pytorch构建deeplabv3+
DeepLab v3+ 是DeepLab语义分割系列网络的最新作,其前作有 DeepLab v1,v2, v3, 在最新作中,Liang-Chieh Chen等人通过encoder-decoder进行多尺度信息的融合,同时保留了原来的空洞卷积和ASSP层, 其骨干网络使用了Xception模型,提高了语义分割的健壮性和运行速率。其在Pascal VOC上达到了 89.0% 的mIoU,在Cityscape上也取得了 82.1%的好成绩,下图展示了DeepLab v3+的基本结构:
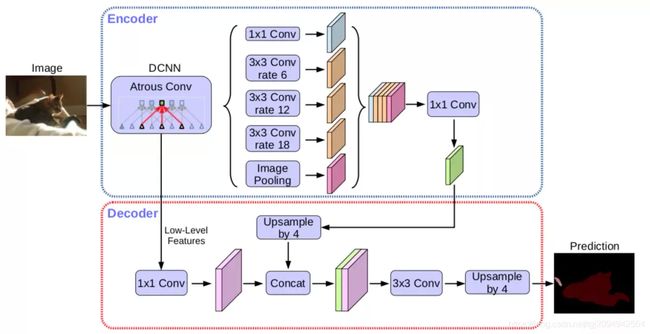
其实在DCNN中主要是做一个特征提取,至于采用哪个网络做backbone具体问题具体对待,在这里我才用的是mobilenetv2(只是将deepwise_conv中添加了dilation, 添加空洞卷积是为了增大感受野)
网络结构分为Encode部分和decoder部分
先看encoder部分:
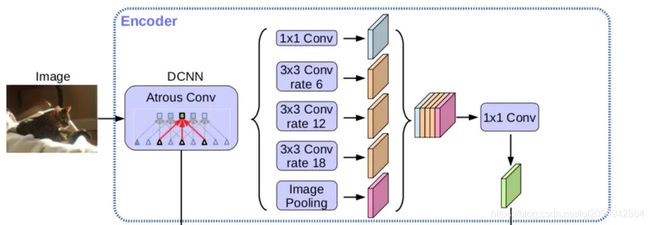
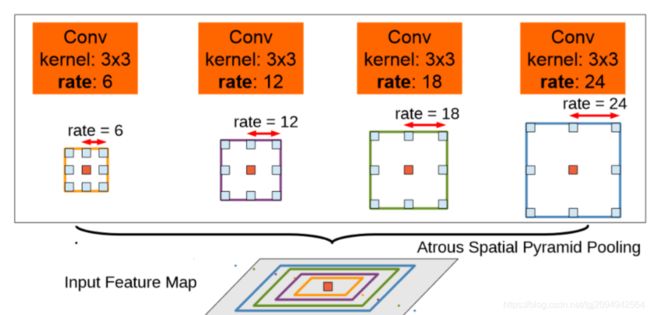
接在DCNN后面的实际上就是一个ASPP结构(采用不同的采样率来对特征图做空洞卷积),然后再将对应的结果进行拼接,需要注意的是传入ASPP结构的是DCNN得到的高层特征图image Pooling部分其实会改变特征图的尺寸,所以可以通过使用双线插值(为什么采用双线插值,因为简单)或者其他方式保证经过ASPP结构的各个特征图尺寸相同,最后再进行拼接
再看decoder部分
decoder部分首先会对传入的低层特征图进行通道调整,然后与encoder传入的特征图进行拼接,注意encoder传入的特征图需要经过上采样处理(维持与低层特征图相同的尺寸),最后输出部分只需要将尺寸还原到输入图片的尺寸就行了
import torch
import torch.nn as nn
import torch.functional as F
class ASPP(nn.Module):
def __init__(self, feature, atrous):
super(ASPP, self).__init__()
self.feature = feature
self.Conv1 = _Deepwise_Conv(in_channels=feature.size()[1], out_channels=256, use_bias=False)
self.Conv_rate1 = _Deepwise_Conv(in_channels=feature.size()[1], out_channels=256, rate=atrous[0],
padding=atrous[0], use_bias=False)
self.Conv_rate2 = _Deepwise_Conv(in_channels=feature.size()[1], out_channels=256, rate=atrous[1],
padding=atrous[1], use_bias=False)
self.Conv_rate3 = _Deepwise_Conv(in_channels=feature.size()[1], out_channels=256, rate=atrous[2],
padding=atrous[2], use_bias=False)
self.globalAvgPoolAndConv = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
Conv(in_channels=320, out_channels=256, kernel_size=1, stride=1, use_bias=False),
)
self.Conv4 = Conv(in_channels=256 * 5, out_channels=256, kernel_size=1, stride=1, use_bias=False)
self.dropout = nn.Dropout(p=0.1)
def forward(self):
f1 = self.Conv1(self.feature.clone())
f2 = self.Conv_rate1(self.feature.clone())
f3 = self.Conv_rate2(self.feature.clone())
f4 = self.Conv_rate3(self.feature.clone())
f5 = self.globalAvgPoolAndConv(self.feature.clone())
f5 = F.interpolate(f5, size=(self.feature.size(2), self.feature.size(3)), mode='bilinear')
x = torch.cat([f1, f2, f3, f4, f5], dim=1)
x = self.Conv4(x)
x = self.dropout(x)
class Deeplabv3(nn.Module):
def __init__(self, feature, atrous, skip1, num_class):
super(Deeplabv3, self).__init__()
self.num_class = num_class
self.feature = ASPP(atrous=atrous, feature=feature).forward()
self.skip1 = skip1
self.encoder = ASPP(atrous=atrous, feature=feature)
self.Conv1 = Conv(in_channels=skip1.size()[1], out_channels=48, kernel_size=1,strip=1, use_bias=False)
self.Conv2 = _Deepwise_Conv(in_channels=48 + 256, out_channels=256, use_bias=False)
self.ConvNUM = Conv(in_channels=256, out_channels=num_class, kernel_size=1, use_bias=False)
def forward(self, input_img):
skip1 = self.Conv1(self.skip1)
feature = F.interpolate(self.feature, size=(skip1.size()[2], skip1.size()[3]), mode='bilinear')
skip1 = torch.cat([skip1, feature], dim=1)
skip1 = self.Conv2(skip1)
skip1 = self.ConvNUM(skip1)
skip1 = F.interpolate(skip1, size=(input_img.size()[2], input_img.size()[3]))
return F.softmax(skip1,dim=1)
class _bottlenet(nn.Module):
def __init__(self, in_channels, out_channels, rate=1, expand_ratio=1, stride=1):
super(_bottlenet, self).__init__()
# 步长为2以及前后通道数不同就不进行残差堆叠
self.use_res_connect = (stride == 1) and (in_channels == out_channels)
self.features = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=in_channels * expand_ratio, kernel_size=1),
nn.BatchNorm2d(num_features=in_channels * expand_ratio),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels=in_channels * expand_ratio, out_channels=in_channels * expand_ratio, kernel_size=3, stride=stride,
padding=rate, dilation=(rate, rate)),
nn.BatchNorm2d(num_features=in_channels * expand_ratio),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels=in_channels * expand_ratio, out_channels=out_channels, stride=1, kernel_size=1,
padding=0),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU6(inplace=True),
)
# self.change = nn.Conv2d()
def forward(self, x):
x_clone = x.clone()
x = self.features(x)
# print(x.size())
if self.use_res_connect:
# print("="*10)
# print(x.size())
# print(x_clone.size())
x.add_(x_clone)
return x
class get_mobilenetv2_encoder(nn.Module):
def __init__(self, downsamp_factor=8, num_classes=3):
super(get_mobilenetv2_encoder, self).__init__()
if downsamp_factor == 8:
self.atrous_rates = (12, 24, 36)
block4_dilation = 2
block5_dilation = 4
block4_stride = 1
else:
self.atrous_rates = (6, 12, 18)
block4_dilation = 1
block5_dilation = 2
block4_stride = 2
self.features = []
self.features.append(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=(3, 3), padding=1, stride=2)
)
self.features.append(
nn.BatchNorm2d(num_features=32)
)
self.features.append(
nn.ReLU6(inplace=True)
)
# ------ 3 ------
# block1
self.features.append(
_bottlenet(in_channels=32, out_channels=16, expand_ratio=1, stride=1)
)
# block2
# [t, c, n, s] = [6, 24, 2, 2]
self.features.append(
_bottlenet(in_channels=16, out_channels=24, expand_ratio=6, stride=2)
)
self.features.append(
_bottlenet(in_channels=24, out_channels=24, expand_ratio=6, stride=1)
)
# ------ 6 -----
# block3
# [t, c, n, s] = [6, 32, 3, 2]
self.features.append(
_bottlenet(in_channels=24, out_channels=32, expand_ratio=6, stride=2)
)
for i in range(2):
self.features.append(
_bottlenet(in_channels=32, out_channels=32, expand_ratio=6)
)
# ------ 9 ------
# block4
# [t, c, n, s] = [6, 64, 4, 2]
self.features.append(
_bottlenet(in_channels=32, out_channels=64, expand_ratio=6, stride=block4_stride)
)
for i in range(3):
self.features.append(
_bottlenet(in_channels=64, out_channels=64, expand_ratio=6, rate=block4_dilation)
)
# ------ 13 ------
# block5
# [t, c, n, s] = [6, 96, 3, 1]
self.features.append(
_bottlenet(in_channels=64, out_channels=96, expand_ratio=6, rate=block4_dilation)
)
for i in range(2):
self.features.append(
_bottlenet(in_channels=96, out_channels=96, expand_ratio=6, rate=block4_dilation)
)
# [t, c, n, s] = [6, 160, 3, 2]
# block6
self.features.append(
_bottlenet(in_channels=96, out_channels=160, expand_ratio=6, stride=1)
)
for i in range(2):
self.features.append(
_bottlenet(in_channels=160, out_channels=160, expand_ratio=6)
)
# [t, c, n, s] = [6, 160, 3, 2]
self.features.append(
_bottlenet(in_channels=160, out_channels=320, expand_ratio=6)
)
self.features = nn.Sequential(*self.features)
def forward(self, x):
skip1 = None
for i, op in enumerate(self.features, 0):
x = op(x)
if i == 5:
skip1 = x.clone()
return x, self.atrous_rates, skip1
class pool_block(nn.Module):
def __init__(self, f, stride):
super(pool_block, self).__init__()
in_channels = f.size()[1]
kernel_size = stride
self.features = nn.Sequential(
nn.AvgPool2d(kernel_size=kernel_size, stride=kernel_size, padding=kernel_size // 2),
nn.Conv2d(in_channels=in_channels, out_channels=512, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(num_features=512),
nn.ReLU6(inplace=True),
nn.Upsample(size=(INPUT_SIZE, INPUT_SIZE), mode="bilinear")
)
def forward(self, x):
x = self.features(x)
return x
class _Deepwise_Conv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, rate=1, use_bias=False):
super(_Deepwise_Conv, self).__init__()
self.conv1 = Conv(in_channels=in_channels, out_channels=in_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=rate, use_bias=use_bias)
self.conv2 = Conv(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, padding=0, use_bias=use_bias)
def forward(self, x):
return self.conv2(self.conv1(x))
class Conv(nn.Module):
'''
nn.Conv2d + Batchnormlizetion + ReLU6
'''
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, dilation=1, use_bias=False):
super(Conv, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, bias=use_bias),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU6(),
)
def forward(self, x):
return self.features(x)
参考链接如下:
https://blog.csdn.net/weixin_44791964/article/details/103017389
https://zhuanlan.zhihu.com/p/68531147