深度操作系统 机器学习
情感聊天机器人(emotional chatbot)
From part 1, we have built the BERT sentiment predictor, we now start combining it and building the emotional dialogue system. Before jumping into the details, let us talk about some pre-requisites first. (But still, I cannot explain all the terms here…)
从第1部分开始,我们构建了BERT情绪预测器,现在开始将其组合并构建情感对话系统。 在进入细节之前,让我们先谈一些先决条件。 (但是,我无法在这里解释所有术语…)
深度学习的先决条件 (Prerequisites in deep learning)
Seq2Seq model
Seq2Seq模型
Seq2Seq modelSeq2Seq model is an advanced neural network which aims to turn one sequence into another sequence. Seq2seq consists of two neural networks: The EncoderRNN (more often as LSTM or GRU to avoid the vanishing gradient problem) encodes the source sentences, to provide the hidden state for the decoder RNN. On the other hand, the DecoderRNN generates the target sentences.
Seq2Seq模型Seq2Seq模型是一种高级神经网络,旨在将一个序列转换为另一序列。 Seq2seq由两个神经网络组成:EncoderRNN(通常为LSTM或GRU,以避免逐渐消失的梯度问题)对源语句进行编码,以为解码器RNN提供隐藏状态。 另一方面,DecoderRNN生成目标语句。
Attention is all you needAlthough the Seq2Seq model has brought a huge breakthrough in NLP, a vanilla Seq2Seq model still suffers the bottleneck and vanishing gradient problem. Attention model, a famous technique on top of Seq2Seq, allows the decoder to focus on certain parts of the source directly, which relieves the vanishing gradient problem by providing a shortcut to faraway states.
注意就是您所需要的尽管Seq2Seq模型在NLP中带来了巨大的突破,但香草Seq2Seq模型仍然存在瓶颈和消失的梯度问题。 注意力模型是Seq2Seq之上的一项著名技术,它使解码器可以直接将注意力集中在源的某些部分,从而通过提供到遥远状态的捷径来缓解消失的梯度问题。
For more details, you can refer to
有关更多详细信息,请参阅
NLP From Scratch: Translation with a Sequence to Sequence Network and Attention.
NLP从零开始:从序列到序列网络的翻译和注意。
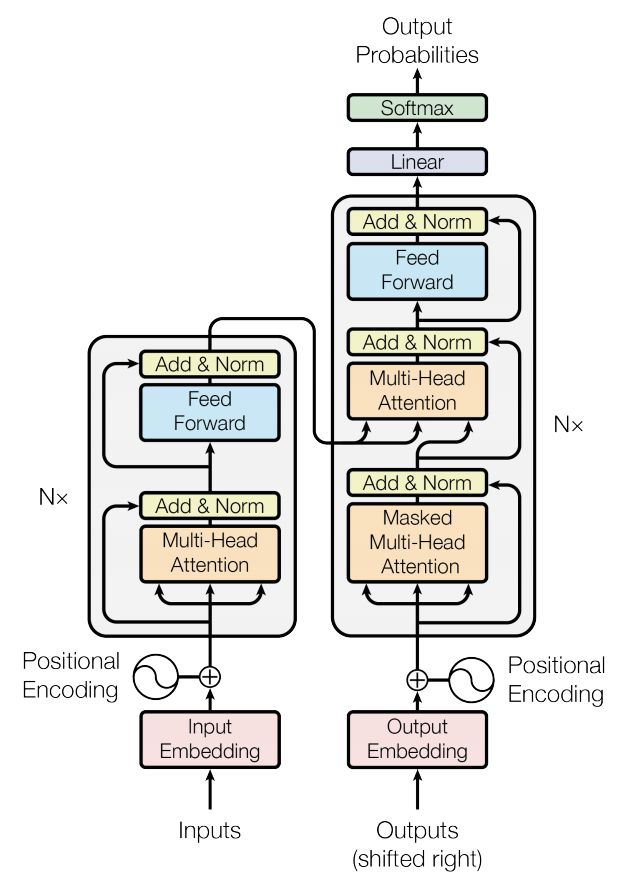
PyTorch & Texar package
PyTorch和Texar软件包
Besides, it is recommended to read:
此外,建议阅读:
Chatbot tutorial in PyTorch and the Texar package, which helps you build complex deep learning model (especially for NLP task) easily. Last but not least, make sure you have a GPU to build the chatbot.
PyTorch和Texar软件包中的Chatbot教程,可帮助您轻松构建复杂的深度学习模型(尤其是用于NLP任务)。 最后但并非最不重要的一点,请确保您具有用于构建聊天机器人的GPU。

EmpatheticDialogues数据集(EmpatheticDialogues Dataset)
The EmpatheticDialogues dataset from ParlAI contains about 33,090 conversations, each conversation contains few sentences and categorized as different emotional situations. For simplicity, the validation dataset is not applied, the train/test was split as 90/10 per cent (skipped the Valid dataset).
来自ParlAI的EmpatheticDialogues数据集包含约33090个对话,每个对话仅包含少量句子,并被分类为不同的情感状况。 为简单起见,未应用验证数据集,将训练/测试划分为90/10%(跳过有效数据集)。
Here is a sample of conservation (convert to pair of source & target sentences):
这是一个保护示例(转换为一对源句子和目标句子):
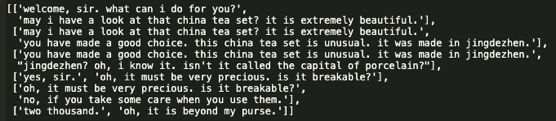
We prepare the data as follow:
我们准备数据如下:
- Drop the sentence with less than 5 words and more than 30 words. 删除少于5个单词且多于30个单词的句子。
- Tokenize the data including the symbols. Many short forms in English are replaced as well. For example, “couldn’t” will be transformed as “could not”. 标记包括符号的数据。 许多英文短格式也被替换。 例如,“不能”将转换为“不能”。
- Construct the vocabulary of all the words. The size of the vocabulary is 24,408, based on training data solely. 构建所有单词的词汇表。 仅根据培训数据,词汇量为24,408。
对话系统设计(编码器和丢失功能) (Dialogue System Design (Encoder and loss function))
Let’s talk about the most interesting part now based on the paper “ HappyBot: Generating Empathetic Dialogue Responses by Improving User Experience Look-ahead” from HKUST.
让我们根据HKUST的论文“ HappyBot:通过改善用户体验预见来生成移情对话响应”来谈谈最有趣的部分。

MLE Loss
MLE损失
Let us discuss the model structure here. The left side is the structure of
让我们在这里讨论模型结构。 左侧是结构
Attention model, a normal dialogue system. The objective is to embed each sentence input (with length T) and then generate the output probability distributions (w_t) from the vocab list. The training objective in response generation is to maximize the likelihood of word y*, and its loss function is written as:
注意模型,一种正常的对话系统。 目的是嵌入每个句子输入(长度为T),然后从词汇表中生成输出概率分布(w_t)。 响应生成中的训练目标是使单词y *的可能性最大化,其损失函数写为:

Linear Regression Loss
线性回归损失
Before we combine the reinforcement learning (RL) part of the sentiment, we introduce another linear regression as a baseline reward model estimating the sentiment score R of each sentence as follow:
在结合情感的强化学习(RL)部分之前,我们引入另一个线性回归作为基线奖励模型,估计每个句子的情感分数R如下:
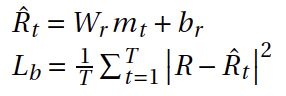
where m_t is the hidden state of the encoder at step t, R is the sentiment score (reward) of that sentence, W_r and b_r are trainable parameters. The objective of this linear regression is to reduce the variance of the reward R.
其中m_t是在步骤t处编码器的隐藏状态,R是该句子的情感分数(奖励),W_r和b_r是可训练的参数。 该线性回归的目的是减少奖励R的方差。
Reinforcement learning lossFor each sentence during training, we decode our predicted sentence by greedy decoding (adopt it for time effectiveness, we will introduce decoding in the next section). Afterwards, the BERT model will predict its sentiment score R of that sentence. The RL loss is calculated as:
强化学习损失对于训练期间的每个句子,我们通过贪婪解码来解码我们的预测句子(出于时间有效性而采用它,我们将在下一部分中介绍解码)。 之后,BERT模型将预测该句子的情感分数R。 RL损失计算如下:
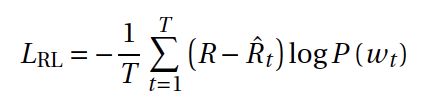
where w_t is the predicted probability distribution of the word at step t.
