李宏毅机器学习作业3——Image Classification
目录
任务和数据集
任务
数据集
Baseline
导包
数据处理
Transforms
Datasets
数据加载函数
分类模型
训练
训练函数
加载数据
训练
预测
输出
解答
数据增广
使用原代码模型
Ensemble+TTA
模型集成Ensemble
Test Time Augmentation
Ensemble+TTA
Cross Validation
训练
讨论
不使用数据增广
单模型的训练技巧——CosineAnnealingWarmRestarts
ResNet过拟合
dropout
迁移学习
TTA
Ensamble
交叉验证
num_works
np.array_split
任务和数据集
任务
Objective - Image Classification
1. Solve image classification with convolutional neural networks.
2. Improve the performance with data augmentations.
3. Understand popular image model techniques such as residual
数据集
● The images are collected from the food-11 dataset classified into 11 classes.
● Training set: 9866 labeled images
● Validation set: 3430 labeled images
● Testing set: 3347 image
下载地址:ML2022Spring-HW3 | Kaggle
Baseline
Simple : 0.50099
Medium : 0.73207 Training Augmentation + Train Longer
Strong : 0.81872 Training Augmentation + Model Design + Train Looonger (+
Cross Validation + Ensemble)
Boss : 0.88446 Training Augmentation + Model Design +Test Time
Augmentation + Train Looonger (+ Cross Validation + Ensemble)
导包
import numpy as np
import pandas as pd
import torch
import os
import torch.nn as nn
import torchvision.transforms as transforms
from PIL import Image
# "ConcatDataset" and "Subset" are possibly useful when doing semi-supervised learning.
from torch.utils.data import ConcatDataset, DataLoader, Subset, Dataset
from torchvision.datasets import DatasetFolder, VisionDataset
# This is for the progress bar.
from tqdm.auto import tqdm
from d2l import torch as d2l
import random
def same_seeds(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True数据处理
Transforms
# Normally, We don't need augmentations in testing and validation.
# All we need here is to resize the PIL image and transform it into Tensor.
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
# However, it is also possible to use augmentation in the testing phase.
# You may use train_tfm to produce a variety of images and then test using ensemble methods
train_tfm = transforms.Compose([
# Resize the image into a fixed shape (height = width = 128)
transforms.Resize((128, 128)),
# You may add some transforms here.
# ToTensor() should be the last one of the transforms.
transforms.ToTensor(),
])
Datasets
class FoodDataset(Dataset):
def __init__(self,path=None,tfm=test_tfm,files=None):
super(FoodDataset).__init__()
self.path = path
if path:
self.files = sorted([os.path.join(path, x) for x in os.listdir(path) if x.endswith(".jpg")])
else:
self.files = files
self.transform = tfm
def __len__(self):
return len(self.files)
def __getitem__(self,idx):
fname = self.files[idx]
im = Image.open(fname)
im = self.transform(im)
#im = self.data[idx]
try:
label = int(fname.split("/")[-1].split("_")[0]) # windows写成\\
except:
label = -1 # test has no label
return im,label数据加载函数
def loadData(dataset_dir, batch_size, num_workers, train_tfm, test_tfm):
# Construct datasets.
# The argument "loader" tells how torchvision reads the data.
train_set = FoodDataset(os.path.join(dataset_dir,"training"), tfm=train_tfm)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=num_workers, pin_memory=True, drop_last = True)
valid_set = FoodDataset(os.path.join(dataset_dir,"validation"), tfm=test_tfm)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=num_workers, pin_memory=True, drop_last = True)
print('训练集总长度是 {:d}, batch数量是 {:.2f}'.format(len(train_set), len(train_set)/ batch_size))
print('验证集总长度是 {:d}, batch数量是 {:.2f}'.format(len(valid_set), len(valid_set)/ batch_size))
return train_loader, valid_loader分类模型
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 維度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512*4*4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)训练
训练函数
def trainer(train_loader, val_loader, model, config, devices):
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=config['learning_rate'], weight_decay=config['weight_decay'])
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,
T_0=config['T_0'], T_mult=config['T_mult'],
eta_min=config['learning_rate']/config['eta_min_ratio'])
n_epochs, patience = config['num_epoch'], config['patience']
num_batches = len(train_loader)
show_batches = num_batches // config['show_num']
if not os.path.isdir('./' + config['model_path'].split('/')[1]):
os.mkdir('./' + config['model_path'].split('/')[1]) # Create directory of saving models.
legend = ['train loss', 'train acc']
if val_loader is not None:
legend.append('valid loss')
legend.append('valid acc')
animator = d2l.Animator(xlabel='epoch', xlim=[0, n_epochs], legend=legend)
for epoch in range(n_epochs):
train_acc, train_loss = 0.0, 0.0
# training
model.train() # set the model to training mode
for i, (data, labels) in enumerate(train_loader):
data, labels = data.to(devices[0]), labels.to(devices[0])
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, train_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
train_acc += (train_pred.detach() == labels.detach()).sum().item()
train_loss += loss.item()
if (i + 1) % show_batches == 0:
train_acc = train_acc / show_batches / len(data)
train_loss = train_loss / show_batches
print('train_acc {:.3f}, train_loss {:.3f}'.format(train_acc, train_loss))
animator.add(epoch + (i + 1) / num_batches, (train_loss, train_acc, None, None))
train_acc, train_loss = 0.0, 0.0
scheduler.step()
# validation
if val_loader != None:
model.eval() # set the model to evaluation mode
val_acc, val_loss = 0.0, 0.0
with torch.no_grad():
for i, (data, labels) in enumerate(val_loader):
data, labels = data.to(devices[0]), labels.to(devices[0])
outputs = model(data)
loss = criterion(outputs, labels)
_, val_pred = torch.max(outputs, 1)
val_acc += (val_pred.cpu() == labels.cpu()).sum().item() # get the index of the class with the highest probability
val_loss += loss.item()
val_acc = val_acc / len(val_loader) / len(data)
val_loss = val_loss / len(val_loader)
print('val_acc {:.3f}, val_loss {:.3f} '.format(val_acc, val_loss))
animator.add(epoch + 1, (None, None, val_loss, val_acc))
# if the model improves, save a checkpoint at this epoch
if val_acc > config['best_acc']:
config['best_acc'] = val_acc
torch.save(model.state_dict(), config['model_path'])
# print('saving model with acc {:.3f}'.format(best_acc / len(val_loader) / len(labels)))
stale = 0
else:
stale += 1
if stale > patience:
print(f"No improvment {patience} consecutive epochs, early stopping")
break
# if not validating, save the last epoch
if val_loader == None:
torch.save(model.state_dict(), config['model_path'])
# print('saving model at last epoch') 加载数据
batch_size = 256
num_workers= 4
dataset_dir = "data/food11"
train_loader, val_loader = loadData(dataset_dir, batch_size, num_workers, train_tfm, test_tfm)
训练
devices = d2l.try_all_gpus()
print(f'DEVICE: {devices}')
# fix random seed
seed = 0 # random seed
same_seeds(seed)
config = {
# training prarameters
'num_epoch': 30, # the number of training epoch
'learning_rate': 1e-4, # learning rate
'weight_decay': 1e-4,
'best_acc': 0.0,
'T_0': 2,
'T_mult': 2,
'eta_min_ratio':20,
'patience': 300,
'show_num': 1 # 每个epoch打印几次loss
}
config['model_path'] = './models/foldmodel' + str(config['learning_rate']) # the path where the checkpoint will be saved
model = Classifier().to(devices[0])
trainer(train_loader, val_loader, model, config, devices)预测
# 单个model
def pred(test_loader, model, devices):
test_acc = 0.0
test_lengths = 0
pred = []
model.eval()
with torch.no_grad():
for batch in tqdm(test_loader):
features = batch[0].to(devices[0])
outputs = model(features)
_, test_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
pred.append(test_pred.cpu())
pred = torch.cat(pred, dim=0).numpy()
return pred
batch_size = 512
test_set = FoodDataset(os.path.join(dataset_dir,"test"), tfm=test_tfm)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, pin_memory=True, num_workers=2)
model_best = Classifier().to(devices[0])
model_best.load_state_dict(torch.load('models/model0.0005Fold_0_best'))
prediction = pred(test_loader, model_best, devices)输出
#create test csv
def pad4(i):
return "0"*(4-len(str(i)))+str(i)
df = pd.DataFrame()
df["Id"] = [pad4(i) for i in range(1,len(test_set)+1)]
df["Category"] = prediction
df.to_csv("submission best0.csv",index = False)解答
数据增广

# Normally, We don't need augmentations in testing and validation.
# All we need here is to resize the PIL image and transform it into Tensor.
test_tfm = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
])
# However, it is also possible to use augmentation in the testing phase.
# You may use train_tfm to produce a variety of images and then test using ensemble methods
train_tfm = transforms.Compose([
# Resize the image into a fixed shape (height = width = 128)
transforms.RandomResizedCrop((128, 128), scale=(0.5, 1), ratio=(0.5, 2)),
# You may add some transforms here.
transforms.RandomHorizontalFlip(0.5),
transforms.RandomVerticalFlip(0.5),
transforms.RandomGrayscale(0.2),
transforms.RandomRotation(30),
transforms.RandomAffine(30),
transforms.RandomSolarize(threshold=192.0, p=0.2),
transforms.ColorJitter(brightness=0.4,contrast=0.4, saturation=0.4),
# ToTensor() should be the last one of the transforms.
transforms.ToTensor(),
])使用原代码模型
直接使用原代码给出的分类模型,再加上数据增广,仔细训练,别的什么技巧都不使用,得分为0.83764,轻松超过了strong line
batch_size = 256
num_workers= 4
dataset_dir = "data/food11"
train_loader, val_loader = loadData(dataset_dir, batch_size, num_workers, train_tfm, test_tfm)
devices = d2l.try_all_gpus()
print(f'DEVICE: {devices}')
# fix random seed
seed = 0 # random seed
same_seeds(seed)
config = {
# training prarameters
'num_epoch': 30, # the number of training epoch
'learning_rate': 1e-4, # learning rate
'weight_decay': 1e-4,
'best_acc': 0.0,
'T_0': 2,
'T_mult': 2,
'eta_min_ratio':20,
'patience': 300,
'show_num': 1 # 每个epoch打印几次loss
}
config['model_path'] = './models/foldmodel' + str(config['learning_rate']) # the path where the checkpoint will be saved
model = Classifier().to(devices[0])
trainer(train_loader, val_loader, model, config, devices)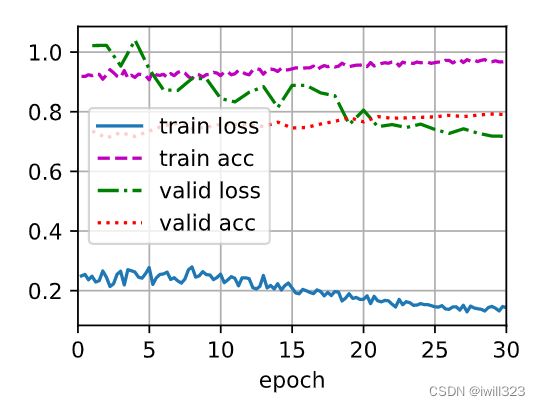

Ensemble+TTA
模型集成Ensemble
对于每一个样本batch,计算各个模型的预测矩阵并求和,得到一个预测矩阵,对于每一个样本,选择得分最高的类别作为预测类别。将各个batch的预测结果保存在同一个列表中,这就是最终结果
集成的几种方式:
● Average of logits or probability : Need to save verbose output, less ambiguous
● Voting : Easier to implement, need to break ties
● Coding : basic math operations with numpy or torch
# 模型集成
prediction = []
with torch.no_grad():
for data in test_loader:
test_preds = []
for model_best in models:
model_pred = model_best(data[0].to(devices[0])).cpu().numpy()
test_preds.append(model_pred)
test_preds = sum(test_preds)
test_label = np.argmax(test_preds, axis=1)
prediction += test_label.squeeze().tolist()Test Time Augmentation
建立1个使用test_tfm的测试集和5个使用train_tfm的测试集,得到列表preds,含有6个元素,第一个是对测试集使用test_tfm得到的预测矩阵,后面的都是对测试集使用train_tfm得到的预测矩阵,每个矩阵的形状是(3347,11),3347是样本数,11是类别数。


# TTA
batch_size = 512
test_set = FoodDataset(os.path.join(dataset_dir,"test"), tfm=test_tfm)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, pin_memory=True, num_workers=2)
test_loaders = []
for i in range(5):
test_set_i = FoodDataset(os.path.join(dataset_dir,"test"), tfm=train_tfm)
test_loader_i = DataLoader(test_set_i, batch_size=batch_size, shuffle=False, num_workers=2, pin_memory=True)
test_loaders.append(test_loader_i)
model_best = Classifier().to(devices[0])
model_best.load_state_dict(torch.load('models23/model0.0005Fold_0_best'))
model_best.eval()
preds = [[], [], [], [], [], []]
with torch.no_grad():
for data, _ in test_loader:
batch_preds = model_best(data.to(devices[0])).cpu().data.numpy()
preds[0].extend(batch_preds)
for i, loader in enumerate(test_loaders):
for data, _ in loader:
batch_preds = model_best(data.to(devices[0])).cpu().data.numpy()
preds[i+1].extend(batch_preds)对6个测试集的预测结果进行加权平均,得到一个(3347,11)矩阵。结果最好不要覆盖preds,而是保存为一个新的变量,这样方便尝试不同的权重系数,得到更好的结果
preds_np = np.array(preds, dtype=object)
print(preds_np.shape)
bb = 0.6* preds_np[0] + 0.1 * preds_np[1] + 0.1 * preds_np[2] + 0.1 * preds_np[3] + 0.1 * preds_np[4] + 0.1 * preds_np[5]
print(bb.shape)
prediction = np.argmax(bb, axis=1)Ensemble+TTA
将这两块内容写到一起
test_loaders = []
batch_size = 256
for i in range(5):
test_set_i = FoodDataset(os.path.join(dataset_dir,"test"), tfm=train_tfm)
test_loader_i = DataLoader(test_set_i, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)
test_loaders.append(test_loader_i)
preds = [[], [], [], [], [], []]
test_set = FoodDataset(os.path.join(dataset_dir,"test"), tfm=test_tfm)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0, pin_memory=True)
with torch.no_grad():
for data, _ in test_loader:
batch_preds = []
for model_best in models:
batch_preds.append(model_best(data.to(devices[0])).cpu().data.numpy())
batch_preds = sum(batch_preds)
preds[0].extend(batch_preds.squeeze().tolist())
for i, loader in enumerate(test_loaders):
for data, _ in loader:
batch_preds = []
for model_best in models:
batch_preds.append(model_best(data.to(devices[0])).cpu().data.numpy())
batch_preds = sum(batch_preds)
preds[i+1].extend(batch_preds.squeeze().tolist())结果很接近boss line了
![]()
Cross Validation


将训练集分成5份,进行5折交叉验证。将训练集和验证集混合,得到总的样本列表total_files,然后用np.array_split函数得到5份数据集,在5个循环中轮番使用训练集和验证集。使用config['model_path']记录保存路径,使用config['best_accs'] 记录每个模型在验证集上的最好表现
def trainer_k_folds(config, dataset_dir, batch_size, train_tfm, test_tfm, devices):
train_dir = os.path.join(dataset_dir,"training")
val_dir = os.path.join(dataset_dir,"validation")
train_files = [os.path.join(train_dir, x) for x in os.listdir(train_dir) if x.endswith('.jpg')]
val_files = [os.path.join(val_dir, x) for x in os.listdir(val_dir) if x.endswith('.jpg')]
total_files = np.array(train_files + val_files)
random.shuffle(total_files)
num_folds = config['num_folds']
train_folds = np.array_split(np.arange(len(total_files)), num_folds)
train_folds = np.array(train_folds, dtype=object) # 防止因为数组维度不整齐而报错
for i in range(num_folds):
print(f'\n\nStarting Fold: {i} ********************************************')
train_data = total_files[np.concatenate(np.delete(train_folds, i)) ]
val_data = total_files[train_folds[i]]
train_set = FoodDataset(tfm=train_tfm, files=train_data)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True, drop_last = True)
valid_set = FoodDataset(tfm=test_tfm, files=val_data)
valid_loader = DataLoader(valid_set, batch_size=batch_size, shuffle=True, num_workers=4, pin_memory=True, drop_last = True)
print('训练集总长度是 {:d}, batch数量是 {:.2f}'.format(len(train_set), len(train_set)/ batch_size))
print('验证集总长度是 {:d}, batch数量是 {:.2f}'.format(len(valid_set), len(valid_set)/ batch_size))
tep = config['model_path']
config['model_path'] += f"Fold_{i}_best"
config['best_acc'] = 0.0
model = Classifier().to(devices[0])
# model.load_state_dict(torch.load('models/foldmodel0.0001')) 提前训练几个epoch,可能加快后面每一个模型的训练
trainer(train_loader, valid_loader, model, config, devices)
config['best_accs'].append(config['best_acc'])
config['model_path'] = tep训练
batch_size = 256
dataset_dir = "data/food11"
devices = d2l.try_all_gpus()
print(f'DEVICE: {devices}')
# fix random seed
seed = 0 # random seed
same_seeds(seed)
config = {
# training prarameters
'num_epoch': 300, # the number of training epoch
'learning_rate': 5e-4, # learning rate
'weight_decay': 1e-4,
'best_acc': 0.0,
'T_0': 16,
'T_mult': 1,
'eta_min_ratio':50,
'patience': 32,
'num_folds':5,
'show_num': 1,
'best_accs': []
}
config['model_path'] = './models22/model' + str(config['learning_rate']) # the path where the checkpoint will be saved
# Initialize a model, and put it on the device specified.
model = Classifier().to(devices[0])
trainer_k_folds(config, dataset_dir, batch_size, train_tfm, test_tfm, devices)交叉验证得到5个模型之后,进行模型集成和TTA,结果如图所示,比boss line还要差一些

讨论
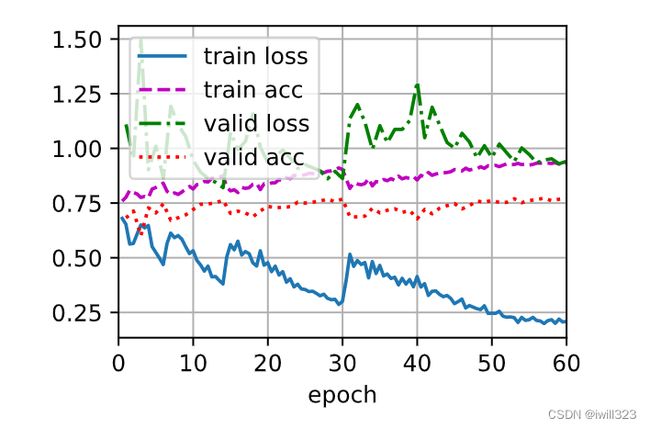
不使用数据增广
尝试了各种学习率,在不使用数据增广的情况下进行训练,结果都和下图差不多.

可以看到,训练误差很快就下降为0,但是验证误差还处于高位,但是由于训练误差为0,所以反向传播的梯度都是0,模型不能继续改进了,这是典型的过拟合。
正则化能够防止模型的过拟合,CS231n把数据增广列为正则化的手段之一(参考2022年Cs231n PPT笔记-训练CNN_iwill323的博客-CSDN博客),一开始我不理解为什么数据增广也属于正则化,做完这个作业现在理解了。在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,事实上扩大了训练集的规模。 随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。
单模型的训练技巧——CosineAnnealingWarmRestarts
使用learning_rate = 1e-4,weight_decay = 5e-3,T_0 = 2,T_mult = 2,对原代码的classifier()进行训练,刚开始的训练曲线如下图。
可以看到明显的波浪形,这是因为CosineAnnealingWarmRestarts按等比数列的间隔调整学习率,即按照T_0 = 2,T_mult = 2的参数设置,每隔2,4,8,16……个epoch循环调整学习率。
浅谈一下我对CosineAnnealingWarmRestarts的理解:
波浪形的学习曲线其实是有一定问题的。前一个周期降下来的loss,到了下一个周期,由于学习率回到高点,于是loss陡然升高,接下来新的周期要花费很多epoch才能降到上一个周期的loss水平,无疑是很降低效率的。那么,为什么要打断loss的下降过程,让loss波动地下降,而不是让loss保持下降趋势呢?
原因在于学习率的下降趋势实际上是没法保持的,如果学习率不及时调整,那么loss的下降最终会进入一个“平坦期”,慢慢地loss下降不动了。训练过程中,不同的阶段采用什么样的学习率是很难知道的, CosineAnnealingWarmRestarts算法通过不断的“搅动”学习率,让loss不断尝试新的学习率周期,说不定更有可能学到好的优化结果。
当然,我们还是希望loss呈直线下降,而不是波浪下降。如果新周期的峰值陡然升的太高了,需要很长时间才能“收回”,那么说明最大学习率可能太大,可以减小最大学习率;如果每一周期末尾loss下降过于平缓,那么说明最小学习率太小了,可以减小eta_min。
继续训练,发现loss曲线波浪形不明显,呈下降趋势,就很理想了。保存checkpoint ,提交预测结果,得分0.80478.

