igraph入门教程
python-igraph的基本操作
参考:python-igraph官网教程
ps:
- 在jupyter上运行后直接导出的md,可能有点乱码
- 部分翻译靠的是机翻,勿细究
- 更多的教程在igraph的官网上,链接已给出
import igraph
print(igraph.__version__)
0.9.6
from igraph import *
g = Graph()
g
print(g)
IGRAPH U--- 0 0 --
g.add_vertices(3) # 添加节点
g.add_edges([(0,1), (1,2)]) # 添加边
# g.add_edges((5, 0)) 添加多的边会引发报错
g.add_edges([(2, 0)])
g.add_vertices(3)
g.add_edges([(2, 3), (3, 4), (4, 5), (5, 3)])
print(g)
IGRAPH U--- 6 7 --
+ edges:
0--1 1--2 0--2 2--3 3--4 4--5 3--5
# !pip install pycairo or cairocffi # 安装可视化相关包
g.get_eid(2, 3)
3
# plot(g,layout="kk") 可视化出来
g.delete_edges(3) # 删除变的联系
summary(g) # 输出节点和边的数量
IGRAPH U--- 6 6 --
可视化需要安装相关依赖包
plot(g,layout="kk") # 可视化,以"kk"布局为例
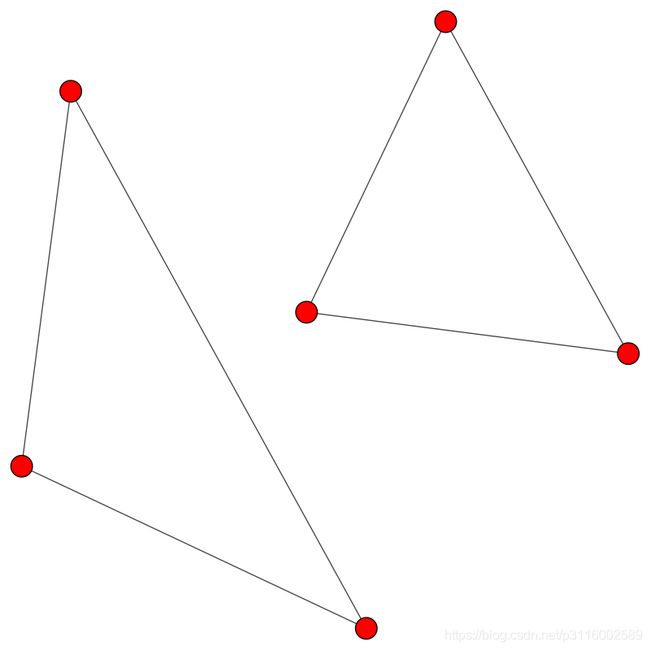
g = Graph.Tree(127, 2) # Tree ()生成一个规则的树图
summary(g)
IGRAPH U--- 127 126 --
# plot(g,layout="kk") # 可视化
g2 = Graph.Tree(127, 2)
g2.get_edgelist() == g.get_edgelist() # 判断是否相同
True
g2.get_edgelist()[0:10] # 输出边列表
[(0, 1),
(0, 2),
(1, 3),
(1, 4),
(2, 5),
(2, 6),
(3, 7),
(3, 8),
(4, 9),
(4, 10)]
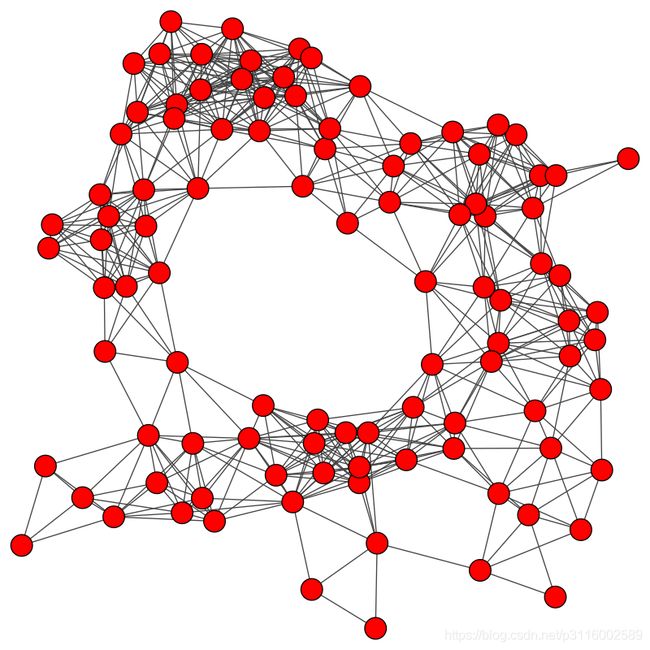
g = Graph.GRG(100, 0.2) # 另一种算法生成图形
plot(g,layout="kk")
g = Graph([(0,1), (0,2), (2,3), (3,4), (4,2), (2,5), (5,0), (6,3), (5,6)]) # 手动生成一个网络
g.vs # 每个图对象包含两个称为 vs 和 es 的特殊成员,分别代表所有顶点和所有边的属性
# 设置节点和边的属性
g.vs["name"] = ["Alice", "Bob", "Claire", "Dennis", "Esther", "Frank", "George"]
g.vs["age"] = [25, 31, 18, 47, 22, 23, 50]
g.vs["gender"] = ["f", "m", "f", "m", "f", "m", "m"]
g.es["is_formal"] = [False, False, True, True, True, False, True, False, False]
g.es[0].attributes() # 通过attributes()函数查看一个边的所有属性
g.vs[0].attributes() # 通过attributes()函数查看一个节点的所有属性
{'name': 'Alice', 'age': 25, 'gender': 'f'}
g.es[0]["is_formal"] = True # 类似字典,也可通过关键字直接查看
g["date"] = "2009-01-10" # Graph对象本身也可以作为对象使用
print(g["date"])
2009-01-10
g.vs[3]["foo"] = "bar" # 添加一个新属性
g.vs["foo"] # 查看属性
[None, None, None, 'bar', None, None, None]
del g.vs["foo"] # 删除属性
# g.vs["foo"] # 查看会报错
图的结构和性质的计算
plot(g,layout="kk")

g.degree() # 图的顶点度数计算
[3, 1, 4, 3, 2, 3, 2]
如果这个图是有向的,可以使用 g.degree (mode = “ in”)和 g.degree (mode = “ out”)分别计算进度和出度。如果只想计算一个顶点子集的度数,你也可以传递一个顶点 ID 或顶点 ID 列表到 degree ()
g.degree([2,3,4]) # 只计算ID为2,3,4节点的度数
[4, 3, 2]
除了度,igraph 还包括内置的例程来计算许多其他中心性属性,包括顶点和边界中间性(Graph.betweenness () ,Graph.edge _ betweenness ())或者 Google 的 PageRank (graph.PageRank ())等等
g.edge_betweenness() # 返回边之间
[6.0, 6.0, 4.0, 2.0, 4.0, 3.0, 4.0, 3.0, 4.0]
g.betweenness() # 返回节点之间
[5.0, 0.0, 5.5, 1.5, 0.0, 2.5, 0.5]
g.get_edgelist() # 返回边的连接情况
[(0, 1), (0, 2), (2, 3), (3, 4), (2, 4), (2, 5), (0, 5), (3, 6), (5, 6)]
ebs = g.edge_betweenness() # 通过 Python找出哪些边具有最高的中介中心性:
max_eb = max(ebs)
[g.es[idx].tuple for idx, eb in enumerate(ebs) if eb == max_eb]
[(0, 1), (0, 2)]
[(0, 1), (0, 2)]
ecount = g.ecount() 统计边的数目
vcount = g.vcount() 统计节点数目
# g.vcount()#统计节点数目
# idx = list(range(g.vcount())) # 转换成列表
# g.vs["name"] = list(map(str,idx)) # 将节点ID作为名字
plot(g,vertex_label=g.vs["name"],bbox=(0,0,300, 300)) # 可视化节点,设置节点标签与图的大小
# plot(g,vertex_label=g.vs["gender"],bbox=(0,0,300, 300))
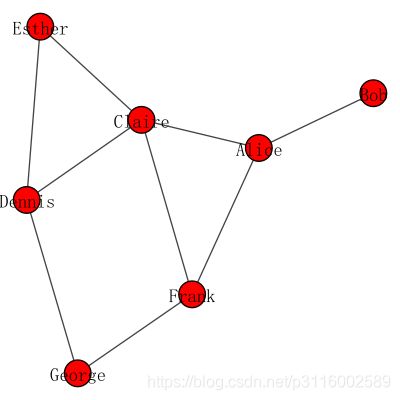
edgelist = g.get_edgelist() # 打印边的连接信息
for edge in edgelist:
print(edge)
(0, 1)
(0, 2)
(2, 3)
(3, 4)
(2, 4)
(2, 5)
(0, 5)
(3, 6)
(5, 6)
g.vs.degree()
g.es.edge_betweenness()
g.vs[2].degree() # 也可以通过索引来单独查询
4
根据顶点和边的属性进行查询
Select ()是 VertexSeq 的一种方法,它的唯一目的是根据各个顶点的特性过滤一个 VertexSeq
g.vs.select(_degree=g.maxdegree())["name"] # 查询最大中心性的节点并返回
['Claire']
seq = g.vs.select(None) # 如果第一个位置参数为 None,则返回一个空序列
graph = Graph.Full(10) # 新建一个网络图
summary(graph)
IGRAPH U--- 10 45 --
only_odd_vertices = graph.vs.select(lambda vertex: vertex.index % 2 == 1) # 根据条件返回节点id
len(only_odd_vertices) # 大小
5
如果第一个位置参数是可迭代的(例如,一个列表、一个生成器或者任何可以迭代的东西) ,它必须返回整数,这些整数将被视为当前顶点集(不一定是整个图)的索引。只有那些匹配给定索引的顶点才会包含在筛选后的顶点集中。
seq = graph.vs.select([2, 3, 7]) # 选择节点
len(seq)
3
[v.index for v in seq]
[2, 3, 7]
seq = seq.select([0, 2])
[v.index for v in seq]
[2, 7]
# seq = graph.vs.select([2, 3, 7, "foo", 3.5]) # 现在不会被忽略了?提示报错
可以使用关键字参数根据顶点的属性或结构属性筛选顶点。
每个关键字参数的名称最多应由两部分组成:属性或结构属性的名称和筛选操作符。
| 关键字参数 | 意义 |
|---|---|
| name_eq | 属性值必须等于关键字参数的值 |
| name_ne | 属性值不得等于关键字参数的值 |
| name_lt | 属性值必须小于关键字参数的值 |
| name_le | 属性值必须小于或等于关键字参数的值 |
| name_gt | 属性值必须大于关键字参数的值 |
| name_ge | 属性值必须大于或等于 关键字参数的值 |
| name_in | 属性值必须包含在关键字参数的值中,在这种情况下必须是一个序列 |
| name_notin | 属性值不得包含在关键字参数的值中,在这种情况下必须是序列 |
seq = g.vs.select(age_lt=30) # 筛选社交网络中30岁以下的人
[v.index for v in seq] # 返回相关节点的id
[0, 2, 4, 5]
seq1 = g.vs(age_lt=30)# 还可以省略select
[v.index for v in seq1]
[0, 2, 4, 5]
还有一些特殊的结构属性用于选择边:
seq2 = g.vs(_degree_gt=2) # 度数大于2的顶点
[v.index for v in seq2]
[0, 2, 3, 5]
seq3 = g.es.select(_source=2) # 选择来自节点序号=2的所有边
[v.index for v in seq3]
[1, 2, 4, 5]
seq4 = g.es.select(_within=[2,3,4]) # 选择了 Claire (节点2)、 Dennis (节点3)和 Esther (节点4)之间的所有边
[v.index for v in seq4]
[2, 3, 4]
_between 接受一个由两个 VertexSeq 对象或包含顶点索引或顶点对象的列表组成的元组,并选择起源于其中一个集合并终止于另一个集合的所有边。
men = g.vs.select(gender="m") # 男性节点集合
women = g.vs.select(gender="f") # 女性节点集合
seq5 = g.es.select(_between=(men, women)) # 男性和女性之间的边的集合
[v.index for v in seq5] # 但我怎么知道边的序号是多少?
