图像分割——DeepLabV3+
来到新公司已经有3个月了,近3个月的工作中图像分割算法用的比较多,主要是需要使用图像分割算法对超市货架的每一层的有效区域做准确分割。刚开始考虑用目标检测算法的,不过如果货架拍摄的角度过大时,我们无法根据目标检测算法的输出准确判断某一个商品属于货架的哪一层,所以最后选择分割算法。在这之前从未在工作中使用过图像分割算法,通过3个月的工作和学习,目前也算是对图像分割算法有了一点粗浅的理解。在这里简单的介绍一下图像分割算法中比较经典,同时效果 非常不错的DeepLab系列算法中的DeepLabV3+。
什么是图像分割?
图像分割就是指像素级别的分类,也就是标注出图像中每一个像素点所属的对象类别。图像分割与图像识别不同,图像识别是对图像进行识别,而图像分割需要进行稠密的像素级分类。
DeepLabV3+
图像分割算法与图像识别、目标算法类似,他们都是建立在语义分类的基础之上的。图像识别是对整幅图像的语义信息进行分类,目标检测是对每一个锚框(或锚点)进行分类,但是他们相对于图像分割对每一个像素分类来说相对稀疏的多。做过目标检测的同学都知道,网络在保证一定深度的同时,输出的特征图尺度越大,越有利于检测效果,这一点对小目标的检测尤为明显,这是因为越大的特征图中,保留的图像细节信息越多,也就越有利于提取到利于分类的特征。也就是说仅有高级的语义信息并不足保证检测召回率,图像的细节特征也很重要。对于目标检测这样稀疏的分类问题尚且如此,那么对于图像分割来说,那这一点就更重要了。图像分割的始祖FCN(Fully Convolutional Networks for Semantic Segmentation)中,网络最终的输出特征图大小为原图的1/32,特征图的语义信息无疑是很丰富的,但是因为丢失了大量的图像空间细节信息,导致分割并不十分准确,尤其是物体边缘分割的十分粗糙。同时,FCN的作者通过结合多个level的特征图用于分割,发现分割准确率有明显改善,这直接证明了图像空间细节信息对于图像分割的重要性。
图像分割的另一个关键点是感受野。感受野在目标检测中是一个十分关键的概念(想要识别到物体,总得先看得到物体的大体全貌吧),在一些常用目标检测算法中(如SSD、Yolo),采用多层特征图参与检测,浅层特征负责检测小尺度目标,深层特征负责检测大尺度目标,因为浅层特征图的感受野相对较小,可以比较好的覆盖小目标,而深层特征的感受野较大,可以较好的覆盖大目标。在图像分割中,感受野更加重要,对像素点进行分类需要丰富的上下文信息,所以模型对感受野的要求更高,不仅要求感受野更加合理,同时要求感受野更加丰富。
在DeepLabV3+中上面提到的问题的解决方法都有所体现。
网络架构
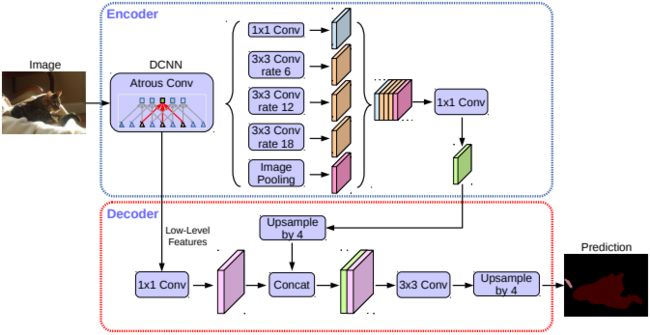
图1 DeepLabv3+模型的整体架构
DeepLabV3+的整体架构如图1所示,它采用了目前语义分割网络常用的Encoder-Decoder架构。Encoder(DCNN)的网络结构可以是任意常用的网络结构,如VGG、MobileNet、ResNet等,不过在网络中使用了带空洞的卷积。在Encoder的最后,使用了带有空洞卷积的空间金字塔池化模块(Atrous Spatial Pyramid Pooling, ASPP),ASPP的作用就是提取多尺度特征,使特征带有更加丰富的上下文信息,所以Encoder的作用就是提取图像特征。Encoder会导致图像的空间按尺寸一步步降低,最终输出的feature maps的大小是原图的1/16,而Decoder则负责恢复feature maps的尺度到原图大小,同时为了弥补空间细节信息,与Decoder的底层特征(Low-Level Features)融合,提升分割精度,尤其是物体边界的分割精度。
空洞卷积
空洞卷积(Atrous Convolution)是DeepLab系列算法的关键之一,空洞卷积在目标检测中也早有使用,它可以在不改变特征图大小的前提下增加感受野,所以它可以代替maxpooling这种操作,在不降低特征图分辨率的情况下扩大感受野,保留更多的空间细节信息。空洞卷积如图2所示,其中rate(r)控制着感受野的大小,r越大感受野越大。可以看到,当rate=1时(图a),空洞卷积就是一个常规卷积;当rate=2时(图b),实际的卷积kernel size还是3x3,但是空洞为1,相当于一个7x7的卷积核,只有9个红色点参与卷积计算,其余的点不参与计算。也可以理解7x7的卷积核中,只有图中的9个点的权重不为0,其余都为0;同理图c中是一个rate=4的空洞卷积,相当于一个15x15的卷积核,卷积核中相邻节点之间存在3个空洞。所以空洞卷积的感受野为:(kernel_size+1)*(rate-1)+kernel_size。
所以所谓的空洞卷积就是在标准卷积核中注入“空洞”,以增加卷积核的感受野,空洞卷积引入了扩张率(dilation rate)这个超参数来指定相邻采样点之间的间隔:扩张率为r的空洞卷积,卷积核上相邻节点之间有r-1个空洞。空洞卷积利用空洞结构扩大了卷积核的尺寸,不经过下采样操作即可增大感受野,同时还能保留输入数据的内部结构。
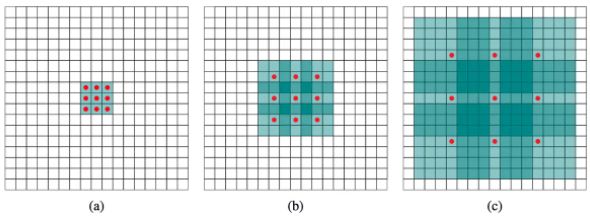
图2 空洞卷积(Atrous Convolution)
ASPP模块
Decoder的模型结构可以使用的就是常用的分类网络(如ResNet),这一点没什么好说的,这里主要介绍一下ASPP模块。如图3所示。

图3 ASSP模块
前面我们说过,在分割中特征中包含丰富的上下文信息对分割算法来说非常重要,ASSP模块中并行的不同rate的空洞卷积可以较好的解决这一点。ASPP模块主要包含以下几个部分: (1) 一个1×1卷积层,以及三个3x3的空洞卷积,当output_stride=16,其rate为(6, 12, 18) ,若output_stride=8,则rate加倍(这些卷积层的输出channel数均为256,并且含有BN层);(2)一个全局平均池化层得到image-level特征,然后送入1x1卷积层(输出256个channel),并双线性插值到原始大小; (3)将5个并行分支的输出通过concat合并到一起,然后经过一个1x1的卷积得到256个通道的新特征。ASPP模块与PSPNet(Pyramid Scene Parsing Network)中的金字塔池化模块非常相似,作用也大同小异,如图4所示,主要区别就是ASPP中使用的是不同rate的空洞卷积,而PSPNet中使用的是不同尺度的池化核的池化层。
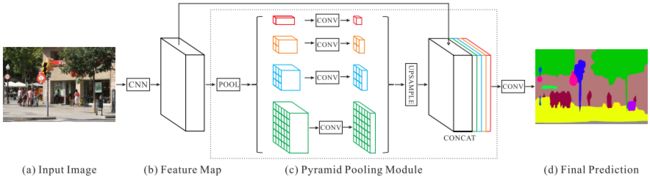
图4 PSPNet中的金字塔池化层
Decoder
经过Encoder处理,特征图的大小变成了原图的1/8或1/16,如果直接通过插值resize到原图大小则太过粗暴,不利于特别精细的分割结果,这一点在FCN中得到了验证。而Decoder则负责通过一些合理的方式逐步恢复到原图大小。如图5所示,首先将Encoder得到的特征双线性插值到原图的1/4大小,然后与Encoder中的低级特征concat,如ResNet50中的layer2的输出,由于Decoder的低级特征的通道维度比较高,可能远超过Decoder的特征通道维度,如果直接concat会把Decoder输出的特征淹没掉,所以低级特征会首先经过一个1x1的卷积降维(论文中将低级特征的通道维度降到了48),然后再将二者concat,接着采用一个3x3的卷积进一步融合特征,最后经过4倍的双线性插值上采样到原图大小,得到最后的分割结果。
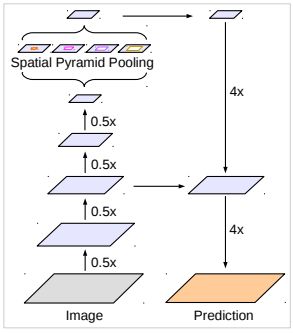
图5 Decoder(右半部分为Decoder,该图为原文剪切下来的,实在抱歉)
改进的Xception模型
DeepLabv3所采用的backbone是ResNet网络,在v3+模型作者尝试了改进的Xception,Xception网络主要采用depthwise separable convolution,这使得Xception计算量更小。改进的Xception主要体现在以下几点: (1)参考MSRA的修改(Deformable Convolutional Networks),增加了更多的层; (2)所有的最大池化层使用stride=2的depthwise separable convolutions替换,这样可以改成空洞卷积 ; (3)与MobileNet类似,在3x3 depthwise convolution后增加BN和ReLU。如图6所示。
采用改进的Xception网络作为backbone,DeepLab网络分割效果上有一定的提升。作者还尝试了在ASPP中加入depthwise separable convolution,发现在可以基本不影响模型效果的前提下减少计算量。
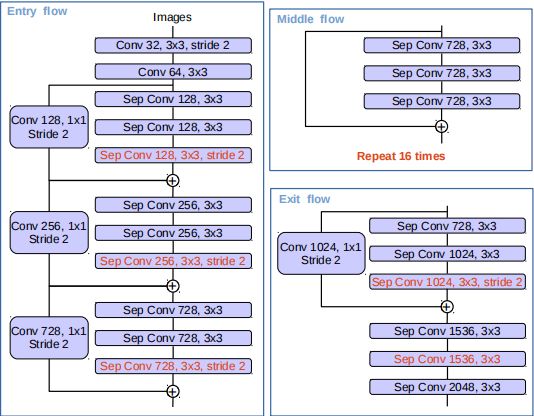
图6 改进的Xception
实验结果
如图7所示,DeepLabV3+在VOC数据集上取得了非常好的分割效果,知道现在依然是最好的分割算法之一。

图7 实验结果
小结
DeepLabV3+算法作为DeepLab系列算法中表现最好的算法,也是目前最好的分割算法之一,的确值得好好学习和品味,当前的很多分割算法也都是在DeepLab算法的基础上进行扩展和改进。当然对于一些要求低时延的分割场景,DeepLabV3+模型的计算复杂度稍高一些,需要一些更加轻量级的模型,目前也是图像语义分割的研究热点之一。
参考文献
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation