Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information 阅读笔记
增强通道和空间信息的多人姿态估计
CVPR2019
论文链接
代码貌似尚未公开
摘要:融合多尺度特征图给姿态估计带来了重大进展,但很少有方法关注增强特征图的通道和空间信息。本文提出两个模块来增强多人姿态估计信息:① Channel Shuffle Module(CSM)对不同层次的特征图进行 channel shuffle,促进金字塔特征图间 cross-channel 信息通信。② Spatial, Channel-wise Attention Residual Bottleneck (SCARB) 利用注意力机制增强原始残差单元,自适应地突出空间和通道上下文中的特征图信息。
文章目录
- 增强通道和空间信息的多人姿态估计
- 1. Introduction
- 2. Related Work
-
- 2.1. Multi-scale Fusion Mechanism
- 2.2. Visual Attention Mechanism
- 3. Method
-
- 3.1. Revisiting Cascaded Pyramid Network级联金字塔网络
- 3.2. CSM: Channel Shuffle Module
-
- 3.2.1 Channel Shuffle Operation
- 3.3. ARB: Attention Residual Bottleneck
-
- 3.3.1 Spatial Attention
- 3.3.2 Channel-wise Attention
- 3.3.3 SCARB: Spatial, Channel-wise Attention Residual Bottleneck
- 3.3.4. CSARB: Channel-wise, Spatial Attention Residual Bottleneck
- 4. Experiments
-
- 4.2. Component Ablation Studies
-
- 4.2.1. Groups g in the Channel Shuffle Module
- 4.2.2. Attention Residual Bottleneck: SCARB and CSARB
- 4.2.3. Component Analysis
- 4.3. Comparisons on COCO minival dataset
- 4.4. Experiments on COCO test-dev dataset
-
- 4.4.1 Comparison with the state-of-the-art Methods
- 4.4.2. Human Detection Perform
- 5. Conclusions
1. Introduction
准确定位关键点仍是姿态估计任务的一个问题。首先,一方面,遮挡情况下,需要具有更大感受野的 high-level 特征图来推理不可见和遮挡的关键点,例如图1中的人体右膝。另一方面,具有更大分辨率的 low-level 特征图也有助于细化关键点,例如图1中的人体右脚踝。high-level 和 low-level 特征图间的 trade-off 是非常复杂的。其次,特征融合是动态的,且融合的特征图始终保持冗余。因此应该动态强调哪些信息对姿态估计更重要,注意力机制可以做到动态强调。根据上述分析,本文提出了一个 Channel Shuffle Module(CSM)来进一步增强所有尺度特征图间的跨通道通信;设计了一个Spatial, Channelwise Attention Residual Bottleneck (SCARB) 在空间和通道上下文中自适应增强融合的特征图。

我们进一步利用 ShuffleNet 提出的 channel shuffle 来促进不同分辨率层特征图间的通道信息通信。不同于 ShuffleNet,本文创造性地采用 channel shuffle 实现跨所有尺度的特征图间的 cross-channel 信息流。据我们所知,先前的多人姿态估计工作几乎没有使用 channel shuffle 增强特征图信息的。如图2所示,CSM 在不同分辨率特征图:Conv-2∼5 上执行,获得 shuffled 特征图:S-Conv-2∼5。CSM背后的思想是:channel shuffle 可以进一步重新校准 low-level 和 high-level 特征图间的相互依赖关系。
此外,本文提出的 SCARB)将空间和 channel-wise 注意力机制集成到原始残差单元中。如图2所示,通过堆叠SCARB,可以在空间和 channel 上下文中自适应地增强 fused pyramid feature responses。具有注意力机制的网络可以有效地自适应地突出输入特征图中最有效的信息,但多人姿态估计很少使用空间和通道方面的注意力。

本文采用 Cascaded Pyramid Network (CPN) 作为 backbone,本文贡献如下:
- 本文提出一个 Channel Shuffle Module (CSM) 来增强 low-level 和 high-level 特征图的 cross-channel 信息交流。
- 本文提出一个 Spatial, Channel-wise Attention Residual Bottleneck (SCARB) 来自适应地增强空间和通道上下文的 fused pyramid feature responses。
- COCO上实现了sota。
2. Related Work
2.1. Multi-scale Fusion Mechanism
Convolutional Pose Machines 中的序列结构实现的大感受野能隐式捕捉多个部位间的 long-range 空间关系,从而细化估计,但此过程忽略了 low-level 信息。Stacked Hourglass Networks 处理所有尺度的特征图,以捕获不同分辨率的空间关系,并采用 skip layers 来保存每个分辨率的空间信息。此外,级联金字塔网络的 GlobalNet 集成特征金字塔网络架构来保持来自不同尺度特征图的 high-level 和 low-level 信息。
2.2. Visual Attention Mechanism
视觉注意力机制在网络结构设计、图像字幕、姿态估计任务上取得了巨大成功。SENet 提出的 “Squeeze-and-Excitation (SE) 块”,通过建模 channel-wise statistics,自适应地强调 channel-wise 特征图,但SE块只考虑了通道关系,忽略了特征图中空间注意力的重要性。SCACNN 在CNN中提出了用于图像字幕的 Spatial and Channel-wise Attentions,空间和通道注意力不仅编码了特征图中的位置(即空间注意力),还介绍了重要的视觉注意力是什么(即通道注意力),但多人姿态估计中很少使用空间和通道注意力机制。Chu等人提出用于人体姿态估计的多上下文注意力模型,但尚未提及用于多人姿态估计的 spatial 和 channel-wise attention residual bottleneck。
3. Method
图2所示为方法的overview,采用CPN作为baseline来探索 CSM 和 SCARB 的有效性。
3.1. Revisiting Cascaded Pyramid Network级联金字塔网络
CPN two-stage 人体姿态估计器。首先,给定一个 human box,CPN 使用 GlobalNet 基于 FPN 架构定位一些 “simple”关键点,然后采用带有 Online Hard Keypoints Mining 机制的 RefineNet 来明确解决 “Hard” 关键点。
如图2所示,对于GlobalNet,ResNet backbone 提取的具有不同 scale 的特征图先通过 1×1 卷积调整为通道=256 的 Conv-2∼5,然后 CSM 作用于 Conv-2~5 来得到 shuffled 特征图:S-Conv-2∼5。最后S-Conv-2∼5 与原始的金字塔特征 Conv-2∼5 进行 concatenate 作为最终增强的金字塔特征,用作 U-shape FPN 架构。此外,对于RefineNet,用 SCARB 来自适应地突出 GlobalNet 传递的空间和通道上下文特征响应。
3.2. CSM: Channel Shuffle Module
深度卷积神经网络中层的深度极大丰富了特征图的 level,许多视觉任务都受益于此,但多人姿态估计任务的 low-level 和 high-level 特征图间的 trade-off 仍存在局限性。不同 level 间具有不同特征的通道信息可以相互补充加强。受此启发,本文提出 CSM 来进一步重新校准低级和高级特征图间的依赖关系。
如图3所示,Conv-3∼5 先上采样到与Conv2分辨率相同,然后 concatenate 这些特征图。之后,对concatenated 特征图执行 Channel shuffle 来融合不同 level 间互补的通道信息。然后 split 这些shuffled 特征图并下采样至原始分辨率,表示为:C-Conv-2∼5。C-Conv-2∼5可被视为不同 level 特征图的互补通道信息组成的特征。 之后执行1×1卷积进一步融合 C-Conv-2∼5,并获得shuffled features:S-Conv-2∼5,然后将S-Conv-2∼5与原始金字塔特征图Conv2∼5 进行concatenate来实现最终增强的金字塔特征表示。这些增强的金字塔特征图不仅包含来自原始金字塔特征的信息,还包含来自 shuffled 金字塔特征图的融合的跨通道信息。

3.2.1 Channel Shuffle Operation
如 ShuffleNet 所述:channel shuffle 操作可以建模为 “reshape-transpose-reshape” 过程。假设不同level 的 concatenated 特征为Ψ,Ψ的 channel 为 256∗4 = 1024,先 reshape Ψ 的 channel 为(g,c),g是 group 数,c=1024/g,然后 transpose channel 为:(c, g), 并 flatten 回 1024。channel shuffle 后,Ψ在通道上下文中完全相关。
3.3. ARB: Attention Residual Bottleneck
基于上面介绍的增强金字塔特征表示,用 Attention Residual Bottleneck 来自适应增强空间和通道上下文中的特征响应。如图4所示,ARB 分别学习空间注意力权重 β 和通道注意力权重 α。
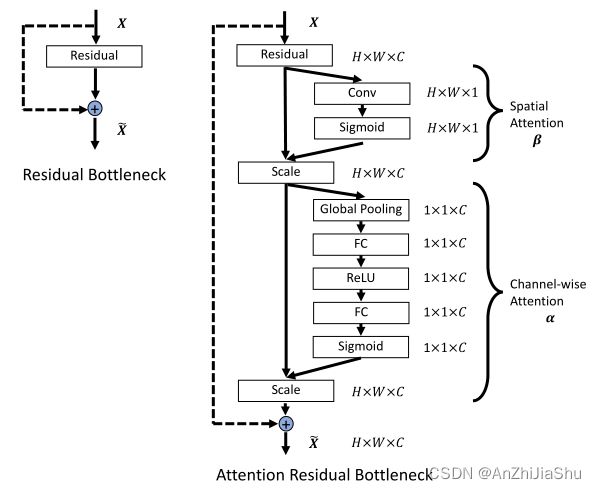
3.3.1 Spatial Attention
应用整个特征图引入不相关区域可能导致次优结果,空间注意力机制自适应地突出特征图中与任务相关的区域。
空间注意力的输入为 V ∈ R H × W × C V∈R^{H×W ×C} V∈RH×W×C ,输出 V ′ = β ∗ V , β ∈ R H × W × C , V ′ ∈ R H × W × C V'=β * V,β∈R^{H×W ×C},V'∈R^{H×W ×C} V′=β∗V,β∈RH×W×C,V′∈RH×W×C,* 表示空间元素相乘,空间注意力权重 β 由下式生成,W表示卷积操作:

最后,在输入V上 rescale 学习的空间注意力权重 β 获得输出V′:

3.3.2 Channel-wise Attention
卷积滤波器可用作一个pattern detector,卷积操作后,一个特征图的每个通道是相应卷积滤波器的特征激活,通道注意力机制可被视作自适应选择 pattern detector 的过程,这对任务更重要。
通道注意力的输入为 U ∈ R H × W × C U∈R^{H×W ×C} U∈RH×W×C ,输出 U ′ = α ∗ U , α ∈ R C , U ′ ∈ R H × W × C U'=α * U,α∈R^C,U'∈R^{H×W ×C} U′=α∗U,α∈RC,U′∈RH×W×C,* 表示通道维度元素相乘。根据SE-Net,通道注意力由 squeeze 和 excitation 两步组成。
squeeze 步骤中,先对 U 执行 global average pooling 操作,生成 channel-wise statistics: z ∈ R C z ∈ R^C z∈RC,z 的第 c 个元素由下式计算:

excitation 步骤中,对 z 执行一个带 sigmoid 的 gating 机制:
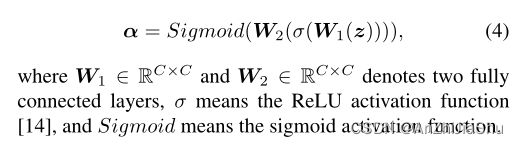
最后,在输入U上 rescale 学习的通道注意力权重 α 来获得通道通道注意力 U′ 的输出:

如图4所示,residual bottleneck 的输入: X ∈ R H × W × C X∈R^{H×W ×C} X∈RH×W×C,注意力机制作为残差模块的 non-identity 分支,且空间、通道方向注意力在与 identity branch 求和前进行。residual bottleneck 中存在两种不同的空间注意力和通道注意力实施顺序:SCARB: Spatial, Channel-wise Attention Residual Bottleneck ; CSARB: Channel-wise, Spatial Attention Residual Bottleneck。两者描述如下。
3.3.3 SCARB: Spatial, Channel-wise Attention Residual Bottleneck
先空间注意力,再通道注意力:
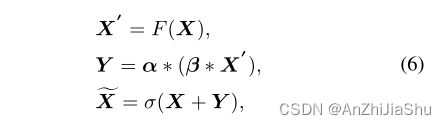
函数 F(X) 表示要在 ResNet 中学习的残差映射, X ~ \widetilde{X} X 是具有增强空间和通道信息的输出注意力特征映射。
3.3.4. CSARB: Channel-wise, Spatial Attention Residual Bottleneck
先通道再空间:
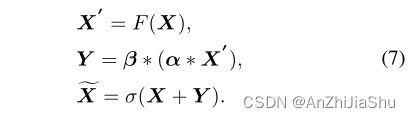
SCARB 和 CSARB 在消融实验中进行研究。
4. Experiments
4.2. Component Ablation Studies
在COCO minival dataset 上研究 Channel Shuffle Module 和 Attention Residual Bottleneck。
4.2.1. Groups g in the Channel Shuffle Module
表1所示为实验结果,g=4 时结果最好:

4.2.2. Attention Residual Bottleneck: SCARB and CSARB
结果如表2所示,SCARB的结果最好:

4.2.3. Component Analysis
根据表3结果所示,最终选择 CSM-4+SCARB:

4.3. Comparisons on COCO minival dataset
结果如表4所示:


4.4. Experiments on COCO test-dev dataset
4.4.1 Comparison with the state-of-the-art Methods


4.4.2. Human Detection Perform

5. Conclusions
本文使用 top-down pipeline 处理多人姿态估计。本文提出 CSM 来促进所有尺度特征图间的跨通道信息通信,设计了 SCARB 以在空间和通道上下文中自适应地突出融合的金字塔特征图。