[0, 2, 3, 5, 6]
寻找具有某些属性的单个节点或边
claire = g.vs.find(name="Claire") # 查找名字为claire的节点
type(claire) # 类型
igraph.Vertex
claire.index # 返回节点ID
2
按名称查找节点属性
g.vs.find("Dennis").degree() # 同下等价
g.degree("Dennis")
3
把一个图表当作一个邻接矩阵
g.get_adjacency()
Matrix([[0, 1, 1, 0, 0, 1, 0], [1, 0, 0, 0, 0, 0, 0], [1, 0, 0, 1, 1, 1, 0], [0, 0, 1, 0, 1, 0, 1], [0, 0, 1, 1, 0, 0, 0], [1, 0, 1, 0, 0, 0, 1], [0, 0, 0, 1, 0, 1, 0]])
g.vcount()#统计节点数目
idx = list(range(g.vcount())) # 转换成列表
g.vs["name"] = list(map(str,idx)) # 将节点ID作为名字
plot(g,vertex_label=g.vs["name"],bbox=(0,0,300, 300)) # 矩阵结合图一起看更好理解
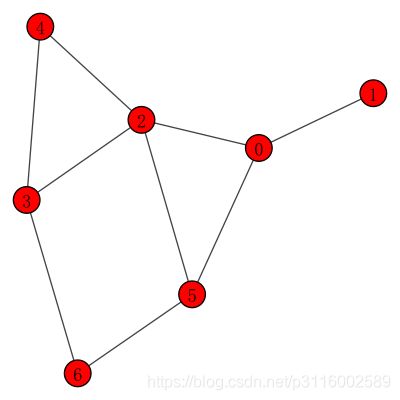
布局和绘图
图的可视化需要安装相关的包,如 Cairo 等。
| 方法名称 | 关键字 | 算法说明 |
|---|---|---|
| layout_circle | circle, circular | 将顶点放在圆上的确定性布局 |
| layout_drl | drl | 大图的分布式递归布局算法 |
| layout_fruchterman_reingold | fr | Fruchterman-Reingold 力导向算法 |
| layout_fruchterman_reingold_3d | fr3d, fr_3d | 三个维度的 Fruchterman-Reingold 力导向算法 |
| layout_grid_fruchterman_reingold | grid_fr | Fruchterman-Reingold 力导向算法,用于大图的网格启发式算法 |
| layout_kamada_kawai | kk | Kamada-Kawai 力导向算法 |
| layout_kamada_kawai_3d | kk3d, kk_3d | 三维Kamada-Kawai力导向算法 |
| layout_lgl | large, lgl, large_graph | 大图的大图布局算法 |
| layout_random | random | 完全随机放置顶点 |
| layout_random_3d | random_3d | 在 3D 中完全随机地放置顶点 |
| layout_reingold_tilford | rt, tree | Reingold-Tilford 树布局,对(几乎)树状图很有用 |
| layout_reingold_tilford_circular | rt_circul ar tree | 具有极坐标转换后的 Reingold-Tilford 树布局,对(几乎)树状图很有用 |
| layout_sphere | sphere, spherical, circular_3d | 将顶点均匀地放置在球体表面的确定性布局 |
layout = g.layout("kk") # 可视化,有布局才能可视化
plot(g, layout=layout)
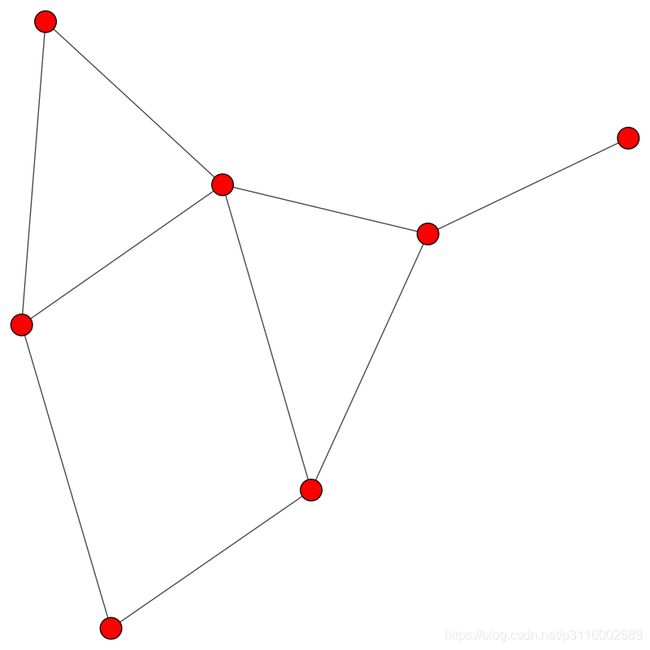
g.vs["name"] = ["Alice", "Bob", "Claire", "Dennis", "Esther", "Frank", "George"] # 改回名称
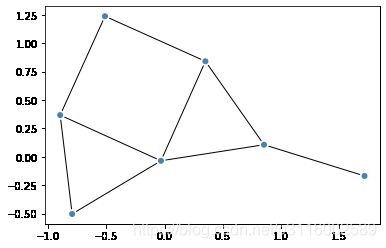
import matplotlib.pyplot as plt # 使用 matplotlib 作为绘图引擎,创建一个坐标轴并使用目标参数
