ultralytics/yolov3训练预测自己数据集的配置过程
需要使用https://github.com/ultralytics/yolov3提供的pytorch yolov3版本来训练预测自己的数据集,以检测出感兴趣目标,目前还没有看到详细的资料,这边系统记录下我的配置过程。
和博主前面几篇博客配置环境一样,在Anconda python环境下进行配置。yolov3的一些资料可见博主的博客目标分类、语义分割、目标检测中的深度学习算法阶段性总结_jiugeshao的专栏-CSDN博客
![]()
一. 使用Conda创建新的环境
1. 之前系列博客里已经实现了很多网络,不想去影响之前python所依赖库的版本,故重新创建一个新的环境来用于跑此版本yolov3
conda create -n pytorch-yolo python=3.8
此虚拟机环境可以从如下路径查看的到

2.如下命令激活此conda环境
source activate pytorch-yolo
若关闭次环境可以用如下语句
source deactivate删除某包
conda remove --name env_name --all安装某个包可以如下
conda install -n env_name numpy删除某包
conda remove -n env_name numpy查看当前所有虚拟环境的名字,以及各虚拟环境下所包含的库命令

3.可以增加清华源,供后面conda install 一些库时,下载速度快点
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2二. 在该conda环境下安装pytorch
1. PyTorch pytorch官网上选中Install按钮

2.博主的cuda 版本当时是10.1版本 深度学习平台实现Demo(三)- Anaconda3配置tensorflow2.3.1及如何转化tensorflow1.x系列代码_jiugeshao的专栏-CSDN博客
由于在下面页面上没有看到对应10.1的版本,故可点击install previous versions of PyTorch


3. 选择如上的命令语句, 在pytorch环境下的命令行语句下执行
![]()
4. 可以输入如下两条命令语句,确认是否安装完毕,且支持gpu加速

三. pycharm应用上面的Conda环境
1. pycharm新建一个工程,名叫Trial

2. File菜单栏,选择Settings,如下项,点击Add,增加新的project Interpreter



3. 应用此设置
4.可以通过第二步中show all选项跳出来的对话框窗口,在右侧功能区选中对应按钮,去更改环境名字

四. ultralytics/yolov3 使用原始模型预测图片
1. github上download资源https://github.com/ultralytics/yolov3,下载的目录放入到上面新建的工程目录Trial下
2. cd到yolov3目录下

3. 使用如下命令,安装此项目所依赖的环境库
pip install -r requirements.txt4. 下载完毕后,可以跑下detect.py,来查看原有的coco数据集上图像的预测结果
此时查看文件,发现需要yolov3.pt(默认参数),但该文件并没有随git该目录时一起下载,github博主提供了这些文件的下载路径,
Releases · ultralytics/yolov3 · GitHub, 若下载速度慢的童鞋,我文末也会附上我整个工程的目录链接

5.yolov3.pt如下目录结构放置即可

6.直接运行detect.py文件,博主这里出现报错
Traceback (most recent call last):
File "D:/mycode/0-Object_Detection/Trial/yolov3-master/detect.py", line 5, in
import cv2
File "C:\Anaconda3\envs\pytorch-yolo\lib\site-packages\cv2\__init__.py", line 5, in
from .cv2 import *
ImportError: numpy.core.multiarray failed to import
此时可以先卸载numpy,再重新安装下,

7.直接默认参数运行detect.py文件,可以看到/data/images路径下两张图的预测结果



五. 构造自己的训练数据集
所使用的的数据集介绍见博主此前博客语义分割之FCN训练预测自己的数据集_jiugeshao的专栏-CSDN博客
1. 在Trial下新建了一个PreepareImage的文件夹,在该文件夹里来准备训练此版网络需要的文件

2. 使用LabelImg来对images里的24张图片进行标注,使用pip语句即可完成labelImg的安装![]()
3.命令输入labelImg命令
![]()
4.对24张图像中的人行道进行标注,我标注的类别只有一种,
![]()
5.保存路径设置为上面images在同一目录下的anno文件夹下
![]()
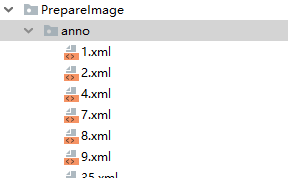
6. anno文件中都为如下格式的xml文件,需要进行转化

7. 新建一个GenerateLabel.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author:Icecream.Shao
#voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import cv2
classes = ["sidewalk"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id, Image_root):
in_file = open('../PrepareImage/anno/%s.xml' % (image_id))
out_file = open('../PrepareImage/anno/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size') # 根据不同的xml标注习惯修改
if size:
w = int(size.find('width').text)
h = int(size.find('height').text)
else:
jpg_img_patch = Image_root + image_id + '.jpg'
jpg_img = cv2.imread(jpg_img_patch)
h, w, _ = jpg_img.shape # cv2读取的图片大小格式是w,h
for obj in root.iter('object'):
difficult = obj.find('difficult')
if difficult:
difficult = obj.find('difficult').text
else:
difficult = 0
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
Image_root = '../PrepareImage/images'
fileList = os.listdir(Image_root)
for path in fileList:
image_ids = path.split(".")
image_id = image_ids[0]
convert_annotation(image_id, Image_root)
运行,在anno文件夹下,会看到对应每一个xml文件,都会生成一个对应的txt文件
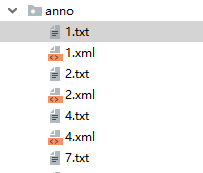
txt文件中的式样如下:
![]()
8. 此时准备训练所用数据都获取完毕,和yolov3-master同一级目录下新建sideWalk文件夹,文件夹中再建立子文件夹,整体目录结构如下:

如上sideWalk/images/train中为上面所用的24张原图

如上sidewalk/labels/train中为上面所生成的24个txt文件

六. 用自己数据集训练ultralytics/yolov3
1. 在/data文件夹中新建sidewalk.yaml文件

文件里内容为:
#Test by Icecream.Shao
# download command/URL (optional)
#download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../sideWalk/images/train/ # 128 images
val: ../sideWalk/images/train/ # 128 images
# number of classes
nc: 1
# class names
names: [ 'sidewalk' ]
2. train中的默认参数为修改了如下红色标记线几处:

3. 运行train.py开始训练
七. 用训练好的模型预测图片
1. 训练好的模型可以从如下文件夹中找到
该文件夹中存在多个exp关键字的文件夹,其每一次训练,exp后面的索引都会增1,以记录你的训练历史

我们选择最新的exp10文件夹
将其中的best.pt拷贝到和前面yolov3.pt的同一级目录下

2. 在data文件夹下新建test文件夹,将要测试的图片放入该文件夹中

3. detect.py我修改了如下默认参数

4. 运行detect.py, 在runs文件夹的detect文件夹中能看到整体测试集的预测结果,这边的exp也是每一次预测的历史记录

检测效果如下:


这边不重点说模型优化的调节方法,方向是调参和选择所用的预训练模型,这边我所用的训练集样本太少。
后续优化过程可以见https://github.com/ultralytics/yolov5/wiki/Tips-for-Best-Training-Results上说明
可从如下链接获取博主所配置的工程
链接:https://pan.baidu.com/s/1t7_IBtLtzYtOJv17Ri3WuA
提取码:9gg6
此版本对应的是9.5版本
