(pytorch进阶之路)Masked AutoEncoder论文及实现
文章目录
- 1. 导读
- 2. 论文地址
- 3. 代码实现思路
-
- 3.1 预处理阶段
- 3.2 Encoder
- 3.3 Decoder
- 3.4 fine tuning
- 3.5 linear probing
- 3.6 evaluation
- 4. 代码地址
- 5. 如何实现MAE
-
- 5.1 model_mae.py
-
- 5.1.1 init函数
- 5.1.2 initialize_weights函数
- 5.1.3 _init_weight函数
- 5.1.4 patchify/unpatchify函数
- 5.1.5 random_masking函数
- 5.1.6 forward_encoder函数
- 5.1.7 forward_decoder函数
- 5.1.8 forward_loss函数
- 5.2 main_pretrain.py
- 5.3 main_finetune.py
1. 导读
这一部分简单介绍一下什么是MAE
Resnet的一作和MAE的一作都是何恺明大佬,于Facebook AI Research (FAIR)研究
MAE作者给的定义是基于部分被观测的量去预测整个原始图像的简单的自编码方法
MAE属于自监督学习的一种,像自监督学习NLP领域中还有word embedding,transformer,bert
摘要,第一部分是写作意图,第二部分是对模型或者算法的描述,第三部分写在某某任务上取得的效果
写作意图:提出用于CV自监督学习模型
模型细节:图片分成一个个patch,随机的遮住一些块,尝试去重构被遮住的那些像素,类似AutoEncoder,句子中一些单词mask掉,用bert来预测那些被mask掉的单词。MAE主要基于两个核心的设计,提出非对称Encoder和Decoder结构
Encoder和Decoder都比较熟悉了,Encoder用于编码获得隐藏层,Decoder用于还原,编码器输入未被遮掩的patch,得到隐含表征再和被遮掩的块结合起来,输入到解码器中,去重构图像
Encoder以可见的块作为输入,另外一个是轻量级的Decoder,作用是恢复原始的照片,输入是来自编码器的hidden_state
论文提到如果以75%的遮掩比例发现能取得一个比较好的遮掩效果
取得效果:基于以上两个设计可以使得更有效和更高效地训练大容量模型,如VIT-Huge在ImageNet-1K上取得87.8%准确率
MAE结构:
首先image2patch,2emb(在timm库有现成的函数可以调用了),图像能变为一维的序列结构,遮掩75%,将25%可见patch拼成序列送入transformer encoder中得到这个序列的隐含表示,transformer encoder是各向同性的,输入多大,输出多大,再把隐含表征和之前的被掩码的embbeding重新拼起来,恢复原始图像的顺序,这一步叫unshuffle,接着送入到decoder中,得到新的表征,最后就把新的表征做一个回归任务
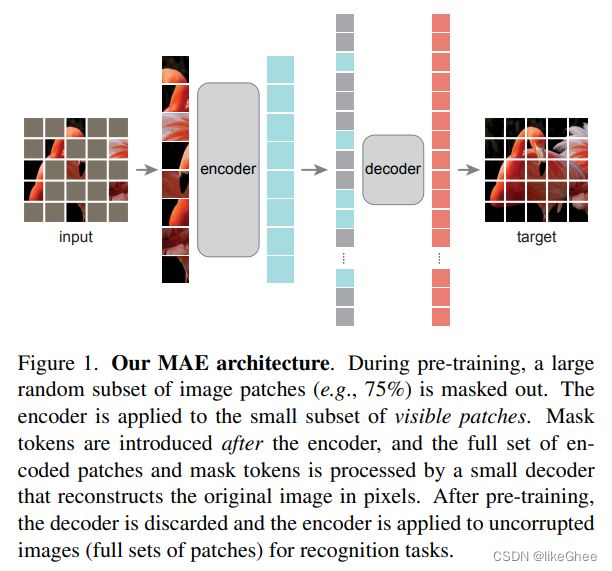
Mask:和VIT处理的一样,将图像划分成一个个没有交叠的块,随机挑选一部分的patch作为可见,剩下的patch遮住,没有采用任何替代,bert中masked token是被另一个单词取代或是用mask token取代,而论文作者强调没有采用替代方法
使用75%比例是为了消除冗余性,图像不用这么高比例的话很容易预测
Encoder:就是VIT结构,VIT在分解一下,就是image2patch2emb,位置编码position emb(PE),MHSA,MLP,仅仅只是输入部分不同,序列长度缩短,减少了计算量
Decoder:接收所有的token作为输入,即输入序列长度是完整长度,token包含两部部分,一是编码过后的可见patch emb,另一个是被mask token,二者需要重排序放回图像的顺序(unshuffle过程)。每个mask token是共享的可学习向量,这些向量来表示需要去预测的丢失的块,无论是第一个位置还是第二个位置,都是用统一的embbeding去表示,说明被掩码的像素是没有被用来输入的,因为我们本来就是要去预测它。PE也是需要用到
解码器仅仅是在预训练阶段使用,解码器做图像重构的回归任务,目的是为了学到有效的编码器。论文作者发现轻量级的解码器就能取得很好的效果
做分类任务时,我们只需要MAE的编码器,解码器是不需要的,编码器添加一个head层
MAE是为了预测那些被mask掉那些图像的像素,即重构图像,每个解码器输出的元素是像素点的值,最后一部分是一个全连接层,比如一个patch大小16×16×3,那么解码器的最后一层MLP就映射到这样一个大小,patch2image,目标函数是MSE(平均平方差),像bert一样只去预测被mask掉的像素(可以用mask loss实现)
预测均值标准差归一化的像素效果会更好一些,(像素减去均值再除以标准差)
Encoder和Decoder都是由一个个transformer block构成的,每个block就是一层自注意力机制,加两层MLP,加上层归一化构成一个残差的结构,是各向同性的block
代码简单实现逻辑:为输入的图像生成一个token emb;再加上位置编码,PE有正余弦固定emb,或者可学习emb;为token的列表做shuffle,取前面的25%;输入到encoder中得到被编码的encoder patch emb,encoder patch emb和刚刚剩下的75%token(共享的可学习mask emb)拼接,再做一个unshuffle操作,最后将unshuffle后的结果输入到decoder
fine tuning:基于预训练过的模型参数和新的目标数据集,微调模型参数
linear probing:冻结模型参数,只训练head层
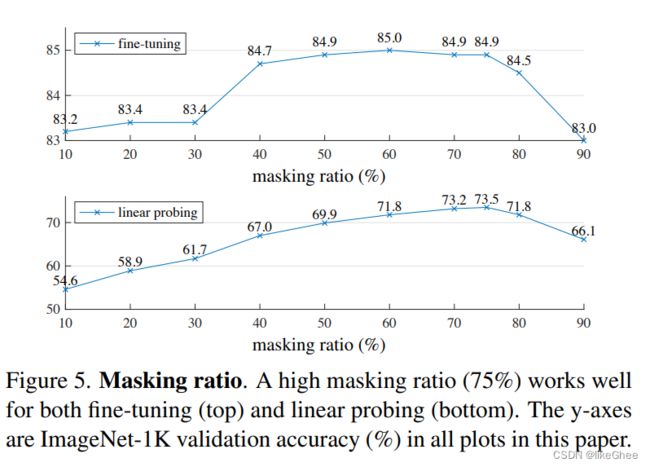
参数如何选择,进行的消融实验

论文中也有重构图像的效果,左边是mask的图片,中间是重构图片,右边是真实图片,基本上能还原上一些大的轮廓,说明MAE起到了图像重构的功能

2. 论文地址
https://openaccess.thecvf.com/content/CVPR2022/papers/He_Masked_Autoencoders_Are_Scalable_Vision_Learners_CVPR_2022_paper.pdf
3. 代码实现思路
假如我们想要复现MAE,我们可以分成4个模块,预处理模块,Encoder,Decoder和Loss(loss部分比较简单,MSE),Encoder,Decoder都是基于transformer block设计的(MHSA,MLP,PE)
模型class实现可以分成3部分:
forward encoder
forward decoder
总体的forward loss
代码大体思路:
构建dataset,dataloader
实例化模型
设置优化器
加载模型
训练epoch
保存模型
加载与保存模型:model.state_dict(), optimizer.state_dict(), epoch,loss,config
3.1 预处理阶段
1,第一步image2tensor,用image-1k dataset举例,将图片读进来
有两种读法
一是PIL库PIL.Image.open读取照片,再convert成RGB得到三通道Uint8的图像,(RGB: #000000 ~ #FFFFFF Uin8的16进制表示)
第二种方法是用torchvision.datasets.ImageFolder,将图像的根目录传入ImageFolder,根目录下得有一个train文件夹,train文件夹里面又有1k的子文件夹代表不同类别的图像
最后获取张量:[c, h, w], type:uint8
2,第二步一般会做augment数据增广的一些操作,
crop:截取,比如500×500截取100×100
resize:图片尺度变换
flip:图像翻转
模糊处理:高斯模糊或者用均值滤波(图像patch中各点的像素值就是该图像素卷积核范围内的像素的均值)
增广操作需要保证增广后的图片大小是网络输入的大小
3,第三步convert
转换成合适的数据格式,可以用torchvision.transforms.PILToTensor()API,将uint8转换成0~1之间的浮点数,映射操作
4,第四步归一化
我们把如256这么大的数直接喂入到神经网络之中,一般会进行归一化(如均值方差归一化)或者正态分布格式(x减去均值除以标准差,数值大小在0上下范围)
3.2 Encoder
1,image2patch2emb,有多种实现啦,举个卷积实现,F.conv2d(image, kernel_martix, stride=kernel_size)
2,position embbeding,可以使用正余弦固定常量计算PE
3,random mask(shuffle),对patch随机打散,再取前面的25%
4,class token,仿照VIT标准做法,在fine-tuning做分类任务需要用到,class token放在开头
5,transformer block,有VIT-Base,VIT-Large,VIT-Huge,可以选择不同的模型

3.3 Decoder
1,projection layer,编码器的特征维度比较大,解码器特征维度比较小,因此对编码器的输出做一个投影
2,unshuffle,将encoder output还原到图片,图片中被掩码的部分用共享的emb代替,得到一张完整的图片emb
3,新的PE,解码器仍然是一个transformer结构,需要用到一个新的position emb反应解码器输入序列上每个token位置
4,transformer block,
5,regression layer,回归任务
6,loss mask,loss function
3.4 fine tuning
1,数据增强,强增广
2,encoder + bn + mlp
3,PE插值,预训练图片大小可能与微调阶段图片大小不一样,比如预训练阶段图片大小是256,微调阶段图片大小是480,patch_size仍然保持和预训练时候的一致,那encoder输入序列长度就会变大,需要做一下PE插值
4,加载模型,加载MAE,严格加载要有相同的层,即state_dict的key一样,A模型加载B模型参数,但是微调阶段只有一个encoder+bn+mlp,因此要非严格加载,参数设置strict=False,相同的层被加载,不同的层给一个提示
5,更新所有参数
6,优化器选择AdamW
7,loss function,CE loss,分类任务用交叉熵
3.5 linear probing
1,弱数据增强
2,encoder + bn + mlp,bn去掉仿射变换,仅仅做归一化
3,PE插值
4,加载模型
5,冻结编码器参数
6,优化器选择LARS
7,loss function,CE loss
3.6 evaluation
with torch.no_grad()
model.eval() 调整bn和dropout成eval
预训练阶段评估,patch还原成照片,MSE loss,PIL.show查看图片样子
微调阶段分类任务,topk,模型预测出来的结果取前k高概率结果与标准label做对比
4. 代码地址
https://github.com/facebookresearch/mae
5. 如何实现MAE
到github下载mae代码
大体上看,主要是engine引擎文件,main主入口文件,model文件,submit提交任务,主要看model,main,engine
mae分为预训练阶段和微调阶段,微调阶段用的是mae encoder部分,在项目中是写成model_vit.py,预训练部分是model_mae.py,其实encoder参数都是一样的,可以加载的,先看model_mae.py
