激光点云语义分割算法:RangeNet++
激光点云语义分割算法:RangeNet++
RangeNet++简介
RangeNet++是一篇发表在IROS 2019上的论文《RangeNet++: Fast and Accurate LiDAR Semantic Segmentation》中提出的一个激光点云语义分割算法,该算法将激光点云通过球面投影转换为距离图像(Range Images),然后在距离图像上用二维卷积神经网络提取特征进行语义分割。为了获得精确的分割效果,作者还提出了一种新的后处理算法用于处理由于投影变换带来的离散化误差或者卷积神经网络模糊的输出结果。实验结果表明,RangeNet++的语义分割效果胜过已有的其他算法,并且可以在单个嵌入式GPU上实时运行。
论文地址: https://www.ipb.uni-bonn.de/wp-content/papercite-data/pdf/milioto2019iros.pdf
代码地址: https://github.com/PRBonn/lidar-bonnetal
实现方法
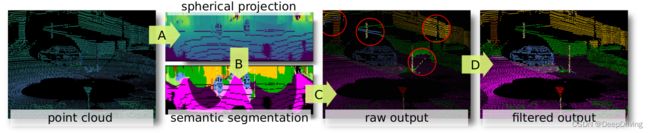
RangeNet++提出的点云语义分割方法分为如下图所示的4个步骤:
A. 点云投影
B. 全卷积语义分割
C. 从距离图像中重建点云
D. 高效的点云后处理
A. 点云投影
很多激光雷达传感器(比如Velodyne激光雷达)通常以类似于距离图像的方式来表示原始的输入数据:每一列表示一组激光测距仪在某个时间点测量到的距离值,而每一行则代表每个测距仪在不同转向位置上测量到的距离值。为了得到全部激光点云精确的语义分割结果,RangeNet++的第一步是通过球面坐标将每个三维空间的点 p i = ( x , y , z ) p_{i}=(x,y,z) pi=(x,y,z)转换到由距离图像表示的二维空间,转换公式如下:
( u v ) = ( 1 2 [ 1 − arctan ( y , x ) / π ] w [ 1 − ( arcsin ( z / r ) + f u p ) / f ] h ) \begin{pmatrix} u \\ v \end{pmatrix}=\begin{pmatrix} \frac{1}{2}\left [ 1-\arctan (y,x) / \pi \right ]w \\ \left [ 1-(\arcsin (z/r)+f_{up})/f \right ]h \end{pmatrix} (uv)=(21[1−arctan(y,x)/π]w[1−(arcsin(z/r)+fup)/f]h)
其中, ( u , v ) (u,v) (u,v)分别表示在距离图像中的横、纵坐标; ( w , h ) (w,h) (w,h)分别表示距离图像的宽和高; f = f u p + f d o w n f=f_{up}+f_{down} f=fup+fdown表示激光雷达的垂直视场角; r = x 2 + y 2 + z 2 r=\sqrt{x^{2}+y^{2}+z^{2}} r=x2+y2+z2表示每个点的距离值(range)。
根据上面的公式,我们就可以得到每个三维空间的点到二维图像空间的对应索引关系。通过这个索引关系,就可以把一帧点云转换为 [ 5 × h × w ] \left [ 5\times h\times w \right ] [5×h×w]的张量,其中的5个通道分别对应点云的 r a n g e , x , y , z , i n t e n s i t y range,x,y,z,intensity range,x,y,z,intensity这5个属性。下图是将SemanticKITTI数据集中的某帧点云进行转换后,对range通道可视化的结果:
![]()
B. 全卷积语义分割
通过上一步将点云转换为距离图像后,得到了一个尺寸为 [ 5 × h × w ] \left [ 5\times h\times w \right ] [5×h×w]的张量,这个张量将被送入一个encoder-decoder结构的全卷积语义分割网络RangeNet53中进行处理,网络如下图所示。
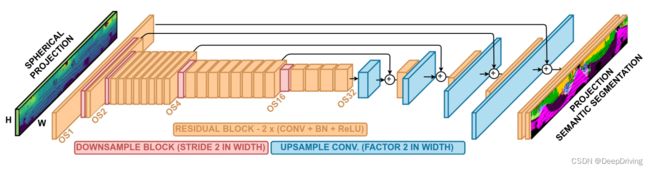
在前面的encoder网络中,会对输入特征图做逐级下采样,最大的下采样倍数为32倍。encoder操作做完后紧接着是一个decoder的网络,用于对特征图做上采样以恢复到原始输入图像的大小。每级上采样操作做完后还会将前面encoder网络中对应尺寸的输入结果进行相加,这样做的目的是恢复一些由于下采样操作而丢失的高频边缘信息。decoder网络后面是一组 [ 1 × 1 ] [1 \times 1] [1×1]的卷积,用于生成尺寸为 [ n × h × w ] [n \times h \times w] [n×h×w]的输出张量,其中 n n n代表训练数据集中语义类别的数量。这个 [ n × h × w ] [n \times h \times w] [n×h×w]的输出张量表示的是,在一个尺寸为 [ h × w ] [h \times w] [h×w]的距离图像中每个像素属于某个语义类别的置信度,这个置信度是由softmax函数计算产生的,我们只要取 n n n个类别中置信度最大的那个作为最终的语义类别即可。在训练过程中,作者采用了一个加权的交叉熵损失函数:
L = − ∑ c = 1 C w c y c log ( y c ^ ) L=-\sum_{c=1}^{C} w_{c}y_{c}\log_{}{(\hat{y_{c}}) } L=−c=1∑Cwcyclog(yc^)
其中
w c = 1 log ( f c + ϵ ) w_{c}=\frac{1}{\log_{}{(f_{c}+\epsilon )} } wc=log(fc+ϵ)1
f c f_{c} fc表示属于类别 c c c的数据出现的频率, w c w_{c} wc相当于一个惩罚因子用于处理训练数据中类别不均衡的情况:该类别数据出现的频率越大那么这个惩罚因子会使得它对总损失的贡献越小。
encoder网络是由Darknet53修改而来,网络的输入由原来的3通道图像变为5通道的图像。由于是处理64线激光雷达的数据,该类型的激光雷达扫描一圈会产生大约130000个点,所以输入图像的高h设置为64。由130000/64=2031.25,取一个接近于该值且是2的n次幂的数,那么图像的宽w可以设置为2048。为了保留垂直方向的信息,encoder网络中的下采样操作仅针对水平方向而垂直方向会保持不变。
C. 从距离图像中重建点云
从距离图像映射回点云的常见做法是使用距离信息、像素坐标、传感器内部标定信息实现从二维到三维的映射。然而存在的一个问题是,由于我们是从点云生成距离图像的,意味着转换过程中会丢失相当数量的点,这种情况在使用小尺寸的距离图像时会更明显。比如,如果将一帧含有130000个点的点云转换为尺寸为 [ 64 × 512 ] [64 \times 512] [64×512]的距离图像,那么只有32768个点的信息被保留在距离图像中。因此,为了从语义图像中推断出所有原始点云的语义信息,RangeNet++采用的方法是在第一步的时候为每个点保存一个该点在距离图像中的坐标索引 ( u , v ) (u,v) (u,v),通过这个坐标索引就可以从语义图像中查找到点云中每个点对应的语义标签。
D. 高效的点云后处理
encoder-decoder结构的全卷积语义分割网络会导致模糊不清的语义分割结果,有些算法(比如SqueezeSeg)采用条件随机场(CRF)来解决二维语义分割中的“渗色”问题,但是这种方法并不能解决从二维图像空间重投影到三维空间引起的“阴影”问题,因为原始的点云可能会有多个点被投影到距离图像的同一个坐标上,那么这些点得到的语义标签是一样的,这种情况在使用小尺寸的距离图像时会更严重。下图展示了这种“阴影”问题,左图是二维图像的语义分割结果,右图是重投影后三维点云的语义分割结果,红色框内是重投影后产生的“阴影”。
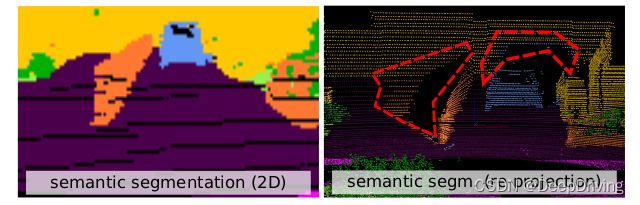
为了解决这个问题,RangeNet++提出了一种直接在输入点云上操作、使用GPU加速的快速k最近邻(k-nearest neighbor,kNN)搜索算法,该算法可以为语义点云中的每个点找到最接近的k个点的共识投票(consensus vote)。与普通的kNN算法一样,作者也设置了一个搜索范围阈值,该阈值设定了最大允许距离,在这个距离内的点才会被认为是近邻点。用于对k个最近点进行排序的度量可以是距离值(range)的绝对值之差,或者是欧式距离。作者也尝试用点云反射强度作为惩罚项,但是并没有起什么作用。
这个kNN后处理算法的具体实现流程在论文里有比较详细的描述,有兴趣的可以直接去看论文。
总结
RangeNet++针对旋转扫描式激光雷达传感器产生的点云提出了一种精确且快速的点云语义分割算法框架,它将点云转换为距离图像然后用二维卷积神经网络实现语义分割,并且采用一种基于GPU加速的后处理算法进一步提升全部点云的语义分割结果。实验结果表明,RangeNet++在分割精度和运行效率方面都达到了state-of-the-art的水平。
参考资料
RangeNet++: Fast and Accurate LiDAR Semantic Segmentation