第3章 线性模型
1.基本形式
1.1 线性模型(linear model)
试图学得一个通过属性的线性组合来进行预测的函数
函数形式:
![]()
向量形式:
![]()
1.2 非线性模型(nonlinear model)
在线性模型的基础上通过引入层级结构或高位映射而得
1.4 可解释性(comprehensibility/understandability)
ω直观表达了各属性在预测中的重要性
2.线性回归(linear regression)
2.1 定义与数学形式
试图学得一个线性模型以尽可能准确地预测实值输出标记
公式:
![]()
2.2 离散属性与序关系
- 有序属性值:连续化
- 无序属性值:one-hot化
2.3 性能度量-均方误差
公式:
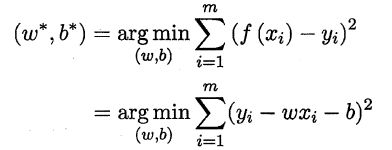
2.3.1 欧氏距离(Euclidean distance)
2.3.2 最小二乘法(least square method)
- 基于均方误差对模型求解的方法
- 试图找到一条直线,使所有样本到直线上的欧式距离之和最小
2.3.3 最小二乘“参数估计”(parameter estimation)
![]()
ω和b最优解的闭式(closed-form)解
- 分别对ω和b求导
- 分别对求导后的式子等于零
2.4 多元线性回归(multivariate linear regression)
2.4.1 秩矩阵(full-rank matrix)或正则矩阵(positive definite matrix)
现实任务重的xTx往往不是满秩矩阵
2.4.2 归纳偏好决定多个解的选择
常见做法:引入正则化(regularization)项
2.5 对数线性回归(log-linear regression) 令模型预测值逼近u的衍生物,例如ln(y)
2.5.1 在形式上仍是线性回归,但实质上已是在求取输入空间到输出空间的非线性函数映射
![]()
2.5.2 线性回归模型的预测值与真实标记联系起来的

2.6 广义线性模型(generalized linear model)
形式:
![]()
- 联系函数(link function) g(.)
- 对数线性回归是广义线性模型在g(.)=ln(.)的特例
3.对数几率回归(logistic regression,亦称logit regression)(不建议用逻辑回归说法)
3.1 分类任务怎么办?
3.1.1 二分类,使用单位阶跃函数(unit-step function)
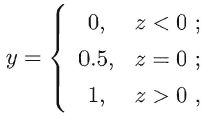
3.1.2 替代函数(surrogate function)
在一定程度上近似单位阶跃函数 单调可微
对数几率函数(logistic function),一种 Sigmoid函数
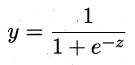
3.1.3 两个函数的联系

3.2 几率(odds)
- 假设
![]()
- 对数几率函数
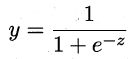
- 带入假设
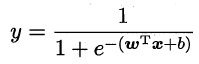
- 变换

- 几率是样本为正例跟样本为负例的比值

3.3 对数几率(log odds,亦称logit)
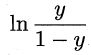
3.4 优点
- 直接对分类可能性进行建模,无需事先假设数据分布
- 可得到近似概率预测
- 对率函数是任意阶可导的凸函数,方便求最优解
3.5 极大似然法(maximum likelihood method)
3.5.1 凸优化理论
3.5.2 经典的数值优化算法,例如
- 梯度下降法(gradient descent method)
- 牛顿法(Newton method)
4.线性判别分析(Linear Discriminant Analysis,简称LDA)
4.1 LDA的思想
给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异类样例的投影点尽可能远离
4.2 二分类问题上称“Fisher判别分析”
- 类内散度矩阵(with-class scatter matrix) Sw
- 类间散度矩阵(between-class scatter matrix) Sb
- LDA可从贝叶斯决策理论的角度来阐释
- Sb与Sw的广义瑞利商(generalized Rayleigh quotient) LDA最大化的目标
LDA可达到最优分类,当
- 两类数据同先验
- 满足高斯分布
- 协方差相等
4.3 LDA可以推广到多分类任务
矩阵的迹(trace)
5.多分类学习
5.1 基本思路
拆解法:讲多分类任务拆为若干个二分类任务求解
5.2 最经典的拆分策略
- 一对一(One vs One,简称OvO)
- 一对其余(One vs Rest,简称OvR)
- 多对多(Many vs Many,简称MvM)
1)最常用技术:纠错输出码(Error Correcting Output,简称ECOC) 编码矩阵(coding matrix)
二元码 指定正类和反类
三元码 还可以指定用类
2)OvO和OvR是MvM的特例
6.类别不平衡问题(class-imbalance)
定义:分类任务中不同类别的训练样例数目差别很大的情况
6.1 处理的基本方法
再平衡(rebalance)/ 再缩放(rescaling)
6.1.1 代价敏感学习(cost-sensitive learning)的基础
6.1.2 解决现实中没有“无偏采样”的做法
- 欠采样(undersampling)/下采样(downsampling)
- 过采样(oversampling)/上采样(upsampling)
- 阈值移动(threshold-moving)
7.阅读材料
7.1 稀疏表示(sparse representation)
- 稀疏性问题本质上对应L0范数的优化,通常是NP难问题
- 求稀疏解的重要技术 LASSO通过L1范数近似L0范数
7.2 MvM实现方式补充
- ECOC
- 有向无环图DAG(Directed Acyclic Graph)
- 多类支持向量机
7.3 代价敏感学习
基于类别的误分类代价(misclassification cost)
7.4 多分类学习
每个样本仅属于一个类别
7.5 多标记学习(multi-label learning)
为一个样本同时预测出多个类别标记