【目标检测--yolov6如何训练自己的数据集】
yolov6 自制数据集训练自己的模型
-
数据集dataset的存放和yolov5差不多,区别在于yolov6不需要images这个文件夹,把图片的文件夹直接放在labels同等级目录即可,
如下图所示: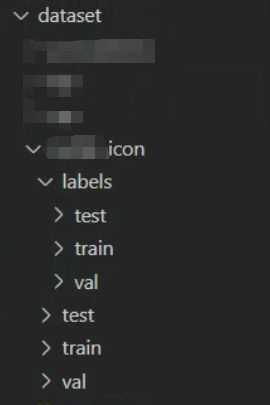
-
创建.yaml文件,参考源码的data文件夹下的dataset.yaml文件修改即可,只需要train,val,test相对应的数据集路径,nc所有标注数量以及names标注名称集。如下所示:
# Please insure that your custom_dataset are put in same parent dir with YOLOv6_DIR train: ../custom_dataset/images/train # train images val: ../custom_dataset/images/val # val images test: ../custom_dataset/images/test # test images (optional) # whether it is coco dataset, only coco dataset should be set to True. is_coco: False # Classes nc: 20 # number of classes names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # class names -
在train.py 里的–data-path的参数修改为自己写的yaml文件路径
default='./data/dataset.yaml', type=str, help='path of dataset') ``` -
datasets.py文件内容全部替换成以下内容:#!/usr/bin/env python3 # -*- coding:utf-8 -*- from distutils.log import info import glob import os import os.path as osp import random import json import time import hashlib from multiprocessing.pool import Pool import cv2 import numpy as np import torch from PIL import ExifTags, Image, ImageOps from torch.utils.data import Dataset from tqdm import tqdm from .data_augment import ( augment_hsv, letterbox, mixup, random_affine, mosaic_augmentation, ) from yolov6.utils.events import LOGGER # Parameters IMG_FORMATS = ["bmp", "jpg", "jpeg", "png", "tif", "tiff", "dng", "webp", "mpo"] # Get orientation exif tag for k, v in ExifTags.TAGS.items(): if v == "Orientation": ORIENTATION = k break class TrainValDataset(Dataset): # YOLOv6 train_loader/val_loader, loads images and labels for training and validation def __init__( self, img_dir, img_size=640, batch_size=16, augment=False, hyp=None, rect=False, check_images=False, check_labels=False, stride=32, pad=0.0, rank=-1, data_dict=None, task="train", ): assert task.lower() in ("train", "val", "speed"), f"Not supported task: {task}" t1 = time.time() self.__dict__.update(locals()) self.main_process = self.rank in (-1, 0) self.task = self.task.capitalize() self.class_names = data_dict["names"] self.img_paths, self.labels = self.get_imgs_labels(self.img_dir) if self.rect: shapes = [self.img_info[p]["shape"] for p in self.img_paths] self.shapes = np.array(shapes, dtype=np.float64) self.batch_indices = np.floor( np.arange(len(shapes)) / self.batch_size ).astype( np.int ) # batch indices of each image self.sort_files_shapes() t2 = time.time() if self.main_process: LOGGER.info(f"%.1fs for dataset initialization." % (t2 - t1)) def __len__(self): """Get the length of dataset""" return len(self.img_paths) def __getitem__(self, index): """Fetching a data sample for a given key. This function applies mosaic and mixup augments during training. During validation, letterbox augment is applied. """ # Mosaic Augmentation if self.augment and random.random() < self.hyp["mosaic"]: img, labels = self.get_mosaic(index) shapes = None # MixUp augmentation if random.random() < self.hyp["mixup"]: img_other, labels_other = self.get_mosaic( random.randint(0, len(self.img_paths) - 1) ) img, labels = mixup(img, labels, img_other, labels_other) else: # Load image img, (h0, w0), (h, w) = self.load_image(index) # Letterbox shape = ( self.batch_shapes[self.batch_indices[index]] if self.rect else self.img_size ) # final letterboxed shape img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment) shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling labels = self.labels[index].copy() if labels.size: w *= ratio h *= ratio # new boxes boxes = np.copy(labels[:, 1:]) boxes[:, 0] = ( w * (labels[:, 1] - labels[:, 3] / 2) + pad[0] ) # top left x boxes[:, 1] = ( h * (labels[:, 2] - labels[:, 4] / 2) + pad[1] ) # top left y boxes[:, 2] = ( w * (labels[:, 1] + labels[:, 3] / 2) + pad[0] ) # bottom right x boxes[:, 3] = ( h * (labels[:, 2] + labels[:, 4] / 2) + pad[1] ) # bottom right y labels[:, 1:] = boxes if self.augment: img, labels = random_affine( img, labels, degrees=self.hyp["degrees"], translate=self.hyp["translate"], scale=self.hyp["scale"], shear=self.hyp["shear"], new_shape=(self.img_size, self.img_size), ) if len(labels): h, w = img.shape[:2] labels[:, [1, 3]] = labels[:, [1, 3]].clip(0, w - 1e-3) # x1, x2 labels[:, [2, 4]] = labels[:, [2, 4]].clip(0, h - 1e-3) # y1, y2 boxes = np.copy(labels[:, 1:]) boxes[:, 0] = ((labels[:, 1] + labels[:, 3]) / 2) / w # x center boxes[:, 1] = ((labels[:, 2] + labels[:, 4]) / 2) / h # y center boxes[:, 2] = (labels[:, 3] - labels[:, 1]) / w # width boxes[:, 3] = (labels[:, 4] - labels[:, 2]) / h # height labels[:, 1:] = boxes if self.augment: img, labels = self.general_augment(img, labels) labels_out = torch.zeros((len(labels), 6)) if len(labels): labels_out[:, 1:] = torch.from_numpy(labels) # Convert img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB img = np.ascontiguousarray(img) return torch.from_numpy(img), labels_out, self.img_paths[index], shapes def load_image(self, index): """Load image. This function loads image by cv2, resize original image to target shape(img_size) with keeping ratio. Returns: Image, original shape of image, resized image shape """ path = self.img_paths[index] im = cv2.imread(path) assert im is not None, f"Image Not Found {path}, workdir: {os.getcwd()}" h0, w0 = im.shape[:2] # origin shape r = self.img_size / max(h0, w0) if r != 1: im = cv2.resize( im, (int(w0 * r), int(h0 * r)), interpolation=cv2.INTER_AREA if r < 1 and not self.augment else cv2.INTER_LINEAR, ) return im, (h0, w0), im.shape[:2] @staticmethod def collate_fn(batch): """Merges a list of samples to form a mini-batch of Tensor(s)""" img, label, path, shapes = zip(*batch) for i, l in enumerate(label): l[:, 0] = i # add target image index for build_targets() return torch.stack(img, 0), torch.cat(label, 0), path, shapes def get_imgs_labels(self, img_dir): assert osp.exists(img_dir), f"{img_dir} is an invalid directory path!" valid_img_record = osp.join( osp.dirname(img_dir), "." + osp.basename(img_dir) + ".json" ) NUM_THREADS = min(8, os.cpu_count()) img_paths = glob.glob(osp.join(img_dir, "*"), recursive=True) img_paths = sorted( p for p in img_paths if p.split(".")[-1].lower() in IMG_FORMATS ) assert img_paths, f"No images found in {img_dir}." img_hash = self.get_hash(img_paths) if osp.exists(valid_img_record): with open(valid_img_record, "r") as f: cache_info = json.load(f) if "image_hash" in cache_info and cache_info["image_hash"] == img_hash: img_info = cache_info["information"] else: self.check_images = True else: self.check_images = True # check images if self.check_images and self.main_process: img_info = {} nc, msgs = 0, [] # number corrupt, messages LOGGER.info( f"{self.task}: Checking formats of images with {NUM_THREADS} process(es): " ) with Pool(NUM_THREADS) as pool: pbar = tqdm( pool.imap(TrainValDataset.check_image, img_paths), total=len(img_paths), ) for img_path, shape_per_img, nc_per_img, msg in pbar: if nc_per_img == 0: # not corrupted img_info[img_path] = {"shape": shape_per_img} nc += nc_per_img if msg: msgs.append(msg) pbar.desc = f"{nc} image(s) corrupted" pbar.close() if msgs: LOGGER.info("\n".join(msgs)) cache_info = {"information": img_info, "image_hash": img_hash} # save valid image paths. with open(valid_img_record, "w") as f: json.dump(cache_info, f) img_info = {} self.change_json(valid_img_record) with open(valid_img_record, "r") as f: cache_info = json.load(f) if "image_hash" in cache_info and cache_info["image_hash"] == img_hash: img_info = cache_info["information"] # check and load anns # label_dir = osp.join( # osp.dirname(osp.dirname(img_dir)), "labels", osp.basename(img_dir) # ) label_dir = osp.join( osp.dirname(img_dir), "labels", osp.basename(img_dir) ) assert osp.exists(label_dir), f"{label_dir} is an invalid directory path!" img_paths = list(img_info.keys()) label_paths = sorted( osp.join(label_dir, osp.splitext(osp.basename(p))[0] + ".txt") for p in img_paths ) label_hash = self.get_hash(label_paths) if "label_hash" not in cache_info or cache_info["label_hash"] != label_hash: self.check_labels = True if self.check_labels: cache_info["label_hash"] = label_hash nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number corrupt, messages LOGGER.info( f"{self.task}: Checking formats of labels with {NUM_THREADS} process(es): " ) with Pool(NUM_THREADS) as pool: pbar = pool.imap( TrainValDataset.check_label_files, zip(img_paths, label_paths) ) pbar = tqdm(pbar, total=len(label_paths)) if self.main_process else pbar for ( img_path, labels_per_file, nc_per_file, nm_per_file, nf_per_file, ne_per_file, msg, ) in pbar: if img_path: img_info[img_path]["labels"] = labels_per_file else: try: img_info.pop(img_path) except: pass nc += nc_per_file nm += nm_per_file nf += nf_per_file ne += ne_per_file if msg: msgs.append(msg) if self.main_process: pbar.desc = f"{nf} label(s) found, {nm} label(s) missing, {ne} label(s) empty, {nc} invalid label files" if self.main_process: pbar.close() with open(valid_img_record, "w") as f: json.dump(cache_info, f) self.change_json(valid_img_record) if msgs: LOGGER.info("\n".join(msgs)) if nf == 0: LOGGER.warning( f"WARNING: No labels found in {osp.dirname(self.img_paths[0])}. " ) if self.task.lower() == "val": if self.data_dict.get("is_coco", False): # use original json file when evaluating on coco dataset. assert osp.exists(self.data_dict["anno_path"]), "Eval on coco dataset must provide valid path of the annotation file in config file: data/coco.yaml" else: assert ( self.class_names ), "Class names is required when converting labels to coco format for evaluating." save_dir = osp.join(osp.dirname(osp.dirname(img_dir)), "annotations") if not osp.exists(save_dir): os.mkdir(save_dir) save_path = osp.join( save_dir, "instances_" + osp.basename(img_dir) + ".json" ) TrainValDataset.generate_coco_format_labels( img_info, self.class_names, save_path ) img_paths, labels = list( zip( *[ ( img_path, np.array(info['labels'], dtype=np.float32) if info['labels'] else np.zeros((0, 5), dtype=np.float32), ) for img_path, info in img_info.items() ] ) ) self.img_info = img_info LOGGER.info( f"{self.task}: Final numbers of valid images: {len(img_paths)}/ labels: {len(labels)}. " ) return img_paths, labels def get_mosaic(self, index): """Gets images and labels after mosaic augments""" indices = [index] + random.choices( range(0, len(self.img_paths)), k=3 ) # 3 additional image indices random.shuffle(indices) imgs, hs, ws, labels = [], [], [], [] for index in indices: img, _, (h, w) = self.load_image(index) labels_per_img = self.labels[index] imgs.append(img) hs.append(h) ws.append(w) labels.append(labels_per_img) img, labels = mosaic_augmentation(self.img_size, imgs, hs, ws, labels, self.hyp) return img, labels def change_json(self, filepath): file_path = filepath new_path = filepath filename = file_path.split("\\")[-1] filenamea = filename.replace(".json","").replace(".","") with open(file_path, "r") as f: file = json.load(f) images_file = file["information"] image_hash = file["image_hash"] images_file_keys = list(images_file.keys()) for f in range(len(images_file_keys)): d = [] img_path = images_file_keys[f] txt_path = img_path.replace("jpg","txt") txt_path = osp.join(osp.dirname(txt_path), osp.basename(txt_path)) txt_path = txt_path.replace("%s"%filenamea,"labels/%s"%filenamea) with open(txt_path,"r") as t: t = t.readlines() for h in range(len(t)): hh = t[h] hh = hh.replace("\n","").split(" ") for i in range(len(hh)): hh[i] = float(hh[i]) d.append(hh) images_file[img_path]["labels"] = d write_fict = {"information":images_file,"image_hash":image_hash} with open(new_path, 'w') as write_f: write_f.write(json.dumps(write_fict, indent=4, ensure_ascii=False)) def general_augment(self, img, labels): """Gets images and labels after general augment This function applies hsv, random ud-flip and random lr-flips augments. """ nl = len(labels) # HSV color-space augment_hsv( img, hgain=self.hyp["hsv_h"], sgain=self.hyp["hsv_s"], vgain=self.hyp["hsv_v"], ) # Flip up-down if random.random() < self.hyp["flipud"]: img = np.flipud(img) if nl: labels[:, 2] = 1 - labels[:, 2] # Flip left-right if random.random() < self.hyp["fliplr"]: img = np.fliplr(img) if nl: labels[:, 1] = 1 - labels[:, 1] return img, labels def sort_files_shapes(self): # Sort by aspect ratio batch_num = self.batch_indices[-1] + 1 s = self.shapes # wh ar = s[:, 1] / s[:, 0] # aspect ratio irect = ar.argsort() self.img_paths = [self.img_paths[i] for i in irect] self.labels = [self.labels[i] for i in irect] self.shapes = s[irect] # wh ar = ar[irect] # Set training image shapes shapes = [[1, 1]] * batch_num for i in range(batch_num): ari = ar[self.batch_indices == i] mini, maxi = ari.min(), ari.max() if maxi < 1: shapes[i] = [maxi, 1] elif mini > 1: shapes[i] = [1, 1 / mini] self.batch_shapes = ( np.ceil(np.array(shapes) * self.img_size / self.stride + self.pad).astype( np.int ) * self.stride ) @staticmethod def check_image(im_file): # verify an image. nc, msg = 0, "" try: im = Image.open(im_file) im.verify() # PIL verify shape = im.size # (width, height) im_exif = im._getexif() if im_exif and ORIENTATION in im_exif: rotation = im_exif[ORIENTATION] if rotation in (6, 8): shape = (shape[1], shape[0]) assert (shape[0] > 9) & (shape[1] > 9), f"image size {shape} <10 pixels" assert im.format.lower() in IMG_FORMATS, f"invalid image format {im.format}" if im.format.lower() in ("jpg", "jpeg"): with open(im_file, "rb") as f: f.seek(-2, 2) if f.read() != b"\xff\xd9": # corrupt JPEG ImageOps.exif_transpose(Image.open(im_file)).save( im_file, "JPEG", subsampling=0, quality=100 ) msg += f"WARNING: {im_file}: corrupt JPEG restored and saved" return im_file, shape, nc, msg except Exception as e: nc = 1 msg = f"WARNING: {im_file}: ignoring corrupt image: {e}" return im_file, None, nc, msg @staticmethod def check_label_files(args): img_path, lb_path = args nm, nf, ne, nc, msg = 0, 0, 0, 0, "" # number (missing, found, empty, message try: if osp.exists(lb_path): nf = 1 # label found with open(lb_path, "r") as f: labels = [ x.split() for x in f.read().strip().splitlines() if len(x) ] labels = np.array(labels, dtype=np.float32) if len(labels): assert all( len(l) == 5 for l in labels ), f"{lb_path}: wrong label format." assert ( labels >= 0 ).all(), f"{lb_path}: Label values error: all values in label file must > 0" assert ( labels[:, 1:] <= 1 ).all(), f"{lb_path}: Label values error: all coordinates must be normalized" _, indices = np.unique(labels, axis=0, return_index=True) if len(indices) < len(labels): # duplicate row check labels = labels[indices] # remove duplicates msg += f"WARNING: {lb_path}: {len(labels) - len(indices)} duplicate labels removed" labels = labels.tolist() else: ne = 1 # label empty labels = [] else: nm = 1 # label missing labels = [] return img_path, labels, nc, nm, nf, ne, msg except Exception as e: nc = 1 msg = f"WARNING: {lb_path}: ignoring invalid labels: {e}" return None, None, nc, nm, nf, ne, msg @staticmethod def generate_coco_format_labels(img_info, class_names, save_path): # for evaluation with pycocotools dataset = {"categories": [], "annotations": [], "images": []} for i, class_name in enumerate(class_names): dataset["categories"].append( {"id": i, "name": class_name, "supercategory": ""} ) ann_id = 0 LOGGER.info(f"Convert to COCO format") for i, (img_path, info) in enumerate(tqdm(img_info.items())): labels = info["labels"] if info["labels"] else [] img_id = osp.splitext(osp.basename(img_path))[0] img_id = int(img_id) if img_id.isnumeric() else img_id img_w, img_h = info["shape"] dataset["images"].append( { "file_name": os.path.basename(img_path), "id": img_id, "width": img_w, "height": img_h, } ) if labels: for label in labels: c, x, y, w, h = label[:5] # convert x,y,w,h to x1,y1,x2,y2 x1 = (x - w / 2) * img_w y1 = (y - h / 2) * img_h x2 = (x + w / 2) * img_w y2 = (y + h / 2) * img_h # cls_id starts from 0 cls_id = int(c) w = max(0, x2 - x1) h = max(0, y2 - y1) dataset["annotations"].append( { "area": h * w, "bbox": [x1, y1, w, h], "category_id": cls_id, "id": ann_id, "image_id": img_id, "iscrowd": 0, # mask "segmentation": [], } ) ann_id += 1 with open(save_path, "w") as f: json.dump(dataset, f) LOGGER.info( f"Convert to COCO format finished. Resutls saved in {save_path}" ) @staticmethod def get_hash(paths): """Get the hash value of paths""" assert isinstance(paths, list), "Only support list currently." h = hashlib.md5("".join(paths).encode()) return h.hexdigest() -
做完上述的操作和替换,就可以执行
python tools/train.py开始训练。 -
成功运行后的图如下所示:
-
等待训练结束即可用自己模型来识别啦!
-
yolov6如何调用摄像头实时识别?
-
调用摄像头识别结果:
