论文阅读:Semantic Aware Attention Based Deep Object Co-segmentation(ACCV2018)
协同分割论文:Semantic Aware Attention Based Deep Object Co-segmentation(ACCV2018)
论文原文 code
目录
1.简介
2.模型结构
3.实时组协同分割(测试时)
4.缺陷
1.简介
引入注意力机制辅助深度神经网络实现协同分割,学习通道间的相关性并进行增强或抑制。在深度神经网络中,越抽象的语义信息往往被被编码在越深的层次中,不同通道包含不同的语义含义。根据这一观察结果,作者认为,通过在深层特征中应用注意力机制(如果一个channel对两图像的特征都有高响应,则强调它,并且抑制其他通道),可以选择和增强语义信息,从而实现协同分割。在处理多个输入时(组协同),可以把注意力看作是全局语义选择器,而不是成对地考虑语义关系。
贡献:
在我们的模型中,我们使用语义注意学习器关注在所有输入图像中都具有高响应的特征通道,并抑制其他响应值低的特征通道。据我们所知,这是第一次利用注意力机制进行深度图像协同分割。
作者强调该方法能在线性内完成对一组图片的分割,计算要求相比DOCS方法低很多。
我们的模型在多对象协同分割数据集中达到了最先进的性能,并且能够泛化到训练数据集中不可见的对象。
2.模型结构
网络结构主要由编码器、语义注意力学习器和解码器三部分构成。

模型概览:编码器+注意力学习器+解码器。编码器采用VGG16网络结构,解码器使用上采样方法并在每每个网络层后添加dropout层以防止过拟合。最后输出为两通道,分别代表前景和背景的概率。
不同于DOCS方法,我们没有将原始特征与处理后的特征concatenate起来,因为innovative feature往往会分割每一个“object-like stuff”,而忽略语义选择器,这与本任务的目标是相反的。我的理解是,未经注意力学习器引导的原始特征只会倾向于分割每一个突出的前景目标而不考虑多张图像的协同,不能区分出多张图片的公共目标,这与我们的期望是不符的。
注意力学习器模块提出三种结构,通道敏感注意力机制CA,混合通道敏感注意力机制FCA,通道和空间敏感注意力机制CSA。
2.1通道敏感注意力机制CA

一对图片经编码器后输出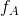 ,
,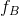 ,之后先进行全局平均池化,后接一个可学习的全连接(FC)层,获得两权重向量
,之后先进行全局平均池化,后接一个可学习的全连接(FC)层,获得两权重向量![]() ,
,![]() ∈
∈![]() ,
,![]() 的第i项代表通道i的激活值高低。
的第i项代表通道i的激活值高低。![]() 和作channel-wise 乘操作得到
和作channel-wise 乘操作得到![]() ,同理得
,同理得![]()

全局平均池化:以feature map为单位进行均值化,即一个feature map输出一个值,在这里就是一个channel平均池化为一个值,经过全局平均池化之后就得到一个维度等同于类别的特征向量。
只有在这两种输入中都有高激活的通道被相对保留和增强,在两个输入中不包含语义的其他通道将被抑制。注意这里使用sigmoid激活函数而非softmax函数。
关于sigmoid和softmax两者在这里的不同作用:Sigmoid函数会分别处理各个原始输出值,因此其结果相互独立,概率总和不一定为1,Softmax函数的输出值相互关联,其概率的总和始终为1。使用sigmoid函数能让需要强调的channel对应值接近1,而如果用softmax函数,则相关与不相关channel的权值都将低于0.5,不适用与该方法(有疑问)
2.2混合通道敏感注意力机制FCA

由于我们的目标是在两个输入中找到相同的语义信息,因此语义注意学习者对两个输入图像的输出注意权重应该是相同的,故提出另一种方式,即两个注意力权重取和后作用于原始特征

2.3通道和空间敏感注意力机制CSA

考虑到全局平均池化使部分空间信息损失,引入空间敏感注意力

3.实时组协同分割(测试时)
在DOCS论文中,实现n张为一组图片的协同分割必须分别匹配所有可能的图像对,需要O(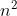 )的计算量,而这篇论文能在测试时实现O(n)计算量的一组图片的协同分割。
)的计算量,而这篇论文能在测试时实现O(n)计算量的一组图片的协同分割。
本论文中,模型训练阶段依然采用成对图片输入,端到端训练。测试时,则将整个模型分为两个模块,分别是注意力生成模块和图像分割模块。
通道敏感注意力机制CA为例,实现方法就是先计算一组图片中图片i对应的的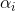 ,i=1,2...N,为了获得所有输入图像的通用语义信息,取其平均
,i=1,2...N,为了获得所有输入图像的通用语义信息,取其平均![]() ,即全局平均注意力,用这个平均向量
,即全局平均注意力,用这个平均向量![]() 与单图特征向量
与单图特征向量 进行运算(乘),即Segmentation(
进行运算(乘),即Segmentation(![]() )。
)。
从而实现线性组测试协同分割。

4.缺陷
使用该方法,如果输入不包含相同的对象,我们的模型将输出错误的结果,因为没有共同的语义。
没有实现真的组协同,训练阶段始终是一对图片的协同分割,测试阶段也只是分别计算出一组图片中每张图片对应的通道敏感注意力向量,求和取均值后替代每个单独的注意力向量。