SPP-Net 论文学习笔记
SPPNet 论文学习笔记
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
目前深度卷积神经网络有一个要求——固定尺寸(如 224*224)的输入图像,这可能会降低图像或任意尺寸子图的识别精度。为避免这个问题,SPPNet 采用了另一种池化策略——空间金字塔池化(spatial pyramid pooling)。SPPNet 能够无视图像的大小尺寸来生成固定长度的表达。Pyramid pooling 对目标变形也有鲁棒性。因此,SPPNet 应该能够提升所有基于 CNN 的图像识别方法。
SPPNet 在目标检测中也有很大作用。采用 SPPNet,只对整张图片计算一次特征图 feature maps,然后在任意区域(子图)中池化特征以生成固定长度的表达来训练目标检测器。
这种方法避免了重复计算卷积特征。(R-CNN 对所有区域建议都采用卷积网络,造成了大量的重复计算。)在测试阶段,SPPNet 比 R-CNN 快 24-102 倍,还能达到类似或更好的效果。
介绍
流行的 CNN 需要固定大小图片输入,限制了长宽比和尺寸。当应用于任意尺寸大小的图象时,需要经过裁剪、扭转放缩操作,但这会带来图像内容缺失和几何失真,从而导致识别精度的下降。
所以为什么 CNN 需要固定大小输入呢?
CNN 由卷积层和其后的全连接层组成。
卷积层在图像上执行滑窗操作,输出表示激活的空间排列的特征图
事实上,卷积层并不需要固定大小的图像,也可以产生任意尺寸的特征图。而另一方面,全连接层根据定义需要有固定长度的输入。因此,固定尺寸的约束只是来自于网络更深层的全连接层的。
Spatial pyramid pooling (SPP)层将去除网络固定尺寸的约束。
添加一层 SPP layer 到最后一层卷积层的顶部。
SPP layer 会池化特征,然后生成固定长度的输出,然后送入全连接层(或其他分类器)。
换句话说,是在网络的更深层中执行了信息的“聚合”(在卷积层和全连接层之间),来避免最开始的裁剪和扭曲缩放。

Spatial pyramid pooling (SPP)将图像从细到粗划分,并在其中聚合局部特征。
SPP 对深度 CNN 有许多重要的特性:
- SPP 能够无视输入尺寸,产生固定长度的输出,过去采用滑窗池化的网络则不行。
- SPP 采用多级 spatial bins(多尺寸 pooling?),而单窗池化采用单一尺寸的滑窗。
- 由于输出尺寸的灵活性,SPP 可以池化从可变尺度上提取的特征。
通过实验可以看到,这些因素提升了深度 CNN 的识别精度。
SPPNet 不光在测试时能够从任意尺寸的图像中生成表达,也允许我们在训练的时候输入各种尺寸的图片。用变尺寸的图片训练可提高尺度不变性,并降低过拟合的风险。
对四种不同的 CNN 架构应用了 SPP,有理由推测 SPP 可以提高更复杂的卷积网络架构。
SPPNet 在目标检测中也有很大优势。在 R-CNN 中,候选框通过深度卷积网络提取特征,但 R-CNN 由于对图片的成千个候选框应用 DCNN 导致特征计算太费时了。
这里,将会在整张图片上只应用一次 CNN(不管候选窗的个数是多少),然后通过 SPPNet 在特征图上提取特征。速度比 R-CNN 提升了上百倍。
SPPNet 继承了深度 CNN 特征图的威力和 SPP 在任意窗口大小上的灵活性,因此具有出色的准确性和效率。
带有 Spartial Pyramid Pooling 的深度网络
卷积层和特征图
卷积层不同于全连接层,可以接受任意尺寸的输入,采用滑动卷积核 filter,输出的长宽比与输入是大致相同的。这些输出称为 feature maps 特征图,不仅包括响应的强度,还包括响应的空间位置。
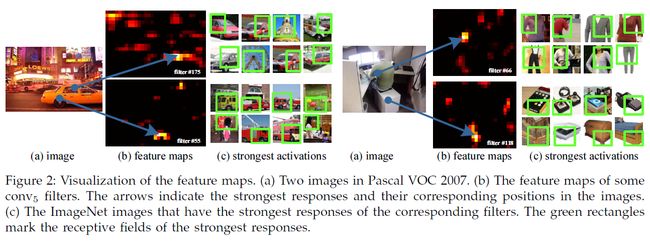
卷积核(filter 滤波器)可以被某些语义内容激活。生成 Fig2 中的特征图时被没有固定输入的尺寸。
SPP 层
卷积层可接受任意尺寸的输入,并产生可变尺寸的输入,而分类器(SVM / Softmax)或全连接层需要固定长度的向量。这样的向量可以由 Bag-of-Words 方法生成。 而 SPP 改善了 BoW,因为它可以通过在局部 spatial bins 中池化来保留空间信息。
这些 spatial bins 的大小和图像大小成比例,因此这些 bins 的数量是固定的,与图像大小无关。(过去的深度网络,滑窗池化依赖于输入的大小。)
为使深度网络应用于任意大小的图片,将最后的池化层(如 AlexNet 中最后一层卷积层之后的 pool_5 层)替换成 SPP 层。

在每个 spatial bin 中, 池化(这里使用的 max pooling )每个卷积 filter 的响应,SPP 的输出是一个 k M kM kM 维的向量。 k k k 是最后一层卷积的卷积核个数, M M M 是 bins 的个数。
利用 SPP,输入图片可以是任意大小,任意长宽比。
最粗糙 coarsest 的金字塔等级(pyramid level)下只有一个 bin 可覆盖整张图象——“全局池化”操作。全局池化操作对应于传统的 Bag-of-Words 方法。
训练网络
GPU实现(如 cuda-convnet 和 Caffe )最好运行在固定的输入图像上。描述了训练方案,利用GPU实现,同时保留空间金字塔池化。
Single-size training | 单尺寸训练
对于一个给定尺寸的图片,可以预先计算 spatial pyramid pooling 需要的 bin 的尺寸。
给定 a × a a\times a a×a 的 feature maps,如果一个 pyramid level 有 n × n n\times n n×n 个 bins,我们将这个 pooling level 当作一个窗口池化 window pooling。窗口尺寸 window size w i n = ⌈ a / n ⌉ win=\lceil a/n \rceil win=⌈a/n⌉(向上取整),步长 stride s t r = ⌊ a / n ⌋ str=\lfloor a/n \rfloor str=⌊a/n⌋(向下取整)。对于一个 l l l-level (共 l l l 级)的金字塔,我们实现 l l l 次这种池化层。之后的 全连接层会把这 l l l 个输出连接起来。

Multi-size training | 多尺寸训练
为解决训练时变尺寸的问题,考虑了一系列预定义的尺寸:224*224 和 180*180。180*180 的图片是由 224*244 缩放来的,而不是裁剪来的。所以这两者只是分辨率不同,而图片的内容和分布都一样。
对于接受 180*180 输入的网络,conv_5 输出的特征图是 a × a = 10 × 10 a\times a = 10 \times 10 a×a=10×10 的,然后采用 w i n = ⌈ a / n ⌉ win=\lceil a/n \rceil win=⌈a/n⌉ 和 s t r = ⌊ a / n ⌋ str=\lfloor a/n \rfloor str=⌊a/n⌋ 来实现每一级金字塔池化。
Spatial pyramid pooling 层对于 180-network(输入是 180*180)得到的输出长度与 224-network 的相同。因此,这个 180-network 与 224-network 每一层的参数是相同的。
换句话说,在训练时,我们通过共享参数的两个固定大小的网络实现了变输入尺寸的 SPPNet。
为了减少从一个网络(如 224 )切换到另一个网络(如 180 )的开销,我们在一个网络上训练每个完整 epoch,然后在下一个完整 epoch 切换到另一个(保持所有权重参数),如此迭代。实验发现这种多尺寸训练的收敛速度与之前单尺寸训练相似。
多尺寸训练的目的是为模拟不同的输入尺寸,同时仍利用已有的优化好的固定尺寸的实现。
除了这两种尺寸的实现,在每个 epoch 还测试了 s s s 平均采样于 [180, 240] 的 s × s s\times s s×s 变尺寸输入,
用于图像分类的 SPPNet
训练设置
- 训练数据集:ImageNet 2012
- 训练算法与 AlexNet 类似
- 图像处理:
- 图像重整为较小维是 256
- 从中心或四角裁剪为 224*224
- 水平翻转
- 改变颜色
- 两层全连接层采用dropout
- 学习率从 0.01 开始,当 error 稳定时除以 10
Baseline Network 结构
- ZF-5
- Convnet-5
- Overfeat-5/7
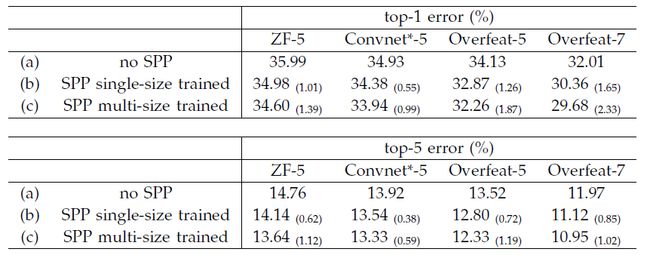
Multi-level Pooling Improves Accuracy | 多级池化提高精度
多级池化能够提高精度不仅是因为引入更多参数,而且是因为多级池化对目标对象的变形和空间布局的变化有好的鲁棒性。
Multi-size Training Improves Accuracy | 多尺寸训练提高精度
训练尺寸是 224 和 180,用在 [180, 224] 间随机尺寸测试时,仍能够得到比单尺寸训练更好的结果。
Full-image Representations Improve Accuracy | 全图像表达提高精度
缩放图片,保持长宽比,使短边为 256,将 SPPNet 应用于整张图片来计算得分。为公平比较,也评估了在中心 224*224 裁剪的单视图的精度。

这说明了维持图片内容完整的重要性,尽管这里只使用正方形图片训练,但也可以推广到其他长宽比。
通过 Table 2,3 ,发现多个视图的组合明显优于单个全图像视图,然而全图像表达仍有优点…
Multi-view Testing on Feature Maps | 特征图上的 multi-view 测试
受检测算法的启发,进一步提出了一种特征图的多视窗 multi-view 测试方法。由于 SPP 的灵活性,可以很容易地从卷积特征图中对任意尺寸的窗口(视窗)提取特征。
在测试阶段,缩放图片,保持长宽比,使短边为 s s s, s s s 表示一个预先定义好的尺寸(比如 256)。然后对整张图片计算卷积特征图。对于原图中任意的窗口,我们将其映射到特征图,然后用 SPP 对此窗口进行特征池化。池化后的特征送入全连接层来计算这个窗口的得分。

实验
略
用于目标检测的 SPPNet
只从整张图片提取一次特征图(可能在多尺度上),然后在特征图的每个候选框上应用 SPP,得到每个窗口的固定长度的表达。因为费时的卷积计算只应用一次,因此此方法运行速度飞快!
SPPNet 是从特征图中的区域提取窗口特征,而 R-CNN 是直接从图像区域上提取特征的。
这种方法可以从深度卷积特征图中提取任意窗口的特征。
检测算法
对于每个候选框应用 4-level spatial pyramid pooling 来得到特征向量。
训练设置,实现细节等。
见 section 4.1
Implementation of Pooling Bins
记 conv_5 特征图的宽度和高度为 w , h w, h w,h,对于一个有 n × n n\times n n×n 个 bins 的pyramid level,第 ( i , j ) (i, j) (i,j) 个 bin 的尺寸范围是 [ ⌊ i − 1 n w ⌋ , ⌈ i n w ⌉ ] × [ ⌊ j − 1 n w ⌋ , ⌈ j n w ⌉ ] [\lfloor \frac{i-1}{n}w\rfloor, \lceil \frac{i}{n}w \rceil] \times [\lfloor \frac{j-1}{n}w\rfloor, \lceil \frac{j}{n}w \rceil] [⌊ni−1w⌋,⌈niw⌉]×[⌊nj−1w⌋,⌈njw⌉]。简单来说,如果需要四舍五入,那么在左/上边界向下取整,在右/下边界向上取整。
Mapping a Window to Feature Maps
SPPNet 是对区域候选框对应的特征图采用 SSP,因此需要建立原图中区域候选框与特征图窗口的映射。
在我们的实现中,我们将一个窗口的角点投影到特征图中的一个像素上,使得这个角点在图像域中最接近该特征图像素的感受野中心。
In our implementation, we project the corner point of a window onto a pixel in the feature maps, such that this corner point in the image domain is closest to the center of the receptive field of that feature map pixel
由于卷积和池化层的 padding,这样的映射变得复杂。 简单起见,在实际部署中,我们对 filter 大小为 p p p 的层填充 ⌊ p / 2 ⌋ \lfloor p/2 \rfloor ⌊p/2⌋。
因此,对于以 ( x ′ , y ′ ) (x', y') (x′,y′) 为中心的响应,它在原图像中的的有效感受野中心为 ( x , y ) = ( S x ′ , S y ′ ) (x,y)=(Sx',Sy') (x,y)=(Sx′,Sy′),其中 S S S 是前面所有步长 strides 的点积。
在我们的模型中,ZF-5 的 conv_5 的 S = 16 S=16 S=16,Overfeat-5/7 的 conv_5 的 S = 12 S=12 S=12。
给定原图中的一个窗口,我们可将左(上)边界投影至特征图的 x ′ = ⌊ x / S ⌋ x'=\lfloor x/S \rfloor x′=⌊x/S⌋,右(下)边界: y ′ = ⌈ y / S ⌉ − 1 y'=\lceil y/S \rceil - 1 y′=⌈y/S⌉−1
如果 padding 不是 ⌊ p / 2 ⌋ \lfloor p/2 \rfloor ⌊p/2⌋,需要给 x x x 添加合适的偏移量。