Simple-BEV: 多传感器BEV感知真正重要的是什么?(斯坦福大学最新)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
后台回复【多传感器融合综述】获取图像/激光雷达/毫米波雷达融合综述等干货资料!
Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?
不依赖高密度激光雷达的无人驾驶车辆,构建3D感知系统是一个很关键的问题,因为与camera和其他传感器相比,激光雷达系统的成本较高。最近的工作开发了多种仅camera的方法,其中特征可从多camera图像“提升”到2D ground plane,从而生成3D空间的“鸟瞰图”(BEV)特征表示。这一系列工作产生了多种新颖的“提升”方法,但训练设置中的其他细节同时也发生了变化,这使得大家不清楚什么是最佳方法。除此之外,考虑到像radar这样的附加传感器已经集成到实际车辆中多年,仅使用camera并不是一个严格的限制。本文首先试图阐明BEV感知模型的设计和训练中的高影响因素,发现bs大小和输入分辨率对性能有很大的影响,而提升策略的影响较小,即使一个简单的无参数提升器也能很好地工作。其次,证明了radar数据可以极大地提高性能,有助于缩小仅camera的系统和支持激光雷达的系统之间的差距,论文还分析了产生良好性能的radar使用细节。
虽然这一进展令人鼓舞,但对创新和准确性的关注以系统简单性为代价,并有可能掩盖对性能提升“真正重要的”内容。将2D图像平面上的特征“提升”到BEV上,一直是人们关注的焦点。例如,一些工作探索了使用homographies 将特征直接扭曲到ground plane,使用深度估计将特征放置在其近似3D位置,使用具有各种几何偏差的MLP,以及最近使用几何感知transformer和跨空间时间的变形注意力机制。与此同时,实施细节已逐渐转向使用更强大的主干和更高分辨率的输入,这使得很难衡量这些发展对提升的实际影响。
本文提出了一个模型,其中“提升”操作是无参数的,不依赖于深度估计:只需在BEV平面上定义一个三维坐标volume ,将这些坐标投影到所有图像中,并平均从投影位置采样的特征。当这个简单的模型得到很好的调整时,它的性能超过了最先进的模型,同时速度更快,参数效率更高。论文测试了batch size、图像分辨率、数据增强和2D到BEV提升策略的独立影响,并从经验上表明,选择好的输入分辨率和bs大小可以将性能提高10点以上(所有其它因素保持不变),而最差和最好的lifting 方法之间的差异只有4分,这尤其令人惊讶,因为lifting 方法一直是早期工作的重点。
论文指出,通过合并来自Radar的输入,可以显著改善结果。虽然最近的工作重点是使用摄像机和/或激光雷达,但Radar传感器已经集成到实际车辆中很多年了,camera加Radar的性能远远好于单独使用camera。虽然仅使用相机可能会使任务具有一定的纯度(需要从2D输入进行3D估计),但它并不能反映自动驾驶的真实应用场景,因为噪声数据不仅可以从radar获得,还可以从GPS和里程计获得。最近几项在语义BEV映射环境中讨论雷达的工作得出结论,数据通常太稀疏,无法使用[3]。这些先前的工作仅评估了Radar的使用,避免了多模态融合问题,并且可能错过了RGB和雷达相互补充的机会。本文引入了一种简单的RGB+雷达融合策略(将BEV中的雷达光栅化,并将其与RGB特征连接起来),其性能比所有已发布的BEV分割模型高出9个百分点。本文有两个主要贡献:首先,阐述了BEV感知模型设计和训练中的高影响因素。特别指出,bs大小和输入分辨率极大地影响性能,而解除细节的效果则较为温和。其次,证明了毫米波雷达数据可以通过简单的融合方法大幅提高性能。
领域工作介绍
在之前的密集BEV解析工作中,一个主要的区别是将2D透视图特征“提升”到3D或直接提升到ground plane,主要有以下几种方法:
无参数unprojection:在各种目标和场景表示模型[15、16、17]中采用的这种策略,使用相机几何体定义体素与其投影坐标之间的映射,并沿体素的3D光线将2D特征复制到体素。本文特别遵循Harley et al.[18]的实现,该实现对每个3D坐标的子像素2D特征进行双线性采样,无参数提升方法通常不用于鸟瞰图解析任务。
Depth-based unprojection:有几项工作使用单目深度估计器估计每像素深度,要么为深度估计预处理[8、19、20],要么只为最终任务训练[9、21、22],并使用深度将特征放置在其估计的3D位置,这是一种有效的策略。
基于霍夫变换的unprojection: 有些工作估计ground plane而不是逐像素深度,并使用将图像与地面关联的单应性来创建warp [23、24、7],将特征从一个平面转移到另一个平面,当场景本身是非平面时,此操作往往会产生较差的结果。
MLP-based unprojection:一种流行的方法是使用MLP将图像特征的垂直轴条转换为地平面特征的前轴条[4,10,25]。这里的一个重要细节是,初始地平面特征被视为与相机平截头体对齐,因此它们被使用相机内部函数wrap成直线空间。这类作品中的一些作品使用了多个MLP,专门用于不同的尺度[26,11]或不同的类别[12]。由于该MLP参数较多,Yang等人[27]提出了一种循环一致性损失(向后映射到图像平面特征)来帮助规范它!
基于几何感知transformer:BEVFormer建议使用可变形注意操作来收集预定义3D坐标网格的图像特征,这类似于无参数unprojection中的双线性采样操作。
毫米波雷达:在汽车行业,Radar已经较为成熟了,由于毫米波雷达测量提供位置、速度和角度方向,因此数据通常用于检测障碍物,并估计移动目标的速度。与激光雷达相比,radar的射程更长,对天气影响的敏感度更低,成本也更低。不幸的是,毫米波雷达固有的稀疏性和噪声使其难以使用[28,29,30,29,31]。一些早期方法使用毫米波雷达进行BEV语义分割任务,与本文的工作非常相似[28,32,29],但仅限于小数据集。nuScenes基准[33]最近的工作报告称,数据过于稀疏,无法使用,建议使用其它传感器设置的更高密度Radar数据。最近的一些作品探索了RGB-毫米波雷达或RGB激光雷达融合策略[23,30],但侧重于检测和速度估计,而非BEV语义标记。
Simple-BEV Model
本节将描述基本BEV mappping模型的结构和训练设置,并在实验中对其进行修改,以研究哪些因素对性能最重要!
设置和概述
本文的模型从camera、radar甚至激光雷达(LiDAR)获取输入,假设数据是跨传感器同步的,假设传感器的内部结构和相对位置是已知的。根据本任务中的基线,将左/右和前/后跨度设置为100m×100m,以200×200的分辨率离散,我们将上/下跨度设置为10m,并且以8的分辨率离散化。此volume 根据参考camera(通常为前camera)居中和定向。用X表示左右轴,用Y表示上下轴,用Z表示前后轴。根据相关工作,首先应用2D ResNet来计算每个相机图像的特征,然后提升到3D,然后reduce到BEV平面,最后在BEV中应用2D ResNet来获得输出。这些步骤如图1所示,论文的提升步骤与之前的工作有细微的不同:虽然有些工作沿着其对应的3D射线“splot”2D特征[9,21],但本文从3D坐标开始,并为每个体素进行双线性采样子像素特征。如果提供了毫米波雷达或激光雷达,将这些数据光栅化为鸟瞰图,并在压缩垂直尺寸之前将其与3D特征体积连接起来。
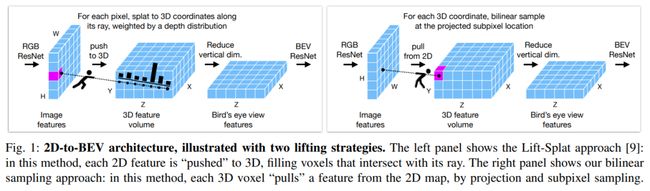
结构设计
论文对每个输入RGB图像进行特征化,形状为3×H×W,使用ResNet-101主干。对最后一层的输出进行升采样,并将其与第三层的输出连接起来,应用两个卷积层,并进行实例归一化和ReLU激活,得到形状为C×H/8×W/8(图像分辨率的八分之一)的特征map。将预定义的三维坐标volume 投影到所有特征地图中,并在那里进行双线性采样,从每个相机生成3D特征volume 。同时计算每个相机的二进制“有效”volume ,表明3D坐标是否落在相机平截头体内。然后,在volume 集合中取有效的加权平均值,将表示减少到单个3D特征volume ,形状为C×Z×Y×X。然后重新排列轴,使垂直尺寸延伸通道尺寸,如C×Z×Y×X→ (C·Y)×Z×X,生成高维BEV特征图。
如果提供了radar,可以将其栅格化,以创建另一个与基于RGB的map具有相同空间维度的BEV特征地图。使用任意数量的Radar通道R(包括R=0,表示没有Radar)。在nuScenes中,每个Radar返回18个字段,其中5个是位置和速度,其余是内置预处理的结果(例如,表示返回有效的置信度)。论文使用所有这些数据,通过使用位置数据选择网格上最近的XZ位置(如果在边界内),并使用15个非位置项作为通道,生成一个形状为R×Z×X,R=15的BEV特征图。如果提供了LiDAR,将其体素化为Y×Z×X形状的二元占用栅格,并使用它代替radar特征。然后,连接RGB特征和雷达/LiDAR特征,并通过应用3×3卷积核将扩展通道压缩到维度C。这实现了减少(C·Y+R)×Z×X→ C×Z×X。此时,我们有一个单一的特征平面,表示场景的鸟瞰图。使用ResNet-18的三个block处理这一点,生成三个特征图,然后使用双线性上采样的附加跳跃连接,逐渐将较粗的特征提高到输入分辨率,最后应用两个卷积层作为分割任务头。继FIERY[21]之后,本文用辅助任务头来补充分割头,以预测中心度和偏移量,从而使模型正规化。偏移头生成一个向量场,其中,在每个目标mask内,每个向量都指向该对象的中心。用交叉熵损失训练分割头,并用L1损失监督中心度和偏移场。论文使用基于不确定性的可学习加权[36]来平衡这三种损失。3D分辨率为200×8×200,最终输出分辨率为200 x 200。本文的3D公制metric为100m×10m×100m。这对应于0.5m×1.25m×0.5m的体素长度(按Z、Y、X顺序),使用128的特征尺寸(即通道尺寸C)。ResNet-101在COCO 2017上进行了物体检测预处理。BEV ResNet-18是从头开始训练的。本文使用Adam-W优化器,使用5e-4的学习率,对25000次迭代进行端到端训练。
研究的关键因素
Lifting策略
本文的模型比相关工作“简单”,特别是在二维到三维提升步骤中,该步骤由(无参数)双线性采样处理。例如,这取代了随后的深度估计、MLPs或注意机制。策略可以理解为“Lift Splat without depth estimation”,但如图1所示,论文的实现在一个关键细节上有所不同:方法依赖于采样而不是splatting。从体素的3D坐标开始,并对每个体素进行双线性采样。由于相机投影,close-up rows的体素从图像中采样非常稀少(即更分散),而远处的行体素采样非常密集(即更密集),但每个体素都接收一个特征。Splattingbased的方法从二维坐标网格开始,沿着射线“拍摄”每个像素,以固定的深度间隔填充与射线相交的体素。因此,splatting方法可以为最接近的体素生成多个采样,并且非常远处体素的采样很少(有时为零)。
正如将在实验中显示的那样,此实现细节对性能有影响,因此在短距离上splatting 稍微好一些,而在长距离上采样稍微好一些。在实验中,还评估了最近提出的deformable attention策略[5],它是类似于双线性采样,但具有每个体素的学习采样核(即,学习的权重和学习的偏移)。
输入分辨率
虽然早期BEV方法在通过模型输入RGB之前对其进行了大量的降采样(例如,降采样到128×352[9]),但我们注意到最近的工作已经越来越少地降采样(比如,最近使用的是全分辨率[13,5])。我们认为这是性能的一个重要因素,所以我们在不同的输入分辨率下训练和测试我们的RGB模型。在我们的模型的不同变体中,我们尝试从112×208到896×1600的分辨率。
batch size大小
大多数关于BEV细分的相关工作在训练中使用相对较小的bs大小。图像分类文献中已报道,更大的批次大小可获得更好的结果,但尚未看到将bs大小作为BEV性能进行讨论的文献。这可能是因为BEV模型对内存的要求很高:有必要使用大容量模块并行处理所有6个摄像头图像,并且根据具体实施情况,有时有必要在将表示减少为BEV之前存储3D体积的特征。为了克服这些内存问题,本文跨多个步骤和多个GPU累积梯度,并以每个梯度步骤较慢的挂钟时间为代价获得任意大的有效bs大小。例如,它需要我们aprrox,5秒累积向前和向后传播,创建40个批次大小,即使并行使用8个A100 GPU。然而,本文的训练时间与之前的工作相似:根据输入分辨率,模型在1-3天内收敛。
数据增强
之前的工作建议使用相机dropout 和各种基于图像的增强,但尚未看到这些因素的量化。论文在训练时进行多次强化实验,并测量其独立效果:
(1) 在RGB输入上应用随机大小调整和裁剪,比例范围为[0.8,1.2](并相应更新内部函数);
(2) 随机选择一个相机作为“参考”相机,它可以随机化3D volume 的方向(以及光栅化注释的方向);
(3) 随机丢弃了六台摄像机中的一台。
在测试时,使用“前”摄像头作为参考摄像头,不进行裁剪。
Radar使用细节
之前的工作报告称,nuScenes中的雷达数据太稀疏,无法使用[3],10],但论文假设,它可能是一个有价值的度量信息来源,而目前只有相机设置缺乏。除了是否简单使用雷达外,模型在以下方面具有灵活性:(1)使用雷达元数据作为附加通道,对比将雷达视为二值占用图像,(2)使用传感器的原始数据,对比使用异常值过滤输入,以及(3)使用从多次扫描中积累的雷达,对比仅使用时间同步数据。
实验
本文的实验首先旨在统一研究影响BEV分割模型性能的因素,包括提升策略等高兴趣细节,以及分辨率和批量大小等很少讨论的细节。其次,旨在量化雷达在这一领域的效用,并揭示最大化性能的使用细节。最后,将与最先进的技术进行比较。
数据集:在nuScenes城市场景数据集中训练和测试所有模型,该数据集公开供非商业用途。该数据集有6个相机,分别指向前方、左前方、右前方、左后方、后方和右后方,以及5个雷达单元,分别指向前部、左侧、右侧、左后方和右后侧,以及一个激光雷达单元。只使用激光雷达输入进行比较,重点是使用RGB和RGB+雷达。论文使用正式的nuScenes训练/验证分割,它在训练集中包含28130个样本,在验证集中包含6019个样本。遵循官方Lift Splat[9]代码库中的分割任务设置,其中“车辆”边界框内的任何点都被视为正标签,所有其它位置都被赋予负标签。“车辆”超类包括自行车、公共汽车、小汽车、建筑车辆、应急车辆、摩托车、拖车和卡车,使用相交于并(IOU)度量进行评估。
性能因素的统一研究提升策略
本文的模型使用双线性采样策略将图像特征提升到BEV平面上,之前的工作已经开发了多种复杂的替代方法,但由于每项工作中的各种实施细节都会发生变化,因此不清楚lifting方法在性能上有多大差异。在表一中给出了一个apples-to-apples的比较,匹配分辨率、批量大小、主干和模型之间的扩展。

发现双线性采样和变形注意力的表现类似,而splatting 方法落后了。多尺度可变形注意力(如BEVFormer[5])表现最好,但代价是速度(训练慢1天,测试时慢0.5 FPS)和复杂性(59M参数而不是42M,需要定制CUDA内核)。还注意到,均匀(未加权)splatting 仅比深度加权splatting 差约1分(与FIERY[21]中观察到的结果一致),这表明大部分场景结构在近似BEV提升后得到解决。
图2显示了采样与深度加权splatting 的跨距离IOU细分,表明splatting 在短距离上具有优势,而在长距离上采样效果更好。论文注意到,评估的所有结果都高于介绍这些方法的工作中报告的结果,这表明训练设置中的其它细节正在产生重大影响。正如在下一小节中所展示的,这里的主要因素是输入分辨率和批大小。
输入分辨率
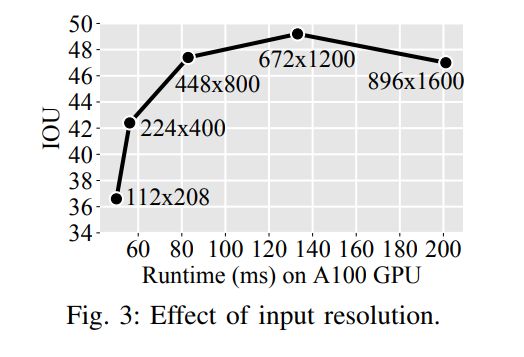
本文测量模型的性能如何随输入分辨率而变化,使用相同的分辨率进行训练和测试,图3总结了结果。使用低于448×800的分辨率会大大降低性能。论文的最佳成绩是49.3 IOU,为672×1200。然而,该模型比47.4 IOU 448×800模型慢得多(133 ms vs 83 ms),并且需要将近两倍的训练时间。结果以最高分辨率下降,可能是因为当图像如此大时,目标比例不再与主干的预训练一致,导致传输效率降低。使用替代的主干架构,高分辨率的性能可能会提高[43]。
批次大小
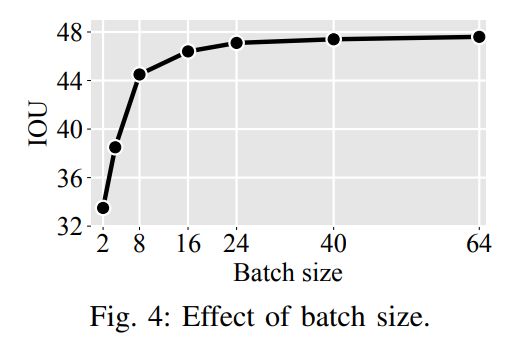
在图4中,探讨了批次大小对模型性能的影响:批次大小的每一次增加都会提高准确性,同时回报也会减少(但数量可观)。将批次大小从2增加到40可以使借据提高近14个百分点。考虑到大多数以前的工作使用的批量小于16,这表明许多现有方法可能会从简单的再训练中受益!
主干
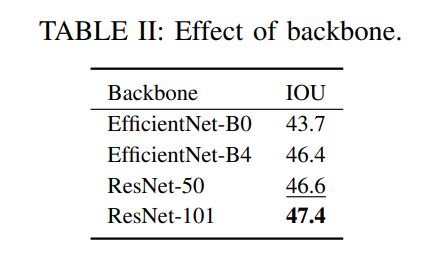
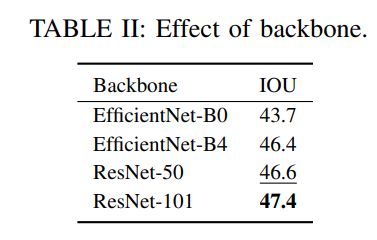
最近的工作一直在使用越来越深的主干作为模型的一部分,该部分根据输入的相机图像创建特征地图(在2D到BEV提升之前)。Lift Splat[9]使用EfficientNet-B0[44],FIERY[21]使用EffecientNet-B4[44]、TIIM[13]使用ResNet-50[34],最近BEVFormer[5]使用了ResNet101[34]。本文在表II中为自己的模型探索了这些选择,发现正如预期的那样,更大的主干提供更好的结果,ResNet-101优于其它主干。然而,我们注意到,特定主干的好处有时与输入分辨率有关,此处固定为448×800。要充分利用可用的900×1600数据,可能需要进一步研究架构细节。
数据增强
