【PyTorch】Torchvision Models
文章目录
- 六、Torchvision Models
-
- 1、VGG
-
- 1.1 add
- 1.2 modify
- 2、Save and Load
-
- 2.1 模型结构 + 模型参数
- 2.2 模型参数(官方推荐)
- 2.3 Trap
六、Torchvision Models
1、VGG
VGG参考文档:https://pytorch.org/vision/stable/models/vgg.html

以VGG16为例:
https://pytorch.org/vision/stable/models/generated/torchvision.models.vgg16.html#torchvision.models.vgg16

ImageNet数据集:
https://pytorch.org/vision/stable/generated/torchvision.datasets.ImageNet.html#torchvision.datasets.ImageNet
ImageNet描述:
https://image-net.org/challenges/LSVRC/index.php
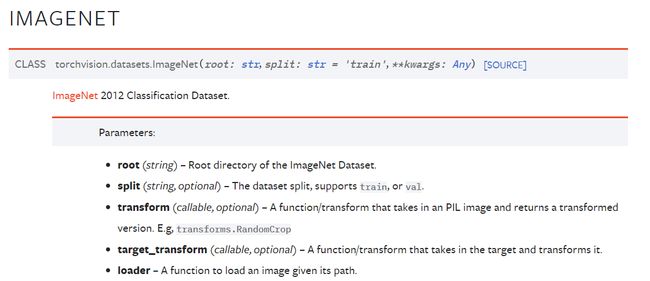
train_data = torchvision.datasets.ImageNet("../data", split="train", transform=torchvision.transforms.ToTensor(),
download=True)
报错:需要手动下载!!!(100多G,还是算了吧)
RuntimeError: The archive ILSVRC2012_devkit_t12.tar.gz is not present in the root directory or is corrupted. You need to download it externally and place it in ../data.
import torchvision
vgg16_false = torchvision.models.vgg16(pretrained=False) # False 加载网络模型 不需要下载
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
out_features=1000,输出为1000个类,如果想要输出10个类,应该如何?
1.1 add
(1)在VGG16中的features中添加add_linear:
import torchvision
from torch import nn
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
vgg16_true.add_module('add_linear', nn.Linear(in_features=1000, out_features=10))
print(vgg16_true)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
...
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
...
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
(2)在VGG16中的classifier中添加add_linear:
vgg16_true.classifier.add_module('add_linear', nn.Linear(in_features=1000, out_features=10))
VGG(
(features): Sequential(
...
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
...
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
)
1.2 modify
直接将out_features=1000,修改为,输出100:
vgg16_true.classifier[6] = nn.Linear(in_features=1000, out_features=10)
VGG(
(features): Sequential(
...
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
...
(6): Linear(in_features=1000, out_features=10, bias=True)
)
)
2、Save and Load
2.1 模型结构 + 模型参数
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16, "../model/vgg16_method1.pth")
vgg16 = torch.load("../model/vgg16_method1.pth")
print(vgg16)
VGG(
(features): Sequential(
...
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
...
)
)
2.2 模型参数(官方推荐)
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16.state_dict(), "../model/vgg16_method2.pth")
查看一下保存的字典:
vgg16 = torch.load("../model/vgg16_method2.pth")
print(vgg16)
OrderedDict([('features.0.weight', tensor([[[[-0.0108, 0.0403, -0.0032],
[-0.0723, 0.0372, -0.1241],
[-0.0583, -0.1042, -0.0469]],
...
...
...
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]))])
加载:
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("../model/vgg16_method2.pth"))
print(vgg16)
VGG(
(features): Sequential(
...
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
...
)
)
2.3 Trap
当我们使用第一种方式保存自己定义的网络模型时:
class Liang(nn.Module):
def __init__(self):
super(Liang, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
def forward(self, x):
x = self.conv1(x)
return x
liang = Liang()
torch.save(liang, "../model/Liang.pth")
再使用第一种方式加载模型时:
liang = torch.load("../model/Liang.pth")
print(liang)
会报错:AttributeError: Can't get attribute 'Liang' on
解决方法一:加上class类
class Liang(nn.Module):
def __init__(self):
super(Liang, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
def forward(self, x):
x = self.conv1(x)
return x
liang = torch.load("../model/Liang.pth")
print(liang)
Liang(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
)
解决方法二:引入
首先将class Liang类 写入all_class.py 文件中,再使用 from all_class import *,直接引用!
from all_class import *
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("../model/vgg16_method2.pth"))
liang = torch.load("../model/Liang.pth")
print(liang)
Liang(
(conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))
)