PyTorch-YOLOv3(eriklindernoren)训练教程
笔记教程,方便自己回忆,纯小白,目前啥也不懂,只知道步骤
系统:Ubuntu 18.04
1、准备工作
1.1、克隆项目
- 为了防止文件夹混乱,自己在主目录下
cd ~创建一个文件夹mkdir YOLOv3,专门用于存放关于YOLOv3的一些工作。 - 进入YOLOv3
cd YOLOv3 - 克隆
git clone https://github.com/eriklindernoren/PyTorch-YOLOv3

1.2、安装模块
- 创建虚拟环境
conda create -n yolov3-pytorch python=3.6,之前安装的虚拟环境python版本为3.8,这个版本的python安装的tensorflow版本为2.0+,高版本的tensorflow对此版本到yolov3有许多不适配的地方,所以最好安装3.6版本到python. - 激活虚拟环境并进入
conda activate yolov3-pytorch - 通过项目下面的 requirements.txt 安装项目需要的模块
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt,如果设置过了pip源,就直接使用pip3 install -r requirements.txt -i,否则下载速度会很慢。
pip国内的一些镜像:
- 阿里云 http://mirrors.aliyun.com/pypi/simple/
- 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
- 豆瓣(douban) http://pypi.douban.com/simple/
- 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
- 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/


1.3、下载预训练权重
- 进入项目目录下,进入权重文件夹
cd weights/ - 下载
bash download_weights.sh。下载慢的话,可以直接将下面的链接通过迅雷下载或者IDM下载下来。

1.4、下载coco数据集
cd ..cd data/bash get_coco_dataset.sh
2、测试
- 进入test.py同级目录下
- 在COCO测试中评估模型
python3 test.py --weights_path weights/yolov3.weights
3、预测
- 进入detect.py同级目录下
- 使用预训练的权重对图像进行预测
python3 detect.py --image_folder data/samples/ - 输出结果可以在output看到
4、训练
train.py [-h] [--epochs EPOCHS] [--batch_size BATCH_SIZE]
[--gradient_accumulations GRADIENT_ACCUMULATIONS]
[--model_def MODEL_DEF] [--data_config DATA_CONFIG]
[--pretrained_weights PRETRAINED_WEIGHTS] [--n_cpu N_CPU]
[--img_size IMG_SIZE]
[--checkpoint_interval CHECKPOINT_INTERVAL]
[--evaluation_interval EVALUATION_INTERVAL]
[--compute_map COMPUTE_MAP]
[--multiscale_training MULTISCALE_TRAINING]
- 要使用在ImageNet上预训练的Darknet-53在COCO上进行训练,请运行(根据自己需求更改):
python3 train.py --data_config config/coco.data --pretrained_weights weights/darknet53.conv.74
4.1、遇到的问题
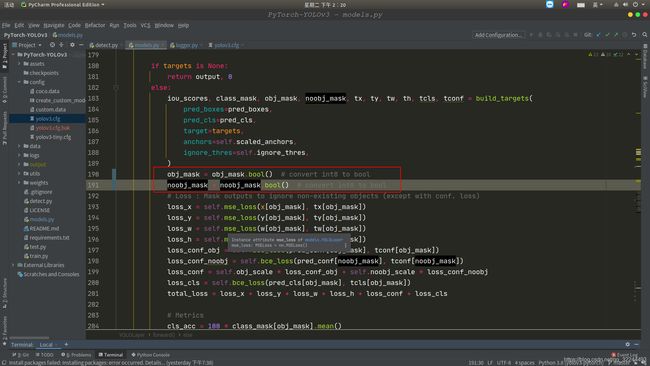
UserWarning: indexing with dtype torch.uint8 is now deprecated, please use a dtype torch.bool instead.
- 找到model.py
- 添加如下标记的两行代码
obj_mask = obj_mask.bool() # convert int8 to bool
noobj_mask = noobj_mask.bool() # convert int8 to bool
RuntimeError: CUDA out of memory. Tried to allocate 32.00 MiB (GPU 0; 7.79 GiB total capacity; 6.61 GiB already allocated; 29.38 MiB free; 94.51 MiB cached)
- 显存溢出,可更据电脑配置调整batch_size大小,默认为8,如下
parser.add_argument("--epochs", type=int, default=100, help="number of epochs")
parser.add_argument("--batch_size", type=int, default=8, help="size of each image batch")
parser.add_argument("--gradient_accumulations", type=int, default=2, help="number of gradient accums before step")
parser.add_argument("--model_def", type=str, default="config/yolov3.cfg", help="path to model definition file")
parser.add_argument("--data_config", type=str, default="config/coco.data", help="path to data config file")
parser.add_argument("--pretrained_weights", type=str, help="if specified starts from checkpoint model")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
parser.add_argument("--checkpoint_interval", type=int, default=1, help="interval between saving model weights")
parser.add_argument("--evaluation_interval", type=int, default=1, help="interval evaluations on validation set")
parser.add_argument("--compute_map", default=False, help="if True computes mAP every tenth batch")
parser.add_argument("--multiscale_training", default=True, help="allow for multi-scale training")
- batch_size改成4,epoch设置成10,运行命令:
python3 train.py --data_config config/coco.data --pretrained_weights weights/darknet53.conv.74 --batch_size 4 --epoch 10
5、训练自己的数据集
5.1、准备工作
5.1.1、修改配置文件和下载预训练权重
$ cd config/ # Navigate to config dir
# Will create custom model 'yolov3-custom.cfg'
$ bash create_custom_model.sh <num-classes> # 类别数目参数,根据你的需要修改
# 下载预训练权重
$ cd weights/
$ bash download_weights.sh

5.1.2、修改 config/custom.data 文件
classes= 5 # 类别数,根据你的需要修改
train=data/custom/train.txt
valid=data/custom/valid.txt
names=data/custom/classes.names
5.1.3、修改 data/custom/classes.names 文件
这里需要分两种情况:
-
有完整的数据,也就是有原始的图片和 txt 文件的,请执行下面的操作:
因为你已经有了 txt 格式的标注数据了,大致的内容如下,第一个数字就是类别对应的代码了,比如 cat 对应 0,dog 对应 1,pig 对应 2
0 0.014656616415410386 0.41642011834319526 0.024288107202680067 0.051775147928994084 1 0.22989949748743718 0.33357988165680474 0.01423785594639866 0.034023668639053255 2 0.28936348408710216 0.30029585798816566 0.01256281407035176 0.03254437869822485那么 data/custom/classes.names 文件必须写成以下形式,必须要对应,否则会出错的
cat dog pig -
没有完整的数据的,即,只有原始图片和 xml 文件的,请执行下面的操作
每个类别一行,顺序要和 data/custom/3_trans.py 中的 classes 变量的顺序一样
classes = ["cf", "os", "rd", "so", "tc"] # 根据自己的需要修改
5.1.4、数据集处理
- 源码去参考3中的 data/custom/ 目录下
- 数据标注工具 https://github.com/tzutalin/labelImg
- 请注意图片的格式,本项目默认是 jpg 格式,这个关系到其他脚本的处理
- 删除 data/custom/images/和data/custom/labels/ 下的文件
- 将自己的图片放到 /data/custom/images/ 下
-
如果需要根据自己的数据生成合适的 Anchor 可以参考 kmeans-anchor-boxes 文件夹下的说明
根据自己的数据生成 anchor。标准的欧几里德距离导致较大的框比较小的框产生更多的误差,故使用:Jaccard index ,公式如下:
J ( b 1 , b 2 ) = min ( w 1 , w 2 ) ⋅ min ( h 1 , h 2 ) w 1 h 1 + w 2 h 2 − min ( w 1 , w 2 ) ⋅ min ( h 1 , h 2 ) J(\mathbf{b_1}, \mathbf{b_2}) = \frac{\text{min}(w_1, w_2)\cdot\text{min}(h_1, h_2)}{w_1h_1 + w_2h_2 - \text{min}(w_1, w_2)\cdot\text{min}(h_1, h_2)} J(b1,b2)=w1h1+w2h2−min(w1,w2)⋅min(h1,h2)min(w1,w2)⋅min(h1,h2)
代码参考:gen_anchor.py 文件,更换自己的 xml 所在的路径即可,会生成 9 个 anchor,结果类似如下:Boxes: [[18.2962963 18.2962963 ] [14.30687831 7.84126984] [12.51851852 11.55555556] [29.85185185 21.87301587] [12.65608466 23.11111111] [ 8.39153439 14.16931217] [21.11640212 29.02645503] [50.77613574 54.61375661] [26.68783069 13.41269841]] Accuracy: 76.61% # 排序之前的比例,也就是上面九个比例的顺序比例 Before Sort Ratios: [1.0, 1.82, 1.08, 1.36, 0.55, 0.59, 0.73, 0.93, 1.99] # 对上面九个框的比例从小到大进行排序 After Sort Ratios: [0.55, 0.59, 0.73, 0.93, 1.0, 1.08, 1.36, 1.82, 1.99] # 最后根据这个结果,从小到大去找对应的 Boxes,修改 config/*.cfg(你生成的配置文件是哪个就修改哪个) 文件的 [yolo] 网络下的 anchors 参数,总共有 3 个地方这是我的替换过程:
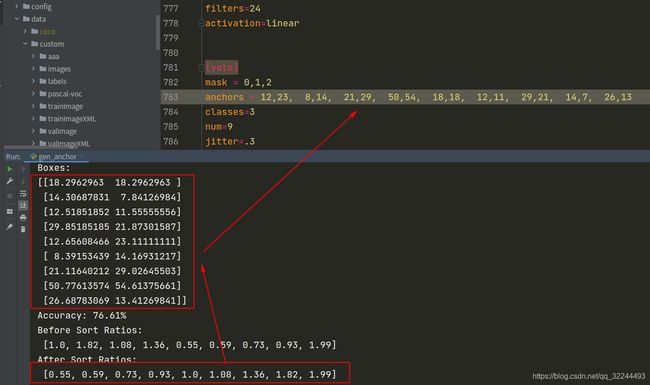
-
运行 0_split_train_val.py
这一步是可选的,如果你的数据已经分好训练集和验证集,那么可以跳过这一步。如果要运行的话,也需要做适当修改,比如每类拆分的比例等。然后 /data/custom/ 下的trains.txt和valid.txt清空,避免数据重复。

