", "恐怕", "我", "只是", "每天", "看", "着", "新闻上", "那些", "缺水", "的", "镜头", ",", "嘴上说要节水", ",", "但事实行动", "保持不了", "三天", "。", "我", "任职", "的", "地方", "在", "昆明市禄劝县", "的", "一个", "村委会", ",", "说实话", "这里", "距离禄", "劝县城不远", ",", "自然环境", "不算", "很差", "。", "目前", ",", "只有", "一个", "自然村", "保证不了", "饮用水", "。", "一个", "自然村", "基本", "能", "保证", "有", "饮用水", "到", "5月", "。", "这里所说", "的", "饮用水", ",", "是指", "从", "山肚子里", "出来", "的", "水", ",积在", "小水坝", "或是", "水塘里", "又", "通过", "管道", "输送到", "村子里", "的水", ",", "和", "我们", "城市里", "真正意义上", "消过毒的", "、能安全", "饮用", "的", "饮用水不同", "。", "在", "整个", "输送", "的", "过程", "中", ",", "可能", "已经", "产生", "了", "有害物质", "。", "我", "觉得", "是", "。", "没有", "饮用水", "的", "那", "个", "自然村叫大海子村", ",", "50户", ",近", "200多人", "。地处山头", ",", "交通", "很不便利", ",", "走路", "大概要", "1个半小时到", "两个", "小时", ",", "而且坡度", "比较大", ",", "是", "一个", "苗族村寨", "。地理条件", "限制", ",", "基本", "没有什么经济作物", ",", "算是", "靠天", "吃饭", "的", "那种", "。", "今年", "遇到", "60年一遇", "的", "干旱", ",村里", "的", "两个水窖", "都", "基本", "干", "了", ",之前几天", ",", "他们", "村长来反映", ",", "几个老人", "已经", "是", "抬个小板凳坐到窖底用碗舀水", "了", "。面对", "这么", "严峻的", "旱情", ",", "村委会", "的领导", "和", "各小组长", "都", "在", "想", "办法", "。", "但是上山的", "路路面情况", "差", ",", "大车重车上不去", ";", "周边水源地少", "。", "最", "可行", "的", "办法", "就是", "从武定", "那边", "绕路上去", "。", "但", "每天运水上"], "ner": [["Ns", 14, 14], ["Ns", 20, 20], ["Ns", 51, 51]], "dep": [[1, 2, "SBV"], [2, 0, "HED"], [3, 2, "WP"], [4, 6, "ADV"], [5, 6, "SBV"], [6, 2, "VOB"], [7, 6, "COO"], [8, 7, "COO"], [9, 8, "VOB"], [10, 8, "WP"], [11, 7, "COO"], [12, 172, "SBV"], [13, 172, "ADV"], [14, 172, "ADV"], [15, 14, "POB"], [16, 172, "RAD"], [17, 172, "SBV"], [18, 172, "ADV"], [19, 172, "ADV"], [20, 172, "ADV"], [21, 172, "SBV"], [22, 172, "ADV"], [23, 172, "ADV"], [24, 172, "ADV"], [25, 172, "ADV"], [26, 172, "RAD"], [27, 172, "VOB"], [28, 156, "WP"], [29, 33, "ADV"], [30, 33, "SBV"], [31, 33, "ADV"], [32, 33, "ADV"], [33, 156, "COO"], [34, 33, "RAD"], [35, 39, "ATT"], [36, 39, "ATT"], [37, 39, "ATT"], [38, 37, "RAD"], [39, 33, "VOB"], [40, 33, "WP"], [41, 44, "ADV"], [42, 44, "WP"], [43, 44, "ADV"], [44, 33, "COO"], [45, 44, "CMP"], [46, 44, "WP"], [47, 48, "SBV"], [48, 55, "ATT"], [49, 48, "RAD"], [50, 51, "POB"], [51, 48, "ADV"], [52, 51, "POB"], [53, 48, "RAD"], [54, 55, "ATT"], [55, 44, "SBV"], [56, 44, "WP"], [57, 44, "ADV"], [58, 59, "SBV"], [59, 44, "ADV"], [60, 44, "COO"], [61, 44, "WP"], [62, 63, "SBV"], [63, 71, "CMP"], [64, 71, "CMP"], [65, 71, "WP"], [66, 71, "ADV"], [67, 71, "WP"], [68, 71, "ADV"], [69, 70, "ATT"], [70, 71, "SBV"], [71, 44, "COO"], [72, 71, "COO"], [73, 71, "WP"], [74, 75, "ATT"], [75, 71, "SBV"], [76, 78, "ADV"], [77, 78, "ADV"], [78, 44, "COO"], [79, 78, "VOB"], [80, 78, "VOB"], [81, 80, "CMP"], [82, 81, "POB"], [83, 78, "WP"], [84, 86, "ATT"], [85, 84, "RAD"], [86, 78, "COO"], [87, 78, "WP"], [88, 44, "COO"], [89, 91, "ADV"], [90, 89, "POB"], [91, 93, "ATT"], [92, 91, "RAD"], [93, 101, "VOB"], [94, 101, "WP"], [95, 101, "CMP"], [96, 97, "LAD"], [97, 101, "VOB"], [98, 101, "ADV"], [99, 101, "ADV"], [100, 99, "POB"], [101, 156, "COO"], [102, 101, "SBV"], [103, 101, "RAD"], [104, 101, "WP"], [105, 109, "ADV"], [106, 107, "ATT"], [107, 105, "POB"], [108, 109, "ADV"], [109, 156, "COO"], [110, 111, "WP"], [111, 109, "COO"], [112, 109, "RAD"], [113, 109, "COO"], [114, 129, "WP"], [115, 129, "ADV"], [116, 119, "ATT"], [117, 119, "ATT"], [118, 117, "RAD"], [119, 120, "ATT"], [120, 115, "POB"], [121, 129, "WP"], [122, 124, "ADV"], [123, 124, "ADV"], [124, 129, "COO"], [125, 124, "RAD"], [126, 129, "COO"], [127, 129, "WP"], [128, 129, "SBV"], [129, 109, "COO"], [130, 129, "VOB"], [131, 129, "WP"], [132, 133, "COO"], [133, 109, "COO"], [134, 109, "RAD"], [135, 109, "ADV"], [136, 137, "ATT"], [137, 109, "SBV"], [138, 109, "WP"], [139, 109, "ADV"], [140, 109, "WP"], [141, 109, "ADV"], [142, 109, "WP"], [143, 109, "WP"], [144, 109, "COO"], [145, 109, "ADV"], [146, 156, "WP"], [147, 156, "SBV"], [148, 156, "ADV"], [149, 151, "ATT"], [150, 151, "ATT"], [151, 156, "VOB"], [152, 156, "WP"], [153, 156, "ADV"], [154, 156, "ADV"], [155, 156, "WP"], [156, 167, "COO"], [157, 158, "ATT"], [158, 167, "VOB"], [159, 160, "WP"], [160, 167, "COO"], [161, 160, "WP"], [162, 163, "ADV"], [163, 167, "COO"], [164, 165, "WP"], [165, 163, "COO"], [166, 163, "ADV"], [167, 27, "ATT"], [168, 167, "RAD"], [169, 172, "ADV"], [170, 172, "WP"], [171, 172, "ADV"], [172, 7, "COO"], [173, 175, "ATT"], [174, 175, "RAD"], [175, 172, "VOB"], [176, 175, "WP"], [177, 175, "RAD"], [178, 175, "ATT"], [179, 181, "ADV"], [180, 181, "ADV"], [181, 6, "COO"], [182, 181, "RAD"], [183, 181, "WP"], [184, 181, "WP"], [185, 190, "SBV"], [186, 190, "SBV"], [187, 190, "WP"], [188, 190, "SBV"], [189, 190, "ADV"], [190, 181, "COO"], [191, 190, "VOB"], [192, 191, "RAD"], [193, 191, "WP"], [194, 195, "ADV"], [195, 204, "CMP"], [196, 204, "VOB"], [197, 204, "WP"], [198, 204, "SBV"], [199, 198, "RAD"], [200, 204, "LAD"], [201, 204, "SBV"], [202, 204, "ADV"], [203, 204, "ADV"], [204, 191, "COO"], [205, 204, "VOB"], [206, 204, "WP"], [207, 204, "ADV"], [208, 209, "SBV"], [209, 191, "ADV"], [210, 209, "WP"], [211, 209, "SBV"], [212, 209, "WP"], [213, 209, "SBV"], [214, 209, "WP"], [215, 216, "ADV"], [216, 218, "ATT"], [217, 216, "RAD"], [218, 209, "SBV"], [219, 209, "ADV"], [220, 191, "ADV"], [221, 191, "ADV"], [222, 181, "COO"], [223, 181, "WP"], [224, 181, "ADV"], [225, 181, "ADV"]], "sdp": [[1, 2, "AGT"], [1, 129, "AGT"], [2, 0, "Root"], [3, 2, "mPUNC"], [4, 7, "mRELA"], [5, 7, "AGT"], [5, 8, "AGT"], [6, 7, "mNEG"], [6, 8, "mNEG"], [7, 2, "dCONT"], [8, 7, "eSUCC"], [9, 8, "LINK"], [10, 8, "mPUNC"], [11, 8, "eSUCC"], [12, 172, "EXP"], [13, 172, "SCO"], [14, 15, "mRELA"], [15, 167, "LOC"], [15, 172, "LOC"], [16, 172, "mDEPD"], [17, 172, "EXP"], [18, 172, "mDEPD"], [19, 172, "mDEPD"], [20, 172, "mNEG"], [21, 172, "AGT"], [22, 172, "SCO"], [23, 172, "EXP"], [24, 172, "EXP"], [25, 172, "MANN"], [26, 172, "mDEPD"], [27, 172, "CONT"], [28, 172, "mPUNC"], [29, 33, "mDEPD"], [30, 33, "AGT"], [31, 33, "mDEPD"], [32, 33, "mDEPD"], [33, 172, "eSUCC"], [34, 33, "mDEPD"], [35, 39, "FEAT"], [36, 39, "SCO"], [37, 39, "rEXP"], [38, 37, "mDEPD"], [39, 33, "CONT"], [40, 33, "mPUNC"], [41, 44, "LOC"], [42, 44, "mPUNC"], [43, 44, "mRELA"], [44, 33, "eSUCC"], [45, 44, "TIME"], [46, 44, "mPUNC"], [47, 48, "AGT"], [47, 60, "PAT"], [47, 204, "AGT"], [48, 55, "rDATV"], [49, 48, "mDEPD"], [50, 48, "LOC"], [51, 50, "mRELA"], [52, 50, "FEAT"], [53, 48, "mDEPD"], [54, 55, "MEAS"], [55, 44, "EXP"], [56, 44, "mPUNC"], [57, 44, "eCOO"], [58, 59, "EXP"], [59, 44, "eSUCC"], [60, 44, "eSUCC"], [61, 60, "mPUNC"], [62, 60, "PAT"], [63, 60, "eSUCC"], [64, 63, "mDEPD"], [65, 71, "mPUNC"], [66, 71, "TIME"], [67, 66, "mPUNC"], [68, 71, "mDEPD"], [69, 70, "MEAS"], [70, 71, "AGT"], [71, 60, "eCOO"], [72, 71, "dCONT"], [73, 72, "mPUNC"], [74, 75, "MEAS"], [75, 72, "AGT"], [76, 78, "mDEPD"], [77, 78, "mDEPD"], [78, 44, "eSUCC"], [79, 78, "dCONT"], [80, 79, "LINK"], [81, 79, "eCOO"], [82, 81, "TIME"], [83, 91, "mPUNC"], [84, 91, "LOC"], [85, 91, "mDEPD"], [86, 88, "EXP"], [87, 88, "mPUNC"], [88, 91, "mDEPD"], [89, 90, "mRELA"], [90, 91, "LOC"], [91, 79, "eSUCC"], [92, 91, "mDEPD"], [93, 79, "EXP"], [94, 93, "mPUNC"], [95, 93, "FEAT"], [96, 97, "mRELA"], [97, 93, "eCOO"], [98, 78, "mDEPD"], [99, 100, "mRELA"], [100, 101, "MANN"], [101, 78, "dCONT"], [102, 107, "FEAT"], [102, 109, "SCO"], [103, 109, "mDEPD"], [104, 109, "mPUNC"], [105, 107, "mRELA"], [106, 107, "FEAT"], [107, 109, "SCO"], [108, 109, "mDEPD"], [109, 101, "ePREC"], [110, 109, "mPUNC"], [111, 109, "eSUCC"], [112, 109, "mDEPD"], [113, 109, "eSUCC"], [114, 129, "mPUNC"], [115, 119, "mRELA"], [116, 119, "SCO"], [117, 119, "FEAT"], [118, 117, "mDEPD"], [119, 124, "STAT"], [120, 119, "mDEPD"], [121, 119, "mPUNC"], [122, 124, "mDEPD"], [123, 124, "mDEPD"], [124, 129, "dCONT"], [125, 124, "mDEPD"], [126, 129, "dCONT"], [127, 129, "mPUNC"], [128, 129, "AGT"], [129, 109, "eSUCC"], [130, 129, "dCONT"], [131, 129, "mPUNC"], [132, 109, "ePREC"], [133, 109, "eSUCC"], [134, 109, "mDEPD"], [135, 109, "SCO"], [136, 137, "MEAS"], [137, 109, "FEAT"], [138, 109, "mPUNC"], [139, 109, "FEAT"], [140, 109, "mPUNC"], [141, 109, "FEAT"], [142, 109, "mPUNC"], [143, 8, "mPUNC"], [143, 109, "mPUNC"], [144, 109, "eSUCC"], [145, 160, "mDEPD"], [146, 160, "mPUNC"], [147, 160, "eSUCC"], [148, 147, "mDEPD"], [149, 147, "MEAS"], [150, 151, "MEAS"], [151, 147, "TIME"], [152, 147, "mPUNC"], [153, 156, "mRELA"], [154, 156, "mRELA"], [155, 156, "mPUNC"], [156, 160, "mDEPD"], [157, 158, "MEAS"], [158, 156, "LINK"], [159, 156, "mPUNC"], [160, 109, "eSUCC"], [161, 160, "mPUNC"], [162, 163, "mDEPD"], [163, 160, "dEXP"], [164, 165, "mPUNC"], [165, 160, "eCOO"], [166, 167, "mRELA"], [167, 165, "dEXP"], [168, 167, "mDEPD"], [169, 167, "SCO"], [170, 160, "mPUNC"], [171, 172, "TIME"], [172, 11, "dCONT"], [173, 8, "MEAS"], [174, 175, "mDEPD"], [175, 8, "eSUCC"], [176, 175, "mPUNC"], [177, 181, "mDEPD"], [178, 181, "EXP"], [179, 181, "mDEPD"], [180, 181, "mDEPD"], [181, 2, "dCONT"], [182, 44, "mDEPD"], [182, 209, "mDEPD"], [183, 209, "mPUNC"], [184, 209, "mPUNC"], [185, 44, "AGT"], [185, 209, "EXP"], [186, 185, "eCOO"], [187, 209, "mPUNC"], [188, 191, "MEAS"], [189, 191, "mDEPD"], [190, 191, "eSUCC"], [191, 209, "dEXP"], [192, 204, "mDEPD"], [193, 204, "mPUNC"], [194, 195, "SCO"], [195, 204, "FEAT"], [196, 204, "CONT"], [197, 204, "mPUNC"], [198, 204, "AGT"], [199, 48, "mDEPD"], [199, 198, "mDEPD"], [200, 204, "mRELA"], [201, 204, "AGT"], [202, 204, "mDEPD"], [203, 204, "eCOO"], [204, 209, "ePREC"], [205, 204, "CONT"], [206, 204, "mPUNC"], [207, 204, "mDEPD"], [208, 204, "LOC"], [209, 181, "eSUCC"], [210, 209, "mPUNC"], [211, 209, "EXP"], [212, 209, "mPUNC"], [213, 209, "EXP"], [214, 209, "mPUNC"], [215, 216, "mDEPD"], [216, 218, "FEAT"], [217, 37, "mDEPD"], [217, 216, "mDEPD"], [218, 209, "EXP"], [219, 209, "mDEPD"], [220, 221, "mRELA"], [221, 209, "LOC"], [222, 181, "eSUCC"], [223, 181, "mPUNC"], [224, 181, "mRELA"], [225, 181, "SCO"]]}紧接着,调用相应的mask策略对数据进行处理,处理后的数据样例如下:
[['[CLS]', '我', '想', ',', '如', '果', '我', '没', '有', '去', '做', '大', '学', '生', '村', '官', ',', '恐', '怕', '我', '这', '个', '在', '昆', '明', '长', '大', '的', '孩', '子', '永', '远', '都', '不', '能', '切', '身', '感', '受', '到', '云', '南', '这', '次', '6', '0', '年', '一', '遇', '的', '特', '大', '旱', '情', '的', '严', '重', '性', ',', '恐', '怕', '[sdp]', '我', '[sdp]', '只', '是', '每', '天', '[sdp]', '看', '[sdp]', '着', '新', '闻', '上', '那', '些', '缺', '水', '的', '镜', '头', ',', '嘴', '上', '说', '要', '节', '水', ',', '但', '事', '实', '行', '动', '保', '持', '不', '了', '三', '天', '。', '我', '任', '职', '的', '地', '方', '在', '昆', '明', '市', '禄', '劝', '县', '的', '一', '个', '村', '委', '会', ',', '说', '实', '话', '这', '里', '[SEP]'], [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], ['昆明长大', '云南', '昆明市禄劝县']]预训练脚本
数据处理完毕之后,就可以调用预训练脚本进行模型的预训练,脚本如下:
gpu_number=1
negative_e_number=4
negative_e_length=16
base_dir=$PWD
checkpoint_dir=$base_dir/checkpoints
resources=$base_dir/resources
local_kg=$resources/ownthink_triples_small.txt
local_train_file=$resources/train_small.txt
remote_kg=https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/ckbert/ownthink_triples_small.txt
remote_train_file=https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/ckbert/train_small.txt
if [ ! -d $checkpoint_dir ];then
mkdir $checkpoint_dir
fi
if [ ! -d $resources ];then
mkdir $resources
fi
if [ ! -f $local_kg ];then
wget -P $resources $remote_kg
fi
if [ ! -f $local_train_file ];then
wget -P $resources $remote_train_file
fi
python -m torch.distributed.launch --nproc_per_node=$gpu_number \
--master_port=52349 \
$base_dir/main.py \
--mode=train \
--worker_gpu=$gpu_number \
--tables=$local_train_file, \
--learning_rate=5e-5 \
--epoch_num=5 \
--logging_steps=10 \
--save_checkpoint_steps=2150 \
--sequence_length=256 \
--train_batch_size=20 \
--checkpoint_dir=$checkpoint_dir \
--app_name=language_modeling \
--use_amp \
--save_all_checkpoints \
--user_defined_parameters="pretrain_model_name_or_path=hfl/macbert-base-zh external_mask_flag=True contrast_learning_flag=True negative_e_number=${negative_e_number} negative_e_length=${negative_e_length} kg_path=${local_kg}"模型Finetune
CKBERT模型与BERT是同样的架构,只需要使用通用的EasyNLP框架命令就可以进行调用。以下命令分别为Train和Predict状态的例子,使用的模型为ckbert-base。
当前在EasyNLP框架中也可以调用large和huge模型进行测试,只需要替换命令中的参数即可
- pretrain_model_name_or_path=alibaba-pai/pai-ckbert-large-zh
- pretrain_model_name_or_path=alibaba-pai/pai-ckbert-huge-zh
$ easynlp \
--mode=train \
--worker_gpu=1 \
--tables=train.tsv,dev.tsv \
--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1 \
--first_sequence=sent1 \
--label_name=label \
--label_enumerate_values=0,1 \
--checkpoint_dir=./classification_model \
--epoch_num=1 \
--sequence_length=128 \
--app_name=text_classify \
--user_defined_parameters='pretrain_model_name_or_path=alibaba-pai/pai-ckbert-base-zh'$ easynlp \
--mode=predict \
--tables=dev.tsv \
--outputs=dev.pred.tsv \
--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1 \
--output_schema=predictions,probabilities,logits,output \
--append_cols=label \
--first_sequence=sent1 \
--checkpoint_path=./classification_model \
--app_name=text_classify在HuggingFace上使用CKBERT模型
为了方便开源用户使用CKBERT,我们也将三个CKBERT模型在HuggingFace Models上架,其Model Card如下所示:

用户也可以直接使用HuggingFace提供的pipeline进行模型推理,样例如下:
from transformers import AutoTokenizer, AutoModelForMaskedLM, FillMaskPipeline
tokenizer = AutoTokenizer.from_pretrained("alibaba-pai/pai-ckbert-base-zh", use_auth_token=True)
model = AutoModelForMaskedLM.from_pretrained("alibaba-pai/pai-ckbert-base-zh", use_auth_token=True)
unmasker = FillMaskPipeline(model, tokenizer)
unmasker("巴黎是[MASK]国的首都。",top_k=5)
[
{'score': 0.8580496311187744,
'token': 3791,
'token_str': '法',
'sequence': '巴 黎 是 法 国 的 首 都 。'},
{'score': 0.08550138026475906,
'token': 2548,
'token_str': '德',
'sequence': '巴 黎 是 德 国 的 首 都 。'},
{'score': 0.023137662559747696,
'token': 5401,
'token_str': '美',
'sequence': '巴 黎 是 美 国 的 首 都 。'},
{'score': 0.012281022034585476,
'token': 5739, 'token_str': '英',
'sequence': '巴 黎 是 英 国 的 首 都 。'},
{'score': 0.005729076452553272,
'token': 704, 'token_str': '中',
'sequence': '巴 黎 是 中 国 的 首 都 。'}
]或者也可以使用Pytorch加载模型,样例如下:
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("alibaba-pai/pai-ckbert-base-zh", use_auth_token=True)
model = AutoModelForMaskedLM.from_pretrained("alibaba-pai/pai-ckbert-base-zh", use_auth_token=True)
text = "巴黎是[MASK]国的首都。"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)在阿里云机器学习平台PAI上使用CKBERT模型
PAI-DSW(Data Science Workshop)是阿里云机器学习平台PAI开发的云上IDE,面向不同水平的开发者,提供了交互式的编程环境(文档)。在DSW Gallery中,提供了各种Notebook示例,方便用户轻松上手DSW,搭建各种机器学习应用。我们也在DSW Gallery中上架了使用CKBERT进行中文命名实体识别的Sample Notebook(见下图),欢迎大家体验!

未来展望
在未来,我们计划在EasyNLP框架中集成更多中⽂知识模型,覆盖各个常⻅中⽂领域,敬请期待。我们也将在EasyNLP框架中集成更多SOTA模型(特别是中⽂模型),来⽀持各种NLP和多模态任务。此外, 阿⾥云机器学习PAI团队也在持续推进中⽂多模态模型的⾃研⼯作,欢迎⽤户持续关注我们,也欢迎加⼊ 我们的开源社区,共建中⽂NLP和多模态算法库!
Github地址:https://github.com/alibaba/EasyNLP
Reference
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. EMNLP 2022
- Taolin Zhang, Junwei Dong, Jianing Wang, Chengyu Wang, Ang Wang, Yinghui Liu, Jun Huang, Yong Li, Xiaofeng He. Revisiting and Advancing Chinese Natural Language Understanding with Accelerated Heterogeneous Knowledge Pre-training. EMNLP 2022
- Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, Guoping Hu. Revisiting Pre-Trained Models for Chinese Natural Language Processing. EMNLP (Findings) 2020
- Yiming Cui, Ziqing Yang, Ting Liu. PERT: Pre-training BERT with Permuted Language Model. arXiv
- Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, Hua Wu. ERNIE: Enhanced Representation through Knowledge Integration. arXiv
- Yuxuan Lai, Yijia Liu, Yansong Feng, Songfang Huang, and Dongyan Zhao. Lattice-BERT: Leveraging Multi-Granularity Representations in Chinese Pre-trained Language Models. NAACL 2021
- Weijie Liu, Peng Zhou, Zhe Zhao, Zhiruo Wang, Qi Ju, Haotang Deng, Ping Wang. K-BERT: Enabling Language Representation with Knowledge Graph. AAAI 2020
- Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, Qun Liu. ERNIE: Enhanced Language Representation with Informative Entities. ACL 2019
原文链接
本文为阿里云原创内容,未经允许不得转载。