![]()
从上图末尾可以发现,loss还能够继续下降,于是将学习率调到5e-5继续训练。一开始初始学习率回到高点,于是loss上升。最终结果不错,看上去其实还有进步空间

参考:torch.optim.lr_scheduler:调整学习率之CosineAnnealingWarmRestarts()参数说明_qq_37612828的博客-CSDN博客_cosineannealingwarmrestarts
在训练过程中,在不同的点保存了checkpoint,得分如下图
| 模型 | 得分 |
| model2 | 0.81872 |
| model3 | 0.83764 |
| model5 | 0.78685 |
| model6 | 0.76792 |
| model7 | 0.80478 |
| model8 | 0.80577 |
| model5e-05 | 0.83167 |
model3反而是最高的得分。这是因为每次从断点重启,best_accuracy一开始是0,于是第一个epoch之后,模型就被覆盖了,但是CosineAnnealingWarmRestarts方法的波浪性不能保证后面的结果会更好。所以每次从断点重启之前,要修改config的best_accuracy
ResNet过拟合
class Residual_Block(nn.Module):
def __init__(self, ic, oc, stride=1):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(ic, oc, kernel_size=3, padding=1, stride=stride),
nn.BatchNorm2d(oc),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(oc, oc, kernel_size=3, padding=1),
nn.BatchNorm2d(oc)
)
self.relu = nn.ReLU(inplace=True)
if stride != 1 or (ic != oc): # 对于resnet18,可以不需要stride != 1这个条件
self.conv3 = nn.Sequential(
nn.Conv2d(ic, oc, kernel_size=1, stride=stride),
nn.BatchNorm2d(oc)
)
else:
self.conv3 = None
def forward(self, X):
Y = self.conv1(X)
Y = self.conv2(Y)
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
class ResNet(nn.Module):
def __init__(self, block = Residual_Block, num_layers = [2,2,2,2], num_classes=11):
super().__init__()
self.preconv = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.layer0 = self.make_residual(block, 64, 64, num_layers[0])
self.layer1 = self.make_residual(block, 64, 128, num_layers[1], stride=2)
self.layer2 = self.make_residual(block, 128, 256, num_layers[2], stride=2)
self.layer3 = self.make_residual(block, 256, 512, num_layers[3], stride=2)
self.postliner = nn.Sequential(
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(512, num_classes)
)
def make_residual(self, block, ic, oc, num_layer, stride=1):
layers = []
layers.append(block(ic, oc, stride))
for i in range(1, num_layer):
layers.append(block(oc, oc))
return nn.Sequential(*layers)
def forward(self, x):
out = self.preconv(x)
out = self.layer0(out) # [64, 32, 32]
out = self.layer1(out) # [128, 16, 16]
out = self.layer2(out) # [256, 8, 8]
out = self.layer3(out) # [512, 4, 4]
out = self.postliner(out)
return out
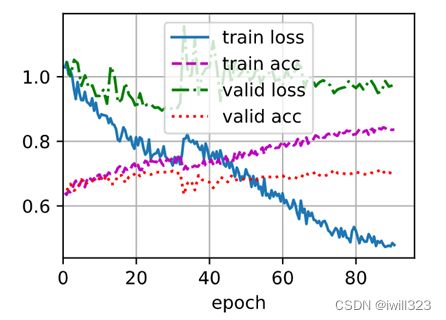
手写了一个RenNet18,具体可以参考李沐的《动手学深度学习》。设learning_rate = 1e-4,可以看到一开始学习比较正常

随着学习的进行,开始不正常了,训练误差持续下降,但是验证误差基本不变,到最后验证误差“躺平了”,有点过拟合的味道。


dropout
李宏毅2022机器学习HW3解析_机器学习手艺人的博客-CSDN博客在残差网络末尾采用了drop out设计。
class Residual_Block(nn.Module):
def __init__(self, ic, oc, stride=1):
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(ic, oc, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(oc),
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(oc, oc, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(oc),
)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if stride != 1 or (ic != oc):
self.downsample = nn.Sequential(
nn.Conv2d(ic, oc, kernel_size=1, stride=stride),
nn.BatchNorm2d(oc),
)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.conv2(out)
if self.downsample:
residual = self.downsample(x)
out += residual
return self.relu(out)
class Classifier(nn.Module):
def __init__(self, block=Residual_Block, num_layers=[2,2,2,2], num_classes=11):
super().__init__()
self.preconv = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
)
self.layer0 = self.make_residual(block, 32, 64, num_layers[0], stride=2)
self.layer1 = self.make_residual(block, 64, 128, num_layers[1], stride=2)
self.layer2 = self.make_residual(block, 128, 256, num_layers[2], stride=2)
self.layer3 = self.make_residual(block, 256, 512, num_layers[3], stride=2)
#self.avgpool = nn.AvgPool2d(2)
self.fc = nn.Sequential(
nn.Dropout(0.4),
nn.Linear(512*4*4, 512),
nn.BatchNorm1d(512),
nn.ReLU(inplace=True),
nn.Dropout(0.2),
nn.Linear(512, num_classes),
)
def make_residual(self, block, ic, oc, num_layer, stride=1):
layers = []
layers.append(block(ic, oc, stride))
for i in range(1, num_layer):
layers.append(block(oc, oc))
return nn.Sequential(*layers)
def forward(self, x):
# [3, 128, 128]
out = self.preconv(x) # [32, 64, 64]
out = self.layer0(out) # [64, 32, 32]
out = self.layer1(out) # [128, 16, 16]
out = self.layer2(out) # [256, 8, 8]
out = self.layer3(out) # [512, 4, 4]
#out = self.avgpool(out) # [512, 2, 2]
out = self.fc(out.view(out.size(0), -1))
return out训练起来并没有明显的改善
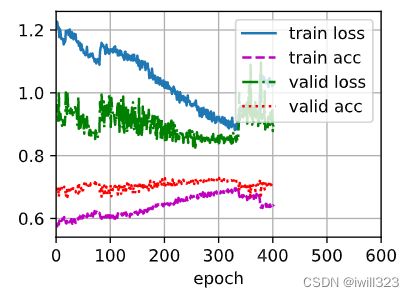
![]()
迁移学习
使用torch自带的resnet18,并且使用预训练的权重,然后在本作业的训练集上整体训练,整个过程轻松又高效,迁移学习的威力体现了,看样子resnet18采取一些训练技巧的话,可以在本作业的训练集上训练成功。
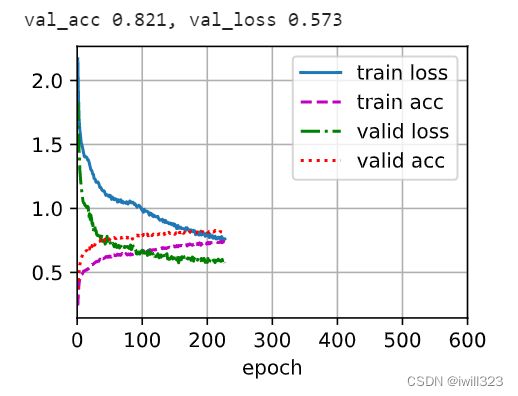
![]()
TTA
对每个模型做TTA(训练5个train_tfm的测试集),大部分都有明显提升。
| 模型 | 得分 | TTA |
| model2 | 0.81872 | 0.82569 |
| model3 | 0.83764 | 0.83565 |
| model5 | 0.78685 | 0.81274 |
| model6 | 0.76792 | 0.7998 |
| model7 | 0.80478 | 0.80876 |
| model8 | 0.80577 | 0.8227 |
model3做了TTA之后,表现基本不变,可能是因为表现已经较好了,TTA的潜力不大。
Ensamble
模型集成并不总是提升模型表现。将model5e-5和其他模型集成,得分0.82569,将model3和其他模型集成,得分0.83366,均不如集成前的表现,所以不能把优秀的模型和差距较大的模型集成,让表现相近的模型做集成才有效果。
- 同一模型的集成
将model5到model8这四个模型做集成,得分0.8237,可以说提升很大了。这里要注意,这几个模型实际上是同一个模型在同一个训练集上,同一个训练过程的不同checkpoint,也能有如此的集成效果,Ensamble的威力可见一斑。
![]()
将model5到model8这四个模型做集成+TTA,和只做集成相比,变化不大。可能是TTA的权重系数没有设好。

- 跨模型集成
将从头训练的resnet模型(得分 0.71414)和model6(得分 0.76792)做跨模型的集成,结果是0.78685,效果比较明显。

在集成的基础上继续做TTA,只做了一个train_tfm的测试集,提升效果很大,下面是preds_np[0]和preds_np[1]不同比例时的得分情况:
| 比例 | 1:1 | 2:1 | 6:1 | 9:1 |
| 得分 | 0.77788 | 0.80776 | 0.81274 | 0.81573 |
- 最终结果-大佬的集成
根据上面的经验,把效果最好的三个模型(model3,得分0.83565;model5e-05,得分0.83175;model迁移学习,得分0.84163)做集成和TTA。
只做集成:
![]()
集成+TTA