-
运行 1_init.py
-
会初始化几个目录,将对应的文件放进对应的文件夹中,需要检查一下 xml 文件和图片文件名称是否一一对应
-
images:用来存放最终训练的所有图片(包括训练图片和验证图片)
-
labels:用来存放最终边框标注的 txt 文件(包括训练集和验证集)
trainImage:训练集的图片 - Abyssinian_1.jpg - Abyssinian_10.jpg - Abyssinian_11.jpg ... valImage:验证集的图片 - Abyssinian_12.jpg - Abyssinian_13.jpg - Abyssinian_14.jpg ... trainImageXML:训练集的 XML 文件 - Abyssinian_1.xml - Abyssinian_10.xml - Abyssinian_11.xml ... valImageXML:验证集的 XML 文件 - Abyssinian_12.xml - Abyssinian_13.xml - Abyssinian_14.xml ...
- 运行 2_createID.py
-
会创建 trainImageId.txt和valImageId.txt 文件,内容是图片的名称。每行一个。生成这两个文件是供 3_trans.py 调用使用的,例:
trainImageId.txt 文件内容如下 Abyssinian_1.jpg Abyssinian_10.jpg Abyssinian_11.jpg ...
- 修改 3_trans.py 中的 classes = [] 顺序要和 data/custom/classes.names 文件一样


-
运行 3_trans.py ,会在 labels 文件夹中生成 txt 文件
-
同时会生成 train.txt 和 val.txt 两个文件,在 config/custom.data 会使用到
-
这个标签务必填准确,我上面图片中填写的首字母是大写的,但是xml中是小写的,如果填写的不准确,生成的label文件夹中的txt就是空的
-
https://blog.csdn.net/xiao_lxl/article/details/85342707 VOC 数据格式含义(生成的 txt 数据格式的含义)
-
生成的 txt 内容如下(举例一条):
label <1> <2> <3> <4> -
可以用以下公式简单验证一下生成的 txt 和与原始的 xml 文件是否转换正确:其中 label 是类别在 data/custom/classes.names 的索引, <> 代表缩放后的比例系数
<1>*w = (xmax-xmin)/2 + xmin <2>*h = (ymax-ymin)/2 + ymin <3> = (xmax-xmin)/w <4> = (ymax-ymin)/h
- 将 trainImage 和 valImage 文件夹中的『图片』全部拷贝至 images 文件夹下
5.2、训练
- 训练命令
python train.py --model_def config/yolov3-custom.cfg --data_config config/custom.data --pretrained_weights weights/darknet53.conv.74
- 从中断的地方开始训练
python train.py --model_def config/yolov3-custom.cfg --data_config config/custom.data --pretrained_weights checkpoints/yolov3_ckpt_299.pth --epoch
5.3、测试
- 测试命令:
python detect.py --image_folder data/samples/ --weights_path checkpoints/yolov3_ckpt_25.pth --model_def config/yolov3-custom.cfg --class_path data/custom/classes.names
- 若是在 GPU 的电脑上训练,在 CPU 的电脑上预测,则需要修改model.load_state_dict(torch.load(opt.weights_path, map_location=‘cpu’))
- 注意预测的时候需要检查数据的格式问题(单通道?三通道?)。预测的值分别是 x1, y1, x2, y2, conf, cls_conf, cls_pred。cfg 中的 路由层(Route) 它的参数 layers 有一个或两个值。当只有一个值时,它输出这一层通过该值索引的特征图。 在我们的实验中设置为了 - 4,所以层级将输出路由层之前第四个层的特征图。 当层级有两个值时,它将返回由这两个值索引的拼接特征图。在我们的实验中为 - 1 和 61, 因此该层级将输出从前一层级(-1)到第 61 层的特征图,并将它们按深度拼接。
参考
- 完美解决 UserWarning: indexing with dtype torch.uint8 is now deprecated, please use a dtype torch.bool
- 目标检测——Yolov3(复现方法说明)
- https://github.com/FLyingLSJ/PyTorch-YOLOv3-master