fig, ax = plt.subplots()
plot(g, layout="kk", target=ax)

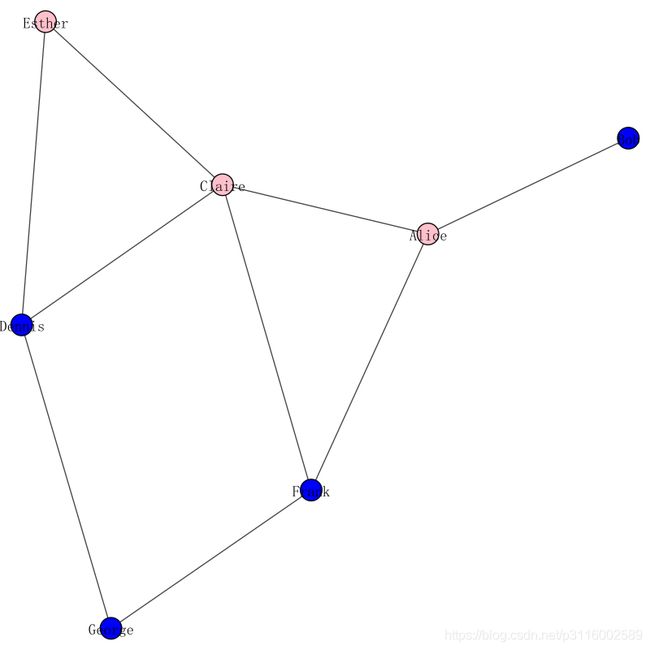
g.vs["label"] = g.vs["name"]
color_dict = {"m": "blue", "f": "pink"}
g.vs["color"] = [color_dict[gender] for gender in g.vs["gender"]] # 通过性别设置颜色属性
plot(g, layout=layout, bbox=(300, 300), margin=20)

fig, ax = plt.subplots()
plot(g, layout="kk", bbox=(300, 300), margin=20, target=ax) # matplotlib version
color_dict = {"m": "blue", "f": "pink"}
plot(g, layout=layout, vertex_color=[color_dict[gender] for gender in g.vs["gender"]])
将图的可视化表示的属性与图本身分开
visual_style = {}
visual_style["vertex_size"] = 20
visual_style["vertex_color"] = [color_dict[gender] for gender in g.vs["gender"]]
visual_style["vertex_label"] = g.vs["name"]
visual_style["edge_width"] = [1 + 2 * int(is_formal) for is_formal in g.es["is_formal"]]
visual_style["layout"] = layout
visual_style["bbox"] = (300, 300)
visual_style["margin"] = 20
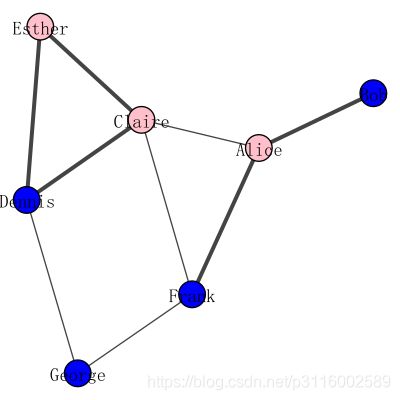
plot(g, **visual_style)
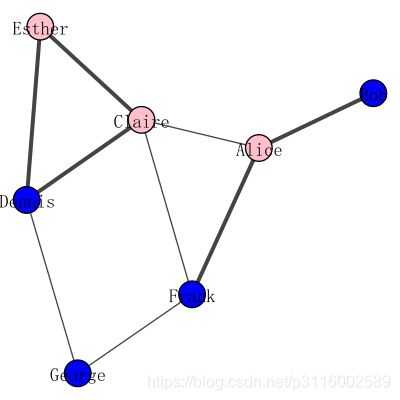
最后的图显示了正式关系的粗线条,而非正式关系的细线条
控制可视化图的节点的属性
| 属性名称 | 关键字参数 | 目的 |
|---|---|---|
| color | vertex_color | 顶点的颜色 |
| label | vertex_label | 顶点标签 |
| label_angle | vertex_label_angle | 顶点标签在围绕顶点的圆上的位置。这是一个以弧度为单位的角度,零属于顶点的右侧。 |
| label_color | vertex_label_color | 顶点标签的颜色 |
| label_dist | vertex_label_dist | 顶点标签与顶点本身的距离,相对于顶点大小 |
| label_size | vertex_label_size | 顶点标签的字体大小 |
| order | vertex_order | 顶点的绘制顺序。将首先绘制具有较小顺序参数的顶点。 |
| shape | vertex_shape | 顶点的形状。已知的形状有: rectangle、circle、hidden、 triangle-up、triangle-down。也接受几个别名,请参阅 drawing.known_shapes。 |
| size | vertex_size | 顶点的大小(以像素为单位) |
控制可视化图的边的属性
| 属性名称 | 关键字参数 | 目的 |
|---|---|---|
| color | edge_color | 边缘颜色 |
| curved | edge_curved | 边缘的曲率。正值对应于 CCW 方向弯曲的边缘,负值对应于顺时针 (CW) 方向弯曲的边缘。零代表直边。True 被解释为 0.5,False被解释为 0。这对于使多条边可见很有用。另请参阅 的 autocurve关键字参数 plot()。 |
