区域卷积神经网络R-CNN
区域卷积神经网络R-CNN
https://www.bilibili.com/video/BV1iJ411V7pM
1、图像分割:
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。它是由图像处理到图像分析的关键步骤。
(1)现有的图像分割方法主要分以下几类:
基于阈值的分割方法、
基于区域的分割方法、
基于边缘的分割方法
基于特定理论的分割方法等。
(2)按分割目的划分
- 普通分割
将不同分属不同物体的像素区域分开。
如前景与后景分割开,狗的区域与猫的区域与背景分割开。 - 语义分割
在普通分割的基础上,分类出每一块区域的语义(即这块区域是什么物体)。
如把画面中的所有物体都指出它们各自的类别。 - 实例分割
在语义分割的基础上,给每个物体编号。
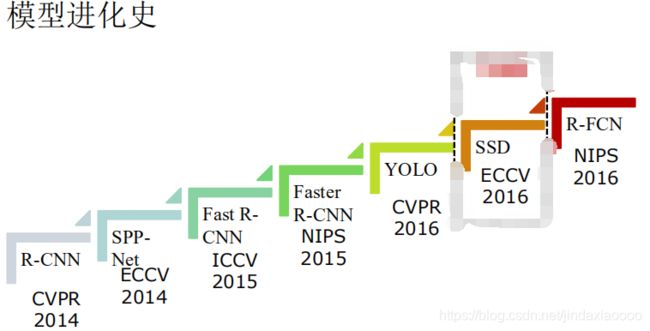
2、R-CNN
R-CNN的全称是Region-CNN,是第一个成功将深度学习应用到目标检测上的算法。R-CNN基于卷积神经网络(CNN),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。
R-CNN遵循传统目标检测的思路,同样采用提取框,对每个框提取特征、图像分类、 非极大值抑制四个步骤进行目标检测。只不过在提取特征这一步,将传统的特征(如 SIFT、HOG 特征等)换成了深度卷积网络提取的特征。R-CNN 体框架如图所示。
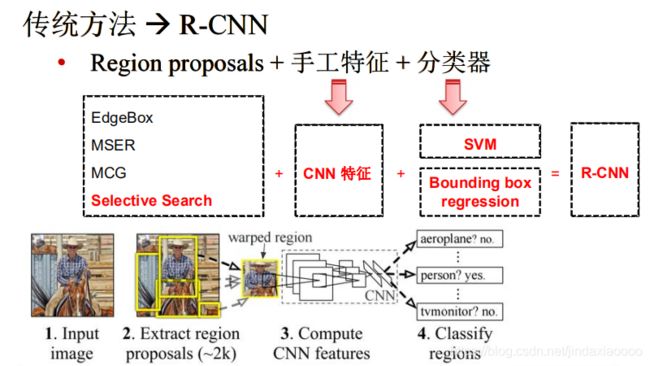

上面的框架图清晰的给出了R-CNN的目标检测流程:
(1) 输入测试图像
(2) 利用selective search算法在图像中提取2000个左右的region proposal。
(3) 将每个region proposal缩放(warp)成227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征,得到一个特征向量。
(4) 将每个region proposal提取到的CNN特征输入到SVM进行分类,预测出候选区域中所含物体的属于每个类的概率值。每个类别训练一个SVM分类器,从特征向量中推断其属于该类别的概率大小。
(5)为了提升定位准确性,R-CNN最后又训练了一个边界框回归模型,通过边框回归模型对框的准确位置进行修正。
2.1细节说明
- Selective Search:一种产生候选区的方法,没有用到深度学习,需要在 CPU 上训练,比较耗时,简称 SS。
- Region proposal:直译为成区域建议(有些别扭),就是生成候选区的过程,类似于比赛前的海选,其中的 region 是矩形区。方法有 Selective Search,论文中产生 2000 个候选区,下面简称这部分产生的区域为候选区。
- Bounding box:直译为边界框,就是最后输出定位的那个矩形框。严格来说,分为人工标注的 ground truth 和 predicted 两种类型。有时候简称为 BB。
- Region of interest(ROI:感兴趣的区域,有时候论文把 region proposal 产生的区域叫 ROI。
- Non maximum suppression(NMS):非极大值抑制,简称为 NMS 算法,其思想是搜素局部最大值,抑制极大值,在目标检测的目的是输出最合适的边界框。
- Fully connected layer:全连接层,我下面简写为 FC 层
- Feature map:卷积层的输出,可翻译为特征图。
(1)训练集
经典的目标检测算法在区域中提取人工设定的特征(Haar,HOG)。本文则需要训练深度网络进行特征提取。可供使用的有两个数据库:
一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。
一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置。一万图像,20类。
本文使用识别库进行预训练,而后用检测库调优参数。最后在检测库上评测。
(2)selective research
步骤一:
将图像A分成不同的子区域R1,R2…Rn
A = R 1 ∪ R 2 ∪ R 3.... ∪ R n A=R1\cup R2\cup R3....\cup Rn A=R1∪R2∪R3....∪Rn
根据交叠、尺寸、纹理、颜色(最终的相似度是这四个值取不同的权重相加)计算相邻子区域的相似度S12,S23,S34…再相加得到S
S = S 12 ∪ S 23 ∪ S 34 . . . . S=S_{12}\cup S_{23}\cup S_{34}.... S=S12∪S23∪S34....
步骤二:
找出相似度最大的子区域如R1,R2,将 R1,R2区域合并成Rn+1,并加入到A中
A = R 1 ∪ R 2 ∪ R 3.... ∪ R n ∪ R n + 1 A=R1\cup R2\cup R3....\cup Rn\cup Rn+1 A=R1∪R2∪R3....∪Rn∪Rn+1
并将S中所有和S1和S2相关的相似度都删除
步骤三:
将合并后的分割区域作为一个整体,跳到步骤1,直到 S = ∅ S=\varnothing S=∅,
此时 A = R 1 ∪ R 2 ∪ R 3.... ∪ R n ∪ R n + 1.... ∪ R n + m A=R1\cup R2\cup R3....\cup Rn\cup Rn+1....\cup Rn+m A=R1∪R2∪R3....∪Rn∪Rn+1....∪Rn+m
通过不停的迭代,候选区域列表中的区域越来越大。可以说,我们通过自底向下的方法创建了越来越大的候选区域Region proposal。表示效果如下:



(3)分类标签
因为训练过程是监督学习过程,所以需要给Region proposals标上标签。
groundtruth
根据提取的Region proposals和groundtruth之间的的IOU来确定Region proposals的标签:

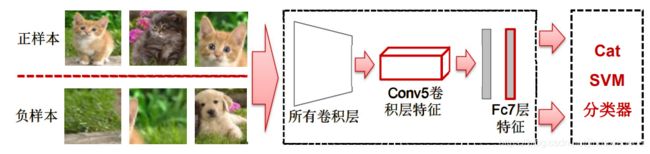
(4)SVM分类
在此模型中用神经网络提取特征,用SVM分类器进行分类。SVM二分类器只能判断region proposal是否属于某个类别,所以模型分类类别有几种,就有几个SVM二分类器。之所以选用SVM作为分类器,是因为region proposal一般都和groundtruth相差比较大,实验表明选用SVM分类器可以一定程度提高分类准确度。
由于直接用Region proposals来训练网络,所以最后得到的bounding box都不会很准确,所以要训练bounding box回归模型。并通过非极大值抑制技术来得到最终的物体的精确位置。
(5)训练bounding box回归模型
对每一类目标,使用一个边界框回归模型进行精修。正则项λ=10000, 输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
Region proposal的位置:
P = ( P x , P y , P w , P h ) P=(P_{x},P_{y},P_{w},P_{h}) P=(Px,Py,Pw,Ph)
groundtruth的位置:
G = ( G x , G y , G w , G h ) G=(G_{x},G_{y},G_{w},G_{h}) G=(Gx,Gy,Gw,Gh)
x,y代表中心点,w,h代表宽和高
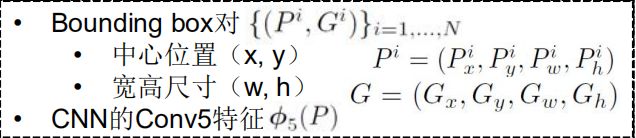
在边界框回归中,我们利用了线性回归在RCNN论文代表这AlexNet第5个池化层得到的特征即将送入全连接层的输入特征的线型函数。在这里,我们将特征记作 ϕ5(P)
bounding box的训练目标就是建立P->G的映射,输入为P,输出为预测的G,我们将映射拆成四个部分

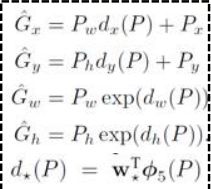
转化成最优化问题,使得使预测的G和实际的G相差最小,tx,ty,tw,th对应以上四个映射,测试的时候,这个映射关系就可以调整Region proposals的位置,来提升bounding box的精确度。
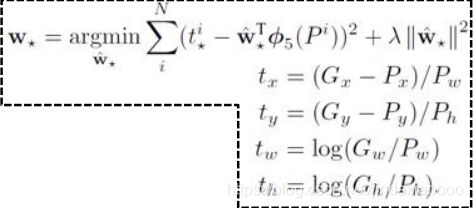
最后通过回归模型,同一物体能得到许多bounding box的位置,我们对bounding box进行打分(置信度:网络对预测结果正确的信心),通过非极大值抑制技术去除冗余的bounding box,最后选出分数最高的bounding box。


3、R-CNN框架存在着的问题:
(1) 训练分为多个阶段,步骤繁琐: 微调网络+训练SVM+训练边框回归器
(2) 训练耗时,占用磁盘空间大:5000张图像产生几百G的特征文件
(3) 速度慢: 使用GPU, VGG16模型处理一张图像需要47s。
针对速度慢的这个问题,SPP-NET给出了很好的解决方案。见下篇博客。