CLIP:从自然语言监督中学习可迁移的视觉模型
最先进的计算机视觉系统经过训练,可以预测一组固定的预定对象类别。这种受限的视觉监督形式限制了它们的通用性和可用性,因为需要额外的标记数据来指定任何其他视觉概念。直接从原始文本中学习图像是一种很有前途的选择,它利用了更广泛的监督来源。我们展示了一个简单的预训练任务,即预测哪个标题与哪个图像匹配,这是一种有效且可扩展的方法,利用这种方法可以在从互联网收集的4亿对(图像、文本)数据集上从头开始学习SOTA视觉模型CLIP。在预训练之后,我们使用自然语言引用学习到的视觉概念(或描述新的概念),从而使CLIP模型能够zero-shot迁移到下游任务上。我们在30多个计算机视觉数据集上进行基准测试,以研究CLIP的性能,这些数据集涵盖了OCR、视频动作识别、地理定位和多种类型的细粒度对象分类等任务。结果表明,CLIP可以非常方便地迁移到大多数任务上,并且不需要任何特定数据集的训练就能与全监督基线模型相竞争。我们已将CLIP的代码和预训练模型权重发布到GitHub:https://github.com/OpenAI/CLIP.
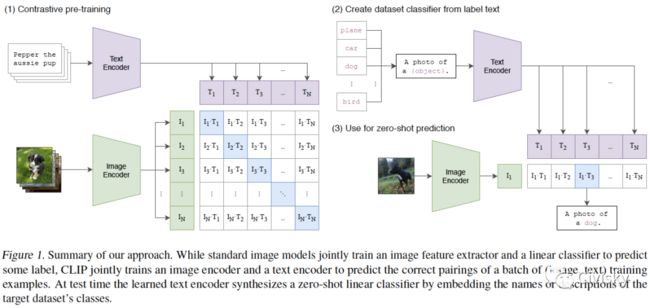
图1. CLIP方法总结。标准图像模型联合训练图像特征提取器和线性分类器以预测某个标签,而CLIP联合训练图像编码器和文本编码器以预测一批(图像、文本)训练示例的正确配对。在测试时,学习的文本编码器通过嵌入目标数据集类的名称或描述来合成zero-shot线性分类器。

图2. CLIP在zero-shot迁移任务上比图像字幕基线模型更有效。Transformer语言模型尽管表达能力很强,但在zero-shot ImageNet分类任务中相对较弱。在这里,我们发现它的学习速度比Bag of Words Prediction基线慢3倍,比Bag of Words Contrastive(CLIP)慢4倍。

图3. CLIP模型的核心伪代码。

表1. CLIP与之前zero-shot迁移图像分类结果的比较。CLIP在三个数据集上的性能得到极大提高。
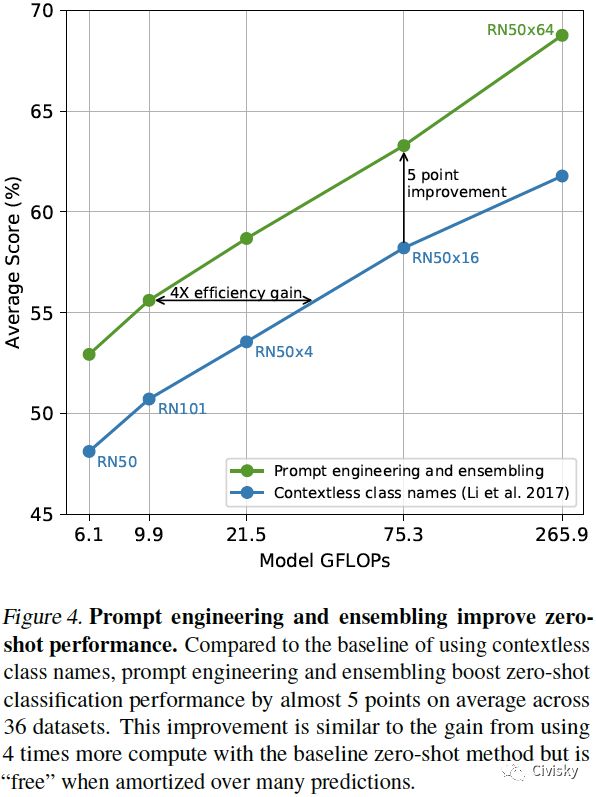
图4. 敏捷工程和集成提高了zero-shot的性能。与基线模型相比,在36个数据集上,敏捷工程和集成平均将zero-shot分类性能提高了近5个百分点。
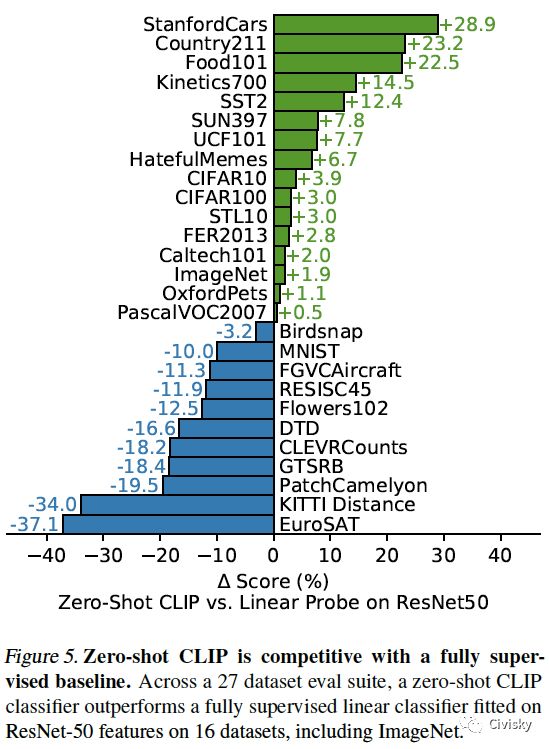
图5. Zero-shot CLIP可以与全监督基线模型相竞争。在27个数据集中,zero-shot CLIP分类器在其中16个数据集(包括ImageNet)上优于ResNet-50全监督线性分类器。
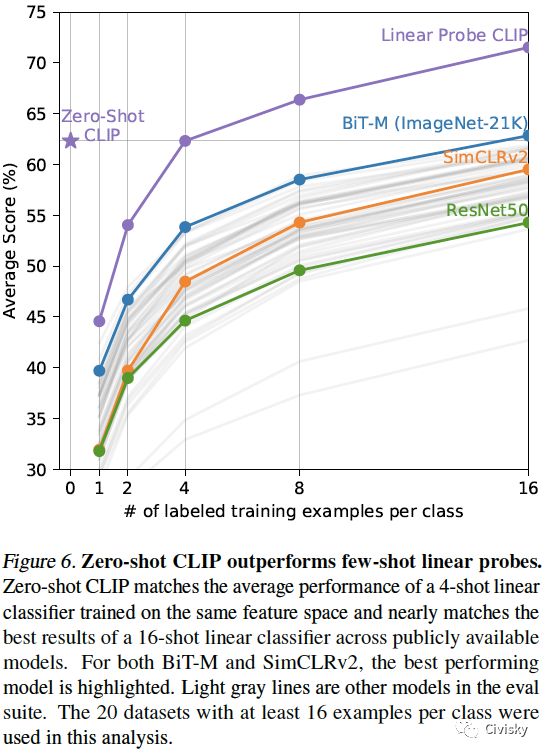
图6. Zero-shot CLIP优于few-shot线性探头。Zero-shot CLIP与在同一特征空间上训练的4-shot Linear Probe CLIP的平均性能相匹敌,并且与现有可用的16-shot线性分类器的最佳性能相匹敌。分析中使用了20个数据集,每个类至少有16个示例。

图7. Zero-shot迁移的数据效率差异很大。
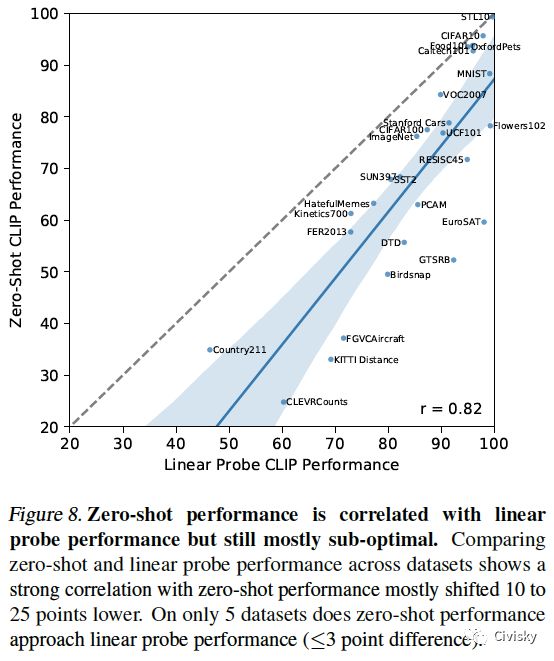
图8. Zero-shot的性能与线性探头的性能相关,但多数情况下仍属次优。比较不同数据集上zero-shot和线性探头的性能,结果表明,zero-shot的性能在大多数情况下降低了10到25个点。仅仅在5个数据集上,zero-shot的性能接近线性探头的性能(在3个点的差异之内)。
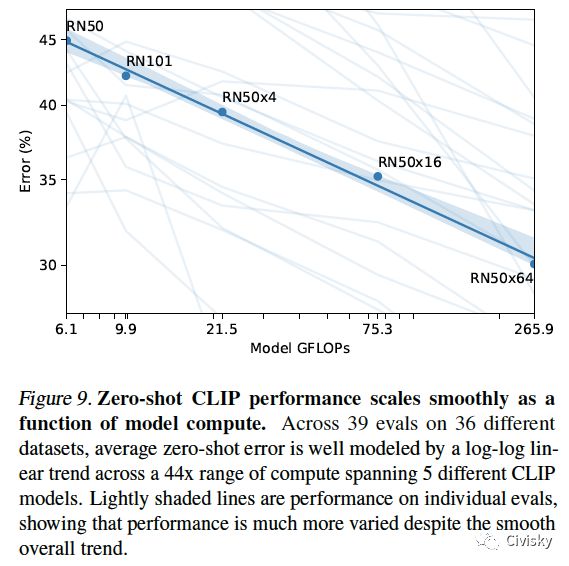
图9. Zero-shot CLIP的性能作为模型计算的函数可以平滑scales。
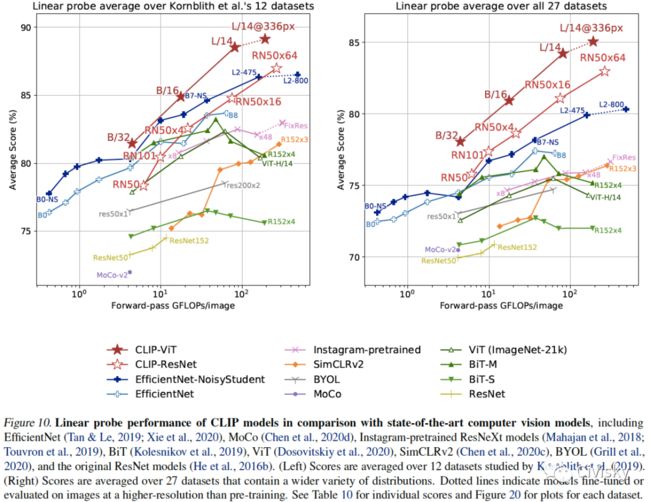
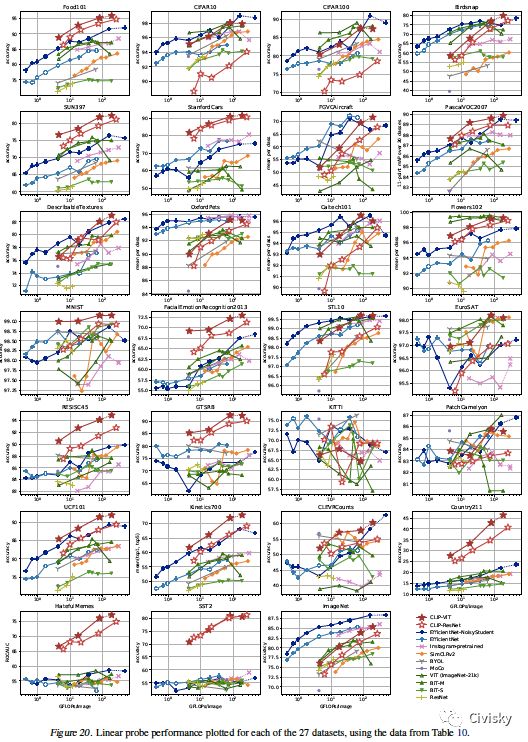
图10. CLIP模型与SOTA计算机视觉模型(包括EfficientNet、MoCo、Instagram-pretrained ResNeXt、BiT、ViT、SimCLRv2、BYOL和ResNet)性能的比较。各数据集的得分见表10,各数据集的曲线图见图20。
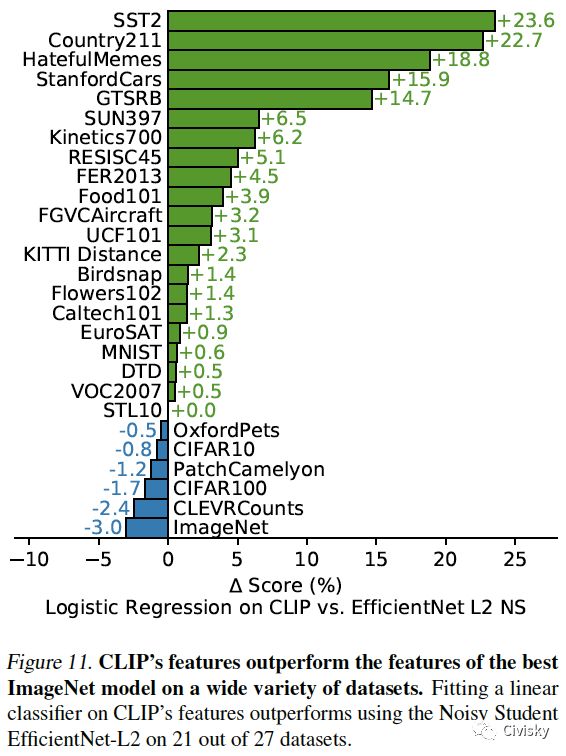
图11. 在很多数据集上,CLIP的特征都优于最佳ImageNet模型的特征。在21/27个数据集上,基于CLIP特征拟合的线性分类器的性能优于Noisy Student EfficientNet-L2的。
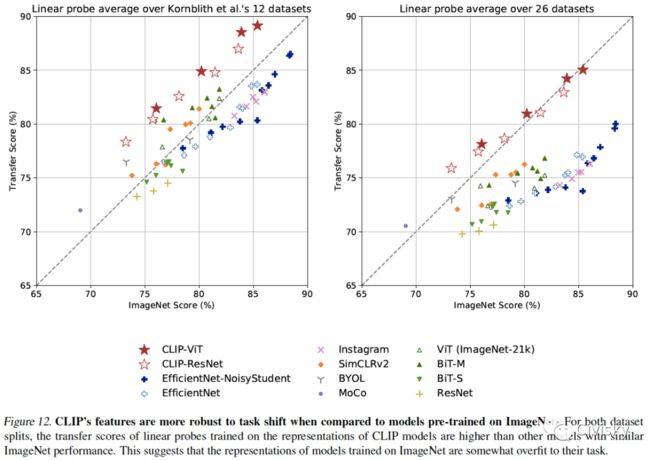
图12. 与在ImageNet上预训练的模型相比,CLIP的特征对任务迁移更具稳健性。
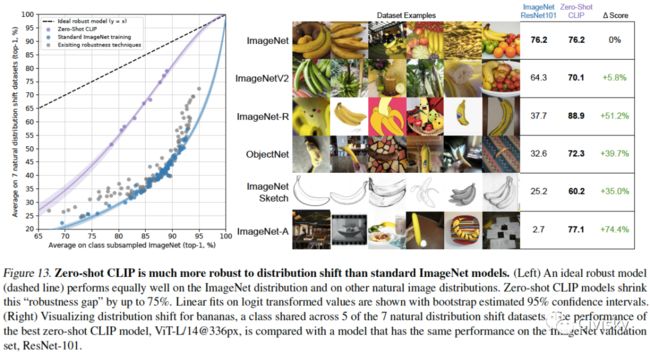
图13. 与标准ImageNet模型相比,zero-shot CLIP对于distribution shifts的稳健性更强。
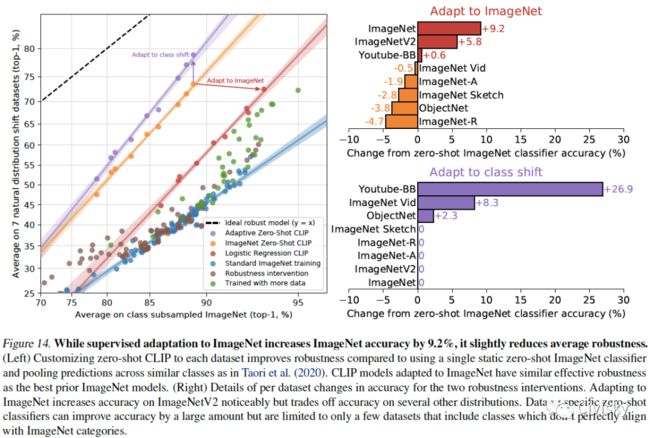
图14. 尽管对ImageNet有监督的自适应将其准确性提高了9.2%,但它略微降低了平均稳健性。
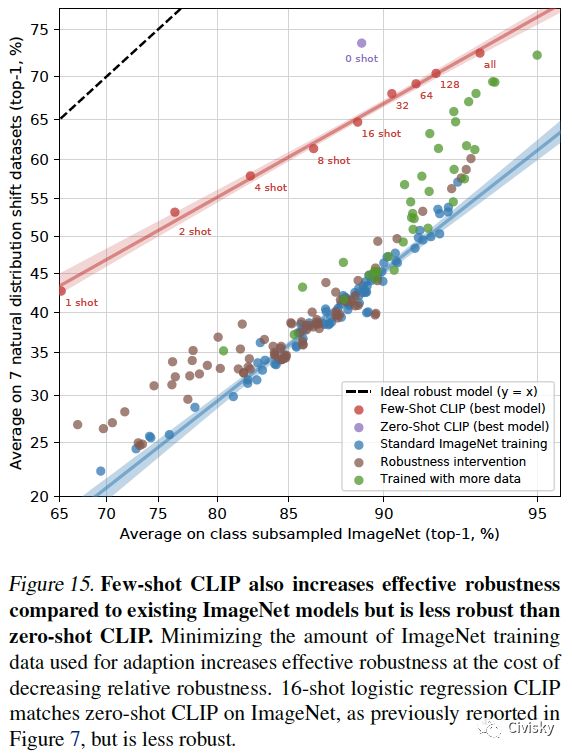
图15. 与现有的ImageNet模型相比,few-shot CLIP也增加了有效的稳健性,但比zero-shot CLIP的稳健性差一点。
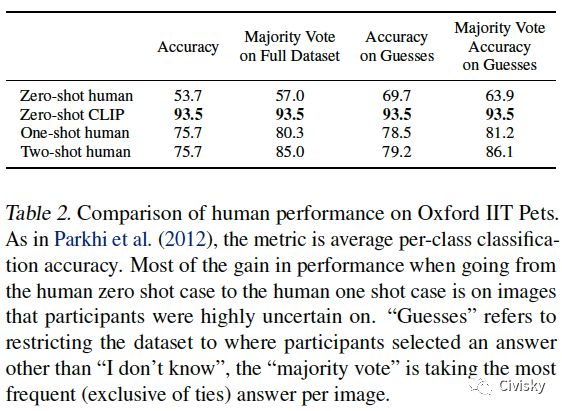
表2给出了在Oxford IIT Pets数据集上,CLIP与人类表现的比较。

图16. CLIP最困难的问题往往也是人类最困难的问题。在这里,我们根据CLIP的难度对图像类别进行排序,这是以正确标签的概率来衡量的。
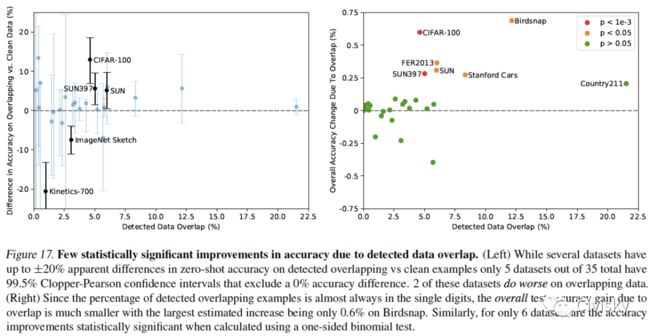
图17. 由于检测到的数据重叠,在准确性方面几乎没有统计上的显著改进。
总结
我们研究了是否有可能将NLP中任务不可知的预训练的成功迁移到另一个领域。我们发现,采用这一公式会导致类似的行为出现在计算机视觉领域,并讨论了这一研究方向的社会影响。CLIP模型在预训练时学习执行各种各样的任务,以优化它们的训练目标。这种任务学习可以通过自然语言提示来实现对许多现有数据集的zero-shot迁移。在足够的规模下,这种方法的性能可以与任务特定的监督模型相竞争,尽管仍有很大的改进空间。