| arrow_size | edge_arrow_size | 如果图形是有向的,则边上箭头的大小(长度),相对于 15 像素。 |
| arrow_width | edge_arrow_width | 如果图形是有向的,则边缘上箭头的宽度,相对于 10 像素。 |
| width | edge_width | 边缘的宽度(以像素为单位) |
plot()函数的关键字及其作用
| 关键字参数 | 目的 |
|---|---|
| autocurve | 是否在具有多条边的图中自动确定边的曲率。默认True用于边数少于 10.000 的图形,False否则。 |
| bbox | 图的边界框。这必须是一个包含所需绘图宽度和高度的元组。默认绘图宽 600 像素,高 600 像素。 |
| layout | 要使用的布局。它可以是 的实例Layout、包含 XY 坐标的元组列表或布局算法的名称。默认为auto,它根据图形的大小和连通性自动选择布局算法。 |
| margin | 绘图的顶部、右侧、底部和左侧边距(以像素为单位)。这个参数必须是一个列表或元组,如果你指定一个少于四个元素的列表或元组,它的元素将被重用。 |
保存绘图
igraph可用于通过要求plot() 函数将绘图保存到文件中而不是在屏幕上显示来创建出版质量的绘图。这可以简单地通过将目标文件名作为图形本身之后的附加参数传递来完成。首选格式是从扩展中推断出来的。igraph可以保存为 Cairo 支持的任何文件,包括 SVG、PDF 和 PNG 文件。如果您愿意,稍后可以将 SVG 或 PDF 文件转换为 PostScript ( .ps) 或 Encapsulated PostScript ( .eps) 格式,而 PNG 文件可以转换为 TIF ( .tif)
plot(g, "social_network.pdf", **visual_style)
igraph读取文件
igraph提供了读取最常见图形格式并将Graph对象保存到符合这些格式规范的文件中的功能。下表总结了igraph可以读取或写入的格式
| 格式 | 简称 | 读者方法 | 写法 |
|---|---|---|---|
| 邻接表 | lgl | Graph.Read_Lgl() | Graph.write_lgl() |
| 邻接矩阵 | adjacency | Graph.Read_Adjacency() | Graph.write_adjacency() |
| DIMACS | dimacs | Graph.Read_DIMACS() | Graph.write_dimacs() |
| DL | dl | Graph.Read_DL() | 尚不支持 |
| Edge list | edgelist, edges, edge | Graph.Read_Edgelist() | Graph.write_edgelist() |
| GraphViz | graphviz, dot | 尚不支持 | Graph.write_dot() |
| GML | gml | Graph.Read_GML() | Graph.write_gml() |
| GraphML | graphml | Graph.Read_GraphML() | Graph.write_graphml() |
| Gzipped GraphML | graphmlz | Graph.Read_GraphMLz() | Graph.write_graphmlz() |
| LEDA | leda | 尚不支持 | Graph.write_leda() |
| Labeled edgelist | ncol | Graph.Read_Ncol() | Graph.write_ncol() |
| Pajek format | pajek, net | Graph.Read_Pajek() | Graph.write_pajek() |
| Pickled graph | pickle | Graph.Read_Pickle() |