pandas库及其具体应用
Series
一组数据加索引
可以有以下的创建方式(运用字典)
import pandas as pd
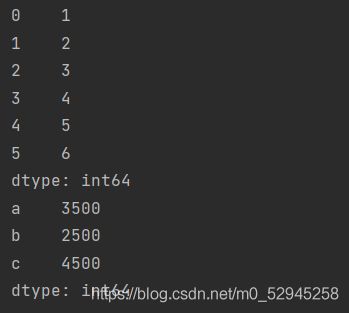
obj=pd.Series([1,2,3,4,5,6])
print(obj)
sdata={'a':3500,'b':2500,'c':4500}
bojt=pd.Series(sdata)
print(bojt)
sdata2=['a','b','c','d']
objt1=pd.Series(bojt,index=sdata2)
print(objt1)
objt1.index.name='stata'
print(objt1)运行结果图:
Series的功能特别的强大,比如说两个数组可以相互相加,或者是数组可以自动匹配赋值,具体的可以在https://blog.csdn.net/brucewong0516/article/details/79196902中找到
DataFrame
import pandas as pd
data={'a':[100,200,300,400],
'b':[200,300,400,500],
'c':[300,400,500,600]}
dframe=pd.DataFrame(data)
print(dframe)
dframe2=pd.DataFrame(data,columns=['c','b','a'])
print(dframe2)
datastates=[1,2,3,4]
dframe3=pd.DataFrame(data,index=datastates,columns=['c','b','a','g'])
print(dframe3)运行结果图为:

解释一下:首先,前5行创建了第一个DataFrame,第六行中的columns=['c','b','a']可以修改三个属性的顺序,index=可以修改行号的索引名称,但是注意,这个修改行号的索引值不能超过原来的行数,不然会报错,如下:
datastates=[1,2,3,4,5]
dframe3=pd.DataFrame(data,index=datastates,columns=['c','b','a','g'])本来有四行,但是将其改成五行,不会新增一行NaN,只会出现

从DataFrame中获取一列,可以得到一个Series,有两种方式,分别是
print(dframe['a'])
print(dframe.b)获取一行,可以通过loc,例如
print(dframe.loc[0])注意注意注意:loc引用要通过【】,而不是(),不然不会输出结果
新增列和删除行列
temp=pd.Series([1,2,3],index=[1,2,3])
print(temp)
dframe['d']=temp
print(dframe)
dframe=dframe.drop(0)
print(dframe)
dframe=dframe.drop('a',axis=1)
print(dframe)
#drop列号,需要加一个axis=1
del dframe['c']
print(dframe)删除行用drop(行号),删除列用del关键字,del dframe【‘列引用’】
新增一列需要首先创建一个Series,然后再添加进去
如果用字典嵌套字典去创建DataFrame,则不用index= 来重新定义行号和列号,如下所示
data1={'a':{'one':100,'two':200,'three':300},'b':{'two':200,'three':300},'c':{'one':100,'two':200,'three':300}}
dframe2=pd.DataFrame(data1)
print(dframe2)
dframe2=dframe2.T
print(dframe2)效果图为:

处理缺失数据
滤除缺失数据
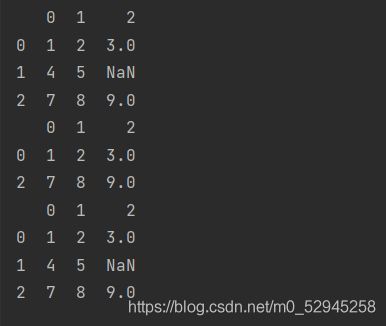
data=pd.DataFrame([[1,2,3],[4,5,np.nan],[7,8,9]])
print(data)
data2=data.dropna()
print(data2)
data3=data.dropna(how='all')
print(data3)how='all'表示只有一行全是nan才会去掉,运行结果为: