DW李宏毅机器学习笔记--Task04(上)-深度学习简介
文章目录
- 前言
- 深度学习的发展历程
- 深度学习的三个步骤
-
- Step1:神经网络
- 网络结构
-
- 完全连接前馈神经网络
- 全链接和前馈的理解
- 深度的理解
- 矩阵计算
- Step2: 模型评估
- Step3:选择最优函数
- 思考
-
- 隐藏层越多越好?
- 普遍性定理
- 总结
前言
这是我在Datawhale组队学习李宏毅机器学习的记录,既作为我学习过程中的一些记录,也供同好们一起交流研究,之后还会继续更新相关内容的博客。
深度学习的发展历程
先回顾一下deep learning的历史:
-
1958: 感知机(线性模型)被提出
-
1969: 正式提出感知机存在一定的局限
-
1980s: 提出多层感知机,已经和现在的多次神经网络没有太大的区别了
-
1986: 提出反向传播,并发现多于3层的隐藏层对其是没有帮助的
-
1989: 提出:一个隐藏层 就已经“足够好”了,为什么要更深?
-
2006: 受限玻尔兹曼机(RBM)的广泛使用 (突破性进展)
-
2009: 开始使用GPU,极大地加速了训练的效率
-
2011: 深度学习开始流行于语音识别
-
2012: 赢得 ILSVRC 图像竞赛
感知机(Perceptron)非常像我们的逻辑回归(Logistics Regression)只不过是没有
sigmoid激活函数。09年的GPU的发展是很关键的,使用GPU矩阵运算节省了很多的时间。
深度学习的三个步骤
机器学习有三个步,对于deep learning其实也是3个步骤:
- Step1:建立神经网络(Neural network)
- Step2:对模型评估(Goodness of function)
- Step3:选择最优函数(Pick best function)
那对于深度学习的Step1就是建立神经网络(Neural Network)
Step1:神经网络
神经网络(Neural network)里面的节点,类似我们的神经元。
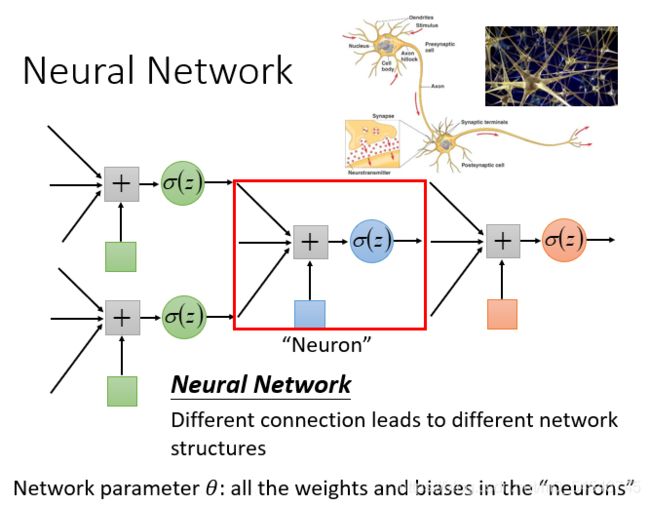
神经网络也可以有很多不同的连接方式,这样就会产生不同的结构(structure)在这个神经网络里面,我们有很多逻辑回归函数,其中每个逻辑回归都有自己的权重和自己的偏差,这些权重和偏差就是参数。 这些神经元的连接方式则是自己手动设置的。
而这种“神经元形式”就是M-P模型,在M-P模型中,神经元接受其他神经元的输入信号(0或1),这些输入信号经过权重加权并求和,将求和结果与阈值(threshold) θ 比较,然后经过激活函数处理,得到神经元的输出。
通过设置权重 w w w和偏差 θ {θ} θ可以使单个神经元表示多种逻辑操作。
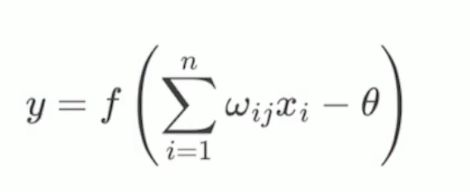
网络结构

完全连接前馈神经网络
概念:前馈(feedforward)也可以称为前向,从信号流向来理解就是输入信号进入网络后,信号流动是单向的,即信号从前一层流向后一层,一直到输出层,其中任意两层之间的连接并没有反馈(feedback),亦即信号没有从后一层又返回到前一层。

- 已知权重和偏差时输入 ( 1 , − 1 ) (1,-1) (1,−1)的结果
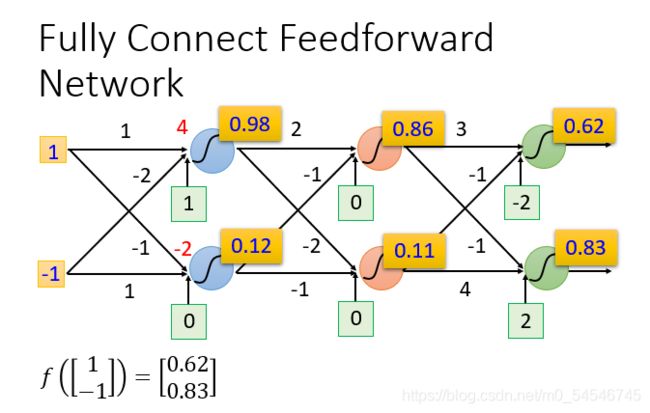
上图是输入为1和-1的时候经过一系列复杂的运算得到的结果
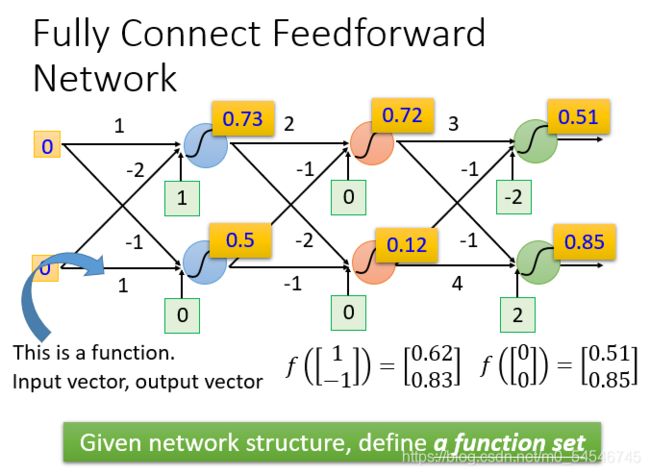
当输入0和0时,则得到0.51和0.85,所以一个神经网络如果权重和偏差都知道的话就可以看成一个函数,他的输入是一个向量,对应的输出也是一个向量。不论是做回归模型(linear model)还是逻辑回归(logistics regression)都是定义了一个函数集(function set)。我们可以给上面的结构的参数设置为不同的数,就是不同的函数(function)。这些可能的函数(function)结合起来就是一个函数集(function set)。这个时候你的函数集(function set)是比较大的,是以前的回归模型(linear model)等没有办法包含的函数(function),所以说深度学习(Deep Learning)能表达出以前所不能表达的情况。
我们通过另一种方式显示这个函数集:
全链接和前馈的理解
- 输入层(Input Layer):1层
- 隐藏层(Hidden Layer):N层
- 输出层(Output Layer):1层

- 为什么叫全链接呢?
- 因为layer1与layer2之间两两都有连接,所以叫做Fully Connect;
- 为什么叫前馈呢?
- 因为现在传递的方向是由后往前传,所以叫做Feedforward。
深度的理解
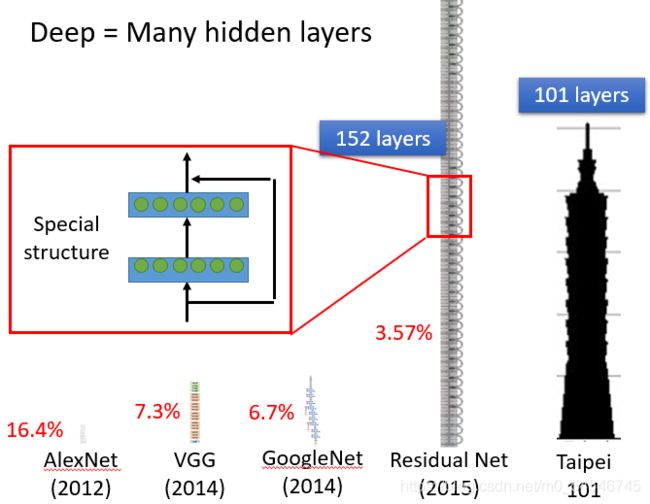
那什么叫做Deep呢?Deep = 很多的隐藏层。那到底可以有几层呢?以下是老师举出的一些比较深的神经网络的例子
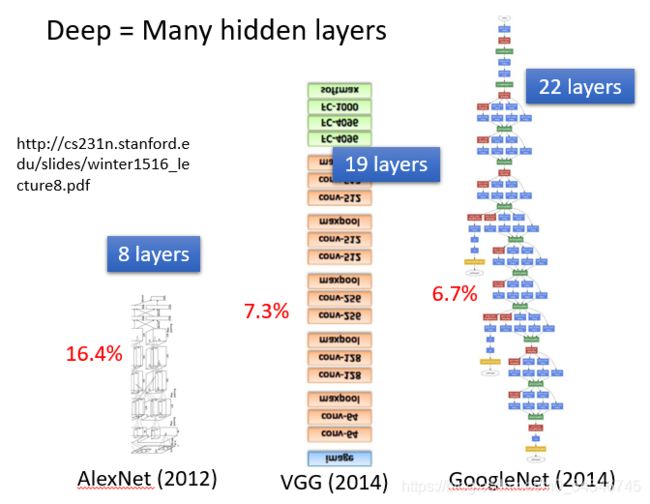
- 2012 AlexNet:8层
- 2014 VGG:19层
- 2014 GoogleNet:22层
- 2015 Residual Net:152层
- 101 Taipei:101层
随着层数变多,错误率降低,随之运算量增大,通常都是超过亿万级的计算。对于这样复杂的结构,我们一定不会一个一个的计算,对于亿万级的计算,使用loop循环效率很低。
这里我们就引入矩阵计算(Matrix Operation)能使得我们的运算的速度以及效率高很多:
矩阵计算
如下图所示,输入是
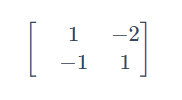
输出是
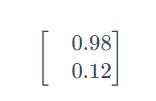
计算方法就是:sigmoid(权重w【黄色】 * 输入【蓝色】+ 偏移量b【绿色】)= 输出
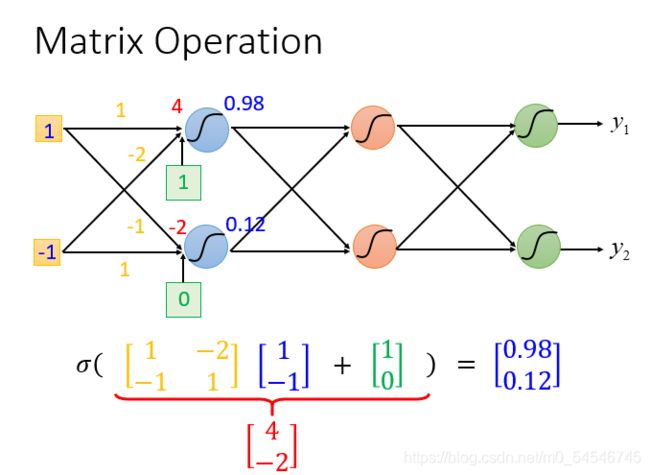
其中sigmoid更一般的来说是激活函数(activation function),现在已经很少用sigmoid来当做激活函数。
如果有很多层呢? a 1 = σ ( w 1 x + b 1 ) a 2 = σ ( w 1 a 1 + b 2 ) ⋅ ⋅ ⋅ y = σ ( w L a L − 1 + b L ) a^1 = \sigma (w^1x+b^1) \ a^2 = \sigma (w^1a^1+b^2) \ ··· \ y = \sigma (w^La^{L-1}+b^L) a1=σ(w1x+b1) a2=σ(w1a1+b2) ⋅⋅⋅ y=σ(wLaL−1+bL)

计算方法就像是嵌套,这里就不列公式了,结合上一个图更好理解。所以整个神经网络运算就相当于一连串的矩阵运算。

从结构上看每一层的计算都是一样的,也就是用计算机进行并行矩阵运算。 这样写成矩阵运算的好处是,你可以使用GPU加速。 整个神经网络可以这样看:
本质:通过隐藏层进行特征转换
把隐藏层通过特征提取来替代原来的特征工程,这样在最后一个隐藏层输出的就是一组新的特征(相当于黑箱操作)而对于输出层,其实是把前面的隐藏层的输出当做输入(经过特征提取得到的一组最好的特征)然后通过一个多分类器(可以是softmax函数)得到最后的输出y。

示例:手写数字识别
举一个手写数字体识别的例子: 输入:一个16*16=256维的向量,每个pixel对应一个dimension,有颜色用(ink)用1表示,没有颜色(no ink)用0表示 输出:10个维度,每个维度代表一个数字的置信度。
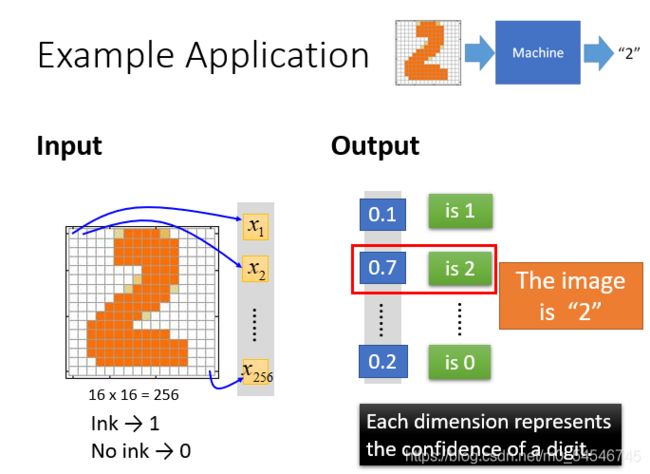
从输出结果来看,每一个维度对应输出一个数字,是数字2的概率为0.7的概率最大。说明这张图片是2的可能性就是最大的
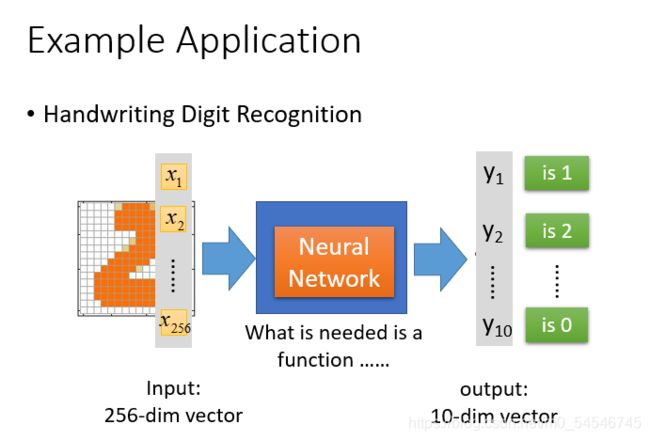
在这个问题中,唯一需要的就是一个函数,输入是256维的向量,输出是10维的向量,我们所需要求的函数就是神经网络这个函数
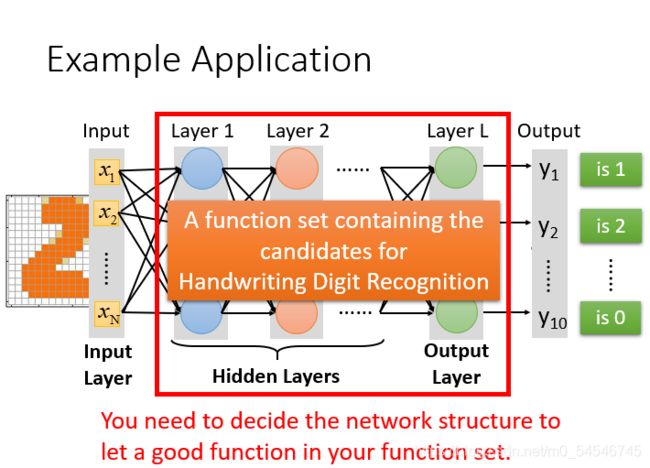
从上图看神经网络的结构决定了函数集(function set),所以说网络结构(network structured)很关键。
一些可能的问题
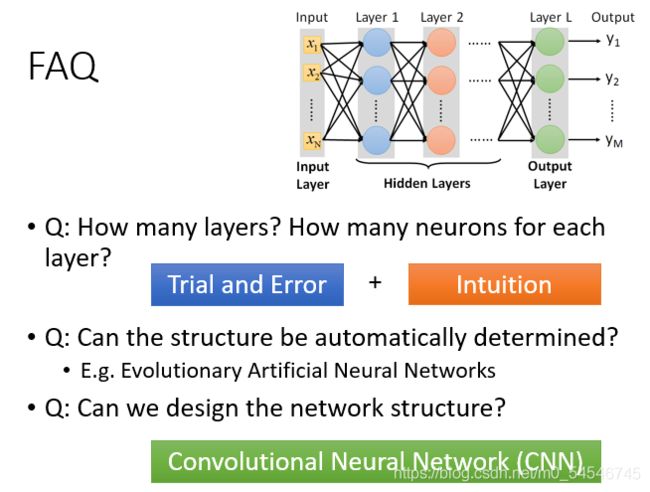
接下来有几个问题:
- 多少层? 每层有多少神经元? 这个问我们需要用尝试加上直觉的方法来进行调试。对于有些机器学习相关的问题,我们一般用特征工程来提取特征,但是对于深度学习,我们只需要设计神经网络模型来进行就可以了。对于语音识别和影像识别,深度学习是个好的方法,因为特征工程提取特征并不容易。
- 结构可以自动确定吗? 有很多设计方法可以让机器自动找到神经网络的结构的,比如进化人工神经网络(Evolutionary Artificial Neural Networks)但是这些方法并不是很普及 。
- 我们可以设计网络结构吗? 可以的,比如 CNN卷积神经网络(Convolutional Neural Network )
Step2: 模型评估
损失示例
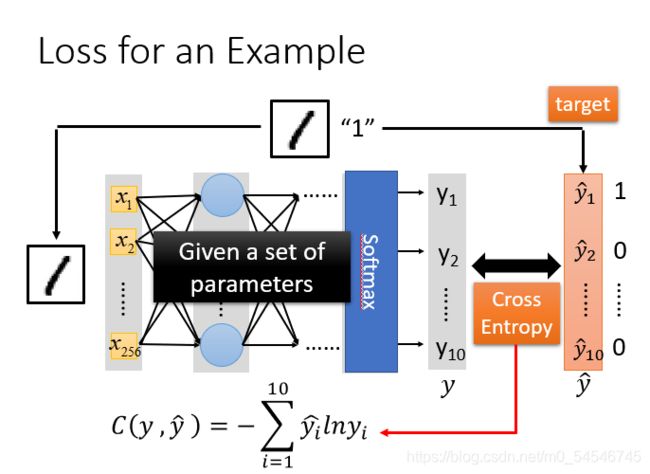
对于模型的评估,我们一般采用损失函数来反应模型的好差,所以对于神经网络来说,我们采用交叉熵(cross entropy)函数来对 y y y和 y ^ \hat{y} y^的损失进行计算,接下来我们就是调整参数,让交叉熵越小越好。
总体损失

对于损失,我们不单单要计算一笔数据的,而是要计算整体所有训练数据的损失,然后把所有的训练数据的损失都加起来,得到一个总体损失L。接下来就是在function set里面找到一组函数能最小化这个总体损失L,或者是找一组神经网络的参数 θ \theta θ,来最小化总体损失L
Step3:选择最优函数
如何找到最优的函数和最好的一组参数呢,我们用的就是梯度下降。


具体流程: θ \theta θ是一组包含权重和偏差的参数集合,随机找一个初始值,接下来计算一下每个参数对应偏微分,得到的一个偏微分的集合 ∇ L \nabla{L} ∇L就是梯度,有了这些偏微分,我们就可以不断更新梯度得到新的参数,这样不断反复进行,就能得到一组最好的参数使得损失函数的值最小
反向传播

在神经网络中计算损失最好的方法就是反向传播,我们可以用很多框架来进行计算损失,比如说TensorFlow,theano,Pytorch等等
思考
为什么要用深度学习,深层架构带来哪些好处?那是不是隐藏层越多越好?
隐藏层越多越好?
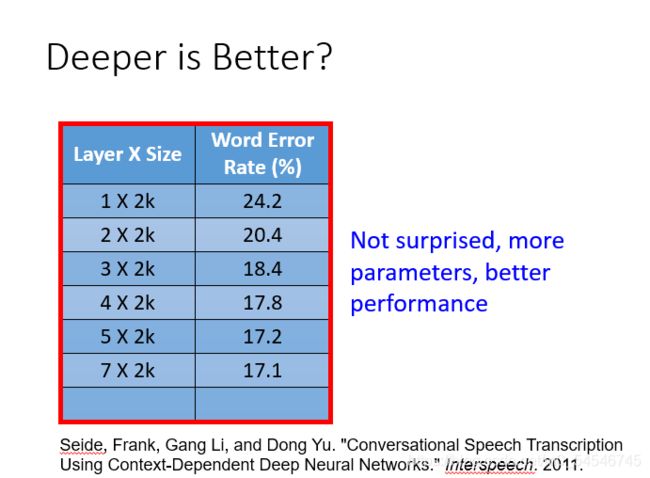
从图中展示的结果看,毫无疑问,层次越深效果越好~~
普遍性定理
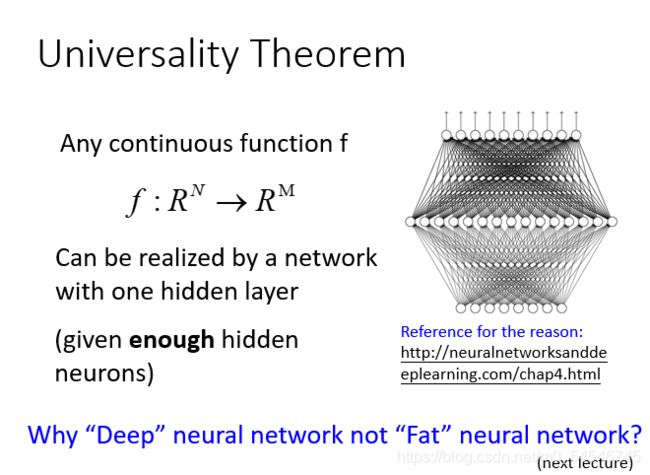
参数多的model拟合数据很好是很正常的。下面有一个通用的理论: 对于任何一个连续的函数,都可以用足够多的隐藏层来表示。
总结
这节课主要介绍了深度学习的发展历程,以及进行深度学习的三个步骤和一些关于深度学习的思考。让我对深度学习有一个大概的了解。