Actor-Critic方法

复习回顾:

![]() 是动作价值函数
是动作价值函数![]() 的期望,如果动作是离散的,则是图中连加的形式,如果动作是连续的,则会是积分形式。
的期望,如果动作是离散的,则是图中连加的形式,如果动作是连续的,则会是积分形式。![]() 是策略函数,可以计算动作的概率值,从而控制agent做运动,
是策略函数,可以计算动作的概率值,从而控制agent做运动,![]() 是动作价值函数,可以评价动作的好坏程度。可惜策略函数和
是动作价值函数,可以评价动作的好坏程度。可惜策略函数和![]() 都不知道,于是需要用两个神经网络分别近似这两个函数,再用Actor-Critic方法同时学习这两个神经网络。
都不知道,于是需要用两个神经网络分别近似这两个函数,再用Actor-Critic方法同时学习这两个神经网络。
我们可以用策略网络![]() 来近似策略函数
来近似策略函数![]() ,θ为策略网络的参数。我们用策略网络控制agent做运动,决策是由策略网络做的,所以策略网络也叫actor。相当于运动员。
,θ为策略网络的参数。我们用策略网络控制agent做运动,决策是由策略网络做的,所以策略网络也叫actor。相当于运动员。
用另一个神经网络![]() 来近似价值函数
来近似价值函数![]() ,这里的w是神经网络的参数,即价值神经网络,这里的价值网络不控制agent的运动,只是给动作打分而已,所以被称为critic。相当于裁判。
,这里的w是神经网络的参数,即价值神经网络,这里的价值网络不控制agent的运动,只是给动作打分而已,所以被称为critic。相当于裁判。
所以最后可以写成:
![]()
搭建网络:
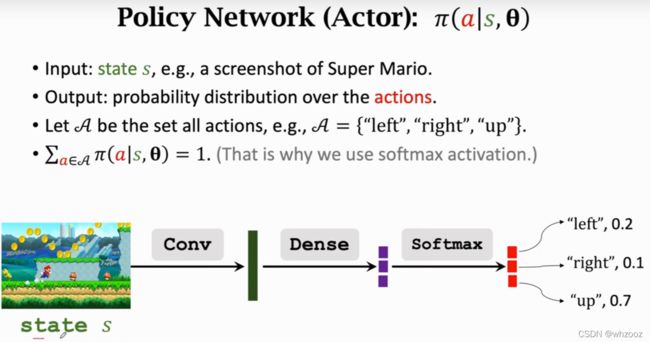
具体过程已经介绍过。

这个价值网络可以可以和策略网络共享卷积层的参数,也可以跟策略网络完全独立。
训练网络:

更新θ和w的目标是不同的。
更新策略网络![]() 的参数θ是为了让v函数的值增加,v函数是对策略π和状态s的评价,如果固定s,v越大,则说明策略π越好,所以我们要更新θ,使得v的平均值增加。学习策略网络
的参数θ是为了让v函数的值增加,v函数是对策略π和状态s的评价,如果固定s,v越大,则说明策略π越好,所以我们要更新θ,使得v的平均值增加。学习策略网络![]() 的时候,监督是由价值网络
的时候,监督是由价值网络![]() 提供的。即运动员的分数是由裁判打分的,运动员改进自己的技术,争取让裁判打的分数平均值更高。
提供的。即运动员的分数是由裁判打分的,运动员改进自己的技术,争取让裁判打的分数平均值更高。
更新价值网络![]() 的w是为了打分更精准,从而更好地估计未来得到的奖励的总和。相当于裁判,一开始是随机初始化的,所以一开始裁判没有判断能力,打分都是瞎猜的,裁判会逐步改变自己的水平,让打分越来越精准。裁判靠的什么改变呢?是根据环境给的奖励reward。
的w是为了打分更精准,从而更好地估计未来得到的奖励的总和。相当于裁判,一开始是随机初始化的,所以一开始裁判没有判断能力,打分都是瞎猜的,裁判会逐步改变自己的水平,让打分越来越精准。裁判靠的什么改变呢?是根据环境给的奖励reward。
使用下面5个步骤对两个神经网路进行更新:

