SSPU-Net
SSPU-Net
Accepted by ACM MM 2021
1. 研究动机:
传统的点云数据通过基于Ground Truth的有监督的方式实现数据上采样的工作,而本文提出了一种可以基于自监督的方式实现点云数据上采样。
为什么要上采样?因为一般采集到的点云数据通常是稀疏的,对于一些局部的几何结构表达不够好,可能会影响下游的处理任务。所以,有必要对稀疏点云进行上采样,以生成稠密完整的点云,从而方便后续的点云处理任务。
创新点:、
- NEU(neighbor expansion unit)模块 — 领域扩展单元
- DRU(differentiable point cloud rendering unit)模块 — 可微渲染单元
2. 网络结构:
2.1 整体网络结构:
首先通过一种邻域扩展单元(NEU)来将稀疏点云向上采样为稠密点云,利用每个点的局部几何结构自适应地学习权重来插值新点的特征。然后通过一个可微渲染单元(DRU),将输入的稀疏点云和生成的密集点云渲染成多视点图像。为了使稀疏点云和稠密点云具有相似的几何结构,我们在点云上构造了形状一致性损失,在渲染图像上构造了图像一致性损失来训练点云上采样网络。
2.2 NEU单元:
变量说明:
r: 上采样率
c: 特征维度,一般点云数据的坐标是三维坐标
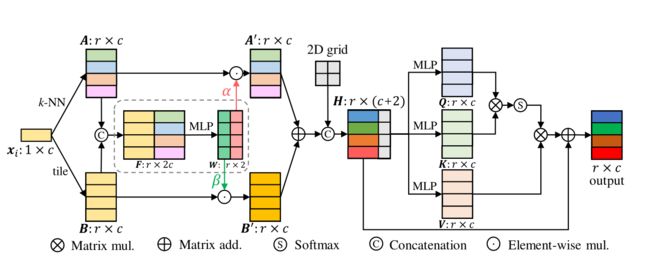
X i X_i Xi代表给定的输入点云数据中的一个点,首先我们选取该点临近的r个点的特征构建出特征图A,同时我们重复时使用该点特征r次构建出特征图B,然后对两个特征图进行concat得到特征图F,然后通过MLP自适应学习权重用于插值。 α \alpha α和 β \beta β分别表示临近点和中心点的权重, γ \gamma γ代表激活函数然后通过如下公式计算插值点的坐标信息:
为了更好的融合特征,还采用了2D grid和自注意力机制。最终基于一个点坐标,构建出了r个点的坐标信息。实现稀疏图像生成密集图像的过程。
2.3 DRU:
通过NEU单元,我们可以获得了在原始输入稀疏数据S的基础上生成的密集图像D,DRU模块的作用就是将稀疏和密集的点云渲染成多视图图像,以计算后续图像的一致性损失。
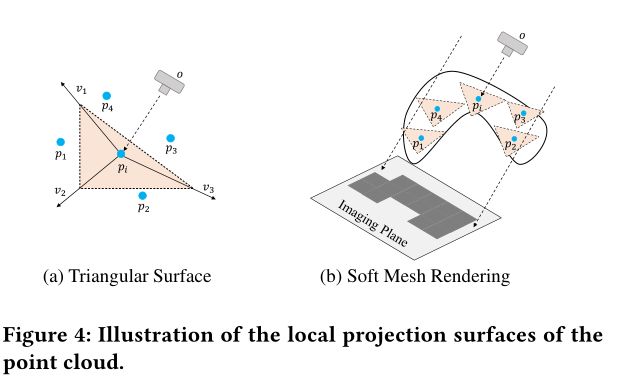
具体做法,首先将虚拟摄像机放置在输入点云周围的不同视点,以重建点云的投影曲面。然后,我们使用软网格渲染方法从投影曲面渲染多视图图像
如何生成不同视角的投影曲面?这里用到了一些数学计算公式
x = p i − o x = p_i - o x=pi−o
s = [ 1 , 0 , 0 ] s = [1,0,0] s=[1,0,0]
v 1 = x ∗ s v_1 = x * s v1=x∗s
为了计算 v 2 v_2 v2, v 3 v_3 v3,需要先计算一个辅助向量 v ^ \widehat{v} v 垂直于 x x x和 s s s: v ^ = x ∗ s \widehat{v} = x * s v =x∗s
然后通过下面一组公式即可算出 v 2 v_2 v2, v 3 v_3 v3同理
通过向量计算,得到当前点的局部切线三角形平面,再通过网格渲染得到最终的图像
2.4 Loss:
定义:
输入的稀疏点云数据为S
生成的密集点云数据为D
密集点云数据下采样得到的数据为D‘
2.4.1 Shape-consistent loss:
该loss处理的对象是原输入的稀疏点云数据S 和经过NEU单元构建的密集点云数据D,具体的设计思想是,选择一种下采样方案(例如论文提到的FPS),对NEU构建的密集点云数据进行下采样,得到新的稀疏点云数据D’ ,然后通过最小化D和D’来训练学习过程。
2.4.2 Image-consistent loss:
对于稀疏的点云数据S和密集的点云数据D分别经过DRU单元可生成不同的渲染图像, 显然D的数据密集,会有更多的点,因此也会生成更多的三角形曲面.但是论文提到经过实验验证,该差异对上采样几乎没有影响,所以损失的定义还是鼓励两个稀疏和密集的点云数据尽可能一致.
3. 实验部分:
3.1 数据集:
基于PU-Net、MPU、PU-GAN和FAUST中的部分人体模型来构建一个大型数据集,称为SSPU数据集,包括227个不同类别的3D模型,随机选择191个模型作为训练集,其余的模型作为测试集。
[一些超参数]:
epoch: 30
batch_size: 28
k[NEU] : 4
3.2 实验结果:
-
与目前一些常用的基于有监督的网络结构进行比较,输入数据有两类,一类是2048个点数据,另一类是4096个点数据。可以看出SSPU-Net与目前的一些自监督的方法取得了差不多的效果。这里的CD HD P2F等是不同的距离度量方式。
不过和PU-Net相比的话,整体都是由于PU-Net的
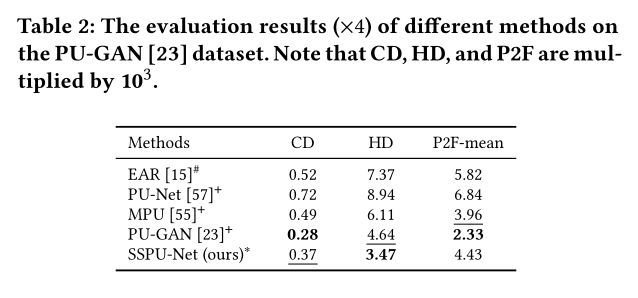
- Table2是在PU-GAN数据集上进行的测试,整体结果还是优于PU
- 下面这幅图是一个可视化的结果,展示了不同网络之间上采样的效果.
- 消融实验: