目标检测——使用yolov6调用本地摄像头进行实时检测
yolov6源码自带了图片目标检测推理功能;
当我们想进行摄像头实时检测识别的时候会有点不方便,根据源码的图片目标检测推理功能,我们进行稍作调整即可进行调用本地摄像头进行目标检测推理功能。
首先在源码文件路径 tools/infer.py 打开infer.py文件,如下图所示:
在infer.py文件第22行修改如下内容:
#source 如果是要根据单独图片进行识别可以输入图片的路径或者图片文件夹的路径; 如果是要根据摄像头实时识别则输入 0
parser.add_argument('--source', type=str, default='0', help='the source path, 0, e.g. image-file/dir/camera.')
在infer.py文件第100行修改如下内容:
if source != '0':
if save_txt or save_img:
LOGGER.info(f"Results saved to {save_dir}")
其次在源码文件路径 yolov6/inferer.py 打开inferer.py文件,新增以及修改内容如下所示:
在 inferer.py文件第34行增加如下内容:
self.camera = source
在 inferer.py文件第45行 #Load data到 def infer函数之前的内容修改成如下内容:
# open camera
if self.camera == '0':
pass
else:
# Load data
if os.path.isdir(source):
img_paths = sorted(glob.glob(os.path.join(source, '*.*'))) # dir
elif os.path.isfile(source):
img_paths = [source] # files
else:
raise Exception(f'Invalid path: {source}')
self.img_paths = [img_path for img_path in img_paths if img_path.split('.')[-1].lower() in IMG_FORMATS]
在 inferer.py文件第58行def infer函数整个更改为如下图所示的内容:
def infer(self, conf_thres, iou_thres, classes, agnostic_nms, max_det, save_dir, save_txt, save_img, hide_labels, hide_conf):
''' Model Inference and results visualization '''
if self.camera == '0':
print("开始调用摄像头...")
cap = cv2.VideoCapture(0)
while True:
f, img_src = cap.read()
image = letterbox(img_src, self.img_size, stride=self.stride)[0]
txt_path = osp.join(save_dir, 'labels', osp.splitext(osp.basename(img_path))[0])
# Convert
image = image.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
image = torch.from_numpy(np.ascontiguousarray(image))
image = image.half() if self.half else image.float() # uint8 to fp16/32
image /= 255 # 0 - 255 to 0.0 - 1.0
img = image
img = img.to(self.device)
if len(img.shape) == 3:
img = img[None]
# expand for batch dim
pred_results = self.model(img)
det = non_max_suppression(pred_results, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)[0]
gn = torch.tensor(img_src.shape)[[1, 0, 1, 0]] # normalization gain whwh
img_ori = img_src
# check image and font
assert img_ori.data.contiguous, 'Image needs to be contiguous. Please apply to input images with np.ascontiguousarray(im).'
self.font_check()
if len(det):
det[:, :4] = self.rescale(img.shape[2:], det[:, :4], img_src.shape).round()
for *xyxy, conf, cls in reversed(det):
class_num = int(cls) # integer class
label = None if hide_labels else (self.class_names[class_num] if hide_conf else f'{self.class_names[class_num]} {conf:.2f}')
self.plot_box_and_label(img_ori, max(round(sum(img_ori.shape) / 2 * 0.003), 2), xyxy, label, color=self.generate_colors(class_num, True))
img_src = np.asarray(img_ori)
cv2.namedWindow('test', cv2.WINDOW_AUTOSIZE) # 窗口设置为自动调节大小
cv2.imshow('test', img_src)
if cv2.waitKey(1) & 0xFF == ord('q'): # 按q退出
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 结束所有窗口
else:
for img_path in tqdm(self.img_paths):
img, img_src = self.precess_image(img_path, self.img_size, self.stride, self.half)
img = img.to(self.device)
if len(img.shape) == 3:
img = img[None]
# expand for batch dim
pred_results = self.model(img)
det = non_max_suppression(pred_results, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)[0]
save_path = osp.join(save_dir, osp.basename(img_path)) # im.jpg
txt_path = osp.join(save_dir, 'labels', osp.splitext(osp.basename(img_path))[0])
gn = torch.tensor(img_src.shape)[[1, 0, 1, 0]] # normalization gain whwh
img_ori = img_src
# check image and font
assert img_ori.data.contiguous, 'Image needs to be contiguous. Please apply to input images with np.ascontiguousarray(im).'
self.font_check()
if len(det):
det[:, :4] = self.rescale(img.shape[2:], det[:, :4], img_src.shape).round()
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (self.box_convert(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf)
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img:
class_num = int(cls) # integer class
label = None if hide_labels else (self.class_names[class_num] if hide_conf else f'{self.class_names[class_num]} {conf:.2f}')
self.plot_box_and_label(img_ori, max(round(sum(img_ori.shape) / 2 * 0.003), 2), xyxy, label, color=self.generate_colors(class_num, True))
img_src = np.asarray(img_ori)
# Save results (image with detections)
if save_img:
cv2.imwrite(save_path, img_src)
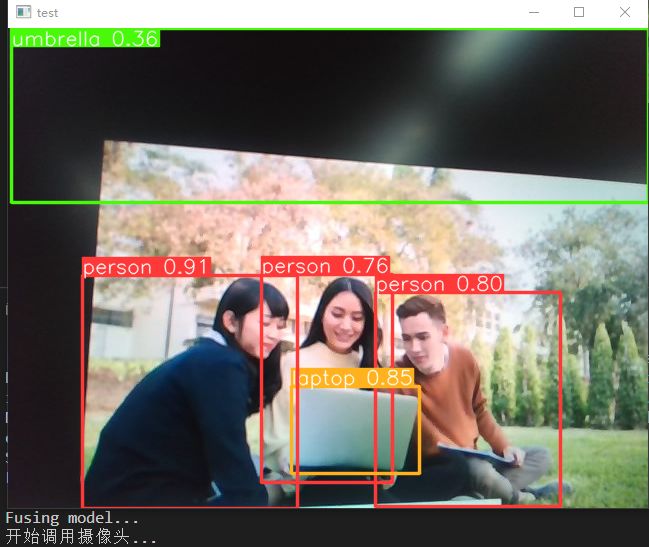
做完上述所有的修改后,回到 tools/infer.py 运行infer.py文件,识别结果如下图所示: