【机器学习】DS的基础学习笔记4:神经网络与反向传播算法
文章目录
- 神经网络与反向传播算法
-
- 4.1 代价函数
- 4.2 反向传播算法
-
- 4.2.1 算法概览
- 4.2.2 细节理解
- 4.3 小结
-
- 4.3.1 随机初始化
- 4.3.2 梯度检验
- 4.3.3 小结
- 4.4 配套作业的Python实现
-
- 4.4.1 上节回顾
- 4.4.2 代价函数
- 4.4.3 反向传播算法
- 4.4.4 梯度检验
- 4.4.5 模型训练
- 4.4.6 显示隐藏层
神经网络与反向传播算法
4.1 代价函数
上一节我们了解了神经网络的基本结构与前向传播算法,在配套作业中神经网络的权重已全部给出,但我们如何自己训练出合适的权重呢?因此我们需要了解代价函数与反向传播算法。
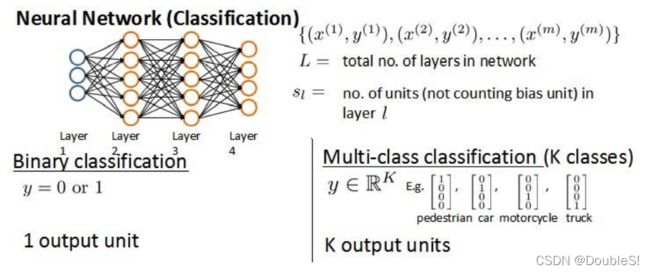
我们需要了解一些标记方法,假设神经网络训练样本有 m m m个,每个包含一组输入 x x x和一组输出信号 y y y, L L L表示神经网络层数, S I S_I SI表示各层神经元个数, S L S_L SL表示最后一层中处理单元的个数。
对于神经网络的分类问题,可以分为两类:二类分类与多类分类。二类分类: S L = 2 , y = 0 o r 1 S_L=2,y=0 or 1 SL=2,y=0or1;多类分类: S L = k , y i = 1 S_L=k,y_i=1 SL=k,yi=1表示分到第 i i i类。( k > 2 k>2 k>2)
我们回顾逻辑回归中的代价函数为
J ( θ ) = − 1 m [ ∑ i = 1 n y ( i ) l o g h θ ( x ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j 2 J(\theta)=-\frac{1}{m}[\sum_{i=1}^ny^{(i)}logh_\theta(x^{(i)})+(1-y^{(i)})log(1-h_\theta(x^{(i)}))]+\frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2 J(θ)=−m1[i=1∑ny(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj2
但因为神经网络中有多个输出量,从而代价函数更加复杂
h Θ ( x ) ∈ R K ( h Θ ( x ) ) i = i t h o u t p u t J ( Θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 K y k ( i ) l o g ( h Θ ( x ( i ) ) ) k + ( 1 − y k ( i ) ) l o g ( 1 − ( h Θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( Θ j i ( l ) ) 2 h_\Theta(x)\in \mathbb{R}^K\qquad (h_\Theta(x))_i=i^{th} output\\ J(\Theta)=-\frac{1}{m}[\sum_{i=1}^m\sum_{k=1}^Ky_k^{(i)}log(h_\Theta(x^{(i)}))_k+(1-y_k^{(i)})log(1-(h_\Theta(x^{(i)}))_k)]+\frac{\lambda}{2m}\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_{l+1}}(\Theta_{ji}^{(l)})^2 hΘ(x)∈RK(hΘ(x))i=ithoutputJ(Θ)=−m1[i=1∑mk=1∑Kyk(i)log(hΘ(x(i)))k+(1−yk(i))log(1−(hΘ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2
该代价函数虽然复杂,但背后蕴含的思想是一致的:我们希望通过观察代价函数来得知算法预测结果与真实情况差距有多大。与逻辑回归不同的是,神经网络有 K K K个预测,我们通过循环,选取可能性最高的一个,将其与 y y y中实际值进行比较。同理,偏置项我们不进行正则化,因此 i i i从1开始记。
4.2 反向传播算法
4.2.1 算法概览
在正向传播算法中,我们从输入层开始一层一层计算得到 h Θ ( x ) h_\Theta(x) hΘ(x)。现在我们为了计算代价函数的偏导数 ∂ ∂ Θ i j ( l ) J ( Θ ) \frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta) ∂Θij(l)∂J(Θ),我们需要采用反向传播算法,也就是先计算最后一层的误差,然后再一层一层反向求出各层误差,直到倒数第二层。在我个人理解来看,实质上是链式求导法则的自然结果。
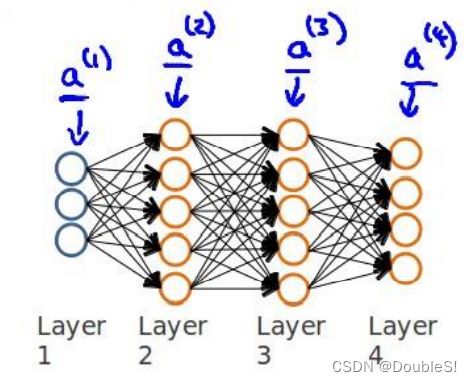
课程上的例子为训练集中只有一个训练样本 ( x ( 1 ) , y ( 1 ) ) (x^{(1)},y^{(1)}) (x(1),y(1)),神经网络结构如图:
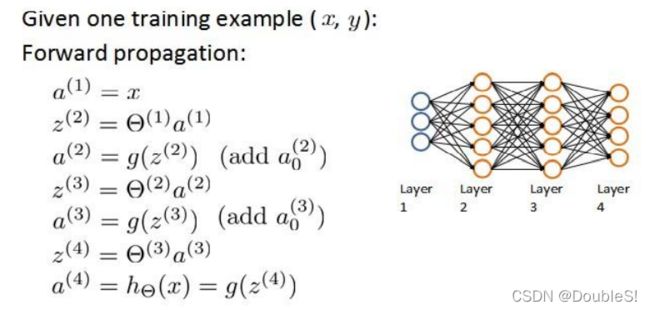
重温前向传播算法:
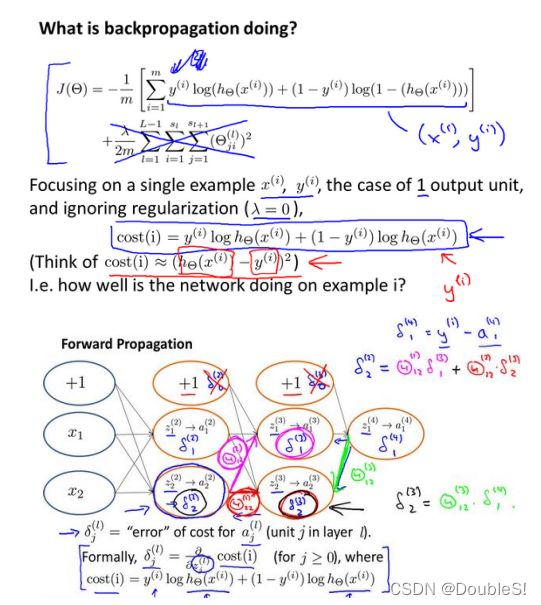
我们从最后一层开始计算误差,最后一层误差指激活单元预测( a k ( 4 ) a_k^{(4)} ak(4))与实际值( y k y_k yk)之间的误差
( k = 1 : k k=1:k k=1:k),我们用 δ \delta δ表示误差,在这里我们可以暂时理解 δ ( l ) = ∂ ∂ z ( l ) J ( Θ ) \delta^{(l)}=\frac{\partial}{\partial z^{(l)}}J(\Theta) δ(l)=∂z(l)∂J(Θ),则 δ ( 4 ) = a ( 4 ) − y \delta^{(4)}=a^{(4)}-y δ(4)=a(4)−y,从而我们利用这个误差值来计算前一层的误差: δ ( 3 ) = ∂ ∂ z ( 3 ) J ( Θ ) = ∂ ∂ z ( 4 ) J ( Θ ) ⋅ ∂ z ( 4 ) ∂ a ( 3 ) ⋅ ∂ a ( 3 ) ∂ z ( 3 ) = ( Θ ( 3 ) ) T δ ( 4 ) . ∗ g ′ ( z ( 3 ) ) \delta^{(3)}=\frac{\partial}{\partial z^{(3)}}J(\Theta)=\frac{\partial}{\partial z^{(4)}}J(\Theta)\cdot\frac{\partial z^{(4)}}{\partial a^{(3)}}\cdot\frac{\partial a^{(3)}}{\partial z^{(3)}}=(\Theta^{(3)})^T\delta^{(4)}.*g'(z^{(3)}) δ(3)=∂z(3)∂J(Θ)=∂z(4)∂J(Θ)⋅∂a(3)∂z(4)⋅∂z(3)∂a(3)=(Θ(3))Tδ(4).∗g′(z(3))其中 . ∗ .* .∗是点乘,对应元素相乘,这里便是用到了复合函数求导中的链式法则。其中我们还应了解sigmoid函数的一个性质: g ′ ( z ) = g ( z ) ∗ ( 1 − g ( z ) ) g'(z)=g(z)*(1-g(z)) g′(z)=g(z)∗(1−g(z)).
我们还可以得到第二层的误差:
δ ( 2 ) = ∂ ∂ z ( 2 ) J ( Θ ) = ∂ ∂ z ( 3 ) J ( Θ ) ⋅ ∂ z ( 3 ) ∂ a ( 2 ) ⋅ ∂ a ( 2 ) ∂ z ( 2 ) = ( Θ ( 2 ) ) T δ ( 3 ) . ∗ g ′ ( z ( 2 ) ) \delta^{(2)}=\frac{\partial}{\partial z^{(2)}}J(\Theta)=\frac{\partial}{\partial z^{(3)}}J(\Theta)\cdot\frac{\partial z^{(3)}}{\partial a^{(2)}}\cdot\frac{\partial a^{(2)}}{\partial z^{(2)}}=(\Theta^{(2)})^T\delta^{(3)}.*g'(z^{(2)}) δ(2)=∂z(2)∂J(Θ)=∂z(3)∂J(Θ)⋅∂a(2)∂z(3)⋅∂z(2)∂a(2)=(Θ(2))Tδ(3).∗g′(z(2))
有了所有误差的表达式后,我们可以计算代价函数的偏导数,假设 λ = 0 \lambda=0 λ=0,即我们不作正则化处理时有: ∂ ∂ Θ i j ( l ) J ( Θ ) = ∂ ∂ z i ( l + 1 ) J ( Θ ) ⋅ ∂ z i ( l + 1 ) ∂ Θ i j ( l ) = a j ( l ) δ ( l + 1 ) \frac{\partial}{\partial \Theta_{ij}^{(l)}}J(\Theta)=\frac{\partial}{\partial z_i^{(l+1)}}J(\Theta)\cdot\frac{\partial z_i^{(l+1)}}{\partial \Theta_{ij}^{(l)}}=a_j^{(l)}\delta^{(l+1)} ∂Θij(l)∂J(Θ)=∂zi(l+1)∂J(Θ)⋅∂Θij(l)∂zi(l+1)=aj(l)δ(l+1)
上式中上下标含义为: l l l代表目前所计算的是第几层; j j j代表目前计算层中的激活单元下标; i i i代表下一层中误差单元的下标。
对于训练集有很多训练样本且要作正则化处理时,我们用 Δ i j ( l ) \Delta_{ij}^{(l)} Δij(l)作总体误差,其含义为各个样本偏导数不作正则化处理时的偏导数之和。我们将算法表示为:

我们对各样本进行循环,利用前向传播算法计算出每一层的激活单元,然后利用反向传播法从而我们计算出了多训练样本的误差和,我们还需要考虑正则化,最终可求得代价函数偏导数:
D i j ( l ) = 1 m ( Δ i j ( l ) + λ Θ i j ( l ) ) i f j ≠ 0 D i j ( l ) = 1 m Δ i j ( l ) i f j = 0 D_{ij}^{(l)}=\frac{1}{m}(\Delta_{ij}^{(l)}+\lambda\Theta_{ij}^{(l)})\qquad if\quad j\neq0\\ D_{ij}^{(l)}=\frac{1}{m}\Delta_{ij}^{(l)}\qquad if\quad j=0 Dij(l)=m1(Δij(l)+λΘij(l))ifj=0Dij(l)=m1Δij(l)ifj=0
4.2.2 细节理解
4.3 小结
4.3.1 随机初始化
任何优化算法都需要一些初始参数,在前面我们都将参数初始化为0,这样的初始方法对神经网络来说是不可行的。如果我们令所有的初始参数都为0,这将意味着我们第二层的所有激活单元都会有相同的值。同理,如果我们初始所有的参数都为同一个非0的数,结果也是一样的。
我们通常初始参数为 ± ε ±\varepsilon ±ε的随机值。
def random_init(size):
return np.random.uniform(-0.12, 0.12, size)
4.3.2 梯度检验
神经网络相较于前两种学习算法而言会更加复杂,从而我们在代码实现上可能出现一些难以察觉的错误,这意味虽然代价不断减小,但最终结果可能并不是最优解。
为了避免这样的问题,我们采取一种叫做梯度的数值检验的方法。其实质为差分近似微分。在代价函数上沿着切线方向选择两个非常近的点,然后计算两个点的平均值用以估计梯度。对于某个特定的 θ \theta θ,我们计算在 θ − ε \theta-\varepsilon θ−ε处和 θ + ε \theta+\varepsilon θ+ε的代价值( ε \varepsilon ε是一个非常小的值,通常选取0.001),然后求两个代价的平均,用以估计在 θ \theta θ处的代价值。
f i ( θ ) ≈ J ( θ ( i + ) ) + J ( θ ( i − ) ) 2 ε f_i(\theta)≈\frac{J(\theta^{(i+)})+J(\theta^{(i-)})}{2\varepsilon} fi(θ)≈2εJ(θ(i+))+J(θ(i−))
如果两者之差在合理范围内,那么说明我们算法的实现是正确的。
4.3.3 小结
如果隐藏层数大于1,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好。我们真正要决定的是隐藏层的层数和每个中间层的单元数。
- 参数的随机初始化
- 利用正向传播算法计算所有的 h θ ( x ) h_\theta(x) hθ(x)
- 编写计算代价函数 J J J的代码
- 利用反向传播算法计算所有偏导数
- 使用优化算法来最小化代价函数
4.4 配套作业的Python实现
4.4.1 上节回顾
本节我们同样使用手写数据集来实现BPNN.
先前我们进行了导入库、可视化、读取已给权重来前向传播,代码如下,具体步骤见上节。
import matplotlib.pyplot as plt
import numpy as np
import scipy.io as sio
import matplotlib
import scipy.optimize as opt
from sklearn.metrics import classification_report#这个包是评价报告
def load_data(path, transpose=True):
data = sio.loadmat(path)
y = data.get('y') # (5000,1)
y = y.reshape(y.shape[0]) # make it back to column vector
X = data.get('X') # (5000,400)
if transpose:
# for this dataset, you need a transpose to get the orientation right
X = np.array([im.reshape((20, 20)).T for im in X])
# and I flat the image again to preserve the vector presentation
X = np.array([im.reshape(400) for im in X])
return X, y
def expand_y(y):
res = []
for i in y:
y_array = np.zeros(10)
y_array[i-1] = 1
res.append(y_array)
return np.array(res)
def plot_100_image(X):
""" sample 100 image and show them
assume the image is square
X : (5000, 400)
"""
size = int(np.sqrt(X.shape[1]))
# sample 100 image, reshape, reorg it
sample_idx = np.random.choice(np.arange(X.shape[0]), 100) # 100*400
sample_images = X[sample_idx, :]
fig, ax_array = plt.subplots(nrows=10, ncols=10, sharey=True, sharex=True, figsize=(8, 8))
for r in range(10):
for c in range(10):
ax_array[r, c].matshow(sample_images[10 * r + c].reshape((size, size)),
cmap=matplotlib.cm.binary)
plt.xticks(np.array([]))
plt.yticks(np.array([]))
X, _ = load_data('exdata1.mat', transpose=True)
plot_100_image(X)
plt.show()
X_raw, y_raw = load_data('ex4data1.mat', transpose=False)
X = np.insert(X_raw, 0, np.ones)
y = expand_y(y_raw)
def deserialize(seq): # 拆散参数
return seq[:25*401].reshape(25, 401), seq[25*401: ].reshape(10, 26)
def sigmoid(z):
return 1 / (1 + np.exp(z))
def feed_forward(theta, X): # 前向传播
t1, t2 = deserialize(theta)
m = X.shape[0]
a1 = X
z2 = a1 @ t1.T
a2 = np.insert(sigmoid(z2), 0, np.ones(m), axis=1)
z3 = a2 @ t2.T
h = sigmoid(z3)
return a1, z2, a2, z3, h

4.4.2 代价函数
J ( Θ ) = − 1 m [ ∑ i = 1 m ∑ k = 1 K y k ( i ) l o g ( h Θ ( x ( i ) ) ) k + ( 1 − y k ( i ) ) l o g ( 1 − ( h Θ ( x ( i ) ) ) k ) ] + λ 2 m ∑ l = 1 L − 1 ∑ i = 1 s l ∑ j = 1 s l + 1 ( Θ j i ( l ) ) 2 J(\Theta)=-\frac{1}{m}[\sum_{i=1}^m\sum_{k=1}^Ky_k^{(i)}log(h_\Theta(x^{(i)}))_k+(1-y_k^{(i)})log(1-(h_\Theta(x^{(i)}))_k)]+\frac{\lambda}{2m}\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_{l+1}}(\Theta_{ji}^{(l)})^2 J(Θ)=−m1[i=1∑mk=1∑Kyk(i)log(hΘ(x(i)))k+(1−yk(i))log(1−(hΘ(x(i)))k)]+2mλl=1∑L−1i=1∑slj=1∑sl+1(Θji(l))2
def regularized_cost(theta, X, y): # 正则化代价函数
m = X.shape[0]
t1, t2 = deserialize(theta)
_, _, _, _, h = feed_forward(theta, X)
pair_computation = -np.multiply(y, np.log(h)) - np.multiply((1-y), np.log(1-h))
cost = pair_computation.sum() / m
reg_t1 = (1 / (2*m)) * np.power(t1[:, 1:], 2).sum()
reg_t2 = (1 / (2*m)) * np.power(t2[:, 1:], 2).sum()
return cost + reg_t1 + reg_t2
4.4.3 反向传播算法
def serialize(a, b): # 扁平化参数
return np.concatenate((np.ravel(a), np.ravel(b)))
def sigmoid_gradient(z):
return np.multiply(sigmoid(z), 1 - sigmoid(z))
def gradient(theta, X, y):
t1, t2 = deserialize(theta)
m = X.shape[0]
delta1 = np.zeros(t1.shape)
delta2 = np.zeros(t2.shape)
a1, z2, a2, z3, h = feed_forward(theta, X)
for i in range(m):
a1i = a1[i, :]
z2i = z2[i, :]
z2i = np.insert(z2i, 0, np.ones(1), axis=0)
a2i = a2[i, :]
hi = h[i, :]
yi = y[i, :]
d3i = hi - yi
d2i = np.multiply(t2.T @ d3i, sigmoid_gradient(z2i))
delta2 += (1/m) * np.matrix(d3i).T @ np.matrix(a2i) # 转换为matrix,(1,10).T@(1,26)->(10,26)
delta1 += (1/m) * np.matrix(d2i[1:]).T @ np.matrix(a1i) # (1,25).T@(1,401)->(25,401)
t1[:, 0] = 0
t2[:, 0] = 0
reg_term1 = (1 / m) * t1
reg_term2 = (1 / m) * t2
delta2 += reg_term2
delta1 += reg_term1
return serialize(delta1, delta2)
4.4.4 梯度检验
我们使用二范数进行数值梯度与解析梯度的度量。
∥ n u m e r i c a l _ g r a d − a n a l y t i c _ g r a d ∥ 2 ∥ n u m e r i c a l _ g r a d ∥ 2 + ∥ a n a l y t i c _ g r a d ∥ 2 \frac{\Vert numerical\_grad - analytic\_grad\Vert_2}{\Vert numerical\_grad\Vert_2+\Vert analytic\_grad\Vert_2} ∥numerical_grad∥2+∥analytic_grad∥2∥numerical_grad−analytic_grad∥2
def expand_array(arr):
"""
input [1,2,3]
out
[[1,2,3],
[1,2,3],
[1,2,3]]
"""
return np.array(np.matrix(np.ones(arr.shape[0])).T @ np.matrix(arr))
def gradient_checking(theta, X, y, epsilon):
def numeric_grad(plus, minus):
return (regularized_cost(plus, X, y)-regularized_cost(minus, X, y)) / (2 * epsilon)
theta_matrix = expand_array(theta)
epsilon_matrix = np.identity(len(theta)) * epsilon
plus_matrix = theta_matrix + epsilon_matrix
minus_matrix = theta_matrix - epsilon_matrix
numeric_grad = np.array([numeric_grad(plus_matrix[i], minus_matrix[i]) for i in range(len(theta))])
analytic_grad = regularized_gradient(theta, X, y)
diff = np.linalg.norm(numeric_grad - analytic_grad) / (np.linalg.norm(numeric_grad) + np.linalg.norm(analytic_grad))
print("If your backpropagation implementation is correct,\n"
"the relative difference will be smaller than 10e-7(assume epsilon=10e-7).\n"
"Relative Difference:{}\n".format(diff))
def random_init(size):
return np.random.uniform(-0.12, 0.12, size)
init_theta = random_init(10285)
gradient_checking(init_theta, X, y, epsilon=10e-7)
If your backpropagation implementation is correct,
the relative difference will be smaller than 10e-7(assume epsilon=10e-7).
Relative Difference:1.0262913293779404e-08
需要注意,当算法通过梯度检验后一定在训练网络前关闭梯度检验一步,否则训练时间非常久。
4.4.5 模型训练
def nn_training(X, y):
init_theta = random_init(10285)
res = opt.minimize(fun=regularized_cost,
x0=init_theta,
args=(X, y, 1),
method='TNC',
jac=regularized_gradient,
options={'maxiter': 400})
return res
res = nn_training(X, y)
_, y_answer = load_data('ex4data1.mat')
final_theta = res.x
def show_accuracy(theta, X, y):
_, _, _, _, h = feed_forward(theta, X)
y_pred = np.argmax(h, axis=1) + 1
print(classification_report(y, y_pred))
show_accuracy(final_theta, X, y_answer)

4.4.6 显示隐藏层
def plot_hidden_layer(theta):
final_theta1, _ = deserialize(theta)
hidden_layer = final_theta1[:, 1:]
fig, ax_array = plt.subplots(nrows=5, ncols=5, sharex=True, sharey=True, figsize=(5, 5))
for r in range(5):
for c in range(5):
ax_array[r, c].matshow(hidden_layer[5*r + c].reshape(20, 20),
cmap=matplotlib.cm.binary)
plt.xticks([])
plt.yticks([])
plot_hidden_layer(final_theta)
plt.show()