首先观察到当前状态st。
第二步把st作为输入,用策略网络![]() 来计算概率分布,随机抽样得到动作at。
来计算概率分布,随机抽样得到动作at。
第三步agent执行动作at,这时环境会更新状态s到![]() 并给出奖励
并给出奖励![]() 。
。
第四步,有了奖励![]() 就可以用TD算法更新价值网络的参数w,也就是让裁判变得更准确。
就可以用TD算法更新价值网络的参数w,也就是让裁判变得更准确。
最后用策略梯度算法来更新策略网络的参数θ,更新该参数要用到裁判对动作at的打分。
更新价值网络:

首先用价值网络![]() 来给动作打分,分别给
来给动作打分,分别给![]() 和
和![]() 打分,这里的动作是由策略函数随机抽取的。
打分,这里的动作是由策略函数随机抽取的。
然后算一下TD target,算出来的值记作yt,γ是折扣率。
再算损失函数,所以要做梯度下降,让损失函数变小,α是学习率。
用策略梯度下降更新策略网络:

已经介绍过了。
网络详解:

策略网络(actor)观测到当前的状态s,控制agent做出动作a,目的是是自己做出的动作更好。问题是什么样的动作更好?

为了使得动作越来越好,需要裁判的作用,裁判通过观察此时的状态s和动作a,给出分数q并告诉运动员。运动员就靠这个q来改变自己的技术,即神经网络里面的参数,通过状态s,动作a,打分q近似算出策略梯度,然后用梯度上升来更新参数,通过这样做,运动员的动作平均水平会越来越高。但是这样做只是为了迎合裁判的喜好,使得裁判的打分q越来越高了,更高的q并不能说明该运动员变得更优秀了,裁判的水平也很重要,二流的裁判不会产生一流的运动员。
为了让运动员变得更优秀,还要使得裁判有更优秀的打分能力,最开始价值网络是随机初始化的,意味着裁判啥也不懂,打分是瞎猜的。所以要不断改进裁判。裁判要靠r来提升打分水平。r相当于上帝视角,即全部结束时的汇报,裁判根据动作a和状态s进行打分,可以生成打分q,比较q和q+1,以及奖励rt,用TD算法更新价值网络参数,这样可以让裁判打分更精准。
算法总结;

1.观测此时的状态![]() ,更具策略函数生成此时概率密度,从中随机抽取动作
,更具策略函数生成此时概率密度,从中随机抽取动作![]() 。
。
2.让agent执行动作![]() ,此时环境生成新的状态
,此时环境生成新的状态![]() ,和回报
,和回报![]() 。
。
3.拿状态![]() 作为输入,用策略网络生成新的概率,随机抽样得到动作
作为输入,用策略网络生成新的概率,随机抽样得到动作![]() ,这个只是一个假想的动作,agent并不会去做这个动作,算法的每一轮循环只做一次动作,已经做过
,这个只是一个假想的动作,agent并不会去做这个动作,算法的每一轮循环只做一次动作,已经做过![]() 了。
了。
4.算两次价值网络的输出,用![]() 和
和![]() 作为输入,算出
作为输入,算出![]() ,用
,用![]() 和
和![]() 算出
算出![]() 。此时丢掉
。此时丢掉![]() ,因为agent并不会执行此动作。
,因为agent并不会执行此动作。
5.算TD error,预测值![]() 与TD Target(
与TD Target(![]() )的差即为TD error,记作
)的差即为TD error,记作![]() 。
。
6.对价值网络求导,算出q网络对w的梯度,把q关于w的梯度记为![]() 。
。
7.用TD算法更新价值网络,让裁判打分变得更精准。α是学习率,做梯度下降算法,使得预测离TD Target更近。
8.对策略网络求导,记作![]() 。
。
9.用梯度上升更新策略网络,让运动员的平均分更高(该步骤中也会使用![]() 来替换公式中的
来替换公式中的![]() ,这两种方法都是对的)。
,这两种方法都是对的)。
每个循环都做这9个动作,每个循环都只做一个动作,只得一次奖励。

可以看到,训练结束后价值神经网络就没用了,因为该二重网络的终极目的是让运动员的动作完美,所以训练结束后裁判就没用了。