MobileNet V1论文记录及pytorch代码
2017年CVPR论文
在此之前深度学习领域一直在不计成本的进行精度提升,到了2017年识别精度已经很高了,这方面的提升已经很难了,所以大家开始寻找其他方向,轻量化网络就是其中一个比较热门的方向
轻量化网络的优势以及应用领域可以参考另一篇博客:
MobileNet V1算法介绍记录_charles_zhang_的博客-CSDN博客

论文正文
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
针对移动端计算机视觉应用的高效卷积
论文作者

Abstract
这是一种高效(参数少、计算量少)的移动嵌入式计算机视觉,MobileNets是基于深度可分离卷积堆叠出的轻量化神经网络,另外作者还设计了两个控制网络大小全局超参数,通过这两个超参数来进行速度(时间延迟)和准确率的权衡,使用者可以根据设备的限制调整网络。进行大量试验 ,在ImageNet classification、object detection 、finegrain classification(细粒度图像分类)、face attributes 和large scale geo-localization领域都有不错的表现。
1、Introoduction
卷积神经网络现在无处不在,从AlexNet在ILSVRC 2012中引爆了卷积神经网络,之后普遍的趋势就是将网络变得更深更复杂,去实现更高的准确率,例如VGG、GoogleNet、Inception-v4、ResNet。但是让网络变得更深并不能带来高效网络,尤其是在真实世界设备上应用会被时效性、计算能力限制。

接下来在文章各个章节会介绍前期准备工作、MobileNet网络结构、width multiplier 、resolution multiplier以及在各个领域的实验成果
2、Prior Work(过去针对轻量化的研究)
对轻量化网络的研究已经有了一些,例如分解卷积、加速卷积运算(剪枝、权重量化)、SqueezeNet、量化、Xnornet等案例。另外也可以通过压缩已有模型或者直接训练小模型实现轻量化。该文属于直接训练小模型方向。
MobileNet主要是基于深度可分离卷积,文章参考了其他论文中的创新点,诸如Inception models、Flattened networks(展开)、Factorized Networks(分解)、Xception networks(结构和MobileNet差不多)。另外Squeezenet网络使用了bottleneck approach设计并训练了一小型网络。
另外使用已训练好的神经压缩瘦身也是一种方法,可以使用乘法量化、hashing、pruning、vector quantization(矢量量化)、Huffman coding(霍夫曼编码)等方式加速深度学习。
通过知识蒸馏也可以训练小网络,通过一个大的老师网络去训练小的学生网络。还有一些新方法也可以加速,例如以极少的比特存储权重值,直接加速卷积运算(im2col+GEMM、Winograd卷积、低秩分解)
3、MobileNet Architecure
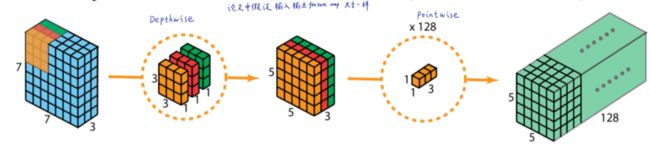
3.1、Depthwise Separable Convolution(深度可分离卷积)
介绍
深度可分离卷积可以被视为一个可被分解的卷积,它将一个常规卷积分解为depthwise conv和pointwise conv。
先depthwise后pointwise

depthwise conv是每个通道对应一个卷积核,pointwise conv是1x1卷积进行跨通道信息融合,可以大大减少参数量
常规卷积是同时进行通道和融合,计算量大
参数量分析
常规卷积核
feature map
输入大小如下,其中M为输入的深度,DF为输入的宽和高

使用N个卷积核,输出大小为,
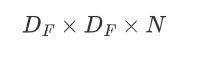
卷积核
DK是卷积核的尺寸,M为卷积核的通道,N为卷积核的个数
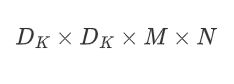
输出特征映射计算
可以表示为下面公式,该公式是文中给出的,见到那的说就是K代表卷积核的权重,与F感受野的像素值(feature map 的值),对应位置相乘在求和
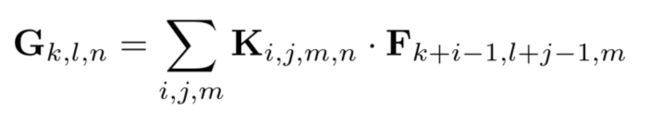
卷积乘法计算量
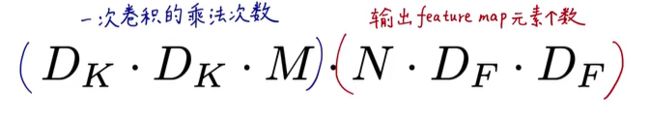
参数量

可以看到参数量和计算量的大小与M和N等参数有关,深度可分离卷积将长宽方向和通道方向的信息解耦,权重也降低
深度可分离卷积
其中包含depthwise conv和pointwise conv两个卷积,depthwise conv 负责处理长宽方向的信息,pointwise conv负责通道combine,卷积之后再使用batchnorm和ReLU
输出特征映射计算
相比常规卷积减少了一些参数,计算量大大减少

计算量
Depthwise卷积计算量

总的计算量

参数量
Depthwise参数量
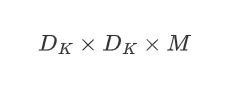
总参数量

深度可分离卷积相对于传统卷积的计算量
如果选用3x3卷积,这个值大概是1/9

参数量,同计算量的比例相同

3.2、Network Structure and Training(网络结构)
结构介绍
MobileNet是基于深度可分离卷积搭建的网络结构,除了第一层是常规卷积,后面的全是深度可分离卷积
MobileNet网络结构如下
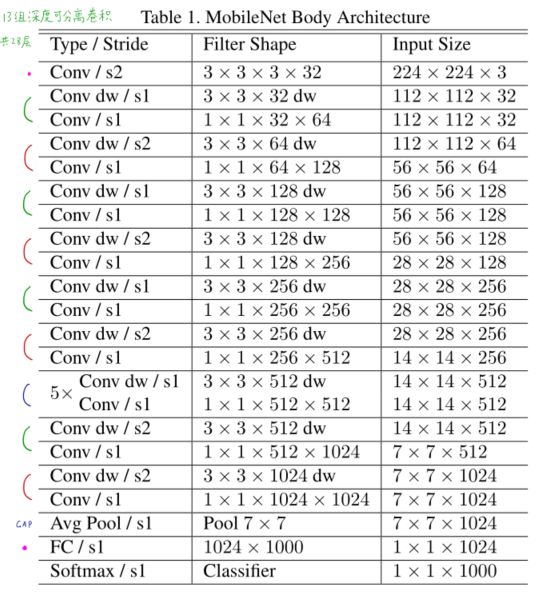
深度可分离卷机结合BN和ReLU,与常规模型的对比如下