在训练论文的模型时,随机地将每个相机的图像调整到目标分辨率的[0.8,1.2]以内,并将其放置在距中心的随机偏移处。表IIIa显示,该增加量提高了1.6%。当还随机选择相机作为“参考”相机时,它指示3D坐标系的方向。在表IIIb中显示了这种增加的结果,对参考相机进行随机化可使IOU增加0.6%。
论文相信,随机选择参考相机有助于减少鸟瞰模块中的过拟合,定性地观察到,如果没有这种增强,分段车在某些位置的某些方向上会有轻微偏差;随着增加,这种偏差消失了。之前的研究报告称,在每个训练样本中随机丢弃6个可用摄像头中的1个摄像头会带来好处[9]。如表IIIc所示,发现相反的情况:使用所有相机表现更好。这可能是因为我们的参考相机随机化提供了足够的正则化,使得相机不必退出。论文还试验了光度增强(模糊、颜色、对比度),但发现它们没有帮助。

多模态融合分析
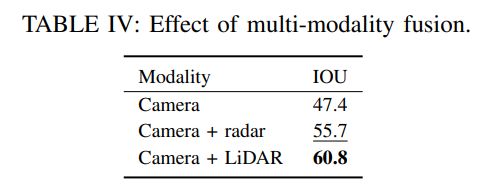
为了分析不同模态组合的性能,论文比较了仅camera、camera加雷达、camera加激光雷达,见表四。正如假设的那样,雷达确实改善了结果。相对于仅使用相机的模型,雷达将结果提高了8点,而激光雷达将结果提升了13点。LiDAR的高性能与3D物体检测的相关工作相一致[1],但RGB+LiDAR和RGB+雷达之间的差距小于预期,因为之前的工作传达了RGB+融合的负面结果[10]。
在图5中显示了定性结果,可视化了相应的雷达数据。定性而言,如相关工作[10,3]所述,雷达确实稀疏且嘈杂,但论文相信它对度量场景结构给出了有价值的提示,当与从RGB获取的信息融合时,可以在鸟瞰图中实现更高精度的语义分割。接下来,将更详细地研究雷达性能因素,如表Va所示,本文的模型受益于访问与每个雷达点相关的元数据,这包括速度等信息,可能有助于区分移动对象和背景。取消此相位可将借据降低0.7点。如表Vb所示,模型受益于将所有雷达返回作为输入,通过禁用nuScenes内置的异常值过滤策略实现。过滤策略试图丢弃异常点(由多径干扰和其他问题产生),但也可能丢弃一些真实的返回。使用过滤数据而不是原始数据会导致性能下降2点。如表Vc所示,模型得益于将雷达的多次扫描作为输入进行聚合。

与最先进技术的比较
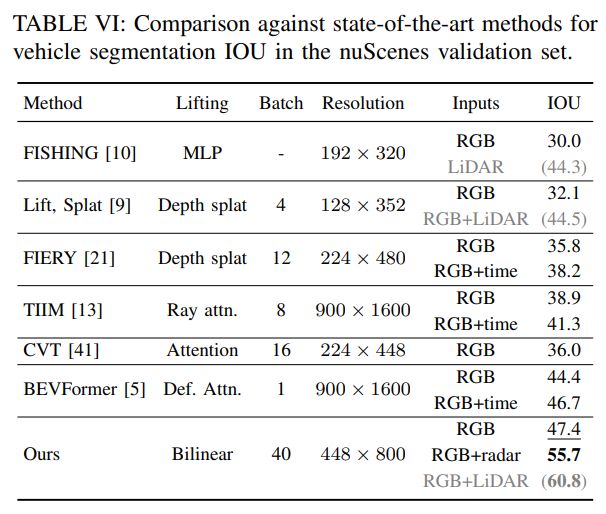
在表VI中,展示了论文的RGB模型略优于所有其它基于RGB和时间模型,而RGB+雷达模型比其他模型高出9个点。本文的模型有42M个参数,与BEVFormer的68.7M相比,这是相当有效的。大多数参数(37M)来自ResNet-101,这也是主要的速度瓶颈。在这种设置中,本文的模型也比BEVFormer快3倍(在V100 GPU上,7.3 FPS比2.3 FPS),这主要是因为使用了较低的RGB分辨率。

参考
[1] Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?
往期回顾
BEVStereo | nuScenes纯视觉3D目标检测新SOTA!(旷视、中科大)
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