可以看到集成效果提升很大,TTA能进一步提升效果,如果精细调整,超过boss line 0.88446不是问题。
交叉验证
做了5折交叉验证,得到5个模型,每个模型结果如下:

对这5个模型进行集成+TTA(做了5个train_tfm的测试集),得分如下。其中preds_np[0]的系数分别是1.5,0.9,0.6。
可以看到得分并不太高,还不如上面的“杂牌军”。这是因为几个模型的得分都不高,因此集成的提升有限。看样子,模型集成遵循着“老子英雄儿好汉”的规律。
为什么上面的交叉验证模型得分不高?这是因为模型训练过程是自动的,超参数还没有仔细调整就停止了,所以得分不高

考虑到model0的得分比较低,把他去掉,用剩下的4个模型做集成+TTA,果然有一定的提升

再去掉得分较低的model1,集成得分是0.86254,没有提升。
下面变换TTA中preds_np[0]的系数,模型得分如下。可以发现没有明显的规律,结果的变化有限。结合之前的例子,0.9似乎比0.6更好。
| preds_np[0]的系数 | 0.2 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 | 1.1 |
| 得分 | 0.8645 | 0.8695 | 0.8665 | 0.8625 | 0.8635 | 0.8655 | 0.8655 | 0.8635 | 0.8645 |
num_works
之前没有注意num_workers对模型计算速度的影响,使用num_workers=0进行计算,发现GPU利用率为0,而CPU的利用率极高。下面的结果是在英伟达3090显卡上,训练原代码的分类模型,不同num_workers时的运行时间。每次都是重启内核之后,测试下一个num_workers
| num_workers | epoch=5时的耗时(s) | epoch=15时的耗时(s) |
| 0 | 1236.3717732429504 | |
| 1 | 312.47620368003845 |
|
| 2 | 168.62319421768188 |
|
| 4 | 107.80014061927795 |
324.39282393455505 |
| 8 | 89.33517622947693 |
294.2875111103058 |
| 16 | 123.81631231307983 |
失败 |
| 32 | 172.18559384346008 |
下图是不同num_workers时,计算5个epoch的情况下,GPU和CPU的运行图。当num_workers=0的时候,GPU没利用起来,内存利用也很低,事实上机器是在用CPU进行计算。当num_workers=1的时候,CPU利用率暴跌,GPU利用率上升了一点但是仍然不高,算了几下就变成0了,这是因为GPU很快就完成任务了,但是受制于数据传输速度,数据供给没跟上。随着num_workers增大,内存利用率上升,CPU在加紧给GPU传送数据,GPU利用率上升。当num_workers等于4/8/16时,GPU利用率很高,计算时间也很短。当num_workers等于32时,由于CPU使用太多的线程传输数据,光是数据协调就花费了很多时间,所以GPU利用率又下降了;拉长计算的战线(计算15个epoch),内核直接死掉了。
显存使用自始至终比较稳定,主要受batch size的影响。


对Kaggle也进行了测试,计算5个epoch:
| num_workers | 0 | 2 | 4 | 8 |
| 耗时(s) | 774 | 475 | 434 | 467 |
当使用多余2个num_workers时,kaggle和colab都会报提醒:
This DataLoader will create 4 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
即它们推荐使用num_workers=2需要注意的函数
np.array_split
可以用于K-fold中分割训练集和验证集
import numpy as np
X_train = np.arange(23)
num_folds = 5
X_train_folds = np.array_split(X_train, num_folds)
X_train_folds = np.array(X_train_folds, dtype=object)
print(X_train_folds)[array([0, 1, 2, 3, 4]) array([5, 6, 7, 8, 9]) array([10, 11, 12, 13, 14]) array([15, 16, 17, 18]) array([19, 20, 21, 22])]
a = np.delete(X_train_folds, 3)
print(a)
concat = np.concatenate(a)
print(concat)[array([0, 1, 2, 3, 4]) array([5, 6, 7, 8, 9]) array([10, 11, 12, 13, 14]) array([19, 20, 21, 22])] [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 19 20 21 22]