斯坦福CS231n听课笔记
课程视频链接
目录
- Lec 1 计算机视觉简介
-
- 历史
- Lec2 图像分类的流程
-
- 图像分类的流程
- 图形分类中可能出现的问题
- 图像分类的尝试
- KNN
- 如何设置超参
- 线性分类
- Lec3 损失函数和优化
-
- 损失函数
- 正则化
- 优化
- 其他
- Lec4 反向传播&神经网络
-
- 反向传播
- Lec5 卷积神经网络
-
- 全连接层
- 卷积层
- 池化层
- 趋势
- Lec6 训练神经网络(1)
-
- 激活函数
-
- sigmoid
- tanh
- ReLu
- Leaky ReLu
- PReLu
- ELU
- maxout“Neuron”
- 使用激活函数的Tips
- 预处理
-
- step1:数据预处理
- step2:初始化权值
- 批量归一化(Batch Normalization,BN)
- 监视训练
- 超参数选择
- 采样
- 可视化损失曲线
- 可视化准确率
- Lec7 训练神经网络
-
- 更好的优化方法
- 正则化
- 迁移学习(transfer learning)
- Lec8 深度学习软件
-
- CPUs vs GPUs
- Frameworks
-
- Pytorch
- 动态计算图VS静态计算图
- Lec9 CNN架构
-
- LeNet-5
- AlexNet
- ZFNet
- VGG
- GoogleNet
- ResNet
- 比较不同模型的复杂度
- NiN(Network in Network)
- Lec10 RNN
- Lec11 识别与分割
- Lec12 可视化和理解CNN
- Lec13 生成式模型
-
- GAN(Generative Adversarial Networks)
- Lec14 深度强化学习
Lec 1 计算机视觉简介

历史
1960s-1980s: 目标识别(object recognition)
- David Mars
输入图片
->原始草图(包括边,端点,直线,曲线等简单结构)
->2.5D 草图(层,视觉场景的不连续性)
->3D模型(分层组织起来的表面和体积)
1970s: 如何识别和表现物体
将物体的复杂结构简化成有更简单形状和几何结构的集合体

1990-2010:目标分割(object segmentation)
目标识别太难,则先将像素分组成不同的具有意义的区域
1.面部识别
2.基于特征的识别
- SIFT:一些关键的特征在变化中保持表现性(diagnostic)和不变性
- 空间金字塔匹配(Spatial Pyramid Matching): 判断场景的类型
3.解构人体并识别
4.目标识别(摄像机和图像的发展)
- 一个基准数据集:PASCAL Visual Object Challenge(20个类别)
- 一个项目:Image Net(百万图片;22,000个类别)(动机:试图识别所有物体;机器学习的过拟合问题
选读教材
Deep Learning by Goodfellow, Bengio, and Courville
Lec2 图像分类的流程
图像分类的流程
- 接受输入图像
- 获得预先确定的类别/标签集
- 给图像赋予标签
图形分类中可能出现的问题
- 语义鸿沟(semantic gap): 给图像赋予语义标签和计算机实际看到的像素值之间的巨大差距
- 视点变化(viewpoint variation): 从不同角度看物体,像素数组看起来不一样,但都是同一个物体
- 照明(illumination):图像的亮度不同,但都是同一个物体
- 形变(deformation):图像种物体的位置和形状的变化
- 遮挡(occlusion): 物体部分隐藏起来
- 背景混杂(bg clutter): 物体与背景融为一体
- 同类差异(intraclass difference): 不同颜色、种类等等,但都是同一个物体
图像分类的尝试
- 计算边、角、边界(但是不同种类不同)
- 数据驱动方式
1)收集数据
2)用机器学习的方法训练一个分类器,学习到如何识别不同类别物体的知识
3)在新图像数据上进行评估
4)分为train和predict两个函数
KNN
| 比较 | 1近邻算法(1-nearest neighbors) | K近邻算法(K-nearest neighbors) |
|---|---|---|
| 方法 | 获取所有的图像数据和标签,给图像打上与它最相似的训练图像的标签。训练快,预测慢 | 不只是寻找最近的点,而是根据距离函数,找到最近的k个点,在这些相邻点中进行投票,选择票数多的近邻点作为预测结果(take a majority vote) |
| 距离函数 | L1 distance(曼哈顿距离) | L2 distance(欧氏距离) |
L1 distance:像素之间绝对值的总和。L1的结果取决于坐标系。 如果数据的vector的每一维有特定的含义,可以尝试;否则L2更好
KNN中的超参
超参是算法中需要我们设置而不是学来的参数,与具体问题有关
- K的值
- 距离函数
实际中,使用KNN进行图像分类不常见,原因如下:
- 运算时间长
- 向量化的距离函数作为距离衡量标准,不太适合用在比较图像上,表示图像之间视觉的相似度
- 维度灾难。k近邻算法像是用训练数据将样本空间分成几块,如果希望分类器能有好结果,需要训练数据能密集地分布在空间中,否则最近邻点的实际距离可能很远,也就是说和待测样本的相似性没有那么高。但是如果想要密集地分布在空间中,需要指数倍的训练数据

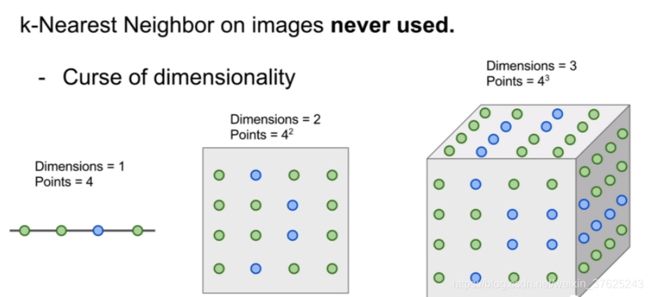
如何设置超参

将数据分为训练集,验证集和测试集
-
训练集VS验证集:算法知道训练集的标签,但不知道验证集的。验证集的标签只是用来检测算法的效果
-
#3:用不同的参数在训练集上进行训练并在验证集上进行评估,最后选择在验证集上表现最好的参数,在测试集上跑出最终结果
-
#4:交叉验证
使用n折交叉验证,对每个k,对算法进行n次测试,观察算法在不同验证集上的方差,量化算法的好坏。画图得出算法的好坏与超参的关系,选择出使效果最好的超参。小数据集中用得较多,深度学习中不多,因为训练比较耗时
线性分类
参数化的方法(Parametric approach)
- 将一张图像拉伸成一个长向量作为输入数据x,参数/权重W,f函数得到对应n个类别的n个数字作为分数
- 深度学习中整个描述都是关于如何选取/设计函数f
- 偏置项(bias):不与训练数据交互,只是给出一些独立于数据,仅仅针对一些类别的偏好值。比如数据集中,cat比dog多,cat的bias会比其他类更高
KNN与参数化方法的比较
- KNN中,训练数据要保留直至运用到测试中
- 参数化方法中,训练之后将学到的知识总结、保留到参数矩阵W,测试时就不需要训练数据,只需要参数矩阵,使得test更高效快捷

线性分类可以看作是一种模板匹配方法 - 每一行表示了图像在某个类别上的一个模板
- 点乘体现出这个类别的模板和图像的像素之间的相似度
- 偏置项给出每个类别上数据独立缩放的偏移量
从图像观点来看,线性分类也可以作为点和高维空间的概念
- 每张图像都类似于高维空间中的一个点,线性分类器试图画出线性决策边界来区别一个类别和其他类别

线性分类可能出现的问题
- 线性分类器只为每个类学习一种模板
- #1:奇偶划分。无法画出一条直线来区分蓝色和红色区域
- #2:数据本身的分布非线性
- #3:多分类问题。多模态数据,如一个类别出现在不同的空间领域中,无法画直线区分
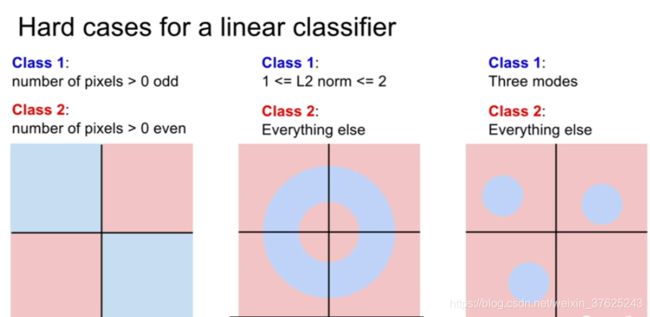
Lec3 损失函数和优化
一句话概括
- 损失函数:定量地衡量W的好坏
- 优化:从W的可行域中找到W取什么值令效果最好
损失函数

合页损失函数(hinge loss)
- 多分类SVM的损失函数
- 对所有错误分类上的分数求和,比较正确分类的分数和错误分类的分数。若正确分类的分数比错误分类的分数高出某个安全边距(safety margin),说明真实分类的分数比任何其他错误分类的分数都高出许多,则成功分类,损失为0

- 安全边距的值不重要,最后会在放缩操作中被消去
- 如果所有分数近乎为0且差不多相等,损失函数预计会是分类的数量减去1(即C-1)。这可以作为一个调试策略。刚开始训练时,W很小,结果接近这种情况。如果结果与C-1相差很大,可能代码出了问题
- 如果对所有分类分数进行相加,结果损失函数会+1。如果函数不是求和,而是取平均,答案不会改变,只是对分数做了一个缩放,我们不管分数具体是多少
- 如果找到一个W令损失函数为0,这个W不是唯一的,对其进行缩放得到的结果同样能使损失函数为0
正则化
在损失函数数据项之后增加一个正则项,目的是减轻模型的复杂度而不是试图取拟合数据,鼓励损失函数选择更简单的W,从而避免过拟合

常见正则化类型

- L1正则化对复杂性具有不同的概念,用权重向量中0的个数来衡量复杂度,更倾向于稀疏向量
- L2正则化更加能够传递出x中不同元素值的影响,当输入的x存在变化时,鲁棒性可能更好,结果主要取决于x向量的整体分布,而不是个别元素
优化
试图找到W,最小化了最终的损失函数
方法
- #1:随机搜索。随机采样权重值,看效果
- #2:选取斜率最大(函数下降最快)的方向,在多元情况下,即梯度(偏导数组成的向量)
梯度
- 数值梯度(numerical gradient):用有限差分法计算每个方向上的斜率。约数,慢,容易写出来
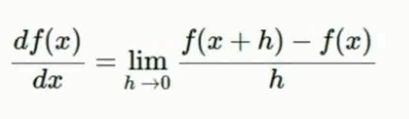
- 解析梯度(analytic gradient):利用微积分知识写出梯度表达式。精确,快,公式容易出错
- 调试策略:使用解析梯度,减少参数数量,用数值梯度作为测试
梯度下降
初始化W矩阵,计算损失和梯度,向梯度相反方向更新权重值。梯度指函数最大增加方向,故梯度减小指的是函数下降的方向。每次行动的步长:学习率
- 随机梯度下降
计算整个数据集的误差和梯度值太慢,因此在每次迭代中,选取一小部分数据(minibatch,2的n次幂),用这部分数据计算误差和梯度

其他
softmax 分类器(多项逻辑回归)
- 将分数指数化以便结果都是正数,对指数的和进行归一化。促使计算的得到的概率分布去匹配目标概率分布,即正确的类占有几乎全部的概率
- 如果所有分数近乎为0且差不多相等,第一次迭代训练后得到的结果如果不是log(c),则算法出现问题
对比
- SVM损失函数:观察正确分类的分数和不正确分类的分数的边际
- softmax:计算一个概率分布,然后观察负对数概率正确的分类
特征表示
计算图像中的特征向量,合在一起成为图像的特征表示,代替原始像素传入分类器
-
颜色直方图
获取每个像素对应的光谱,映射到柱状中,计算每个柱中像素点出现的频次。从全局上显示图像中有哪些颜色 -
方向梯度直方图
将图像分为8*8像素的区域,在每个区域中计算每个像素值的边缘方向。将这些边缘方向量化到几个组,在每个区域内,计算不同的边缘方向从而得到直方图 -
词袋
获得一堆图像,采样小的随机块,用k均值等方法使其聚合成簇,得到不同的簇中心,代表视觉单词的不同类型 -
以前是先提取图像特征,输入线性分类器之后,训练时这些特征不再改变,仅仅改变分类器
-
现在不提前记录特征,而是直接从数据中学习特征
Lec4 反向传播&神经网络
计算图
表示任何函数。节点表示要执行的每一步计算
反向传播
- 递归地使用链式法则来计算计算图中每个变量的梯度
- 从计算图的最末端开始,输出最终变量在某方向上的梯度(偏导f/偏导f=1),然后反向进行下一步
- 该步骤的梯度=上游梯度*本地梯度
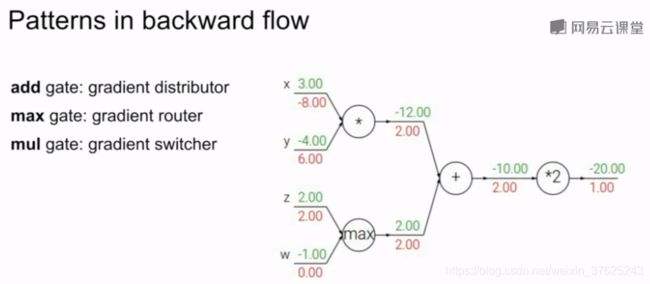
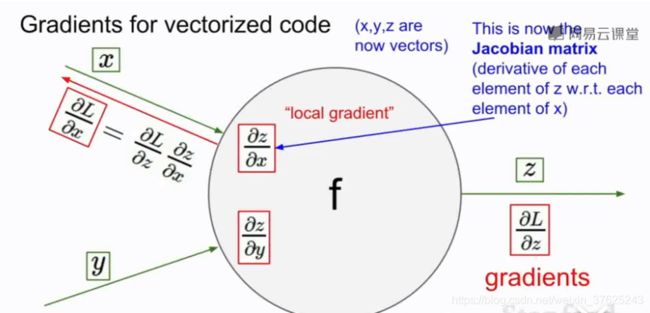
- 当x,y,z不是标量而是向量时,本地梯度是一个雅各比矩阵,矩阵的每个元素是输出变量的每个元素对输入变量每个元素分别求导的结果。每个梯度元素量化了每个元素对最终输出的贡献
- 反向传播可以看做是门单元之间在通过梯度信号相互通信,只要让它们的输入沿着梯度方向变化,无论它们自己的输出值在何种程度上升或降低,都是为了让整个网络的输出值更高
- 神经网络可以理解为 由简单函数组成的一组函数,用一种层次化的方式将其堆叠,形成一个更复杂的非线性函数,多阶段分层计算
- 隐藏层h是W1中每个模板的得分,W2是中间变量W1得分的加权权重
- 正向计算(feed forward)
神经网络中的节点进行神经元的各种计算,每个隐藏层是一个向量,一组神经元的集合。利用矩阵乘法计算神经元的值
Lec5 卷积神经网络
全连接层
- 向量操作
- 输入图像input->将像素展开成行向量->Wx->输出激活值
卷积层
-
保全输入的空间结构,卷积核可成为这个神经元的感知野
-
输入图像input,保持三维形状->使用多个卷积核(每个卷积核的权重是一样的)作为权重矩阵,从图像左上角开始,在图像像素矩阵上滑动,计算点积->输出激活映射
-
多个卷积层依次堆叠,用激活函数对其进行逐一处理,一层的输出作为下一层的输入
-
多个卷积层作用在图像的同一区域,但是有不同的作用,代表从简单到复杂的特征序列。前面几层一般代表低阶的图像特征,如边缘;中间层更加复杂,如边角、斑点等。这与对视觉神经细胞的研究结果一致,大脑对看到的东西的感知也是从简单到复杂的神经元
-
可以用0填充原始像素矩阵来保持输入图像的尺寸
Q:填充0是否意味着在边角添加了新的特征?
A:我们还是尽力处理图像范围之内的东西,检测这个区域内的模板的某些部分,零填充只是其中一种方式,处理实际问题时这是一种合理的方法
-
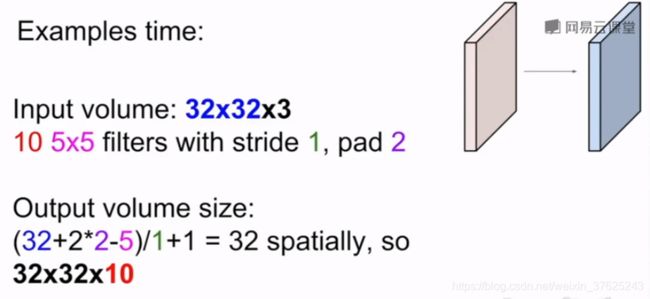
卷积后的形状由输入维度N,卷积核大小F,步长stride,零填充的维度P决定。最后得到的形状为outsizeoutsize卷积核数量
output size= (N-F+2p)/stride+1 -
通常,卷积的步长为1,卷积核数量为2的幂次,形状为F*F(常见的F有3,5,7),零填充大小(F-1)/2

池化层
- 让生成的表示更小、更容易控制,这样参数量更少。相当于在平面上做降采样(不对深度进行此操作)
- 最大池化(max pooling):filter以一定步长划过整个区域,每次提取其所在区域的最大值,可以看作是这组滤波器在图像任意区域的激活程度的一个显著值。通常步长设定为不会使其发生重叠。一般不在池化层做零填充,因为池化层只做降采样。常见尺寸:2x2,步长2;3x3,步长3
趋势
- 更小的卷积核,更深的结构
- 丢弃池化层和全连接层,只保留卷积层
Lec6 训练神经网络(1)
激活函数
输入数据->全连接层/卷积层中乘以权重->激活函数

sigmoid
- 将数据挤压到0-1之间
- 存在的几个问题:
- 饱和神经元将使得梯度消失
x为较大的负数或较大的正数时,处于sigmoid函数的平滑区域,求导之后接近0,经过链式法则,零梯度会传递到下游节点,导致下游梯度消失 - 非零中心函数

sigmoid导数始终非负,局部梯度df/dw=x。如果所有输入x都为正或都为负,则sigmoid对w的导数始终为正数或始终为负数,导致只能朝两种方向更新梯度,梯度更新效率很低。因此应该尽量使用以0为中心的输入数据
- exp()函数计算较为耗时。但不是大问题
- 饱和神经元将使得梯度消失
tanh
- 挤压到-1到1,以零为中心
ReLu
- max(0,x)不会在正数区产生饱和现象,计算成本不高,收敛快6倍
- 存在的问题:
- 不以0为中心,负半轴产生饱和会出现梯度消失
- 如果学习率设得太高,做大量的更新,权值不断波动,ReLu会被数据多样性淘汰掉:一开始效果很好,但在某个时间点之后开始变差最后挂掉
Leaky ReLu
- 在负半轴给出一个微小的负斜率

PReLu
- α为可以反向传播和学习的参数,有更多的灵活性

ELU
- 输出均值接近零
- 负饱和机制,使得模型对噪音有更强的鲁棒性

maxout“Neuron”
- 没有先做点积运算
- 泛化ReLu和Leaky ReLu
- 另一个线性机制的操作,既不会饱和也不会消亡,但每个神经元的参数数量翻倍

使用激活函数的Tips

预处理
step1:数据预处理

- 零中心化:数据为全正或者全负时,优化方向是次优的
- 归一化:所有特征在相同值域内,贡献相同
- 在处理图像时,归一化用得少,因为在每个位置已经得到了相对可比较的范围。零中心化有以下两种方式,二者没有太大的不同,后者更容易传送和处理

- 在训练阶段算出均值,以同样的均值在测试阶段使用
step2:初始化权值
- 如果W=0:所有神经元都做相同的事情,输出相同数据,得到相同梯度,这里基本没有打破参数对称问题。但实际上希望它们学到不同的东西
- 几种初始化方法:
- 所有权重初始化为小的随机数
从均值为0,标准差为0.01的标准高斯分布中抽样,再乘以0.01。深层网络可能会出现激活值都接近0的情况,这样在反向传播中,每次传回的梯度乘以一个很小的值,结果会是梯度几乎没有更新
从均值为0,标准差为0.01的标准高斯分布中抽样,再乘以1。权重都很大,在relu下激活值会趋于-1或者+1,会导致饱和,以致于所有梯度趋于0,权重得不到更新 - Xavier初始化
从标准高斯分布中取样,再根据输入数量进行缩放。要求输入的方差等于输出的方差。如果输入量较小,将除以较小的数,得到较大的权重;反之亦然
Relu每次会将一半的激活值设为0,相当于把神经元减半,实际上是把得到的方差减半。除以2可以解决这个问题
- 所有权重初始化为小的随机数
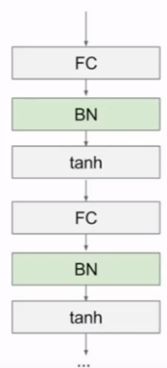
批量归一化(Batch Normalization,BN)
参考 https://www.cnblogs.com/guoyaohua/p/8724433.html
-
让激活数据在训练开始前通过一个网络,网络处理数据使其服从标准高斯分布。在神经网络训练过程中使得每一层的输入保持相同分布
-
批量归一化可以理解为在网络的每一层之前都做预处理,只是这种操作以另一种方式与网络集成在了一起。通常位于全连接层或卷积层之后,激活函数之前。
-
本质思想:
因为深层神经网络在做非线性变换前的激活输入值(就是那个WX+b)随着网络深度加深或者在训练过程中之所以收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近,导致反向传播时低层神经网络的梯度消失。
而BN通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,使得激活输入值落在激活函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,让梯度变大,避免梯度消失问题产生。梯度变大意味着学习收敛速度快,能大大加快训练速度。 -
BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift)
用一个常量γ进行缩放,再用β进行平移,这样就恢复了恒等函数,就像没有进行BN一样。BN的作用在于将数据转化为单位高斯数据,但不总是最好的选择,进行缩放和平移可以增加灵活性。
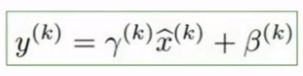
网络可以学习到γ=标准差,β=均值

-
对每个batch计算均值,方差->归一化->缩放平移,从而改进了整个网络的梯度流,增强了鲁棒性,能在更广范围的学习率和不同初始值下工作
强制输入符合高斯分布,会损失结构吗?不会,只是缩放到适合操作的区域


监视训练
- 数据预处理->选择网络结构->初始化,检查损失函数完整性->确定学习率
- 损失值下降不明显:学习率太小
- 损失值太大:学习率太大
- 学习率通常设置在10-3到10-5之间
Q:损失没有什么变化,准确率却快速提高?
A:分布依然很分散,但都在朝正确的方向轻微移动,因为正在选择最大的准确率,因此准确率会得到很大提升
超参数选择
粗细粒交叉搜索(coarse to fine search)
- 一开始处理很大的搜索范围,用几个epoch的迭代来验证,可以缩小范围,圈定合适的超参所在的区域,再对这个小范围重复这个过程,进一步精确搜索
- 用对数来优化效果更好。用10的幂次比在某个范围内均匀采样要好
采样
随机采样/网格采样

- 对每个超参的一组固定值采样,不如随机采样
- 对每个超参在一定范围内进行随机采样,如图上方的绿色曲线,表示了较好值的位置,如果采用网格分布,采样的值很少,错过了很多好的局域
- 当模型对某个超参比对其他超参更敏感时,使用随机搜索对超参空间覆盖更好
可视化损失曲线


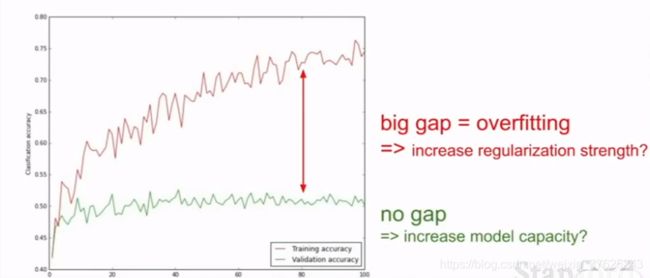
可视化准确率
观察训练精度和验证精度之间的gap
Lec7 训练神经网络
更好的优化方法
-
SGD的问题:
- 若损失等高线在一个方向上变化很快,在其他上很慢,梯度下降会做之字形运动,收敛很慢
- 卡在局部极小值/鞍点
局部极小值:往任何一个方向损失都增加,但梯度为0
鞍点:在一个方向上损失函数增加,另一个方向上损失函数减小,在鞍点处梯度为0,梯度在此处不再更新或者幅度很小
在高维神经网络中,后者出现的可能性更大
-
SGD+Momentun动量
保持一个不随时间变化的速度,将梯度估计加在速度上。在这个速度的方向上前进,用摩擦系数进行衰减,之后加到梯度上。即使到了局部极小点或鞍点,因为有速度所以仍然可以越过这样的点继续下降,更平稳地接近最小点

-
Nesterov Momentum
进行换元之后可以同时计算损失和梯度。
因为有校正因子,与常规方法相比,该方法不会非常剧烈地越过局部极小值点

-
AdaGrad
优化过程中,需要保持一个训练过程中的每一步梯度的平方和的持续估计。训练时不断将当前梯度平方累加到这个梯度平方项,更新参数时会除以梯度平方的实际值。这样的放缩对矩阵中条件数(condition number)很大的情形有什么改进?假设有两个坐标轴,一个轴方向有很大的梯度,另一个方向却有很小的梯度,随着累加很小梯度的平方,我们会在最后更新参数时除以一个很小的数字,从而加速在小梯度维度上的学习速度,相应的在另一个轴方向上会变慢,也就是在每个维度上进行大致相同的优化
当时间增加时,步长会变得越来越小。因为是随着时间累加梯度平方的估计,这个估计值随时间单调递增。当优化函数为凸函数时效果很好,接近极值点时会慢下来逐渐收敛,但在非凸函数时,会困住
-
RMSProp
对AdaGrad的改进,乘以一个衰减率,让平方梯度按照一定的比率下降。但可能会造成训练一直在变慢

-
Adam
-
PMSProp+梯度平方/动量+第二个梯度平方,合并了两者各自好的性质
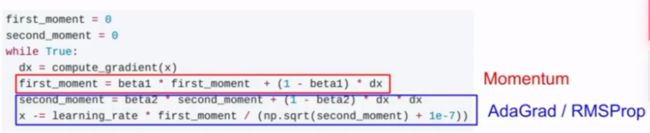
-
Q:在最初的第一步会发生什么?
A:开始时,第二动量被设为0,经过一步更新后,第二动量的衰减率大概是0.9或0.99,此时第二动量仍然非常接近0,然后除以第二动量(一个非常小的数),因此会得到一个很大的步长,说明初始化工作存在问题,最终很难收敛 -
->添加偏置校正项
更新第一、第二动量后,构造其无偏估计,用这个而不是初始值来更新

-
Adam几乎是解决任何新问题的默认算法
-
-
学习率可以衰减

- 随迭代次数衰减

- 指数衰减
- 随迭代次数衰减
-
二阶优化

- 牛顿步长:计算海森矩阵(二阶偏导矩阵),求它的逆,以便直接走到用二次逼近后的最小值的地方
- 与之前更新规则不同的地方:不需要学习率。用二次逼近直接走到,但因为海森矩阵太大,存不下
- 拟牛顿法:低阶逼近逆
-
L-BFGS:三阶逼近
如果问题没有很多随机性而且参数很少,内存能够承受整个批次的更新,可以用L-BFGS

-
如何减少训练和测试之间的误差?
- 模型集成(model ensembles)
从不同的随机初始值上训练10个不同的模型,测试时在10个模型上进行预测,平均10个模型的预测结果,或者在一次训练过程中保存多个快照。能缓解一些过拟合

- Polak平均
训练模型时,对不同时刻的每个模型参数求指数衰减平均值,从而得到网络训练中一个比较平滑的集成模型,之后使用这些平滑衰减的平均后的模型参数,而不是截至在某一个时刻的模型参数。并不常见

- 模型集成(model ensembles)
正则化
- 减小训练和测试集上的差异,提高单个模型的效果
- Dropout
- 每次在网络中正向传递时,在每层随机对一些神经元置零
- Wx+b->置零->传给下一层
- 常用在全连接层中。用在卷积层中时通常是将某个特征整个置零,而不是其中的某些元素
- dropout避免了特征间的相互适应(co-adaptation);dropout之后,是在一个子网络中用神经元的子集进行运算,dropout存在多种可能性,相当于对一群共享参数的网络做集成学习
- 在测试时,dropout增加了输出的随机性,可以通过一些积分来边缘化(average out)随机性,但是积分很难处理。或者通过采样来计算积分,但仍然会引入一些随机性。还可以通过一些方法局部逼近这个积分:用dropout的概率*激活输出。概率可以改变正则化的强度

- 一种通用的模式:
在训练时加入一些随机性,防止过拟合;在测试时抵消掉随机性,提高泛化能力

- 数据增强
- 训练时以某种方式随机转换图像,使标签保持不变
- 训练时随机裁剪图像,测试时评估一些固定的裁剪图像来抵消随机性(通常是四个角,中间,以及翻转)

- 色彩抖动(color jitter)
训练时随机改变图像的对比度和亮度

- 随机组合不同的数据增强方法

- dropconnect
随机将权重矩阵的一些值置零 - 部分最大池化(fractional max pooling)
训练时随机池化,测试时采用固定池化或者多次池化取平均值 - 随机深度(stochastic depth)
训练时丢弃掉一些层,测试时使用全部层
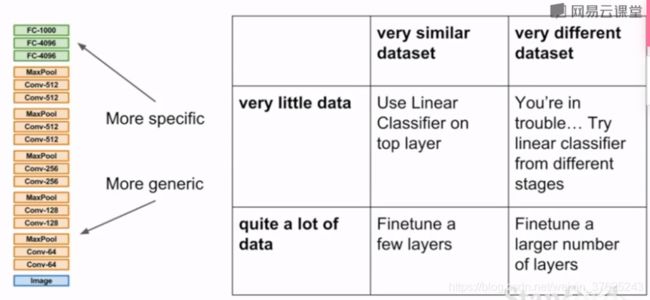
迁移学习(transfer learning)
- 下载在大数据集上进行了预训练的网络模型,然后根据实际问题进行微调。当没有很大的是数据集时,仍然能进行深度学习任务
- 先用大数据集训练。当只想把从数据集中训练出的提取特征的能力用到小数据集上时,只需修改从最后一层的特征到最后分类的输出之间的全连接层,重新随机初始化这部分矩阵,冻结其他层的权重。只需要训练最后这层,使其在新数据集上收敛
- 或者微调(fine–tuning)整个网络
- 更新网络时调低学习率,因为原始网络是在大数据集上训练的,泛化能力已经很强了,只需要有小调整来适应新数据集
- 如果新数据集和之前的大数据集相差太大,则需要多调整一些层

Lec8 深度学习软件
CPUs vs GPUs
GPU的核数多,但每个核没办法独立操作,需要共同协作,并行处理能力强

Frameworks
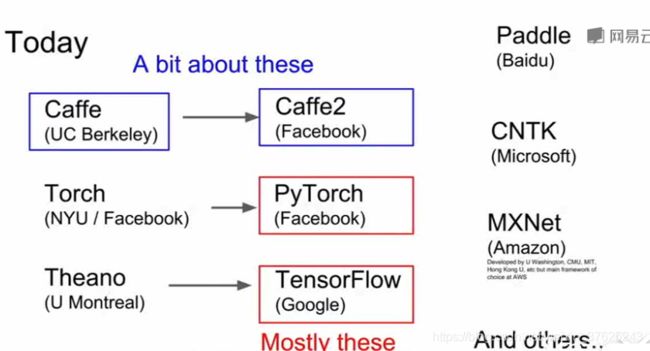

Pytorch
- 明确定义了三类抽象
Tensor:跟深度学习无关,但是可以在GPU上运行
Variable:变量对象。计算图中的节点,可以计算梯度
Module:模块对象。神经网络层,可以存储状态或可学习的权重。将模块组合起来构成一个大的网络
Tensor和变量拥有相同的API - 每次前向传播时都建立一个新的图,这使程序显得更简洁
- nn封装包:把模型定义为层的序列,线性层,RELU,循环体中每次迭代都可以得到预测值,放入损失函数得到loss,调用loss.backward自动计算梯度,在模型所有参数上循环,进行显式的梯度下降来更新模型
- 优化:将参数更新的流程抽象出来,执行更新法则。建立optimizer对象,设定学习率等参数,计算梯度之后,调用.step更新模型中的参数
- 可以定义自己的nn模块
- Dataloader
- Visdom可视化
动态计算图VS静态计算图
- 优化
静态图可以只定义一次,复用很多次,更有效率。优化的过程在前端可能代价较高,但可以通过加速减少成本 - 执行序列化

静态图中建立好了网络结构就可以保存下来,之后直接加载,不用在访问最早的代码去建立它;动态图是交叉进行图的建立和执行,所以未来想要复用模型时总是需要原来的代码 - 条件运算
动态图代码更简洁。在静态图中不能用python控制流操作,得用特殊的tf流tf.cond - 循环
在动态图中,只需要python的循环结构即可,计算图最终会得到不同的大小,但是静态图中需要定义为显式的节点 - 静态图:tf,每次运行运用的是同一个图
动态图:pytorch。建立新的计算图时,每次前向传播都更新 - 动态图的应用
- 递归结构
树结构、图结构在每个不同的数据点可能有不同的结构,计算图的结构在输入数据上重复出现 - 模块化神经网络
不同问题用不同的网络
- 递归结构
Lec9 CNN架构
LeNet-5
- 通信网络的第一个实例
- 5层网络:CONV-POOL-CONV-POOL-FC-FC-FC
- 步长为1,大小为5x5的卷积核
- 在数字识别上效果很好

AlexNet
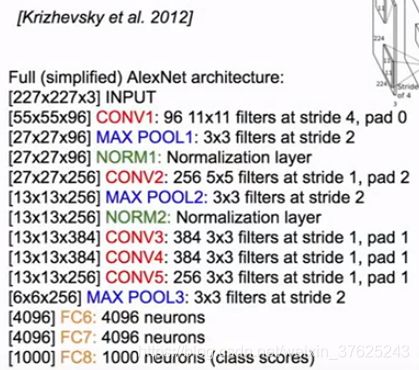
- 卷积-池化-归一化-一些卷积层,一个池化层-一些全连接层
- 第一次使用ReLu
- 本地相应归一化层,通过相邻通道来归一化响应,但不再使用
- 大量的数据增强,如翻转(flipping),晃动(jittering),裁剪(cropping),颜色归一化
- dropout0.5, batch size128
- SGD Momentum 0.9
- lr 1e-2, reduced by10
- L2权重衰减
- 7 CNN 集成:18.2->15.4%
- 在两个内存只有3GB的GTX 580 GPU上训练。将特征映射一分为二
- ImageNet结果:16.4%
- 总参数:60 million
第一层 卷积层:

输出维度:55x55x96(96个卷积核)
总参数数量:11x11x3x96=35K(每个卷积核处理一个11x11x3的数据块)
第二层 池化层:

输出维度:27x27x96
总参数数量:0
ZFNet
- 对AlexNet进行超参调优
- ImageNet结果:11.7%
VGG
- 16-19层
- 很小的卷积核,定期下采样:
- 3x3卷积核,步长1,补零1
- 2*2最大池化,步长2
Q:3*3卷积核,步长为1的卷积层的有效接受范围?
A:[7x7]
Q:为什么使用很小的卷积核?
A:与7*7卷积核有相同的感知野,但网络更深,有更多非线性,可以得到较小的参数量
- ImageNet结果:7.3%
- 19层VGG只是有更多的卷积层


GoogleNet

- 22层
- Inception模块,计算高效
设计一个好的局部网络拓扑(网络中的网络),在每层顶部堆叠这些模块。对进入相同层的相同输入并行应用不同的卷积操作,在不同层得到不同输出,在深度层面上串联在一起得到一个输出->计算复杂性

 总计算量8.54亿次!
总计算量8.54亿次!
->在消耗大量计算力的卷积层之前加一个瓶颈层,降低特征映射的维度。1x1卷积核维持了原有形状但降低了输入的深度



因此在3x3和5x5卷积之前先做1x1卷积;在池化层之后也加一个1x1卷积 - 辅助分类输出:网络太深时,梯度信号会丢失。在前面部分添加额外的信号
- 没有FC层,参数量大大减少(500万)
- ImageNet:6.7%
ResNet
- 152层
-
Q:当不断在不带残差功能的卷积网络上堆叠越来越多层时会发生什么?
A:更深的网络不能表现更好。在训练数据上也没有过拟合。这个问题是优化问题,更深的模型更难优化

解决方案:将浅层模型通过恒等映射,拷贝到剩下的深层中。这样深层模型至少跟浅层模型一样好
用模型去拟合残差H(x)-X,而不是直接拟合H(x)。相当于对输入的一个修正



-ImageNet:3.57%
比较不同模型的复杂度

左图:按算法性能顺序排序。Inception V4是表现最好的模型
右图:x轴表示操作,越大表示尝试了更多的可能性,花费更多算力;Y轴表示最高精度,越高越好;圆圈大小表示使用的内存大小。GoogleNet效率很高,空间占用量在算法训练过程中一路下降,只使用了很小的内存空间
NiN(Network in Network)
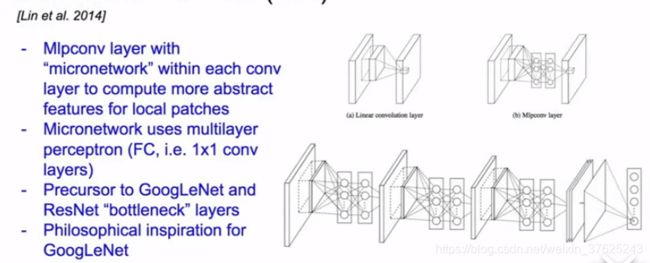
vanilla卷积层+MLP卷积层。在每个卷积层中,只要在标准卷积上叠加一个完全连接的MLP层,就能为局部图像块计算更多的抽象特征
Lec10 RNN
ResNet:合理地管理梯度流
RNN:处理大小可变的有序数据
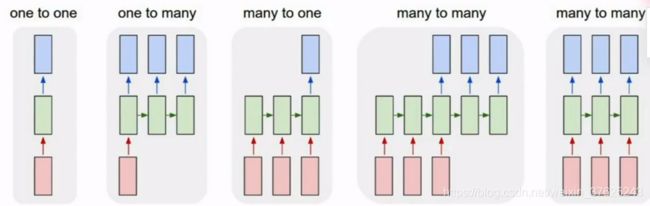
- RNN结构:
输入->每次读取新的输入时更新隐藏状态->每一个时步输出一些结果 - 循环单元的公式:

每个time step使用相同的函数,相同的W

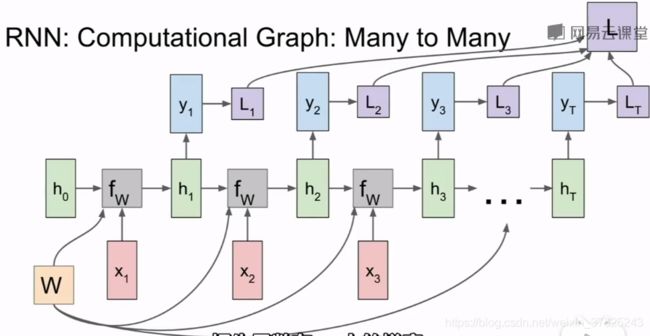
沿时间的反向传播:每次前向传播和反向传播都需要遍历整个词典,非常耗时

沿时间的截断反向传播:训练时前向计算若干步,计算这部分子序列的损失,然后沿着子序列反向传播误差,计算梯度更新参数。重复上述过程,仍会保留从第一批数据中计算得到的隐藏状态,在计算下一批数据时使用。因此前向计算是相同的。在计算梯度时,只能根据第二批数据反向传播误差,是一种近似估计梯度的方法,不要反向传播遍历非常长的序列


- Image Captioning

输入图像->CNN->图像的特征向量->RNN->标题单词 - 视觉问答
输入图像和一个用语言描述的问题->根据图像内容选出问题的正确答案
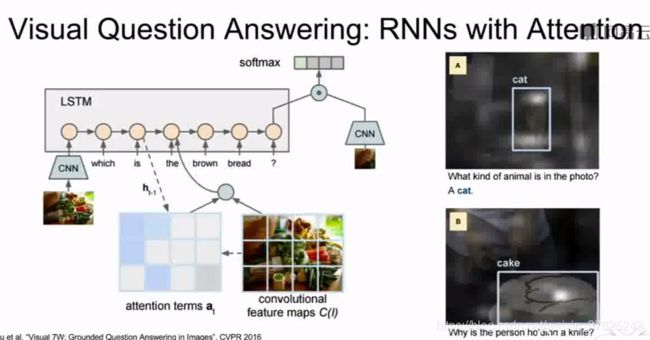
自然语言描述的问题->RNN->将问题概括为一个向量
图像->CNN->将图片概括为一个向量
结合两个向量->RNN->预测答案的概率分布 - Vanilla RNN
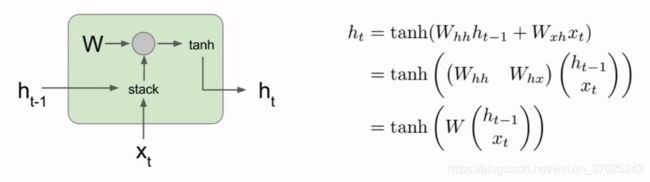
堆叠Xt,h(t-1)作为当前时间步的输入,与权重矩阵相乘,将输出通过tanh得到下一个隐藏状态
在实现矩阵乘法的层的反向传播时,实际是用权重矩阵的转置来做矩阵乘法。
解决梯度爆炸的方法:梯度截断。梯度超过阈值时进行除法
解决梯度消失的方法:换更复杂的RNN结构,如LSTM