下采样层采用卷积核步长为2的卷积层进行,没有池化层(ResNet之后开始取消池化层)
最后使用GAP全局平均池化,降低维度和减少参数量(替代了全连接层)
仅仅是设计一个网络结构是不够的的,我们的目标是让使用者可以自行决定网络的大小,由此引入两个超参数
通常而言稀疏矩阵的计算速度要比稠密矩阵的慢,除非特别稀疏。1x1卷积核是一个比较密集的矩阵,所以在卷积计算时速度较快
1x1卷积可以直接通过GEMM(general matrix multiply)进行加速,其他类型的卷积在使用GEMM之前需要先经过Im2col。
所以MobileNet中95%的1x1卷积可以大大加速网络运算,部署在算力限制设备上更容易
训练配置参数
使用Tensorflow框架训练,使用RMSprop优化器,异步梯度下降(并行数据),需要“钞能力”才可以搞定整个结构。
However, contrary to training large models we use less regularization and data augmentation techniques because small models have less trouble with overfitting.
因为训练的是小模型,所以较少使用正则化和数据增强防止过拟合,另外最好不要使用权重衰减(L2正则化),因为参数量没有大型网络多,尽可能的放开参数限制。
3.3. Width Multiplier: Thinner Models(宽度超参数α)
网络的宽度,一般是指卷积核的个数,网络的深度一般是指卷积层的层数
在一些特定的使用场景,需要让网络更小更快,为了方便调整网络,引入了α,如果把α设置成0.8,那么网络结构中的每一个卷积层中的卷积核个数都变为0.8倍,
α是以比例表示的1、0.75、0.5、0.25
问题:具体减少怎么减少,单纯减少卷积核个数会不会导致前后数据大小对不上?
计算量相当于原始计算量中,凡有M和N的地方都乘α,实际上降低了α的平方倍

3.4. Resolution Multiplier: Reduced Representation(分辨率超参数ρ)
ρ负责控制输入图像的尺寸,间接控制中间层feature map的大小。输入的尺寸大,中间层的feature map就大,feature map大卷积的次数就会变多,次数变多运算量变大
ρ的值也是0-1,他的含义是输入图像的分辨率,表示224、192、160、128
计算量,所有的M、N乘α,所有的DF乘ρ

实际上相对宽度超参数α式子,再降低了ρ的平方倍,参数量相比之前没有减少
文中给出了常规卷积、深度可分离卷积以及添加了两种超参数深度可分离卷积的参数量对比例子,输入的feature map 为14x14x512,卷积核大小为3x3x512x512,乘法 和加法的计算量如下图:
通过对比看可以看到添加了两张超参数的网络计算量和权重参数量都相应减少,再添了ρ参数之后发现参数量因为要在加了α的式子中所有的14乘0.714,但是橙色式子中没有14,所以参数量没有变化。添加ρ参数(分辨率超参数)不影响权重的参数量

4、Experiments
首先使用网络的宽度进行探究而不是深度,展示了MobileNet在两个超参数不同情况下而表现,也进行了MobileNet在不同场景下的实验
4.1、Model Choices
实验一
标准卷积下的MobileNet表现情况,可以看到差不多精度的情况下,使用深度可分录卷积的MobileNet参数量和计算量要小很多

实验二
使用一个浅层MobileNet和一个使用α等于0.75的MobileNet网络结构的对比,其中浅层MobileNet结构试将本文原始结构中的5个重复模块去掉

最终结果如下,可以看到二者的参数量和计算量差不多,但是深度减少之后的浅网络精度相对降低,得出结论超参数比减少网络层数有用

4.2. Model Shrinking Hyperparameters
实验三
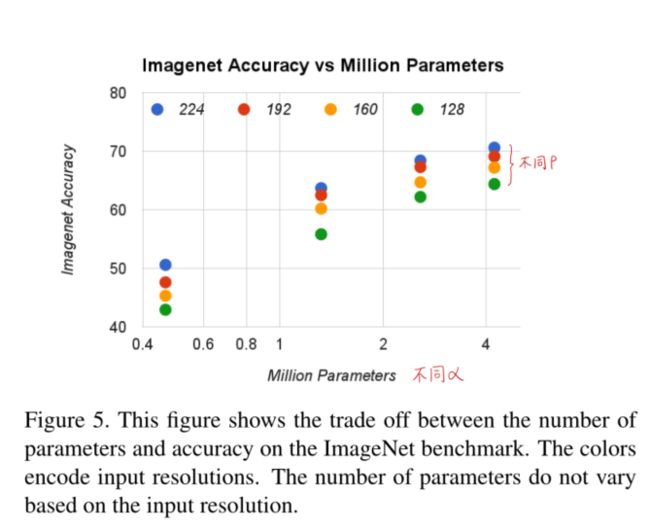
对比不同α(宽度)的效果,可以明显看出准确率随着α减小而降低,前三个相对平滑,当值为0.25时突然急剧降低

