Paper reading——Deep residual pooling network for texture recognition
Title
Deep residual pooling network for texture recognition
Year/ Authors/ Journal
2021
/Mao, Shangbo and Rajan, Deepu and Chia, Liang Tien
/ Pattern Recognition
citation
@article{mao2021deep,
title={Deep residual pooling network for texture recognition},
author={Mao, Shangbo and Rajan, Deepu and Chia, Liang Tien},
journal={Pattern Recognition},
volume={112},
pages={107817},
year={2021},
publisher={Elsevier}
}
Summary
-
The balance between the orderless features and the spatial information for effective texture recognition.
-
Experiments show that retaining the spatial information before aggregation is helpful in feature learning for texture recognition.
Interesting Point(s)
-
It would be interesting to explore if the best feature maps could be automatically identified as suitable candidates for combining.
-
In our method, the multi-size training can influence only the features learned in the convolutional transfer module, which will not lead to a major influence in the final performance. We plan to address this in the future.
-
The properties of the Deep-TEN for integrating Encoding Layer with and end-to-end CNN architecture.
-
spatial information + orderless features.
-
end to end training.
-
same dimensions.
-
Research Objective(s)

Fig. 1. Overall framework of deep residual pooling network. When the backbone network is Resnet-50 and the input image size is 224 ×224 ×3 , the dimension of the feature map extracted from $ f_{cnn} $ is 7 ×7 ×2048 , as the orange cube in the figure shows. (For interpretation of the references to color in this figure legend, the reader is referred to the web version of this article.)
Current deep learning-based texture recognition methods extract spatial orderless features from pretrained deep learning models that are trained on large-scale image datasets. These methods either pro- duce high dimensional features or have multiple steps like dictionary learning, feature encoding and dimension reduction. In this paper, we propose a novel end-to-end learning framework that not only overcomes these limitations, but also demonstrates faster learning.
Contributions
The contribution of our work is three fold:
- We propose a learnable residual pooling layer comprising of a residual encoding module and an aggregation module. We take advantage of the feature learning ability of the convolutional layer and integrate the idea of residual encoding to pro- pose a learnable pooling layer. Besides, the proposed layer produces the residual codes retaining spatial information and aggregates them to a feature with a lower dimension compared with the state-of-the-art methods. Experiments show that retaining the spatial information before aggregation is helpful in feature learning for texture recognition.
- We propose a novel end-to-end learning framework that integrates the residual pooling layer into a pretrained CNN model for efficient feature transfer for texture recognition. We show the overview of the proposed residual pooling framework in Fig. 1 .
- We compare our feature dimensions as well as the performance of the proposed pooling layer with other residual encoding schemes to illustrate state-of-the-art performance on bench- mark texture datasets and also on a visual inspection dataset from industry. We also test our method on a scene recognition dataset.
Background / Problem Statement
- Following its success, several pretrained CNN models complemented by specific modules to improve accuracy have been proposed [5,13,25] that achieve better performance on benchmark datasets such as Flickr Material Dataset (FMD) [23] and Describable Texture Dataset (DTD) [3] . However, since the methods proposed in [4,25] contain multiple steps such as feature extraction, orderless encoding and dimension reduction, the advantages offered by end-to-end learning are not fully utilized. Moreover, the features extracted by all of these methods [4,5,25] have high dimensions resulting in operation on large matrices.
- There is a need to balance orderless feature and ordered spatial information for effective texture recognition [33] . From feature visualization experiments, we see that pretrained CNN features are able to differentiate textures only to a certain ex- tent. Hence, we propose to use the pretrained CNN features as the compact dictionary. Since the pretrained CNN features mainly focus on the extraction of spatial sensitive information, we implement the hard assignment based on the spatial locations during the calculation of the residuals. Then, in order to get an orderless feature, we propose an aggregation module to remove the spatial sensitive information.
- The challenge is to make the loss function differentiable with respect to the inputs and layer parameters.
All in one word: for better transferring the deep-learning method into texture recognition. Since model in this field always with pretrained in large dataset (such as ImageNet).
Method(s)
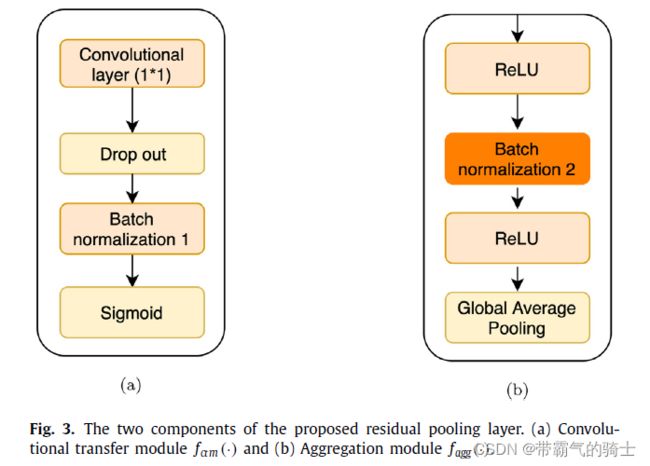
Unlike Deep TEN [34] , which removed the spatial sensitive information at the beginning itself, we retain the spatial sensitive information until the aggregation module to achieve the balance of orderless features and ordered spatial information.
Our proposed residual encoding module is motivated by Deep TEN [34] , but there are two main differences. The first one is that in the convolutional transfer module, we retain the spatial information in the pretrained convolutional features as the dictionary and apply hard assignment based on the spatial location. Deep TEN removes the spatial information in their residual encoding layer. The second one is that the aggregation module yields the final orderless feature whose dimension equals the number of channels in the current pretrained convolutional layer without a separate dimension reduction step. This avoids the potential risk of over- fitting and extra computation.
Due to the using of global average pool, this method results in a lower D D D (other methods have K D / 8 KD/8 KD/8 (where K = 64), 2 K d 2Kd 2Kd (where K=64 and d = D / 8 d=D/8 d=D/8) and K d Kd Kd (where K=32 and $d=D/16) )dimensional feature vector, which is also an effective one without dimension reduction.
Residual Pooling Layer
-
Residual Encoding Module. The spatial sensitive hard assignment results in the residual map r ij at location ( i, j) computed as
r i j = x i j − σ ( C i j ) , r i j , x i j , C i j ∈ R 2048 r_{ij}=x_{ij}-\sigma(C_{ij}), \qquad r_{ij},\space x_{ij},\space C_{ij}\in\R^{2048} rij=xij−σ(Cij),rij, xij, Cij∈R2048
where σ \sigma σ is the sigmoid function that accentuates the difference between the learned feature and the pretrained feature. -
Aggregation Module. It is used to aggregate the residuals to obtain an orderless feature. By setting the negative residuals to zero, the transferred features X X X that are more different from the corresponding pretrained feature are retained and others are re- moved resulting in highly discriminative features for classification.
-
Residual pooling layers. The calculation process is as following.
y i = f a g g ( R i ) y_i = f_{agg}(\R_i) yi=fagg(Ri)
KaTeX parse error: Undefined control sequence: \C at position 15: \R_i = f_ctm(\̲C̲_I) - \sigma(C_…
where f c t m f_{ctm} fctm and f a g g f_{agg} fagg represent convolutional transfer module and aggregation module respectively.

Additional methods
The last two convolutional blocks will bring benefits to the evaluate the effectiveness of texture recognition since they extract distinguishable features whose combination is more discriminative, which is approved in Ref [2]. For adopt this effectiveness, two ways are optional.
-
Concatenation.
-
Auxiliary classifier, which is used in GoogleNet.
y ^ = y i + α y j a u x \hat y = y_i + \alpha y_{j}^{aux} y^=yi+αyjaux
Evaluation
-
Comparison of different ways to combine different convolutional layers on FMD (10 splits), DTD (10 split). The backbone used is Resnet-50.

-
Comparison of single-size(224 ×224) and multi-size training(160 ×160 and 224 ×224) on FMD (10 splits), DTD (1 split), and MIT-Indoor (1 split).

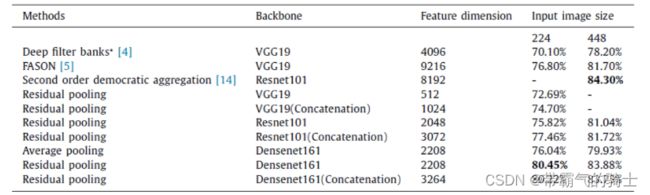
- Comparison with state-of-the-art methods on FMD, DTD, and 4D-Light datasets. In the experiments of SRNET, all three datasets use 256 × 256 input image size which is consistent with [1] . In the remaining experiments, FMD and DTD dataset uses 224 × 224 image size. 4D Light uses 256 × 256 input image size. * indicates multiple size training.

-
Average and minimum classification errors obtained from A-test [8] .

-
Comparison with state-of-the-art methods on metal surface anomaly dataset. * indicates multiple size training.

- Comparison with state-of-the-art methods on MIT-Indoor dataset.
Conclusion
- The residual encoding module retains spatial information of the features while computing the residuals between pre-trained and transferred features.
- The aggregation module generates low dimension features and selects those features that are discriminative for classification.
Codes
class myModel(nn.Module):
def __init__(self):
super(myModel,self).__init__()
model_dense=models.densenet161(pretrained=True)
self.features=nn.Sequential(*list(model_dense.features.children())[:-1])
self.conv1= nn.Sequential(nn.Conv2d(in_channels=2208,
out_channels=1104,
kernel_size=1,
stride=1,
padding=0),
nn.Dropout2d(p=0.5),
nn.BatchNorm2d(1104))
self.relu1 = nn.ReLU(inplace=True)
self.relu2 = nn.ReLU(inplace = True)
self.norm1 = nn.BatchNorm2d(4416);
self.relu3 = nn.ReLU(inplace=True);
self.classifier=nn.Linear((4416),num_classes)
def forward(self,x):
out = self.features(x)
identity=out
## Residual pooling layer ##
## 1. Residual encoding module ##
identity = self.sigmoid(identity)
out = self.conv1(out)
out = self.relu1(out)
out = out - identity
## 2. Aggregation module ##
out = self.relu2(out)
out = self.norm1(out)
out = self.relu3(out)
out = nn.functional.adaptive_avg_pool2d(out,(1,1)).view(out.size(0), -1)
x=self.classifier(out)
return x
Notes
datasets: FMD, DTD, 4D Light and one industry dataset used for metal surface anomaly detection, the MIT-Indoor scene recognition dataset
The description between the methods.
Our proposed residual encoding module is motivated by Deep TEN [34] , but there are two main differences. The first one is that in the convolutional transfer module, we retain the spatial information in the pretrained convolutional features as the dictionary and apply hard assignment based on the spatial location. Deep TEN removes the spatial information in their residual encoding layer. The second one is that the aggregation module yields the final orderless feature whose dimension equals the number of channels in the current pretrained convolutional layer without a separate dimension reduction step. This avoids the potential risk of over- fitting and extra computation.
Question(s)
1. Why all addressing the orderless feature is beneficial for texture recognition?
References
[1] H. Zhang , J. Xue , K. Dana , Deep ten: texture encoding network, in: Proceed- ings of the IEEE Conference on Computer Vision and Pattern recognition, 2017, pp. 708–717 .
[2] X. Dai , J. Yue-Hei Ng , L.S. Davis , FASON: first and second order information fusion network for texture recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 7352–7360 .