- LSTM
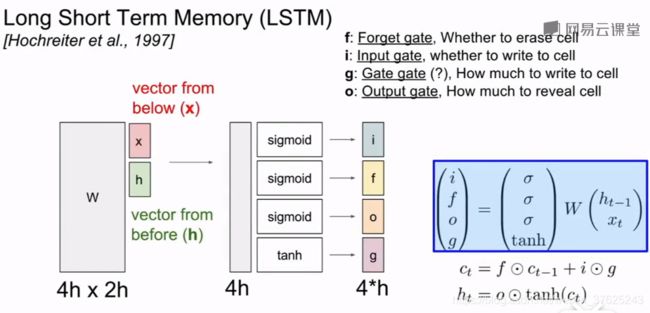
i:输入门,表示LSTM要接受多少新的输入信息
f:遗忘门,遗忘多少上一个时间步的单元记忆
o:输出门,展示多少信息给外界
g:gate gate,有多少信息要写入到输入单元
四个门使用不同的非线性函数,前三个采用sigmoid,输出0-1;最后一个采用tanh,输出范围-1~1。单元状态的每个元素在每个时间步中只能自增或者自减

输入:上一个时间步中单元的状态c,隐藏状态,当前步的输入
1.将h和x堆叠,乘上权重矩阵w,得到四个门(这些门从权重矩阵的不同部分得来,省略了非线性函数)
2.遗忘门和上一个单元状态做逐元素乘法,输入门和g做逐元素乘法并与单元状态相加,得到下一时间步的单元状态。
3.下一时间步的单元状态经过tanh的压缩,再与o进行逐元素乘法,得到下一时间步的隐藏状态

反向传播时,加法运算使得上游梯度直接被复制并通过元素相乘的方式直接贯穿了反向传播过程,最终只会通过遗忘门得到相乘后的元素。形成梯度的高速公路
优点:遗忘门是矩阵元素相乘,而不是矩阵相乘;矩阵元素相乘可能会在不同的时间点乘以不同的遗忘门,在每个时间点会发生变化,而在vanilla神经网络中,会不断地乘以相同的权重矩阵 - 高速公路神经网络
在每层中计算备用的激活函数和门函数。门函数表示之前那一层的输入和备用的激活函数之间的关联

- GRU
与LSTM相似,通过加法连接和乘法门来管理梯度流

Lec11 识别与分割
语义分割:在图像上每个像素都标注标签,但是不区分类别
分类+定位:在物体周围绘制方框。知道要寻找的类别的数量
目标检测:在物体周围绘制方框并分类,不知道要寻找的类别的数量
实例分割:图像分割+目标检测。检测所需类别的实例,标记每个实例的像素

-
语义分割
对输入图像中每个像素做分类。不区分同类物体
法1:滑动窗口,每次对图像中的一个小块进行分类。X计算量巨大

法2:全连接卷积网络,不光是从图像中提取各个图像块并分类,可以把网络当成很多卷积层堆叠在一起,一次性完成所有像素的计算。X计算量大,耗内存
损失函数:对每个像素进行分析。有一个真值表匹配输出的像素,计算输出的像素与真值像素之间的交叉熵损失

法3:在图像内做下采样,再对特征做上采样,而不是基于整个图像的维度做卷积,仅对一部分卷积层做原清晰度处理。
跨卷积(stride conv),池化也能用于减小图像尺寸


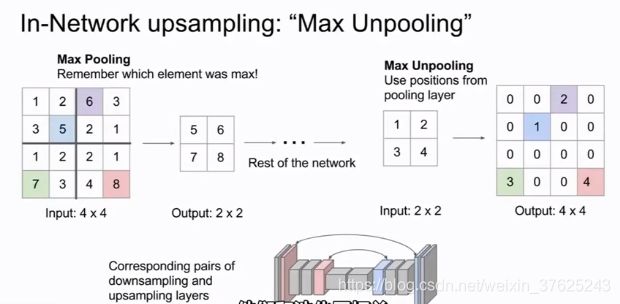
-
上采样:
1.去池化。增加网络特征映射的尺寸
2.卷积转置(transpose conv)/去卷积(deconv)/小步长卷积(strided conv)/反向跨卷积(backwards strided conv)。不仅进行上采样,还学习到了一些描述如何上采样的权重。取输入的特征映射的值,乘以卷积核,在区域内复制这些值作为输出


-
分类和定位
输入图像->巨大的卷积网络->2个全连接层,一个得到分类得分,一个得到标定边界的参数(高度,宽度,边界的xy坐标)->两组损失,图像分类上的softmax,衡量预测坐标和实际值之间差异的L2损失
多重任务损失:对损失函数进行加权求和。更好的做法是用关心的其他性能指标组成矩阵来取代原本的损失值,最终是在用性能指标矩阵在做交叉验证,而不是盯着损失值来选择参数 -
人体姿态估计human pose estimation
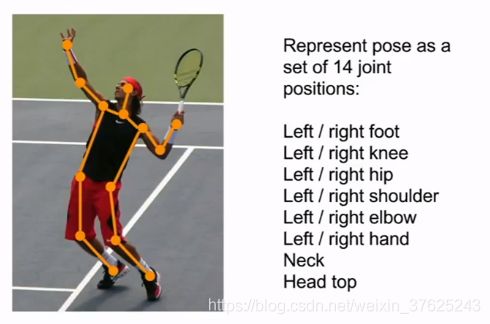
神经网络输出14个参数,给出14个关节的坐标,用回归损失评估14个点的预测表现 -
目标检测object detection
基于候选框的模型
根据输入的图像,每当图像中出现其中一类对象时,围绕对象划定一个框,并判定类别。对每张图像,分类数量是不固定的
法1:滑动窗口(sliding window)
将图像切成小块,使用CNN进行分类
问题:图块选择困难。物体可以出现在任何地方,拥有任何尺寸,任何比例;计算复杂度高

候选区域(region proposal)
候选区域网络找到物体可能存在的备选区域,CNN对区域进行分类
例:R-CNN,固定算法找到候选区域框+分类+校正区域框
问题:对每个候选区域进行独立训练,会将所有特征存入磁盘,计算复杂,消耗资源;使用固定选择模型找到候选区域,并不学习参数;测试阶段的inference也很慢

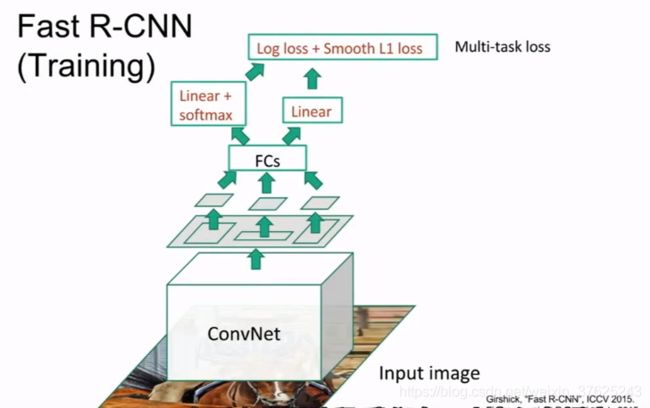
- fast R-CNN
(1)对整个图像使用CNN得到高分辨率特征映射
(2)基于备选区域投影到卷积特征映射,从卷积特征映射提取属于备选区域的卷积块,而不是直接截取备选区域,使得很多卷积可以重用
(3)ROI pooling layer对备选区域进行整形,使其符合全连接层的尺寸
(4)全连接层预测分类和对包围盒(bounding box)的线性回归补偿
- Faster R-CNN
解决了用固定函数计算备选区域耗时长的问题,也可以克服固定算法与自己的数据集不匹配的问题
让网络自身做这个预测:
(1)对整个图像运行CNN来获取特征映射
(2)备选区域网络预测备选区域:每个备选区域是否是待识别物体,校正包围盒。设置备选区域与真值重叠的阈值,大于阈值时判断为正,可以使用这个区域做选择
(3)最后的网络重复判断+校正

前馈模型
YOLO(you only look once)/SSD(single shot detection)
将这个问题作为回归问题处理,借助CNN,所有预测一次完成
将图像分为网格,在每个网格内,想象一系列的基本边界框。对每个网格和边界框,预测:边界框偏移(边界框与目标物体位置的偏差);每个边界框对应目标类别的分数;
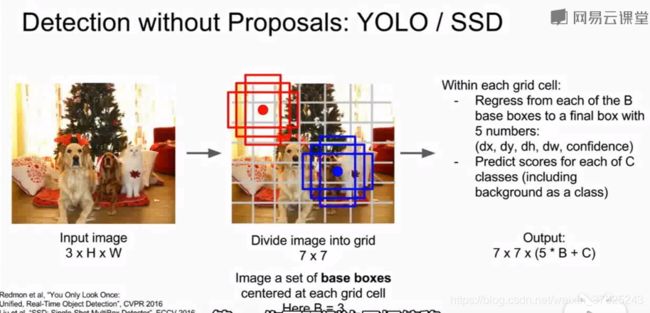
B个边界框,每个边界框对应5个值(边界框的差值,置信度),C则是对应C个类别的分数
基于候选区域的模型更容易得到更高的精度,但是速度慢;SSD更快但是准确度没那么高
-
实例分割(instance segmentation)
对输入图像预测物体位置、整个分割区域及其对应类别- Mask R-CNN
整张输入图像送进CNN和训练好的候选框生成网络,得到训练好的候选框后映射到卷积特征图上,进行尺寸对齐,进入两个分支:预测分类,同时通过回归预测候选框的坐标;通过对每个候选框的像素确定是否属于某个物体,对每个候选框预测出一个分割区域

- Mask R-CNN
Lec12 可视化和理解CNN
CNN内部的工作原理是什么?
-
第一层:可视化卷积核的权重
在该层中,卷积核在输入图像上来回滑动,输出图像块和卷积核权重的点积
可视化为64个带三个通道的11x11图像

可视化结果中,可以看出该层在寻找有向边,从不同角度和位置观察图像,与人类视觉系统早期的工作相似 -
中间层卷积核的权重
第二层用20个卷积核进行7x7的卷积,接受了16个通道的输入,无法直接可视化,因此把16x7x7的卷积核平面展开成16x7x7的灰度图,但这些卷积核没有直接连接到输入图像,因此看上去没有意义

-
最后一个隐层
在分类器前4096维的特征向量层
通过训练的CNN提取数据集检测图像,为每个图像标记4096维的向量,根据这个向量计算其近邻,可视化最后一个隐层。与根据像素空间确定近邻的方式不同,因为在其特征空间和近邻之间有很大的差异,然而图像的语义内容在特征空间中是相似的
在4096维空间中计算近邻,可视化结果表明特征空间的特性是捕捉图像的语义信息

另一种方法:降维
简单:PCA
强大:t-SNE(t-分布邻域嵌入,t-distributed stochastic neighbor embeddings),常用语可视化特征的非线性降维方法
提取大量的图像,使其在CNN上运行,记录每个图像在最后一层4096维的特征向量,使用t-SNE将4096维压缩到2维。取图像的原始像素,将其放在二维坐标上,即为对应的4096维特征向量降维版本。可视化结果体现出不连续的语义概念 -
可视化中间层的激活映射图具备可解释性

可视化输入图像中什么类型的图像块可以最大程度地激活不同的特征
选取卷积层,得到所有激活值(128x13x13,三维数据),从128通道中选一个。通过卷积层运行很多图像,记录卷积特征,可视化来自特定层特定特征的最大激活的图像块,根据激活程度排序。可视化结果体现特定层的特定特征的神经元在寻找什么特征

-
排除实验
弄清楚是图像的哪个部分导致网络做出分类的决定
用数据集平均像素值遮挡图像,记录遮挡图像的预测概率,将遮挡部分划过图像的每个位置。画出的热力图显示了作为图像遮挡部分的预测概率输出
可视化结果表明,遮挡部分可能对分类决策起重要作用。黄色和白色对应高预测概率

-
显著图
想知道哪些像素对于分类是重要的
计算关于输入像素的预测分类的分值的梯度
可视化结果显示对于输入图像的每个像素,如果进行小小的扰动,相应类的分类分值会产生多大的变化 -
引导式反向传播(guided back-propagation)
对于一个特定的图像,提取中间层的一些神经元,输入图像的哪个部分影响其分值
计算中间值关于图像像素的梯度


-
梯度上升法
了解什么类型的输入大体上会激活某个神经元

修正训练的CNN的权重,在图像的像素上执行梯度上升来合成图像最大化某些中间神经元和类的分值。执行梯度上升的过程中,不再优化网络中保持不变的权重,而是试图改变一些图像的像素,使得类的分值最大化,并加入正则项防止生成的图像过拟合特定网络的特性,强制其看起来像是自然图像。如果不加,生成的图像可能看上去没有意义
需要两个特定属性的生成图像:最大程度地激活一些分值或神经元的值,同时希望生成图像看起来是自然的


-
对抗样本

-
DeepDream:基于梯度的图像优化,放大神经网络检测到的特征
谷歌提出的博客文章

-
特征反演(feature inversion)
选取一张图像将其通过神经网络,记录其中一个图像的特征值,根据其特征标识重建这张图。
最小化捕获到的特征向量之间的距离,在生成图像的特征之间合成一个新的与之前计算过的图像特征匹配的图像

-
全变差正则化
将左右相邻的像素之间的差异拼凑成上下相邻,以尝试增加生成图像中的空间平滑度
例子:尝试使用VGG-16的relu2_2特征重构图像,图像被完美重构,不会丢弃原始像素值得许多信息。而在神经网络较高层低层次细节更容易损失,更多保留的是语义信息

-
纹理合成
给定一些纹理的输入图像块,构建模型使其生成更大块的相同纹理的图像

计算机图形学中的古老问题,采用简单的算法即可解决。2015年采用神经网络的做法:
使用格拉姆矩阵,抽取不同特征描述其共现关系,统计特征映射图中的哪些特征倾向于在空间不同位置一起激活
丢弃了体积的所有信息,因为对图像中每一点对应的特征取平均值

有了纹理在神经网络上的描述符,通过梯度上升合成图像。不是重构输入图像的全部特征映射图,而是重构输入图像格拉姆矩阵的纹理描述符

利用高层重构纹理能恢复更多的特征 -
风格迁移
取两张图像,一张作为内容图像,引导生成图像的主体;一张作为风格图像,生成图像的纹理或风格。共同做特征识别,用随机噪声初始化输出图像,计算L2范数损失和图像上的像素梯度,在生成图像上执行梯度上升。最小化内容图像的特征重构损失和风格图像的格拉姆矩阵损失,得到图像,在风格图像的艺术风格上呈现内容图像的内容
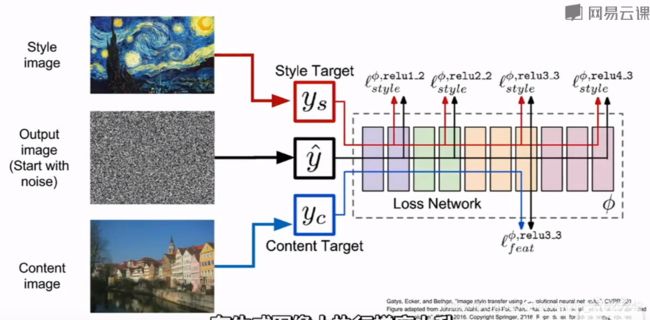
但训练太慢->训练一个可以输入内容图像的前馈网络,直接输出风格迁移后的结果。训练前馈网络时计算相同内容图像和风格图像的损失,使用相同梯度更新前馈神经网络的权重。速度很快,实时

谷歌:训练一个神经网络,在测试时间内使用一个训练好的神经网络应用许多不同风格

Lec13 生成式模型



Q:为何将先验假设也就是隐变量分布定为高斯分布?
A:我们是在定义牟征生成过程,该过程首先对z采样然后对x采样,对隐变量的属性来说高斯分布是一种合理的先验模型,接下来能够优化模型
总流程
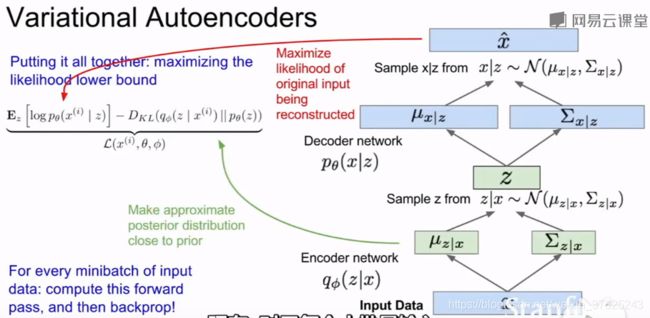
训练好VAE之后,用解码器生成数据

总结
在原来的自编码器上加入随机成分,采用了随机分布和采样的思想,从而生成数据
变分指用近似的方法来解决难解的表达式。VAE定义了一个难解的密度分布,推导出一个变化的下界然后优化它

GAN(Generative Adversarial Networks)
采用一个博弈论的方法,模型将会习得从训练分布中生成数据
问题:没有直接的方法能从复杂高维的分布中采样
解决:从简单分布中采样,例如随机噪声。需要神经网络学习的是从简单分布到训练分布的变换



梯度信号主要受到采样良好的区域支配,而事实上希望在采样效果并不好的时候多学到一些知识。为了提高学习效率,针对梯度定义一个不同的目标函数,做梯度上升。不再最小化判别器判别正确的概率,转而最大化判别器出错的概率

提升样本质量:加入卷积结构
总结


Lec14 深度强化学习
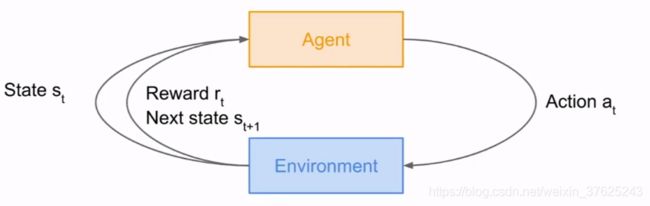
Environment赋予agent一个状态,agent采取行动,envi回馈给agent奖励,直到envi给出终态,结束这个环节
agent在所处环境中采取行动,因为其行动获得奖励。目标是学会如何采取行动以最大程度地获取奖励
- 马尔科夫性(Markov property):当前状态完全刻画了世界的状态
- 马尔科夫决策过程(MDP, Markov Decision Process):强化学习的数学表达,满足马尔科夫性
- 由(S, A, R, P, γ)描述
S:所有可能的状态
A:所有行动的集合
R:奖励的分布函数(从状态动作组到奖励的函数映射)
P:下一个状态的转移概率分布
γ:折扣因子,对近期奖励、远期奖励分配权重 - 工作方式:初始时间步骤t=0,环境会从状态分布p(s)中采样初始状态s0,然后循环:agent选择行动at,envi从R分布中采样rt,envi采样下一个状态,agent接受奖励和下一个状态

- 由(S, A, R, P, γ)描述
- 策略π(policy):指定每个状态下要采取的行动
- 目标:找到策略π*,最大化累积折扣奖励 ∑ t > 0 γ t r t \sum\limits_{t>0}\gamma^t r_{t} t>0∑γtrt
Q:如何处理MDP中的随机性(初始状态、转移概率)?
A:最大化预期的奖励总和
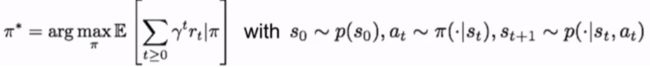
-
值函数(value function)&Q值函数(Q-value function)
- 值函数:量化一个状态的好坏
任何状态下的值函数都是从状态s的决策到现在的决策之后的预期累积回馈。从当前状态开始,累积奖励的期望值

- Q值函数:定义在状态s时采取行动a的期望奖励

最优Q值函数Q*:给定的状态动作组下得到的最大期望累积奖励

Q* 满足Bellman等式:若已知下一时间步的最佳状态动作组的价值Q*,则最优策略是采取那个能最大化这次行动将会得到的奖励r+进入下一个状态s’的价值的行动

- 值函数:量化一个状态的好坏
-
最佳策略是在任何状态下按照具体的Q* 采取最好的行动
- 求解最佳策略:值迭代算法(value iteration algorithm)
利用Bellman等式进行迭代更新。每一步中通过强化Bellman方程来改进对Q*的近似
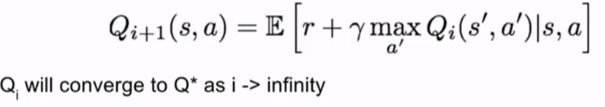
问题:不可扩展(not scalable)。必须对每个状态动作组的Q值进行计算以便进行迭代更新。计算巨大的状态空间是不可行的
- 求解最佳策略:值迭代算法(value iteration algorithm)
-
Q-learning
用函数逼近器来估计动作值函数。若函数逼近器为深度神经网络,则这种方式被称为深度Q-learning,是深度强化学习常用方法之一
网络将试图接近不同状态动作组的Q值函数

训练这个损失函数,最小化Bellman等式的误差


一次前向传播就能根据当前状态算出所有Q的值
训练Q-Network:经验回放(experience replay)
从连续样本中学习存在问题:
样本都是相关的,导致低效率的学习
当前的Q-network参数决定了接下来的训练样本的大致方向,会导致不好的反馈循环
保留状态转换的重放记忆表,在训练中获得更多的经验,不断更新表。从回放记忆中采样小批量的转移样本而不是连续样本训练Q-network。每个转换可能对多次权重更新起作用,数据效率更高

- 初始化回放记忆、Q-network
- 进行M次迭代
- 初始化状态
- 每个时间步尽量保证抽样样本空间的不同部分,选择一个随机动作,否则使用当前策略根据贪心原则选择动作
- 采取行动,得到奖励和下一个状态
- 将转换存储在回放记忆中
- 从回放的记忆中随机抽取一个小批量转换样本,进行梯度下降更新权重

-
Policy gradient
Q-learning非常复杂,但策略可以非常简单->可以直接学习这个策略吗?从一系列策略中找到最好的策略,而不是通过这个评估Q值的过程来推断
定义一类参数化策略,对每个策略定义价值。目标:找到最大化策略的参数

-
对策略参数进行梯度评价:REINFORCE算法
获取对轨迹的未来奖励的期望
采样经验轨迹,使用策略pi(θ),对每个轨迹计算奖励

对期望值求梯度,并转化为梯度的期望。可以用蒙特卡罗抽样使用得到的样本轨迹来估计梯度(强化的核心思想)

p(τ;θ)是一个轨迹的概率,是所有得到的下一个状态的转移概率和在策略π下采取行动的概率的乘积

得到的梯度会告诉我们应该对参数调节多少才能增加行动增加行动的似然值,通过乘以奖励值来放缩

希望给定奖励就可以认为所有行动就是最好的行动,需要大量的样本、对时间求平均才有一个好的估计。方差较大。
Q:如何减少方差提高估计量?
A:
1.给定梯度估计量,通过影响来自该状态的未来奖励来提高行为的概率,先不对似然值进行放缩,或通过轨迹的总奖励增加行动的似然值
2.使用折扣因子来忽略延迟效应,更关注即将获得的奖励而不是更晚的,即关注在不久的将来产生的行动组,降低晚一点发生行为的权重
3.使用baseline来减少方差
仅仅使用轨迹的原始值不一定有意义。如果奖励一直是正的,将不断提高行动的概率,但真正重要的是奖励与期望的相比更好->
提高一个已知状态的行动的概率,只要这个行动好于从那个状态得到的期望值
引入一个依赖于状态的基线函数表示期望从这个状态得到的值,那么用来增加或降低概率的奖励或放缩因子=未来奖励的期望-基线值
Q:如何选取baseline?
A:
最简单的做法:获取所有轨迹上迄今为止获得的奖励的滑动平均值。也可以利用方差
Q:不知道Q和V,如何学习?
A:Actor-Critic算法。结合policy gradients和Q-learning训练一个actor(策略)和一个critic(Q值函数),来判断一个状态怎么样,在该状态下的行动怎么样
actor决定采取哪一种行动,critic判断行动怎么样以及如何调整
之前提到的Q-learning问题必须学习每一个状态行动组的Q值,而critic只需要学习这个策略产生的状态行动组的值,减轻了critic的负担
可以结合Q-learning的技巧,如经验回放
可以由优势函数(advantage function)定义一个行动比期望值高出多少
-初始化策略参数θ和评价参数φ(phi)
-对于每次训练的迭代,在当前策略下采样M个轨迹,计算梯度
-对每个轨迹和每个时间步,计算其优势函数,用于梯度估算,并累积起来
-用同样的方法训练φ,增强值函数来学习我们的值函数,使优势函数最小化使其接近Bellman等式
-在学习和优化策略函数以及评价方程间进行迭代,更新梯度




-
行为强化:RAM(Recurrent Attention Model),硬attention
目标:图像分类
有选择地集中在图像的某些部分周围通过观察来建立信息,预测分类
-从人类感知图片的行为中获得灵感。人类在看图像时要确定图像中的内容,首先低分辨率地看见它或只看图像的某些部分,再针对局部观察
-节约计算资源,不需要处理整幅图的像素
-可以忽略图片中混乱和不相关的信息,有助于正确分类
State:目前已经看到的微景(glimpses)
Action:下一个要看的图像部分的坐标
Reward:分类正确为1,否则为0
从图像周围取得glimpse是不可导操作,因此要使用强化学习公式学习获取glimpse的行动的策略。给定目前已经看到的glimpse的状态,使用RNN对状态建模,输出下一个行动

-输入一张图像,观察图像获取glimpse,传入根据不同任务制定的神经网络
-使用RNN集成历史状态
-输出一个行动的分布(高斯分布的均值),从行为分布中抽取一个特定的坐标,作为输入并得到下一个glimpse
-采用轨迹进行计算,得到策略梯度的估算,做反向传播

-
AlphaGo

-
总结
Q-learning:对很多维度要计算确切的状态行动组的值,但比决策梯度有更高的采样效率。面临的挑战:需要充分的探索
