全局稳定性收敛平衡点为0吗_GAN最新进展:8大技巧提高稳定性

【新智元导读】生成对抗网络GAN很强大,但也有很多造成GAN难以使用的缺陷。本文介绍了可以克服GAN训练缺点的一些解决方案,有助于提高GAN性能。
生成对抗网络 (GAN) 是一类功能强大的神经网络,具有广泛的应用前景。GAN 本质上是由两个神经网络组成的系统——生成器 (Generator) 和鉴别器 (Discriminator)——二者相互竞争。

给定一组目标样本,生成器试图生成能够欺骗鉴别器的样本,使鉴别器认为这些样本是真实的。鉴别器试图从假的 (生成的) 样本中分辨出真实的 (目标) 样本。使用这种迭代训练方法,我们最终能得到一个非常擅长生成足以以假乱真的样本的生成器。
GAN 有很多应用,因为它们可以学习模仿几乎所有类型的数据分布。通常,GAN 用于移除图像伪影、超分辨率、姿势转换,以及任何类型的图像翻译,例如下面这些:

使用 GAN 进行图像翻译 (Source: https://phillipi.github.io/pix2pix/)
然而,由于其无常的稳定性,GAN 非常难以使用。不用说,许多研究人员已经提出了很好的解决方案来减轻 GAN 训练中涉及的一些问题。
然而,这一领域的研究进展如此之快,以至于很难跟踪所有有趣的想法。本文列出了一些常用的使 GAN 训练稳定的技术。
使用 GAN 的缺点
GAN 难以使用的原因有很多,这里列出一些主要的原因。
1、模式坍塌 (Mode collapse)
自然数据分布是高度复杂且多模态的。也就是说,数据分布有很多 “峰值”(peaks) 或 “模式”(modes)。每个 mode 表示相似数据样本的集中度,但与其他 mode 不同。
在 mode collapse 期间,生成器生成属于一组有限模式集的样本。当生成器认为它可以通过锁定单个模式来欺骗鉴别器时,就会发生这种情况。也就是说,生成器仅从这种模式来生成样本。
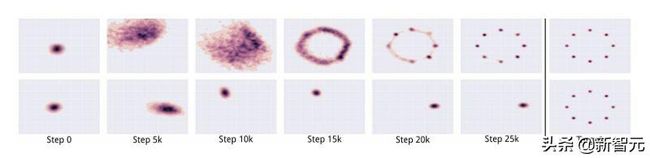
顶部的图像表示没有发生 mode collapse 的 GAN 的输出。底部的图像表示发生了 mode collapse 的 GAN 的输出
(Source: https://arxiv.org/pdf/1611.02163.pdf)
鉴别器最终会发现这种模式下的样本是假的。但生成器仅仅是锁定到另一种模式。这个循环无限重复,从根本上限制了生成样本的多样性。
2、收敛 (Convergence)
GAN 训练中一个常见的问题是 “我们应该在什么时候停止训练?”。由于鉴别器损失降低时,生成器损失增加 (反之亦然),我们不能根据损失函数的值来判断收敛性。如下图所示:
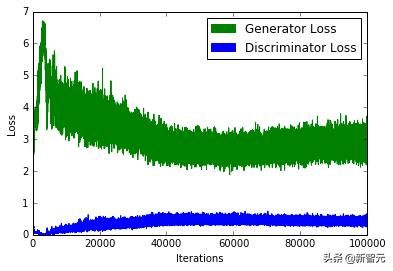
一个典型的 GAN 损失函数
3. 质量
与前一个问题一样,很难定量地判断生成器何时产生高质量的样品。在损失函数中加入额外的感知正则化可以在一定程度上缓解这种情况。
4. 度量标准 (Metrics)
GAN 目标函数可以解释生成器或鉴别器相对于其他方法的性能表现。然而,它并不代表输出的质量或多样性。因此,我们需要不同的度量标准。
8大技巧提高GAN性能
有很多技巧可以用来使 GAN 更加稳定或更加强大。这里只解释了相对较新的或较复杂的一些技术。
1、替代损失函数 (Alternative Loss Functions)
针对 GAN 的缺陷,最常用的一种修复方法是 Wasserstein GAN。它本质上用 Earth Mover distance (Wasserstein-1 distance 或 EM distance) 来替代传统 GAN 的 Jensen Shannon 散度。EM 距离的原始形式是难以处理的,因此我们使用它的 dual 形式。这要求鉴别器为 1-Lipschitz,它是通过削减鉴别器的权重来维持的。
使用 Earth Mover distance 的优点是,即使真实的数据和生成的数据分布不相交,它也是连续的,这与 JS 散度或 KL 散度不同。同时,生成的图像质量与损失值之间存在相关性。缺点是,我们需要对每个生成器更新执行多个鉴别器更新。此外,作者认为,利用权重削减来确保 1-Lipschitz 约束是一种糟糕的方法。

即使分布不连续,earth mover distance(左)也是连续的,与 JS 散度 (右) 不同
另一个解决方案是使用均方损失 (mean squared loss) 来替代对数损失。LSGAN 的作者认为,传统的 GAN 损失函数并没有提供太多的激励来将生成的数据分布 “拉” 到接近真实数据分布的位置。
原始 GAN 损失函数中的 log loss 并不关心生成的数据与决策边界的距离 (决策边界将真实数据和虚假数据分开)。另一方面,LSGAN 对远离决策边界的生产样本实施乘法,本质上是将生成的数据分布 “拉” 得更接近真实的数据分布。LSGAN 用均方损失代替对数损失来实现这一点。
2、Two Timescale Update Rule (TTUR)
在这种方法中,我们对鉴别器和生成器使用不同的学习率。通常,生成器使用较慢的更新规则 (update rule),鉴别器使用较快的更新规则。使用这种方法,我们可以以 1:1 的比例执行生成器和识别器的更新,只需要修改学习率。SAGAN 实现正是使用了这种方法。
3、梯度惩罚 (Gradient Penalty)
在 Improved Training of WGANs 这篇论文中,作者声称 weight clipping 会导致优化问题。
作者表示, weight clipping 迫使神经网络学习最优数据分布的 “更简单的近似”,从而导致较低质量的结果。他们还声称,如果没有正确设置 WGAN 超参数,那么 weight clipping 会导致梯度爆炸或梯度消失问题。
作者在损失函数中引入了一个简单的 gradient penalty,从而缓解了上述问题。此外,与最初的 WGAN 实现一样,保留了 1-Lipschitz 连续性。
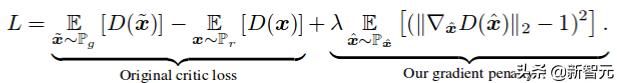
与 WGAN-GP 原始论文一样,添加了 gradient penalty 作为一个正则化器
DRAGAN 的作者声称,当 GAN 所玩的游戏达到 “局部平衡状态” 时,就会发生 mode collapse。他们还声称,鉴别器围绕这些状态产生的梯度是“尖锐的”。当然,使用 gradient penalty 可以帮助我们避开这些状态,大大增强稳定性,减少模式崩溃。
4、谱归一化 (Spectral Normalization)
Spectral Normalization 是一种权重归一化技术,通常用于鉴别器上,以增强训练过程。这本质上保证了鉴别器是 K-Lipschitz 连续的。
像 SAGAN 这样的一些实现,也在生成器上使用 spectral Normalization。该方法比梯度惩罚法计算效率更高。
5、Unrolling 和 Packing
防止 mode hopping 的一种方法是预测未来,并在更新参数时预测对手。Unrolled GAN 使生成器能够在鉴别器有机会响应之后欺骗鉴别器。
防止 mode collapse 的另一种方法是在将属于同一类的多个样本传递给鉴别器之前 “打包” 它们,即 packing。这种方法被 PacGAN 采用,在 PacGAN 论文中,作者报告了 mode collapse 有适当减少。
6、堆叠 GAN
单个 GAN 可能不足以有效地处理任务。我们可以使用多个连续堆叠的 GAN,其中每个 GAN 可以解决问题中更简单的一部分。例如,FashionGAN 使用两个 GAN 来执行局部图像翻译。

FashionGAN 使用两个 GAN 进行局部图像翻译
把这个概念发挥到极致,我们可以逐渐加大 GAN 所解决的问题的难度。例如, Progressive GAN (ProGAN) 可以生成高质量的高分辨率图像。
7、Relativistic GAN
传统的 GAN 测量生成的数据是真实数据的概率。 Relativistic GAN 测量生成的数据比真实数据 “更真实” 的概率。正如 RGAN 论文中提到的,我们可以使用适当的距离度量来度量这种“相对真实性”。
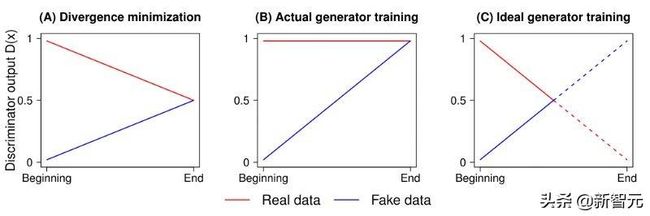
使用标准 GAN loss 时鉴别器的输出 (图 B)。图 C 表示输出曲线的实际样子。图 A 表示 JS 散度的最优解。
作者还提到,鉴别器的输出在达到最优状态时应该收敛到 0.5。然而,传统的 GAN 训练算法强迫鉴别器对任何图像输出 “real”(即 1)。这在某种程度上阻止了鉴别器达到其最优值。 relativistic 方法也解决了这个问题,并取得了相当显著的效果,如下图所示:

经过 5000 次迭代后,标准 GAN(左) 和 relativistic GAN(右) 的输出
8、自注意力机制
Self Attention GANs 的作者表示,用于生成图像的卷积会查看局部传播的信息。也就是说,由于它们限制性的 receptive field,它们错过了全局性的关系。

将 attention map(在黄色框中计算) 添加到标准卷积操作中
Self-Attention GAN 允许对图像生成任务进行注意力驱动的长期依赖建模。 Self-Attention 机制是对普通卷积运算的补充。全局信息 (远程依赖) 有助于生成更高质量的图像。网络可以选择忽略注意机制,也可以将其与正常卷积一起考虑。

对红点标记的位置的 attention map 的可视化
总结
研究社区已经提出了许多解决方案和技巧来克服 GAN 训练的缺点。然而,由于新研究的数量庞大,很难跟踪所有重要的贡献。
由于同样的原因,这篇文章中分享的细节并非详尽无疑,可能在不久的将来就会过时。尽管如此,还是希望本文能够成为人们寻找改进 GAN 性能的方法的一个指南。
囿于篇幅,本文中的参考文献见原文:
https://medium.com/beyondminds/advances-in-generative-adversarial-networks-7bad57028032