实验四
对比不同分辨率参数ρ的效果,准确率随着ρ值减少而降低,相对降低更平滑
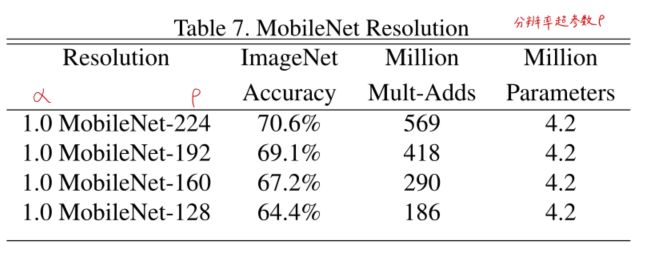
计算量和准确度之间的关系:准确率和计算量的对数呈线性关系,或者说准确率=kLn(计算量),会出现边际效应
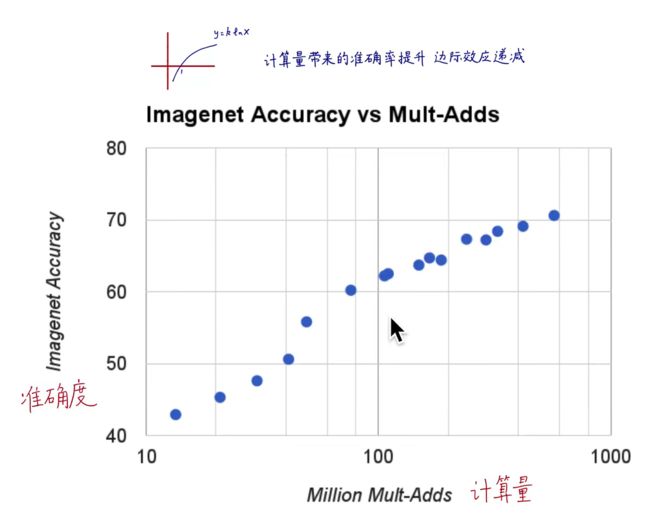
不同α和不同ρ对准确度和计算量的影响:
实验五
与其他网络结构对比


4.3. Fine Grained Recognition(细粒度图像分类)
实验六
使用斯坦福狗数据集(细粒度)对比InceptionV3和不同超参数下的MobileNet结构进行精度和参数量对比,MobileNet表现依然良好
准确率差不多,参数量和计算量大大减少
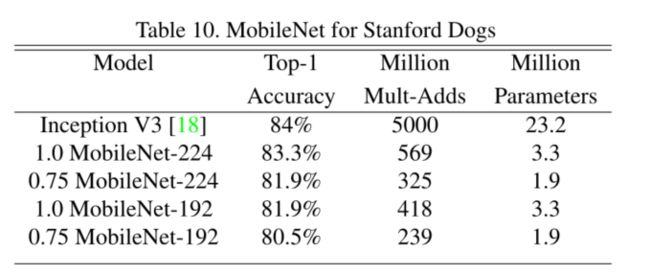
4.4. Large Scale Geolocalizaton(以图搜地)
实验七
基于以图搜地,对比不同网络结构进行对比,MobileNet的表现比之前的效果好