5.1 model_mae.py
model_mae.py中首先定义了一个class,叫做MaskedAutoencoderViT,即基于VIT实现的mae
class MaskedAutoencoderViT(nn.Module):
""" Masked Autoencoder with VisionTransformer backbone
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3,
embed_dim=1024, depth=24, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4., norm_layer=nn.LayerNorm, norm_pix_loss=False):
super().__init__()
# --------------------------------------------------------------------------
# MAE encoder specifics
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim), requires_grad=False) # fixed sin-cos embedding
self.blocks = nn.ModuleList([
Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
# --------------------------------------------------------------------------
# --------------------------------------------------------------------------
# MAE decoder specifics
self.decoder_embed = nn.Linear(embed_dim, decoder_embed_dim, bias=True)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
self.decoder_pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, decoder_embed_dim), requires_grad=False) # fixed sin-cos embedding
self.decoder_blocks = nn.ModuleList([
Block(decoder_embed_dim, decoder_num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(decoder_depth)])
self.decoder_norm = norm_layer(decoder_embed_dim)
self.decoder_pred = nn.Linear(decoder_embed_dim, patch_size**2 * in_chans, bias=True) # decoder to patch
# --------------------------------------------------------------------------
self.norm_pix_loss = norm_pix_loss
self.initialize_weights()
def initialize_weights(self):
# initialization
# initialize (and freeze) pos_embed by sin-cos embedding
pos_embed = get_2d_sincos_pos_embed(self.pos_embed.shape[-1], int(self.patch_embed.num_patches**.5), cls_token=True)
self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0))
decoder_pos_embed = get_2d_sincos_pos_embed(self.decoder_pos_embed.shape[-1], int(self.patch_embed.num_patches**.5), cls_token=True)
self.decoder_pos_embed.data.copy_(torch.from_numpy(decoder_pos_embed).float().unsqueeze(0))
# initialize patch_embed like nn.Linear (instead of nn.Conv2d)
w = self.patch_embed.proj.weight.data
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
# timm's trunc_normal_(std=.02) is effectively normal_(std=0.02) as cutoff is too big (2.)
torch.nn.init.normal_(self.cls_token, std=.02)
torch.nn.init.normal_(self.mask_token, std=.02)
# initialize nn.Linear and nn.LayerNorm
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
# we use xavier_uniform following official JAX ViT:
torch.nn.init.xavier_uniform_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def patchify(self, imgs):
"""
imgs: (N, 3, H, W)
x: (N, L, patch_size**2 *3)
"""
p = self.patch_embed.patch_size[0]
assert imgs.shape[2] == imgs.shape[3] and imgs.shape[2] % p == 0
h = w = imgs.shape[2] // p
x = imgs.reshape(shape=(imgs.shape[0], 3, h, p, w, p))
x = torch.einsum('nchpwq->nhwpqc', x)
x = x.reshape(shape=(imgs.shape[0], h * w, p**2 * 3))
return x
def unpatchify(self, x):
"""
x: (N, L, patch_size**2 *3)
imgs: (N, 3, H, W)
"""
p = self.patch_embed.patch_size[0]
h = w = int(x.shape[1]**.5)
assert h * w == x.shape[1]
x = x.reshape(shape=(x.shape[0], h, w, p, p, 3))
x = torch.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape(shape=(x.shape[0], 3, h * p, h * p))
return imgs
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore
def forward_encoder(self, x, mask_ratio):
# embed patches
x = self.patch_embed(x)
# add pos embed w/o cls token
x = x + self.pos_embed[:, 1:, :]
# masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# append cls token
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# apply Transformer blocks
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x, mask, ids_restore
def forward_decoder(self, x, ids_restore):
# embed tokens
x = self.decoder_embed(x)
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # no cls token
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
x = torch.cat([x[:, :1, :], x_], dim=1) # append cls token
# add pos embed
x = x + self.decoder_pos_embed
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x
def forward_loss(self, imgs, pred, mask):
"""
imgs: [N, 3, H, W]
pred: [N, L, p*p*3]
mask: [N, L], 0 is keep, 1 is remove,
"""
target = self.patchify(imgs)
if self.norm_pix_loss:
mean = target.mean(dim=-1, keepdim=True)
var = target.var(dim=-1, keepdim=True)
target = (target - mean) / (var + 1.e-6)**.5
loss = (pred - target) ** 2
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return loss
def forward(self, imgs, mask_ratio=0.75):
latent, mask, ids_restore = self.forward_encoder(imgs, mask_ratio)
pred = self.forward_decoder(latent, ids_restore) # [N, L, p*p*3]
loss = self.forward_loss(imgs, pred, mask)
return loss, pred, mask
5.1.1 init函数
init函数中定义了一些超参数,image_size,patch_size,in_chans,embed_dim,depth(编码器block个数,24对应的是large模型),num_heads,decoder_embed_dim(解码器大小,比encoder dim小),decoder_depth,decoder_num_heads
首先是分界线,定义encoder部分
实例化patch_emb,直接用timm.models.vision_transformer.PatchEmbed API,传入照片大小,patch大小,输入通道数,emb_dim,得到patch_emb序列
num_patches类比NLP就是一句话单词数目,这里将图片变成patch序列
分别实例化cls_token,pos_embed,cls_token可训练,pos_embed是正余弦常量构成的固定参数emb(shape:[1, num_patches+1, emb_dim]),大小设置是1,num_patches+1,因为cls token也占了一个位置,所以在num_patches基础上+1
定义block,用的ModuleList装block,block实例化也是用的timm库,timm.models.vision_transformer.Blcok API,传入的参数是embed_dim(输入和输出维度,因为各向同性,输入和输出维度一致),num_heads,mlp_ratio(瓶颈结构,dim放大倍率), qkv_bias=True, qk_scale=None, norm_layer=norm_layer
nn.LayerNorm定义LN,对encoder output最后一层在做一个归一化
分界线划分encoder,下面是decoder部分
首先是维度变换层Linear
定义mask_token,一个可训练的共享emb,替换75%被遮掩的patch
定义pe,大小[1, num_patches+1, decoder_dim]
定义block
定义LN
定义预测linear,即重构图片,输入decoder_dim,输出是patch_size平方×in_channel
最后是norm_pix_loss,是否对像素做归一化
initialize_weight()初始化权重
def __init__(self, img_size=224, patch_size=16, in_chans=3,
embed_dim=1024, depth=24, num_heads=16,
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
mlp_ratio=4., norm_layer=nn.LayerNorm, norm_pix_loss=False):
super().__init__()
# --------------------------------------------------------------------------
# MAE encoder specifics
self.patch_embed = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim), requires_grad=False) # fixed sin-cos embedding
self.blocks = nn.ModuleList([
Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
# --------------------------------------------------------------------------
# --------------------------------------------------------------------------
# MAE decoder specifics
self.decoder_embed = nn.Linear(embed_dim, decoder_embed_dim, bias=True)
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
self.decoder_pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, decoder_embed_dim), requires_grad=False) # fixed sin-cos embedding
self.decoder_blocks = nn.ModuleList([
Block(decoder_embed_dim, decoder_num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
for i in range(decoder_depth)])
self.decoder_norm = norm_layer(decoder_embed_dim)
self.decoder_pred = nn.Linear(decoder_embed_dim, patch_size**2 * in_chans, bias=True) # decoder to patch
# --------------------------------------------------------------------------
self.norm_pix_loss = norm_pix_loss
self.initialize_weights()
5.1.2 initialize_weights函数
首先对pe做初始化,用util文件夹下的util.pos_embed.get_2d_sincos_pos_embed函数实现(这个不错,后面自己可以拿来用 XD,不过在pytorch进阶之路二篇也自己实现过了)
之后使用.data.copy_替换类成员pos_embed
接下是对patch_embed table做一下初始化,用的xavier均匀分布的初始化
cls token和mask token初始化
使用Module父类的apply函数,参数是接受一个_init_weight函数,这个函数会作用到当前这个module和当前module的所有子module,遍历递归的形式对所有的子module调用_init_weight函数
5.1.3 _init_weight函数
如果当前进入的是linear层,对它的权重进行均匀分布的初始化
如果还有bias,初始化常数为0
如果是LN层,常数初始化为0和1.0
def _init_weights(self, m):
if isinstance(m, nn.Linear):
# we use xavier_uniform following official JAX ViT:
torch.nn.init.xavier_uniform_(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
5.1.4 patchify/unpatchify函数
划为patch
(N, 3, H, W) -> (N, L, patch_size**2 *3)
def patchify(self, imgs):
"""
imgs: (N, 3, H, W)
x: (N, L, patch_size**2 *3)
"""
p = self.patch_embed.patch_size[0]
assert imgs.shape[2] == imgs.shape[3] and imgs.shape[2] % p == 0
h = w = imgs.shape[2] // p
x = imgs.reshape(shape=(imgs.shape[0], 3, h, p, w, p))
x = torch.einsum('nchpwq->nhwpqc', x)
x = x.reshape(shape=(imgs.shape[0], h * w, p**2 * 3))
return x
patch还原成图像,x使用了爱因斯坦标定法
def unpatchify(self, x):
"""
x: (N, L, patch_size**2 *3)
imgs: (N, 3, H, W)
"""
p = self.patch_embed.patch_size[0]
h = w = int(x.shape[1]**.5)
assert h * w == x.shape[1]
x = x.reshape(shape=(x.shape[0], h, w, p, p, 3))
x = torch.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape(shape=(x.shape[0], 3, h * p, h * p))
return imgs
5.1.5 random_masking函数
mae核心部分
输入x大小是[N,L,D]
输出x,x将输入到encoder,mask掩码矩阵,mask提供给decoder使用,0表示未掩码,1表示被掩码,ids_restore恢复索引,decoder中将用到ids_restore恢复图片顺序
计算出保留块的个数
torch.rand,均匀分布采样生成0~1之间的随机数,这里生成是的[N, L]矩阵,每个样本保留位置都是随机不同的
用argsort对刚刚生成的0~1噪声矩阵进行排序,argsort后得到一个列表,这个列表表示x从小到大排序所对应的索引是什么,即列表元素是下标索引,各个位置的索引对应的元素大小在列表中呈升序排序
再对L维度元素大小升序排序的索引传入argsort,得到从大到小排序的张量对应的索引,ids_restore表示encoder之后得到的新序列每个元素在原来位置上是对应第几个
举个例子假设图片x为[[x1, x2, x3, x4]],共享掩码向量为mask_emb,掩盖比列是50%,假设noise是[[0.4629, 0.8821, 0.8695, 0.2301]],则ids_shuffle为[[3, 0, 2, 1]],则ids_restore为[[1, 3, 2, 0]],那么根据ids_shuffle,依次取元素x[3],x[0],x[2],x[1],我们取到新x=[[x4, x1, x3, x2]],取前50%输入encoder,得到encoder输出[[x4_emb, x1_emb]],encoder的输出再和共享向量拼接得到新x=[[x4_emb, x1_emb, mask_emb, mask_emb]],我们需还原图像的序列再输入到decoder,则依次遍历ids_restore,第一个位置是x[1], 第二位置是x[3], 第三个位置是x[2],第四个位置是x[0],得到最终的到结果x=[[x1_emb, mask_emb, mask_emb, x4_emb]],(其实这个过程可以看作为gether函数的2D tensor,dim=1的过程)
ids_keep取ids_shuffle前%多少的元素
torch.gather函数,根据ids_keep取x的未被掩码部分,dim=1(序列长度L维)
gather函数3D tensort,dim=1公式:out[i][j][k] = input[i][index[i][j][k]][k]
举个简单的3D tensort,dim=1的例子input=[[[1,2],[3,4],[5,6]]],index=[[[1,1]]],如何求out?
我们遍历index,一开始i=0,j=0,k=0, index[0][0][0] = 1, 根据out[i][j][k] = input[i][index[i][j][k]][k] ,则out[0][0][0] = input[0][1][0] = 3,往后遍历,下一个是i=0, j=0, k=1, 则out[0][0][1] = input[0][1][1] = 4,index遍历完,结束,最终out = [[[3, 4]]]
最后是生成mask表提供给decoder使用,mask表示被掩码部分的矩阵,首先生成全1矩阵[N, L],前%多少设置全0,后面被掩码部分设置成1,用gather函数,传入ids_restore参数,将mask还原成在照片中的顺序,0表示未掩码,1表示被掩码
def random_masking(self, x, mask_ratio):
"""
Perform per-sample random masking by per-sample shuffling.
Per-sample shuffling is done by argsort random noise.
x: [N, L, D], sequence
"""
N, L, D = x.shape # batch, length, dim
len_keep = int(L * (1 - mask_ratio))
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_masked, mask, ids_restore
5.1.6 forward_encoder函数
接收两个参数,第一个是x,第二个是mask_ratio
第一步将图片送入到patch_embed
第二步,在x基础上加入PE
第三步,MAE核心操作随机掩码,返回x,x将输入到encoder,mask掩码矩阵,mask提供给decoder使用,0表示未掩码,1表示被掩码,ids_restore恢复索引,decoder中将用到ids_restore恢复图片顺序
第四步,添加cls token
第五步,遍历block,blocks是存储model列表,对每个block进行前向运算
最后经过一层LN层
def forward_encoder(self, x, mask_ratio):
# embed patches
x = self.patch_embed(x)
# add pos embed w/o cls token
x = x + self.pos_embed[:, 1:, :]
# masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, mask_ratio)
# append cls token
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# apply Transformer blocks
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x, mask, ids_restore
5.1.7 forward_decoder函数
解码器部分
先输入decoder_embed,维度变换层,降维到decoder维度上
将mask_tokens(共享的可学习向量)扩维,batch_size,和seq_len维度,+1是考虑cls token
x和mask_token拼接起来,x先去掉cls token,因为ids_restore没有考虑到cls token
用gather函数unshuffle回原来的顺序
再把cls token加回来
后面比较简单了:
添加PE
输入block
输入LN
回归预测任务,将隐藏特征映射到图片维度
忽略cls token
def forward_decoder(self, x, ids_restore):
# embed tokens
x = self.decoder_embed(x)
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # no cls token
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
x = torch.cat([x[:, :1, :], x_], dim=1) # append cls token
# add pos embed
x = x + self.decoder_pos_embed
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection
x = self.decoder_pred(x)
# remove cls token
x = x[:, 1:, :]
return x
5.1.8 forward_loss函数
forward_loss是一个平方差loss,MSE,但是归一化需要对每个patch的dim计算均值和方差,防止方差为0加上一个1.e-6
后面是求一个MSE,最后乘上mask求和
def forward_loss(self, imgs, pred, mask):
"""
imgs: [N, 3, H, W]
pred: [N, L, p*p*3]
mask: [N, L], 0 is keep, 1 is remove,
"""
target = self.patchify(imgs)
if self.norm_pix_loss:
mean = target.mean(dim=-1, keepdim=True)
var = target.var(dim=-1, keepdim=True)
target = (target - mean) / (var + 1.e-6)**.5
loss = (pred - target) ** 2
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return loss
5.2 main_pretrain.py
预训练入口函数
首先是args = get_args_parser(),设置参数,边角料不重要
主要看main函数
首先是初始化分布式训练,通用代码,多机单机都通用
init_distributed_mode中world_size表示gpu数目,rank和local_rank表示当前在第几个卡上,如果是单卡将distributed设置为False就行
torch.distributed.barrier函数等待所有分布式任务初始化完成
设置device
固定seed
benchmark=True,这些都是常规操作了
torchvision库中的torchvision.transforms.Compose对图片进行预增广,有随机截取resize,随机翻转,ToTensor将uint8映射到0~1浮点数,均值标准差归一化
datasets.ImageFolder得到dataset_train
得到sampler_train,支持多机
传入torch.utils.data.DataLoader获得dataloader
实例化模型
实例化优化器,使用timm的optim_factory构造参数组,对参数加decay,实例化AdamW
是NativeScaler对象表示loss_scaler
是否加载模型
遍历训练,遍历epoch
engine中有train_one_epoch函数,训练一个周期
支持混合精度,autocast,更新loss
def main(args):
misc.init_distributed_mode(args)
print('job dir: {}'.format(os.path.dirname(os.path.realpath(__file__))))
print("{}".format(args).replace(', ', ',\n'))
device = torch.device(args.device)
# fix the seed for reproducibility
seed = args.seed + misc.get_rank()
torch.manual_seed(seed)
np.random.seed(seed)
cudnn.benchmark = True
# simple augmentation
transform_train = transforms.Compose([
transforms.RandomResizedCrop(args.input_size, scale=(0.2, 1.0), interpolation=3), # 3 is bicubic
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
dataset_train = datasets.ImageFolder(os.path.join(args.data_path, 'train'), transform=transform_train)
print(dataset_train)
if True: # args.distributed:
num_tasks = misc.get_world_size()
global_rank = misc.get_rank()
sampler_train = torch.utils.data.DistributedSampler(
dataset_train, num_replicas=num_tasks, rank=global_rank, shuffle=True
)
print("Sampler_train = %s" % str(sampler_train))
else:
sampler_train = torch.utils.data.RandomSampler(dataset_train)
if global_rank == 0 and args.log_dir is not None:
os.makedirs(args.log_dir, exist_ok=True)
log_writer = SummaryWriter(log_dir=args.log_dir)
else:
log_writer = None
data_loader_train = torch.utils.data.DataLoader(
dataset_train, sampler=sampler_train,
batch_size=args.batch_size,
num_workers=args.num_workers,
pin_memory=args.pin_mem,
drop_last=True,
)
# define the model
model = models_mae.__dict__[args.model](norm_pix_loss=args.norm_pix_loss)
model.to(device)
model_without_ddp = model
print("Model = %s" % str(model_without_ddp))
eff_batch_size = args.batch_size * args.accum_iter * misc.get_world_size()
if args.lr is None: # only base_lr is specified
args.lr = args.blr * eff_batch_size / 256
print("base lr: %.2e" % (args.lr * 256 / eff_batch_size))
print("actual lr: %.2e" % args.lr)
print("accumulate grad iterations: %d" % args.accum_iter)
print("effective batch size: %d" % eff_batch_size)
if args.distributed:
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu], find_unused_parameters=True)
model_without_ddp = model.module
# following timm: set wd as 0 for bias and norm layers
param_groups = optim_factory.add_weight_decay(model_without_ddp, args.weight_decay)
optimizer = torch.optim.AdamW(param_groups, lr=args.lr, betas=(0.9, 0.95))
print(optimizer)
loss_scaler = NativeScaler()
misc.load_model(args=args, model_without_ddp=model_without_ddp, optimizer=optimizer, loss_scaler=loss_scaler)
print(f"Start training for {args.epochs} epochs")
start_time = time.time()
for epoch in range(args.start_epoch, args.epochs):
if args.distributed:
data_loader_train.sampler.set_epoch(epoch)
train_stats = train_one_epoch(
model, data_loader_train,
optimizer, device, epoch, loss_scaler,
log_writer=log_writer,
args=args
)
if args.output_dir and (epoch % 20 == 0 or epoch + 1 == args.epochs):
misc.save_model(
args=args, model=model, model_without_ddp=model_without_ddp, optimizer=optimizer,
loss_scaler=loss_scaler, epoch=epoch)
log_stats = {**{f'train_{k}': v for k, v in train_stats.items()},
'epoch': epoch,}
if args.output_dir and misc.is_main_process():
if log_writer is not None:
log_writer.flush()
with open(os.path.join(args.output_dir, "log.txt"), mode="a", encoding="utf-8") as f:
f.write(json.dumps(log_stats) + "\n")
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('Training time {}'.format(total_time_str))
5.3 main_finetune.py
前面都差不多,初始化参数,build_transform回根据参数创建transform,得到dataloader
新增了一个增广mixup,对效果有一定的提升
实例化model_vit模型,只做了一点就是mae的encoder部分
mae模型参数导入到微调模型
使用了interpolate_pos_embed对位置编码进行插值,线性插值法,微调阶段有图片大小更大的话,pe仍然可以适用
loss改成CE loss