TVM(端到端深度学习编译器)简介
TVM-算子编译器前后端
- 前言
- TVM
-
- 出现背景
- TVM是什么
- 为什么用TVM,TVM解决了什么
-
- 当前问题:
- TVM解决了
- TVM如何解决
-
- 具体实现手段
- 如何设计搜索空间Search Space
- 优化策略
-
- 图优化 - 算子融合
- 图优化 - Layout Transform
- 张量优化 - 矩阵乘法 GEMM
- 张量优化 - 调度算法
- 张量优化 - 搜索空间
- 性能对比
- 挑战 && TVM能做的
- VTA(Versatile Tensor Accelerator)
- reference
前言
深度学习high level已经内卷,
那么深度学习+编译器呢?
在此向陈天奇大佬致敬。
注:本文为博主的学习笔记,所用的图都是截取的,侵权联系删。
TVM
出现背景
传统深度学习框架:
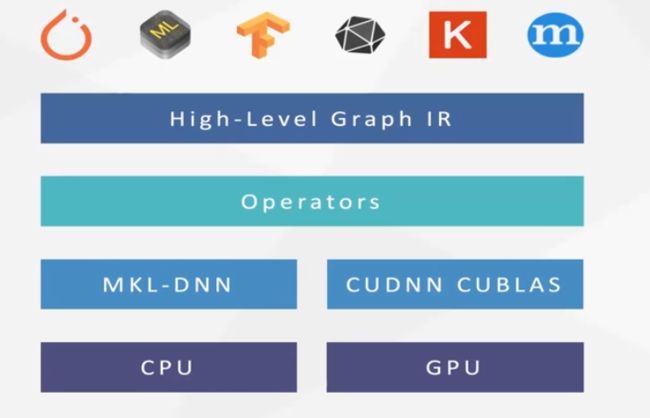
对上图的补充说明:
- Graph IR:几层的Conv2d, Relu
- Operators: 比如矩阵乘法
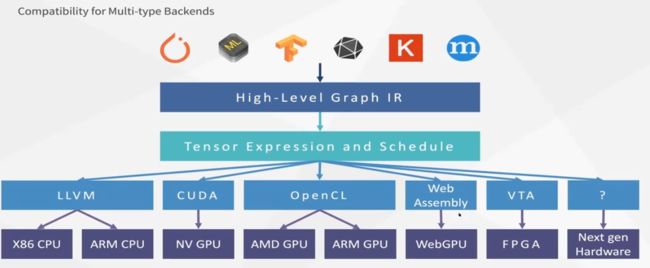
TVM栈如下图:

把Operators换成了Tensor Expr, 生成代码后交给LLVM,CUDA编译器。即,通过编译的方式去解决,优点是通用性强,可部署到任何有编译器的环境中(比如手机、汽车)。
AutoTVM:是learning based optimization, 用机器学习去优化的ML编译器
有了Tensor Expression, TVM会去声明一个计算应该怎么做,然后再通过Schedule调度优化,之后就可以得到结果。
因此不依赖于计算库。
当有新算子时,对于TVM只是新加了Schedule,对此新算子进行适配对于TVM而言很高效。
TVM是什么
深度学习代码自动生成方法,自动的为各种硬件生成可部署的优化代码。
TVM是由华盛顿大学在读博士陈天奇等人提出的深度学习自动代码生成方法,该技术能自动为大多数计算硬件生成可部署优化代码,其性能可与当前最优的供应商提供的优化计算库相比,且可以适应新型专用加速器后端
TVM:End to End learning-based deep learning compiler
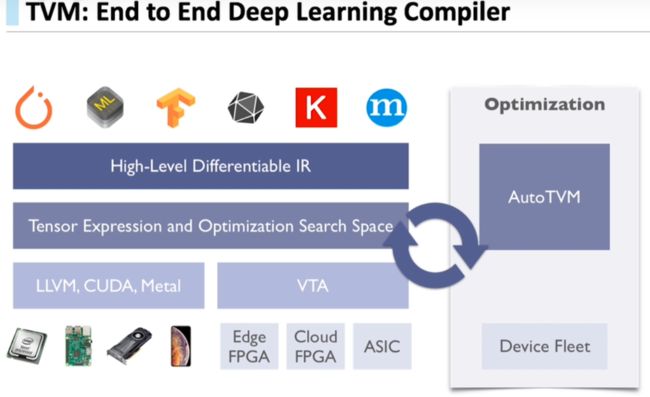
intermediate representation (IR).
注:上图中的VTA,会在本文的后面介绍
为什么用TVM,TVM解决了什么

当前问题:
若针对不同的硬件去设计算子,
- 不同的硬件用自己专有的一套库(比如Nvidia用cuDNN)去设计算子,
- 当需要组合或优化算子时,如上图把 分红+绿色 => 蓝色 时,现在库中没有此蓝色算子,就需要联系厂商或只能手写了
那么工作量很大。
尤其是当算子不断扩展,硬件不断更新变多时,此问题很大。
TVM解决了
TVM尝试解决底层代码自动生成的问题。
TVM如何解决
基于机器学习的程序优化器

具体实现手段
把算子用 Tensor Expression 表示

上面的搜索空间,需要补充一下:

对搜索空间的更新手段:
 上图中的c是IR。
上图中的c是IR。
而f(x) 理解为cost。
IR有对应的cost。
通过不断迭代优化,最终可对某个Expression针对某个硬件得到较优的IR。
如何设计搜索空间Search Space
基本目标:把相同的Tensor Expression 映射到不同的硬件上。
对于cpu、gpu而言已经有了一些经验,那么关键是如何针对TPU去设计SS.
说到TPU,那么需要先了解下compute primitives:
比如intel和ARM可以支持vector级别的计算即在一个寄存器中一次读多个浮点数然后运算,优点是加速,当然代价是我们需要设计出program去支持这种级别的计算。
而NPU/TPU的指令都是tensor级别的,可以直接做矩阵乘法或矩阵向量乘法。
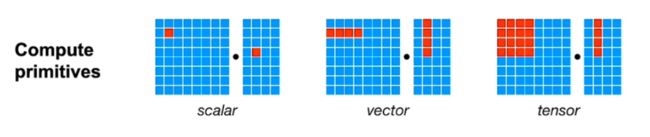
挑战是:如何设计出一个系统,可以支持那么多的张量指令。
这里引入一个张量化Tensorization的概念
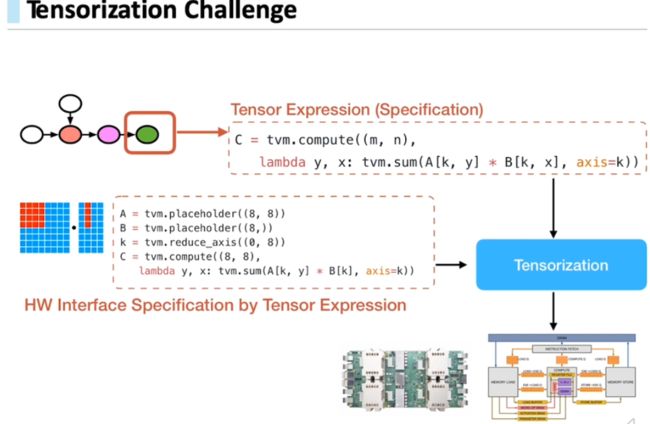 如上图,希望:不仅仅Tensor Expression去表示高层的计算,也可以表示底层的硬件本身的特性。即,张量化的过程是:同时揭露高层张量表达式 和 底层硬件的特性描述,来把高层的表示映射到底层硬件所可以支持的指令上。
如上图,希望:不仅仅Tensor Expression去表示高层的计算,也可以表示底层的硬件本身的特性。即,张量化的过程是:同时揭露高层张量表达式 和 底层硬件的特性描述,来把高层的表示映射到底层硬件所可以支持的指令上。
至此,使得TVM可以支持cpu、gpu、tpu等等
优化策略
图优化 - 算子融合
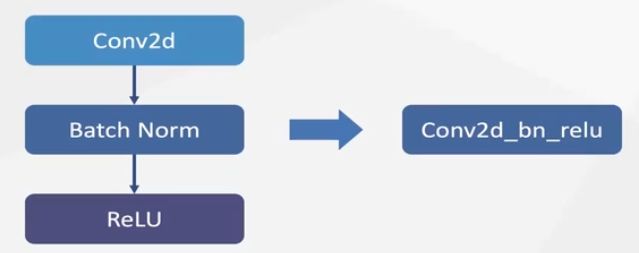
合成一个算子后,可以用cache,提高cache命中率(即尽可能从cache读取,而非从主存中读取)。
图优化 - Layout Transform

张量优化 - 矩阵乘法 GEMM

张量优化 - 调度算法
 上图箭头右方的代码是优化后的代码。
上图箭头右方的代码是优化后的代码。
Schedule不会带来正确性的问题,只是性能上的优化。
张量优化 - 搜索空间

上图中的搜索空间大小是334.
[16,32,64], [16, 32, 64], [1,2,4,8]
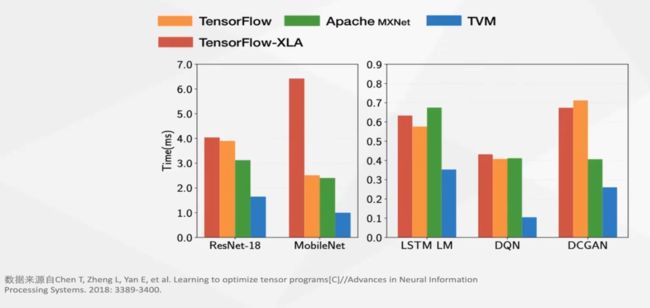
性能对比
挑战 && TVM能做的
VTA(Versatile Tensor Accelerator)
VTA不仅仅是一个独立的加速器,它其实是一个端到端的解决方案,包含了驱动程序、JIT运行时以及基于TVM的优化编译器栈。
端(AI框架)到端(硬件)的解决方案;
high level的加速,图优化器,tensor优化器;

目标:
simple HardWare, smart Software.
硬件更加细粒度,高自由;对软件有更高的要求。
比如,内存使用。
cpu不需要对内存进行管理。
gpu需要对shared Mem进行管理使用。
自动代码生成:
可以建立搜索空间存储手动的优质代码,然后从此空间里拿代码为自动代码生成服务。
reference
https://www.bilibili.com/video/BV1kJ411X72Y?from=search&seid=13643575601862258075
https://www.bilibili.com/video/BV1T5411W7o8