其中w_t是单词在步骤t的预测概率分布。
The meaning of RL: the output of the linear regression (Rˆt) serves as a mean of R. When it comes to a great sentiment score (i.e. R > Rˆt ), minimizing L_RL is to maximize w_t, that is to say, we want to increase the chance of getting a great reward. On the other hand, when R
RL的含义:线性回归(Rˆt)的输出用作R的平均值。当涉及到较高的情感评分(即R> Rˆt)时,最小化L_RL就是最大化w_t,也就是说,我们想要增加获得丰厚奖励的机会。 另一方面,当R <Rtt时,必须使wt最小化以减少损失。 这是强化学习的原则:您希望有更高的机会获得良好的回报。 (就像心理学中的操作者调节)
Finally, these 3loss functions are combined as follow:
最后,将这3loss函数组合如下:
where the lambda (the weight) of MLE, RL and B are three hyper-parameters to decide the weighting.
其中MLE,RL和B的Lambda(权重)是三个用于确定权重的超参数。
对话系统设计(解码策略) (Dialogue System Design (Decoding Strategy))
After training the model with the loss function. To generate the predicted sentences from the probability distribution of w_t, we need the decoding part. We will apply and compare two decoding strategies here:
用损失函数训练模型后。 为了从w_t的概率分布生成预测语句,我们需要解码部分。 我们将在此处应用并比较两种解码策略:
Greedy decodingIt takes the most probable word (by argmax) on each step without backtracking.
贪婪解码它在每个步骤中都采用最可能的单词(通过argmax)而不回溯。
-
--
Advantages: Fast
优点:快速
Advantages: Fast- Disadvantages: Cannot trace back the generating process, may cause some strange responses. (Generating: I love…., oh actually the word “love” is not what I want!)
优点:快速-缺点:无法追溯生成过程,可能会引起一些奇怪的响应。 (生成:我爱....,哦,“爱”这个词实际上不是我想要的!)
Top-K sampling decoding
Top-K采样解码
randomly samples from w_t restricted to only the top-k most probable words. With top-k sampling, especially with larger k, the response will be more generic and diverse. (Noted that if you want to write poetry or novel, you need top-k sampling instead of greedy decoding)
来自w_t的随机采样仅限于前k个最可能的单词。 对于前k个采样,尤其是对k更大的采样,响应将更加通用和多样化。 (请注意,如果您想写诗或小说,则需要top-k采样而不是贪婪的解码)
For more information about decoding strategies, one can read the following article “Decoding Strategies that You Need to Know for Response Generation”.
有关解码策略的更多信息,请阅读以下文章“生成响应所需要了解的解码策略”。
If you adopt the decoding from the Texar package, you can easily implement different decoding strategies by the “helper” instance.
如果您采用Texar软件包中的解码,则可以通过“ helper”实例轻松实现不同的解码策略。
模型训练 (Model Training)
There are several strategies adopted during training:
培训期间采用了几种策略:
Start the training of reinforcement learning part laterIn the first epoch, the generated sentences are not sophisticated enough for sentiment scoring. So we start the RL part at the 19th epoch. In other words, the chatbot learn normally at the beginning and consider the positive emotional later.
稍后开始强化学习训练在第一个时期,生成的句子不够复杂,无法进行情感评分。 因此,我们在第19个时期开始RL部分。 换句话说,聊天机器人从一开始就可以正常学习,然后再考虑积极的情绪。
Extremely small weight for the RL
RL的重量极小
Noted the slope of lossRL is high (since the slope of the log function is high then the input is negative, and so its gradient descends). Extremely small lambda (the weight)of RL and B to balance it with the lambda of MLE.
注意lossRL的斜率很高(因为log函数的斜率很高,因此输入为负,因此其斜率下降)。 RL和B的λ(重量)极小,以使其与MLE的λ平衡。
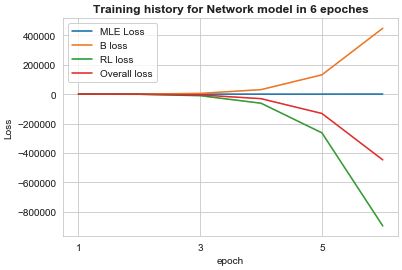
Early Stopping
提前停止
As lossRL is dominating, the model may reduce it at the expense of loss_MLE. Hence, early stopping is adopted in our model. If the loss MLE after adding loss_RL is larger than the mean of lossMLE before adding loss_RL, the model training will end. Our model training ended on the 20th epoch.
由于lossRL占主导地位,该模型可能会以loss_MLE为代价将其降低。 因此,在我们的模型中采用了提前停止。 如果加上loss_RL之后的损失MLE大于加上loss_RL之前的lossMLE的平均值,则模型训练将结束。 我们的模型训练在20世纪结束。
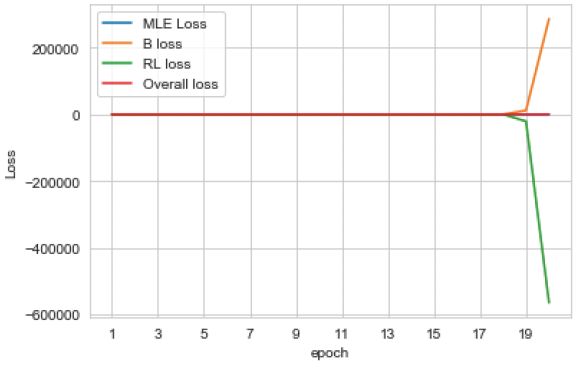
Here is the final training history of the model for 20 epochs:
这是该模型20个时期的最终训练历史:
模型评估 (Model Evaluation)
To evaluate our approach, we will build one more baseline model (without the reinforcement learning part) for comparison. We will use two standard metrics in response generation:
为了评估我们的方法,我们将建立一个基准模型(不包括强化学习部分)进行比较。 我们将在响应生成中使用两个标准指标:
BLEU metric
BLEU指标
BLEU metricThe Bilingual Evaluation Understudy Score (BLEU), evaluates the co-occurrences of n-grams in the ground truth and the system responses. The n-gram precision is calculated as:
BLEU度量标准双语评估学习分数(BLEU)评估基础事实中n-gram的共现和系统响应。 n克精度的计算公式为:
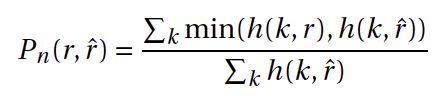
where r is the ground truth response, r^ is the system response, k indexes all possible n-grams of length n and h(k, r) is the number of n-grams in r. BLEU-1 (uni-gram) and BLEU-2 (bi-gram) is chosen for our evaluation.
其中r是地面真相响应,r ^是系统响应,k索引长度为n的所有可能的n-gram,h(k,r)是r中n-gram的数量。 我们选择了BLEU-1(单克)和BLEU-2(双克)进行评估。
Distinct metricDistinct metric measures the diversity of the generated sentences, which is defined as the number of distinct n-grams divided by the total amount of generated words. Distinct-1 (uni-gram) is chosen for our evaluation.
区别指标差异度量度量生成的句子的多样性,定义为不同的n-gram数除以生成的单词总数。 选择Distinct-1(unigram)进行评估。
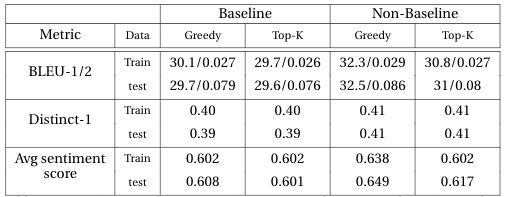
Evaluation based on the metricWe have trained two sets of the model, the baseline (with our reinforcement learning part)and non-baseline model. For decoding strategy, we also testify the greedy and top-k (k=5) to verify the impact of decoding strategy.
基于指标的评估我们已经训练了两组模型,即基线(带有强化学习部分)和非基线模型。 对于解码策略,我们还证明了贪婪和top-k(k = 5),以验证解码策略的影响。
In the below table, it is found that our not baseline model outperforms the baseline one with having the highest sentiment score, BLEU-1/2 and Distinct score (slightly better than the baseline model) in both train and test datasets.
在下表中,我们发现在训练和测试数据集中,我们的非基线模型的表现优于基线模型,其情感评分最高,BLEU-1 / 2和Distinct得分(略好于基线模型)。
Generated examples
产生的例子

结论(Conclusion)
Comparing to the baseline model, our approach has successfully generated more positive responses with maintaining high linguistic performance.
与基线模型相比,我们的方法在保持高语言性能的同时成功地产生了更多积极的React。
Surprisingly, it is found that greedy not only performs similarly as the top-k sampling (k=5) but also outputs more positive responses since top-k sampling favour the generic responses.
出人意料的是,发现贪婪不仅表现得与前k个采样类似(k = 5),而且由于前k采样有利于一般响应,因此还输出更多的正响应。
翻译自: https://towardsdatascience.com/deep-learning-how-to-build-an-emotional-chatbot-part-2-the-dialogue-system-4932afe6545c
深度操作系统 机器学习