4.5. Face Attributes(人脸属性识别)
人脸属性识别是一个不可指的或深奥的训练问题,本文使用MobileNet和知识蒸馏结合做实验,MobileNet是知识蒸馏中的学生网络
如何蒸馏:
首先用MobileNet做为学生网络,让教师网络的预测结果作为学生网络的教材(标签),让学生网络尽可能的去模仿教师网络的行为,而不是像常规网络那样去模仿真实结果。教师网络的输出结构会经过soft再作为学生网络的标签,因此这就可以让学生网络从“无限“数据中学习。
小型网络MobileNet和产出大量结果的知识蒸馏相结合,碰撞出了不可思议的火花,效果相对之前更好
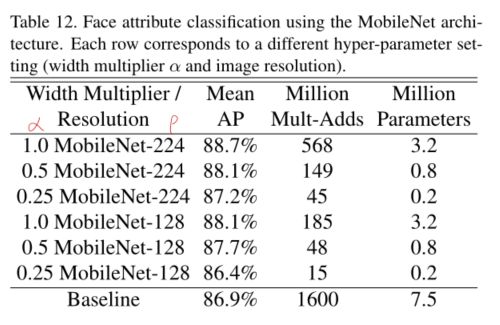
4.6. Object Detection(目标检测)
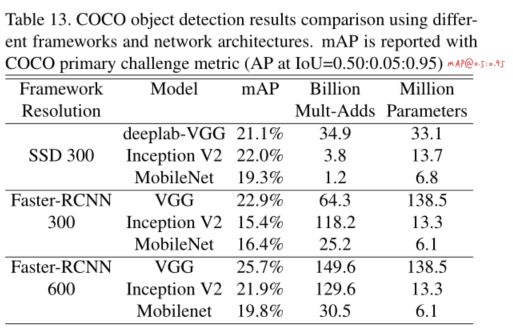
MobileNet使用在很多主流目标识别的骨干网络中,基于SSD300、Faster-RCNN300、Faster-RCNN600框架进行,在COCO数据集排除了8k张minival images数据集上进行训练,排除的8k张minival images数据作为测试,更换不同骨干网络,进行对比试验
4.7. Face Embeddings(人脸识别)
基于triplet loss训练的FaceNet是现在效果比较好的网络结构,为了训练移动端的人脸识别,再次使用知识蒸馏,并结合均方误差(L2矩离)进行训练

5. Conclusion
略
References
[9]G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 2,7
知识蒸馏
[13]S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.1,3,7
BN-Inception(深度学习必备)
[23]S. Ren, K. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91–99, 2015.7
Faster-RCNN
[24]O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein,et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3):211–252,2015.1
ImagesNet竞赛
[26]L. Sifre.Rigid-motion scattering for image classification.PhD thesis, Ph. D. thesis, 2014.1,3
深度可分离卷积
Pytorch代码
class Net(nn.Module): def __init__(self): super(Net, self).__init__() def conv_bn(inp, oup, stride): return nn.Sequential( nn.Conv2d(inp, oup, 3, stride, 1, bias=False), nn.BatchNorm2d(oup), nn.ReLU(inplace=True) ) def conv_dw(inp, oup, stride): return nn.Sequential( nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False), nn.BatchNorm2d(inp), nn.ReLU(inplace=True), nn.Conv2d(inp, oup, 1, 1, 0, bias=False), nn.BatchNorm2d(oup), nn.ReLU(inplace=True), ) self.model = nn.Sequential( conv_bn( 3, 32, 2), conv_dw( 32, 64, 1), conv_dw( 64, 128, 2), conv_dw(128, 128, 1), conv_dw(128, 256, 2), conv_dw(256, 256, 1), conv_dw(256, 512, 2), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 512, 1), conv_dw(512, 1024, 2), conv_dw(1024, 1024, 1), nn.AvgPool2d(7), ) self.fc = nn.Linear(1024, 1000) def forward(self, x): x = self.model(x) x = x.view(-1, 1024) x = self.fc(x) return x
参考:
【精读AI论文】谷歌轻量化网络MobileNet V1(附MobileNetV1实时图像分类代码)_哔哩哔哩_bilibili
轻量级神经网络“巡礼”(二)—— MobileNet,从V1到V3 - 知乎
https://medium.com/@yu4u/why-mobilenet-and-its-variants-e-g-shufflenet-are-fast-1c7048b9618d
https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215